Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan EMR Tanpa Server denganAWS Lake Formationuntuk kontrol akses berbutir halus
Gambaran umum
Dengan Amazon EMR merilis 7.2.0 dan yang lebih tinggi, manfaatkan AWS Lake Formation untuk menerapkan kontrol akses berbutir halus pada tabel Katalog Data yang didukung oleh S3. Kemampuan ini memungkinkan Anda mengonfigurasi kontrol akses tingkat tabel, baris, kolom, dan sel untuk read kueri dalam pekerjaan Spark Tanpa Server EMR Amazon Anda. Untuk mengonfigurasi kontrol akses berbutir halus untuk pekerjaan batch Apache Spark dan sesi interaktif, gunakan EMR Studio. Lihat bagian berikut untuk mempelajari lebih lanjut tentang Lake Formation dan cara menggunakannya dengan EMR Tanpa Server.
Menggunakan Amazon EMR Tanpa Server dengan AWS Lake Formation dikenakan biaya tambahan. Untuk informasi lebih lanjut, lihat harga Amazon EMR
Bagaimana EMR Serverless bekerja denganAWS Lake Formation
Menggunakan EMR Tanpa Server dengan Lake Formation memungkinkan Anda menerapkan lapisan izin pada setiap pekerjaan Spark untuk menerapkan kontrol izin Lake Formation saat EMR Tanpa Server mengeksekusi pekerjaan. EMR Tanpa Server menggunakan profil sumber daya Spark untuk membuat dua profil
Saat Anda menggunakan kapasitas pra-inisialisasi dengan Lake Formation, kami sarankan Anda memiliki minimal dua driver Spark. Setiap Formation-enabled pekerjaan Lake menggunakan dua driver Spark, satu untuk profil pengguna dan satu untuk profil sistem. Untuk kinerja terbaik, gunakan dua kali lipat jumlah pengemudi untuk Formation-enabled pekerjaan Danau dibandingkan jika Anda tidak menggunakan Lake Formation.
Saat Anda menjalankan pekerjaan Spark di EMR Tanpa Server, pertimbangkan juga dampak alokasi dinamis pada manajemen sumber daya dan kinerja klaster. Konfigurasi spark.dynamicAllocation.maxExecutors jumlah maksimum pelaksana per profil sumber daya berlaku untuk pengguna dan pelaksana sistem. Jika Anda mengonfigurasi angka tersebut agar sama dengan jumlah maksimum pelaksana yang diizinkan, pekerjaan Anda mungkin macet karena satu jenis pelaksana yang menggunakan semua sumber daya yang tersedia, yang mencegah pelaksana lain saat Anda menjalankan pekerjaan.
Jadi Anda tidak kehabisan sumber daya, EMR Serverless menetapkan jumlah maksimum default pelaksana per profil sumber daya menjadi 90% dari nilai. spark.dynamicAllocation.maxExecutors Anda dapat mengganti konfigurasi ini ketika Anda menentukan spark.dynamicAllocation.maxExecutorsRatio dengan nilai antara 0 dan 1. Selain itu, konfigurasikan juga properti berikut untuk mengoptimalkan alokasi sumber daya dan kinerja keseluruhan:
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
Berikut ini adalah ikhtisar tingkat tinggi tentang bagaimana EMR Tanpa Server mendapatkan akses ke data yang dilindungi oleh kebijakan keamanan Lake Formation.
