Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Konektor DynamoDB dengan dukungan Spark DataFrame
Konektor DynamoDB dengan dukungan DataFrame Spark memungkinkan Anda membaca dari dan menulis ke tabel di DynamoDB menggunakan Spark API. DataFrame Langkah-langkah pengaturan konektor sama dengan DynamicFrame-based konektor dan dapat ditemukan di sini.
Untuk memuat di pustaka DataFrame-based konektor, pastikan untuk melampirkan koneksi DynamoDB ke pekerjaan Glue.
catatan
Glue console UI saat ini tidak mendukung pembuatan koneksi DynamoDB. Anda dapat menggunakan Glue CLI (CreateConnection) untuk membuat koneksi DynamoDB:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
Setelah membuat koneksi DynamoDB, Anda dapat melampirkannya ke pekerjaan Glue Anda melalui CLI CreateJob(UpdateJob,) atau langsung di halaman “Detail pekerjaan”:
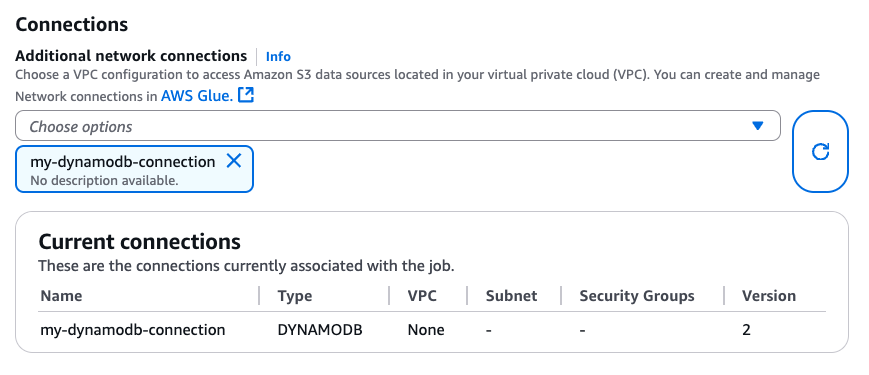
Setelah memastikan koneksi dengan Jenis DYNAMODB terpasang ke pekerjaan Glue Anda, Anda dapat menggunakan operasi baca, tulis, dan ekspor berikut dari konektor. DataFrame-based
Membaca dari dan menulis ke DynamoDB dengan konektor DataFrame-based
Contoh kode berikut menunjukkan cara membaca dari dan menulis ke tabel DynamoDB melalui konektor. DataFrame-based Contoh-contoh tersebut menunjukkan pembacaan dari satu tabel dan penulisan ke tabel lain.
Menggunakan ekspor DynamoDB melalui konektor DataFrame-based
Operasi ekspor lebih disukai untuk membaca operasi untuk ukuran tabel DynamoDB lebih besar dari 80 GB. Contoh kode berikut menunjukkan cara membaca dari tabel, ekspor ke S3, dan mencetak jumlah partisi melalui konektor. DataFrame-based
catatan
Fungsi ekspor DynamoDB tersedia melalui objek Scala. DynamoDBExport Pengguna Python dapat mengaksesnya melalui interop JVM Spark atau menggunakan AWS SDK untuk Python (boto3) dengan DynamoDB API. ExportTableToPointInTime
Opsi konfigurasi
Baca opsi
| Opsi | Deskripsi | Default |
|---|---|---|
dynamodb.input.tableName |
Nama tabel DynamoDB (wajib) | - |
dynamodb.throughput.read |
Unit kapasitas baca (RCU) untuk digunakan. Jika tidak ditentukan, dynamodb.throughput.read.ratio digunakan untuk perhitungan. |
- |
dynamodb.throughput.read.ratio |
Rasio unit kapasitas baca (RCU) yang digunakan | 0,5 |
dynamodb.table.read.capacity |
Kapasitas baca tabel sesuai permintaan yang digunakan untuk menghitung throughput. Parameter ini hanya efektif dalam tabel kapasitas sesuai permintaan. Default ke unit baca throughput hangat. | - |
dynamodb.splits |
Mendefinisikan berapa banyak segmen yang digunakan dalam operasi pemindaian paralel. Jika tidak disediakan, konektor akan menghitung nilai default yang wajar. | - |
dynamodb.consistentRead |
Apakah akan menggunakan bacaan yang sangat konsisten | SALAH |
dynamodb.input.retry |
Mendefinisikan berapa banyak percobaan ulang yang kami lakukan ketika ada pengecualian yang dapat dicoba ulang. | 10 |
