Bantu tingkatkan halaman ini
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Untuk berkontribusi pada panduan pengguna ini, pilih Edit halaman ini pada GitHub tautan yang terletak di panel kanan setiap halaman.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Muat Model & Sajikan di Amazon EKS
Tip
Daftar
Langkah-langkah di bagian ini menerapkan model bahasa besar (LLM) di Amazon EKS, menyajikannya dengan VllM, dan berinteraksi dengan titik akhir inferensi.
Walkthrough menggunakan alat-alat berikut:
-
VLLm
- Mesin inferensi throughput tinggi yang dioptimalkan untuk penyajian LLM dan manajemen memori GPU. -
Run:ai Model Streamer
- Streaming bobot model langsung dari Amazon S3 ke memori GPU, mengurangi waktu muat dari menit ke detik. -
Buka WebUI
— Frontend obrolan yang dihosting sendiri yang terhubung ke API VLLM. OpenAI-compatible
Bagian ini menggunakan Ministral-3-8B-Instruct-2512 model
penting
Gunakan cluster yang Anda buat di Siapkan klaster Amazon EKS untuk beban AI/ML kerja bagian ini. Instruksi dalam panduan ini berfungsi untuk Mode Otomatis EKS dan Karpenter yang dikelola sendiri.
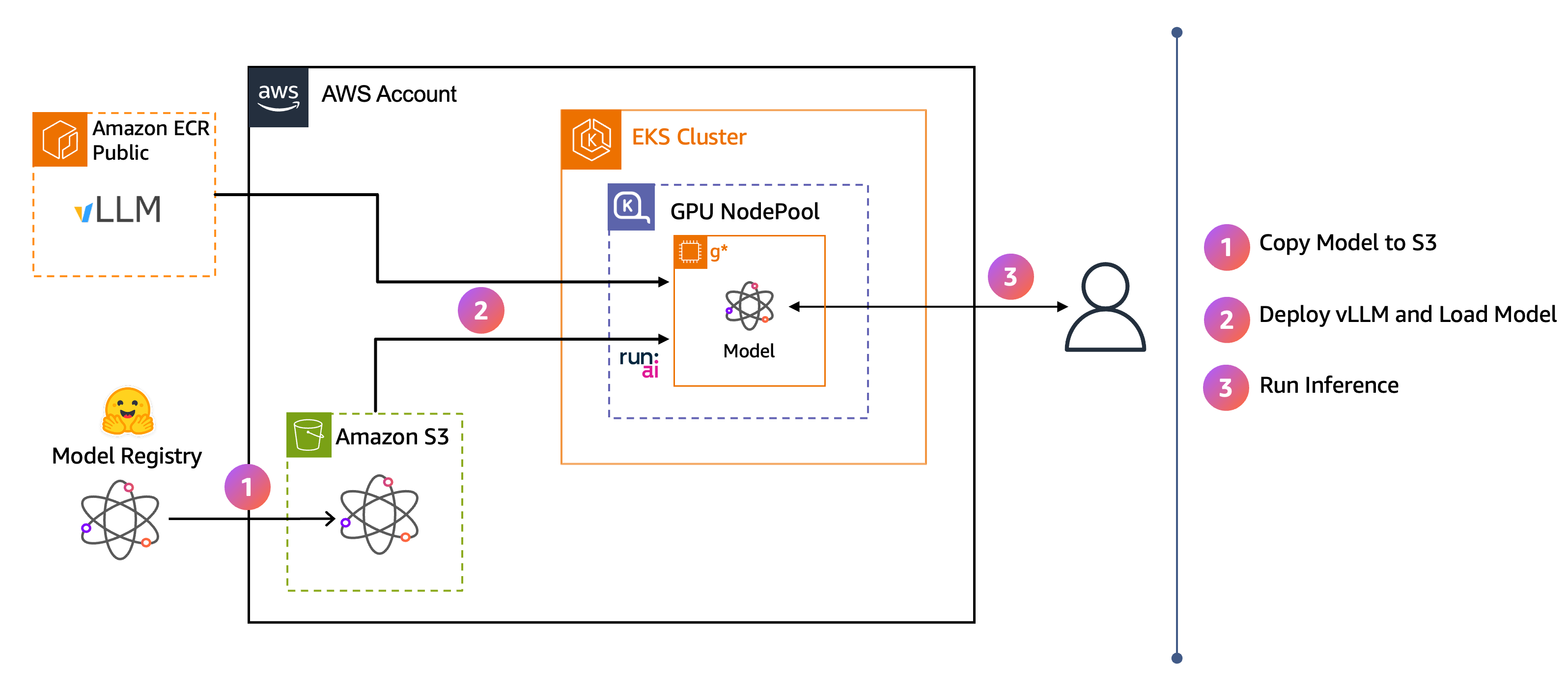
Diagram arsitektur menunjukkan aliran ujung ke ujung:
-
Bobot model diunduh dari Hugging Face ke Amazon S3.
