Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Migrasi dari Couchbase Server
Pengantar
Panduan ini menyajikan poin-poin penting yang perlu dipertimbangkan saat bermigrasi dari Couchbase Server ke Amazon DocumentDB. Ini menjelaskan pertimbangan untuk fase penemuan, perencanaan, pelaksanaan, dan validasi migrasi Anda. Ini juga menjelaskan cara melakukan migrasi offline dan online.
Perbandingan dengan Amazon DocumentDB
| Server Couchbase | Amazon DocumentDB | |
|---|---|---|
| Organisasi Data | Dalam versi 7.0 dan yang lebih baru, data diatur ke dalam ember, cakupan, dan koleksi. Dalam versi sebelumnya, data diatur ke dalam ember. | Data diatur ke dalam database dan koleksi. |
| Kompatibilitas | Ada yang terpisah APIs untuk setiap layanan (misalnya data, indeks, pencarian, dll.). Pencarian sekunder menggunakan SQL++ (sebelumnya dikenal sebagai N1QL); bahasa kueri berdasarkan SQL standar ANSI sehingga akrab bagi banyak pengembang. | Amazon DocumentDB kompatibel dengan MongoDB API. |
| Arsitektur | Penyimpanan dilampirkan ke setiap instance cluster. Anda tidak dapat menskalakan komputasi secara independen dari penyimpanan. | Amazon DocumentDB dirancang untuk cloud dan untuk menghindari keterbatasan arsitektur database tradisional. Lapisan komputasi dan penyimpanan dipisahkan di Amazon DocumentDB dan lapisan komputasi dapat diskalakan secara independen dari penyimpanan. |
| Tambahkan kapasitas baca sesuai permintaan | Cluster dapat ditingkatkan dengan menambahkan instance. Karena penyimpanan dilampirkan ke instance di mana layanan berjalan, waktu yang diperlukan untuk skala keluar tergantung pada jumlah data yang perlu dipindahkan ke instance baru, atau diseimbangkan kembali. | Anda dapat mencapai penskalaan baca untuk klaster Amazon DocumentDB Anda dengan membuat hingga 15 replika Amazon DocumentDB di cluster. Tidak ada dampak pada lapisan penyimpanan. |
| Pulihkan dengan cepat dari kegagalan node | Cluster memiliki kemampuan failover otomatis tetapi waktu untuk mengembalikan cluster ke kekuatan penuh tergantung pada jumlah data yang perlu dipindahkan ke instance baru. | Amazon DocumentDB dapat melakukan failover primer biasanya dalam 30 detik dan mengembalikan cluster kembali ke kekuatan penuh dalam 8-10 menit terlepas dari jumlah data dalam cluster. |
| Skalakan penyimpanan saat data tumbuh | Untuk penyimpanan cluster yang dikelola sendiri dan IOs jangan skala secara otomatis. | Penyimpanan IOs dan skala Amazon DocumentDB secara otomatis. |
| Backup data tanpa mempengaruhi kinerja | Cadangan dilakukan oleh layanan cadangan dan tidak diaktifkan secara default. Karena penyimpanan dan komputasi tidak terpisah, dapat berdampak pada kinerja. | Pencadangan Amazon DocumentDB diaktifkan secara default dan tidak dapat dimatikan. Cadangan ditangani oleh lapisan penyimpanan, sehingga berdampak nol pada lapisan komputasi. Amazon DocumentDB mendukung pemulihan dari snapshot cluster dan memulihkan ke titik waktu. |
| Daya tahan data | Bisa ada maksimal 3 salinan replika data dalam sebuah cluster dengan total 4 salinan. Setiap contoh di mana layanan data berjalan akan memiliki salinan aktif dan 1, 2, atau 3 replika data. | Amazon DocumentDB menyimpan 6 salinan data tidak peduli berapa banyak instance komputasi yang ada dengan kuorum tulis 4 dan persistst true. Klien menerima pengakuan setelah lapisan penyimpanan bertahan 4 salinan data. |
| Konsistensi | Konsistensi langsung untuk K/V operasi didukung. Couchbase SDK merutekan K/V permintaan ke instance tertentu yang berisi salinan aktif data sehingga setelah pembaruan diakui, klien dijamin untuk membaca pembaruan tersebut. Replikasi pembaruan ke layanan lain (indeks, pencarian, analisis, eventing) pada akhirnya konsisten. | Replika Amazon DocumentDB pada akhirnya konsisten. Jika pembacaan konsistensi langsung diperlukan, klien dapat membaca dari contoh utama. |
| Replikasi | Cross-Data Center Replication (XDCR) menyediakan replikasi data yang disaring, aktif-pasif/aktif-aktif dalam banyak topologi. | Cluster global Amazon DocumentDB menyediakan replikasi aktif-pasif dalam topologi 1:many (hingga 10). |
Penemuan
Migrasi ke Amazon DocumentDB memerlukan pemahaman menyeluruh tentang beban kerja database yang ada. Penemuan beban kerja adalah proses menganalisis konfigurasi klaster Couchbase dan karakteristik operasional Anda — kumpulan data, indeks, dan beban kerja — untuk membantu memastikan transisi yang mulus dengan gangguan minimal.