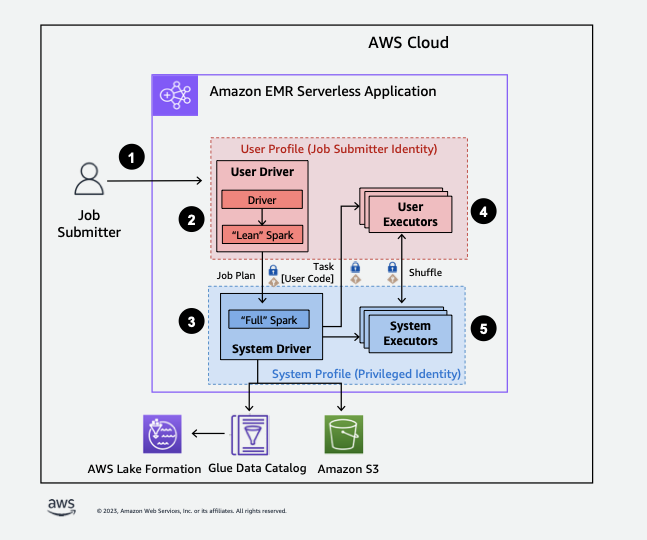
-
Seorang pengguna mengirimkan pekerjaan Spark ke aplikasi EMR Tanpa AWS Lake Formation Server yang diaktifkan.
-
EMR Tanpa Server mengirimkan pekerjaan ke driver pengguna dan menjalankan pekerjaan di profil pengguna. Driver pengguna menjalankan versi lean Spark yang tidak memiliki kemampuan untuk meluncurkan tugas, meminta pelaksana, mengakses S3 atau Glue Catalog. Ini membangun rencana kerja.
-
EMR Serverless menyiapkan driver kedua yang disebut driver sistem dan menjalankannya di profil sistem (dengan identitas istimewa). EMR Tanpa Server menyiapkan saluran TLS terenkripsi antara dua driver untuk komunikasi. Driver pengguna menggunakan saluran untuk mengirim rencana pekerjaan ke driver sistem. Driver sistem tidak menjalankan kode yang dikirimkan pengguna. Ini menjalankan Spark penuh dan berkomunikasi dengan S3, dan Katalog Data untuk akses data. Ini meminta pelaksana dan mengkompilasi Job Plan ke dalam urutan tahapan eksekusi.
-
EMR Serverless kemudian menjalankan tahapan pada pelaksana dengan driver pengguna atau driver sistem. Kode pengguna dalam tahap apa pun dijalankan secara eksklusif pada pelaksana profil pengguna.
-
Tahapan yang membaca data dari tabel Katalog Data yang dilindungi oleh AWS Lake Formation atau yang menerapkan filter keamanan didelegasikan ke pelaksana sistem.
Mengaktifkan Lake Formation di Amazon EMR
Untuk mengaktifkan Lake Formation, atur spark.emr-serverless.lakeformation.enabled ke true bawah spark-defaults klasifikasi untuk parameter konfigurasi runtime saat membuat aplikasi EMR Tanpa Server.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
Anda juga dapat mengaktifkan Lake Formation ketika Anda membuat aplikasi baru di EMR Studio. Pilih Gunakan Lake Formation untuk kontrol akses berbutir halus, tersedia di bawah Konfigurasi tambahan.
Inter-worker enkripsi diaktifkan secara default saat Anda menggunakan Lake Formation dengan EMR Tanpa Server, jadi Anda tidak perlu mengaktifkan enkripsi antar-pekerja secara eksplisit lagi.
Mengaktifkan Lake Formation untuk pekerjaan Spark
Untuk mengaktifkan Lake Formation untuk pekerjaan Spark individual, setel spark.emr-serverless.lakeformation.enabled ke true saat menggunakanspark-submit.
--conf spark.emr-serverless.lakeformation.enabled=true
Izin IAM peran runtime pekerjaan
Izin Lake Formation mengontrol akses ke sumber daya Katalog Data AWS Glue, lokasi Amazon S3, dan data dasar di lokasi tersebut. Izin IAM mengontrol akses ke API dan sumber daya Lake Formation dan AWS Glue. Meskipun Anda mungkin memiliki izin Lake Formation untuk mengakses tabel di Katalog Data (SELECT), operasi Anda gagal jika Anda tidak memiliki izin IAM pada operasi glue:Get* API.
Berikut ini adalah contoh kebijakan tentang cara memberikan izin IAM untuk mengakses skrip di S3, mengunggah log ke S3, izin AWS Glue API, dan izin untuk mengakses Lake Formation.