-
VllM mengalirkan model langsung dari S3 ke memori GPU menggunakan Model Streamer. Run:ai
-
Pengguna mengirim permintaan inferensi ke titik akhir VllM.
Ketika Anda menyelesaikan langkah-langkah ini, Anda memiliki titik akhir inferensi VLLM yang dapat Anda gunakan untuk berinteraksi dengan model Ministal melalui aplikasi frontend obrolan.
Prasyarat
Selesaikan langkah-langkah di bagian pengaturan Cluster.
Jika Anda membuka terminal baru, atur nama cluster dan wilayah yang Anda gunakan di bagian Pengaturan Cluster via CLI:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Cari bucket bobot model yang Anda buat di langkah bucket Model weights S3:
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
Langkah 1: Unduh model dari Hugging Face
Pada langkah ini, Anda menerapkan Kubernetes Job yang mengunduh model dari Hugging Face dan mengunggahnya ke bucket S3 yang Anda buat di bagian prasyarat.
Untuk mengunduh model, terapkan manifes Job berikut:
contoh Unduhan model Manifes pekerjaan
cat << EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-download namespace: default labels: guide: ai-eks-docs spec: backoffLimit: 10 activeDeadlineSeconds: 3600 ttlSecondsAfterFinished: 86400 template: spec: restartPolicy: Never serviceAccountName: model-storage-sa containers: - name: downloader image: python:3.11-slim command: ["/bin/bash", "-c"] args: - | set -e pip install -q huggingface_hub boto3 echo "Downloading Ministral-3-8B-Instruct-2512 from Hugging Face..." python3 -c "from huggingface_hub import snapshot_download; snapshot_download('mistralai/Ministral-3-8B-Instruct-2512', local_dir='/tmp/mistral', allow_patterns=['*.json', '*.txt', '*.md', 'consolidated.safetensors'], ignore_patterns=['model-*.safetensors', 'model.safetensors.index.json'])" echo "Uploading to S3 bucket: \${MODEL_BUCKET}" python3 << 'PYTHON' import boto3 import os from pathlib import Path s3 = boto3.client('s3') bucket = os.environ.get('MODEL_BUCKET') local_dir = Path("/tmp/mistral") for file_path in local_dir.rglob("*"): if file_path.is_file(): if '.cache' in file_path.parts: continue s3_key = f"Ministral-3-8B-Instruct-2512/{file_path.relative_to(local_dir)}" print(f"Uploading {file_path.name}...") s3.upload_file(str(file_path), bucket, s3_key) print("Upload complete!") PYTHON env: - name: MODEL_BUCKET value: "${MODEL_BUCKET}" - name: HF_HUB_DISABLE_XET value: "1" resources: requests: memory: "2Gi" cpu: "1" limits: memory: "4Gi" cpu: "2" EOF
Tunggu sampai Job selesai. Bobot model (konsolidas.safetensors) kira-kira 10,4 GB, dan langkah ini biasanya memakan waktu 3-5 menit.