Tulis opsi
| Opsi | Deskripsi | Default |
|---|---|---|
dynamodb.output.tableName |
Nama tabel DynamoDB (wajib) | - |
dynamodb.throughput.write |
Unit kapasitas tulis (WCU) untuk digunakan. Jika tidak ditentukan, dynamodb.throughput.write.ratio digunakan untuk perhitungan. |
- |
dynamodb.throughput.write.ratio |
Rasio unit kapasitas tulis (WCU) yang digunakan | 0,5 |
dynamodb.table.write.capacity |
Kapasitas tulis tabel sesuai permintaan yang digunakan untuk menghitung throughput. Parameter ini hanya efektif dalam tabel kapasitas sesuai permintaan. Default ke unit tulis throughput hangat. | - |
dynamodb.item.size.check.enabled |
Jika benar, konektor menghitung ukuran item dan membatalkan jika ukuran melebihi ukuran maksimum, sebelum menulis ke tabel DynamoDB. | BETUL |
dynamodb.output.retry |
Mendefinisikan berapa banyak percobaan ulang yang kami lakukan ketika ada pengecualian yang dapat dicoba ulang. | 10 |
Opsi ekspor
| Opsi | Deskripsi | Default |
|---|---|---|
dynamodb.export |
Jika diatur untuk ddb mengaktifkan konektor ekspor AWS Glue DynamoDB di mana yang ExportTableToPointInTimeRequet baru akan dipanggil selama AWS pekerjaan Glue. Ekspor baru akan dihasilkan dengan lokasi yang dilewatkan dari dynamodb.s3.bucket dandynamodb.s3.prefix. Jika diatur untuk s3 mengaktifkan konektor ekspor AWS Glue DynamoDB tetapi melewatkan pembuatan ekspor DynamoDB baru dan sebagai gantinya menggunakan dan dynamodb.s3.bucket sebagai lokasi Amazon S3 dari sebelumnya dynamodb.s3.prefix yang diekspor dari tabel tersebut. |
ddb |
dynamodb.tableArn |
Tabel DynamoDB untuk dibaca. Harus diisi jika dynamodb.export diatur ke ddb. |
|
dynamodb.simplifyDDBJson |
Jika diatur ketrue, melakukan transformasi untuk menyederhanakan skema struktur DynamoDB JSON yang hadir dalam ekspor. |
SALAH |
dynamodb.s3.bucket |
Bucket S3 untuk menyimpan data sementara selama ekspor DynamoDB (wajib) | |
dynamodb.s3.prefix |
Awalan S3 untuk menyimpan data sementara selama ekspor DynamoDB | |
dynamodb.s3.bucketOwner |
Tunjukkan pemilik bucket yang diperlukan untuk akses Amazon S3 lintas akun | |
dynamodb.s3.sse.algorithm |
Jenis enkripsi yang digunakan pada bucket tempat data sementara akan disimpan. Nilai yang valid adalah AES256 dan KMS. |
|
dynamodb.s3.sse.kmsKeyId |
ID kunci AWS KMS terkelola yang digunakan untuk mengenkripsi bucket S3 tempat data sementara akan disimpan (jika ada). | |
dynamodb.exportTime |
Titik waktu di mana ekspor harus dilakukan. Nilai yang valid: string yang mewakili ISO-8601 instant. |
Opsi umum
| Opsi | Deskripsi | Default |
|---|---|---|
dynamodb.sts.roleArn |
Peran IAM ARN akan diasumsikan untuk akses lintas akun | - |
dynamodb.sts.roleSessionName |
Nama sesi STS | glue-dynamodb-sts-session |
dynamodb.sts.region |
Wilayah untuk klien STS (untuk asumsi peran lintas wilayah) | Sama seperti region opsi |