Menyiapkan izin Lake Formation untuk peran runtime pekerjaan
Pertama, daftarkan lokasi meja Hive Anda dengan Lake Formation. Kemudian buat izin untuk peran runtime pekerjaan Anda di tabel yang Anda inginkan. Untuk detail lebih lanjut tentang Lake Formation, lihat Apa ituAWS Lake Formation? di Panduan AWS Lake Formation Pengembang.
Setelah Anda mengatur izin Lake Formation, kirimkan pekerjaan Spark di Amazon EMR Tanpa Server. Untuk informasi lebih lanjut tentang pekerjaan Spark, lihat contoh Spark.
Mengirimkan pekerjaan
Setelah Anda selesai menyiapkan hibah Lake Formation, Anda dapat mengirimkan pekerjaan Spark di EMR Tanpa Server. Bagian berikut menunjukkan contoh cara mengkonfigurasi dan mengirimkan properti job run.
Persyaratan izin
Tabel tidak terdaftar diAWS Lake Formation
Untuk tabel yang tidak terdaftarAWS Lake Formation, peran runtime pekerjaan mengakses Katalog Data AWS Glue dan data tabel yang mendasarinya di Amazon S3. Ini mengharuskan peran runtime pekerjaan memiliki izin IAM yang sesuai untuk operasi AWS Glue dan Amazon S3.
Tabel terdaftar diAWS Lake Formation
Untuk tabel yang terdaftarAWS Lake Formation, peran runtime pekerjaan mengakses metadata Katalog Data AWS Glue, sementara kredensil sementara yang dijual oleh Lake Formation mengakses data tabel yang mendasarinya di Amazon S3. Izin Lake Formation yang diperlukan untuk menjalankan operasi bergantung pada panggilan AWS Glue Data Catalog dan Amazon S3 API yang memulai tugas Spark dan dapat diringkas sebagai berikut:
-
Izin DESCRIBE memungkinkan peran runtime untuk membaca tabel atau metadata database dalam Katalog Data
-
Izin ALTER memungkinkan peran runtime untuk memodifikasi tabel atau metadata database dalam Katalog Data
-
Izin DROP memungkinkan peran runtime untuk menghapus tabel atau metadata database dari Katalog Data
-
Izin SELECT memungkinkan peran runtime membaca data tabel dari Amazon S3
-
Izin INSERT memungkinkan peran runtime untuk menulis data tabel ke Amazon S3
-
Izin DELETE memungkinkan peran runtime untuk menghapus data tabel dari Amazon S3
catatan
Lake Formation mengevaluasi izin dengan malas saat pekerjaan Spark memanggil AWS Glue untuk mengambil metadata tabel dan Amazon S3 untuk mengambil data tabel. Pekerjaan yang menggunakan peran runtime dengan izin yang tidak mencukupi tidak akan gagal sampai Spark melakukan panggilan AWS Glue atau Amazon S3 yang memerlukan izin yang hilang.
catatan
Dalam matriks tabel yang didukung berikut:
-
Operasi yang ditandai sebagai Didukung secara eksklusif menggunakan kredensil Lake Formation untuk mengakses data tabel untuk tabel yang terdaftar dengan Lake Formation. Jika izin Lake Formation tidak mencukupi, operasi tidak akan kembali ke kredensyal peran runtime. Untuk tabel yang tidak terdaftar di Lake Formation, kredensyal peran runtime pekerjaan mengakses data tabel.
-
Operasi yang ditandai sebagai Didukung dengan izin IAM di lokasi Amazon S3 tidak menggunakan kredensil Lake Formation untuk mengakses data tabel yang mendasarinya di Amazon S3. Untuk menjalankan operasi ini, peran runtime pekerjaan harus memiliki izin Amazon S3 IAM yang diperlukan untuk mengakses data tabel, terlepas dari apakah tabel terdaftar di Lake Formation.