kubectl wait --for=condition=complete job/model-download --timeout=600s
Keluaran yang diharapkan
job.batch/model-download condition met
Verifikasi bahwa bobot model telah diunggah ke S3:
aws s3 ls s3://$(kubectl get job model-download -o jsonpath='{.spec.template.spec.containers[0].env[?(@.name=="MODEL_BUCKET")].value}')/Ministral-3-8B-Instruct-2512/ --recursive
Keluaran yang diharapkan
2026-05-18 10:29:53 20311 Ministral-3-8B-Instruct-2512/README.md 2026-05-18 10:29:53 2361 Ministral-3-8B-Instruct-2512/SYSTEM_PROMPT.txt 2026-05-18 10:29:53 1903 Ministral-3-8B-Instruct-2512/config.json 2026-05-18 10:29:54 10420633176 Ministral-3-8B-Instruct-2512/consolidated.safetensors 2026-05-18 10:29:53 131 Ministral-3-8B-Instruct-2512/generation_config.json 2026-05-18 10:29:53 1185 Ministral-3-8B-Instruct-2512/params.json 2026-05-18 10:29:53 976 Ministral-3-8B-Instruct-2512/processor_config.json 2026-05-18 10:29:53 16753777 Ministral-3-8B-Instruct-2512/tekken.json 2026-05-18 10:29:53 17077402 Ministral-3-8B-Instruct-2512/tokenizer.json 2026-05-18 10:29:53 21168 Ministral-3-8B-Instruct-2512/tokenizer_config.json
File.safetensors yang dikonsolidasikan berisi bobot model (sekitar 10,4 GB). File yang tersisa adalah file konfigurasi dan tokenizer yang dibutuhkan VllM untuk melayani model.
Langkah 2: Menyebarkan wadah inferensi
Di bagian ini, Anda menerapkan VllM sebagai Deployment Kubernetes untuk menyajikan model yang Anda unggah ke Amazon S3.
Bagian ini menggunakan AWS Deep Learning Containers
Penerapan ini menggunakan AWS DLC berikut untuk VllM 0.21.0public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci
Tag gambar menunjukkan VLLm 0.21.0 dengan dukungan GPU, Python 3.12, CUDA 13.0, Ubuntu 22.04, dioptimalkan untuk beban kerja, dan untuk startup container yang lebih cepat. EC2-based SOCI-enabled
Manifes ini membuat Deployment yang menjalankan VllM pada node GPU dan mengalirkan model langsung dari S3 ke memori GPU menggunakan Model Streamer. Run:ai Manifes juga membuat Layanan ClusterIP yang mengekspos titik akhir VllM pada port 8000 untuk akses dalam cluster.
Terapkan manifes:
contoh Penyebaran dan Layanan VLLm YAMB
cat << EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app labels: guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app guide: ai-eks-docs spec: serviceAccountName: model-storage-sa tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule nodeSelector: karpenter.sh/nodepool: gpu-inf containers: - name: vllm-inference image: public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci ports: - containerPort: 8000 args: - "--model=s3://${MODEL_BUCKET}/Ministral-3-8B-Instruct-2512/" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=128" - "--load-format=runai_streamer" - "--enforce-eager" - "--tokenizer_mode=mistral" - "--config_format=mistral" - "--enable-auto-tool-choice" - "--tool-call-parser=mistral" resources: limits: nvidia.com/gpu: 1 requests: memory: "40Gi" cpu: "8" --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc namespace: default labels: app: vllm-inference-app spec: selector: app: vllm-inference-app ports: - name: http port: 8000 targetPort: 8000 protocol: TCP EOF
Periksa apakah pod VllM dalam status Ready:
kubectl get pod -l app=vllm-inference-app -w
Keluaran yang diharapkan
NAME READY STATUS RESTARTS AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 Running 0 86s
Mungkin diperlukan ~2 menit agar gambar kontainer ditarik dan VllM mengalirkan bobot model dari S3 ke memori GPU. Tunggu sampai pod muncul 1/1 di kolom READY sebelum Anda melanjutkan.
Kombinasi EKS, SOCI, dan Run:ai Model Streamer memungkinkan startup pod yang cepat. Untuk memeriksa waktu startup untuk setiap tahap, lihat peristiwa pod:
kubectl describe pod -l app=vllm-inference-app | grep -A 20 "Events:"
Keluaran yang diharapkan
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 86s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). Normal Nominated 85s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-kqkq6 Normal Scheduled 55s default-scheduler Successfully assigned default/vllm-inference-app-d9d54586d-csmd7 to i-04f8792414384d2d3 Normal Pulling 52s kubelet Pulling image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" Normal Pulled 4s kubelet Successfully pulled image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" in 48.376s (48.376s including waiting). Image size: 8802823997 bytes. Normal Created 4s kubelet Created container vllm-inference Normal Started 4s kubelet Started container vllm-inference
Dalam contoh ini, node GPU disediakan dalam 30 detik dan gambar kontainer 8,8 GB ditarik dalam waktu sekitar 48 detik menggunakan SOCI. Penarikan gambar yang cepat mengurangi waktu mulai dingin untuk kontainer inferensi besar, yang memungkinkan Anda menskalakan pod GPU secara dinamis alih-alih menyediakan kapasitas GPU idle secara berlebihan.
Selanjutnya, periksa log VllM untuk memverifikasi waktu pemuatan model:
kubectl logs $(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') | grep -i 'Model loading took'
Keluaran yang diharapkan
INFO 05-18 18:41:49 [gpu_model_runner.py:4959] Model loading took 9.81 GiB memory and 5.023344 seconds
Log mengonfirmasi bahwa Run:ai Model Streamer memuat bobot model 10,4 GB langsung dari S3 ke memori GPU dalam waktu sekitar 5 detik, menghabiskan memori GPU 9,8 GiB.
Waktu pengunduhan gambar dalam contoh ini menggunakan instance g6e.4xlarge, yang memiliki bandwidth jaringan berkelanjutan 20 Gbps. Penarikan gambar dan waktu pemuatan model akan bervariasi pada jenis instance lain tergantung pada bandwidth jaringan yang tersedia.
Langkah 3: Jalankan inferensi
Dengan VllM Deployment berjalan, validasi titik akhir inferensi dan terapkan frontend obrolan untuk berinteraksi dengan model.
Jalankan uji validasi model
Paparkan titik akhir inferensi melalui port forward:
kubectl port-forward svc/vllm-inference-svc 8000:8000
Buka jendela terminal baru, lalu validasi bahwa wadah inferensi merespons:
curl -sI -X GET http://localhost:8000/health
Keluaran yang diharapkan
HTTP/1.1 200 OK date: Fri, 18 May 2026 00:39:23 GMT server: uvicorn content-length: 0
Langkah 4: Monitor Vllm
VllM mengekspos metrik Prometheus di luar kotak, termasuk tingkat permintaan, throughput token, latensi ujung ke ujung, dan pemanfaatan cache GPU KV. Di bagian ini, Anda menggunakan metrik ini dengan tumpukan pemantauan yang Anda siapkan di langkah penyiapan Cluster dan melihatnya di dasbor Grafana yang telah disediakan sebelumnya.
penting
Anda harus menyelesaikan subbagian Monitoring dari Pengaturan Cluster melalui bagian CLI sebelum melanjutkan. Langkah ini tergantung pada kube-prometheus-stack yang diinstal dan dasbor Grafana VllM sudah disediakan di file values.
Terapkan VllM ServiceMonitor
A ServiceMonitor memberi tahu Prometheus di mana harus mengikis metrik VllM.
cat << EOF | kubectl apply -f - apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: vllm-inference-app namespace: default labels: release: kube-prometheus-stack spec: selector: matchLabels: app: vllm-inference-app endpoints: - port: http path: /metrics interval: 15s EOF
Verifikasi bahwa ServiceMonitor telah dibuat:
kubectl get servicemonitor vllm-inference-app
Keluaran yang diharapkan
NAME AGE vllm-inference-app 5s
Untuk mengisi dasbor dengan metrik, buat lalu lintas inferensi terhadap titik akhir VllM yang sudah Anda ekspos melalui port-forward pada langkah validasi.
Temukan nama model yang disajikan:
MODEL_NAME=$(curl -s http://localhost:8000/v1/models | jq -r '.data[0].id') echo "Using model: $MODEL_NAME"
Kirim 50 permintaan penyelesaian obrolan secara paralel:
for i in $(seq 1 50); do curl -s -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d "{\"model\": \"$MODEL_NAME\", \"messages\": [{\"role\": \"user\", \"content\": \"Write a short poem about Kubernetes.\"}], \"max_tokens\": 128}" \ > /dev/null & done wait
Saat lalu lintas mengalir (atau segera setelahnya), periksa metrik token-throughput langsung dari titik akhir VllM: /metrics
curl -s http://localhost:8000/metrics | grep -E '^vllm:(prompt_tokens_total|generation_tokens_total|avg_generation_throughput_toks_per_s|avg_prompt_throughput_toks_per_s)' | head
Metrik vllm:prompt_tokens_total dan vllm:generation_tokens_total metrik secara monoton meningkatkan penghitung token input dan output yang disajikan. Metrik vllm:avg_prompt_throughput_toks_per_s dan vllm:avg_generation_throughput_toks_per_s metrik adalah pengukur throughput rata-rata bergulir. Metrik yang sama ini memberi daya pada dasbor Grafana yang Anda buka di ayat berikut.
Lihat dasbor Grafana VllM
File nilai kube-prometheus-stack dari bagian Monitoring sudah menyediakan dasbor VLLM komunitas (gnetID 25263) di bawah folder Pemantauan GPU, jadi
Untuk mengakses Grafana, mulai port-forward ke layanan Grafana:
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
Buka http://localhost:3000admin dan kata sandi dari perintah berikut:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Arahkan ke Dasbor> Pemantauan GPU > Metrik VllM.
Dasbor Grafana VLLm

Dasbor menampilkan tingkat permintaan, throughput token prompt dan generasi, persentil latensi, dan pemanfaatan cache GPU KV untuk titik akhir inferensi VllM.
Langkah 5: Menyebarkan aplikasi obrolan
Pada langkah ini, Anda menerapkan Open WebUI sebagai frontend obrolan untuk berinteraksi dengan model. Open WebUI adalah antarmuka AI open source yang di-host sendiri yang OpenAI-compatible mendukung API dan menyediakan antarmuka obrolan dengan riwayat percakapan dan rendering penurunan harga. Karena VLLM mengekspos OpenAI-compatible API, Open WebUI menghubungkannya secara langsung sebagai backend.
Untuk menyebarkan aplikasi Open WebUI, terapkan manifes berikut:
contoh Buka WebUI Deployment dan Service YAMB
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: open-webui namespace: default labels: app: open-webui guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: open-webui template: metadata: labels: app: open-webui guide: ai-eks-docs spec: containers: - name: open-webui image: ghcr.io/open-webui/open-webui:v0.9.2 ports: - containerPort: 8080 resources: requests: cpu: "500m" memory: "500Mi" limits: cpu: "1000m" memory: "1Gi" env: - name: OPENAI_API_BASE_URLS value: "http://vllm-inference-svc:8000/v1" - name: OPENAI_API_KEY value: "dummy" - name: WEBUI_AUTH value: "False" - name: ENABLE_OLLAMA_API value: "False" - name: ENABLE_EVALUATION_ARENA_MODELS value: "False" - name: RAG_EMBEDDING_ENGINE value: "" volumeMounts: - name: webui-volume mountPath: /app/backend/data volumes: - name: webui-volume emptyDir: {} --- apiVersion: v1 kind: Service metadata: name: open-webui namespace: default labels: app: open-webui spec: type: ClusterIP selector: app: open-webui ports: - protocol: TCP port: 80 targetPort: 8080 EOF
Tunggu hingga pod Open WebUI siap:
kubectl wait --for=condition=ready pod -l app=open-webui --timeout=300s
Keluaran yang diharapkan
pod/open-webui-6cbfc9867f-jf9w9 condition met
Untuk mengakses aplikasi, atur penerusan port:
kubectl port-forward svc/open-webui 8080:80
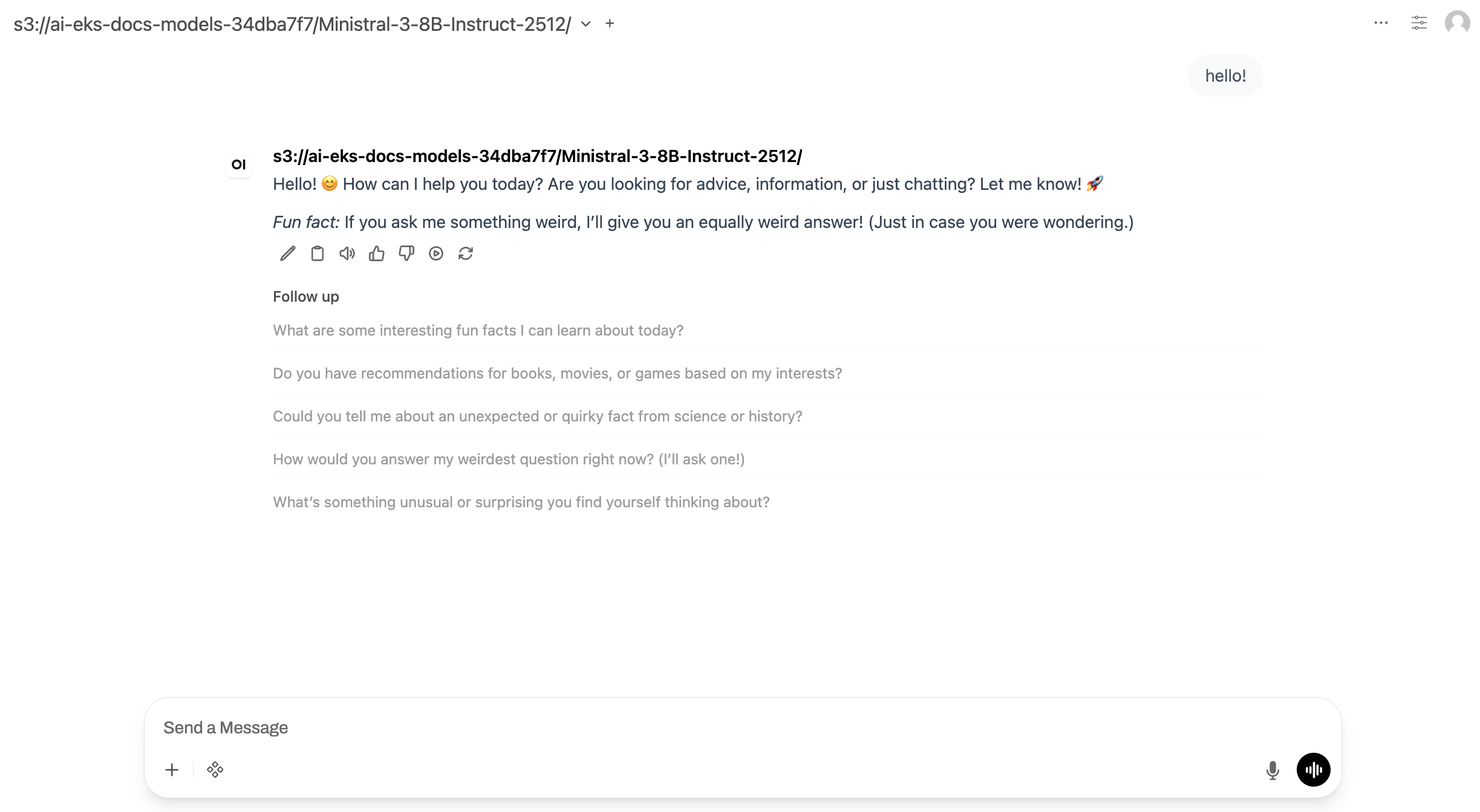
Buka http://localhost:8080
Antarmuka obrolan muncul di mana Anda dapat berinteraksi dengan model Ministral.
Saat Anda selesai menguji, hentikan port-forward dengan kbd: [Ctrl+C].
Bersihkan
Untuk menghapus sumber daya beban kerja yang Anda buat di bagian ini, hapus aplikasi Open WebUI, server inferensi VLLM, dan Job unduhan model:
kubectl delete deployment open-webui kubectl delete service open-webui kubectl delete deployment vllm-inference-app kubectl delete service vllm-inference-svc kubectl delete servicemonitor vllm-inference-app kubectl delete job model-download
Untuk petunjuk cara menghapus sumber daya infrastruktur seperti cluster, dan bucket S3 NodePool, lihat Cluster Setup Cleanup.