Konfigurasi klaster
Couchbase menggunakan arsitektur service-centric di mana setiap kemampuan sesuai dengan layanan. Jalankan perintah berikut terhadap cluster Couchbase Anda untuk menentukan layanan mana yang digunakan (lihat Mendapatkan Informasi tentang Node
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
Contoh output:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
Layanan Couchbase meliputi:
Layanan data (kv)
Layanan data menyediakan read/write akses ke data dalam memori dan pada disk.
Amazon DocumentDB K/V mendukung operasi pada data JSON melalui MongoDB API.
Layanan kueri (n1ql)
Layanan query mendukung query data JSON melalui SQL++.
Amazon DocumentDB mendukung kueri data JSON melalui MongoDB API.
Layanan indeks (indeks)
Layanan indeks membuat dan memelihara indeks pada data, memungkinkan kueri lebih cepat.
Amazon DocumentDB mendukung indeks primer default dan pembuatan indeks sekunder pada data JSON melalui MongoDB API.
Layanan pencarian (fts)
Layanan pencarian mendukung pembuatan indeks untuk pencarian teks lengkap.
Fitur pencarian teks lengkap asli Amazon DocumentDB memungkinkan Anda melakukan pencarian teks pada kumpulan data tekstual besar menggunakan indeks teks tujuan khusus melalui MongoDB API. Untuk kasus penggunaan penelusuran lanjutan, integrasi Amazon DocumentDB Zero-ETL dengan OpenSearch Amazon
Layanan Analytics (cbas)
Layanan analitik mendukung analisis data JSON dalam waktu dekat.
Amazon DocumentDB mendukung kueri ad-hoc pada data JSON melalui MongoDB API. Anda juga dapat menjalankan kueri kompleks pada data JSON Anda di Amazon DocumentDB menggunakan Apache Spark yang berjalan di Amazon
Layanan eventing (eventing)
Layanan eventing mengeksekusi logika bisnis yang ditentukan pengguna dalam menanggapi perubahan data.
Amazon DocumentDB mengotomatiskan beban kerja yang digerakkan oleh peristiwa dengan AWS Lambda menjalankan fungsi setiap kali data berubah dengan cluster Amazon DocumentDB Anda.
Layanan Backup (backup)
Layanan cadangan menjadwalkan pencadangan data penuh dan tambahan dan penggabungan cadangan data sebelumnya.
Amazon DocumentDB terus mencadangkan data Anda ke Amazon S3 dengan periode retensi 1—35 hari sehingga Anda dapat dengan cepat memulihkan ke titik mana pun dalam periode retensi cadangan. Amazon DocumentDB juga mengambil snapshot otomatis data Anda sebagai bagian dari proses backup terus menerus ini. Anda juga dapat mengelola pencadangan dan pemulihan Amazon AWS Backup DocumentDB
Karakteristik operasional
Gunakan Discovery Tool for Couchbase
Kumpulan data
Alat ini mengambil bucket, cakupan, dan informasi pengumpulan berikut:
nama bucket
jenis ember
nama lingkup
nama koleksi
ukuran total (byte)
total item
ukuran item (byte)
Indeks
Alat ini mengambil statistik indeks berikut dan semua definisi indeks untuk semua bucket. Perhatikan bahwa indeks primer dikecualikan karena Amazon DocumentDB secara otomatis membuat indeks utama untuk setiap koleksi.
nama bucket
nama lingkup
nama koleksi
nama indeks
ukuran indeks (byte)
Beban kerja
Alat ini mengambil K/V dan metrik kueri N1QL. K/V nilai metrik dikumpulkan pada tingkat bucket dan metrik SQL++ dikumpulkan di tingkat cluster.
Opsi baris perintah alat adalah sebagai berikut:
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
Berikut adalah contoh perintah:
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
Nilai metrik K/V akan didasarkan pada sampel setiap 10 menit selama seminggu terakhir (lihat metode HTTP dan URI
collection-stats.csv - bucket, ruang lingkup, dan informasi pengumpulan
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv - nama indeks dan ukuran
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv - dapatkan, atur, dan hapus metrik untuk semua bucket
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv - SQL++ pilih, hapus, dan masukkan metrik untuk cluster
selects,deletes,inserts 0,132,87
indeks- .txt <bucket-name>— definisi indeks dari semua indeks dalam ember. Perhatikan bahwa indeks primer dikecualikan karena Amazon DocumentDB secara otomatis membuat indeks utama untuk setiap koleksi.
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
Perencanaan
Pada tahap perencanaan, Anda akan menentukan persyaratan klaster Amazon DocumentDB dan pemetaan bucket, cakupan, dan koleksi Couchbase ke database dan koleksi Amazon DocumentDB.
Persyaratan klaster Amazon DocumentDB
Gunakan data yang dikumpulkan dalam fase penemuan untuk mengukur cluster Amazon DocumentDB Anda. Lihat Ukuran instans untuk informasi selengkapnya tentang ukuran cluster Amazon DocumentDB Anda.
Memetakan ember, cakupan, dan koleksi ke database dan koleksi
Tentukan database dan koleksi yang akan ada di cluster Amazon DocumentDB Anda. Pertimbangkan opsi berikut tergantung pada bagaimana data diatur di cluster Couchbase Anda. Ini bukan satu-satunya pilihan, tetapi mereka memberikan titik awal untuk Anda pertimbangkan.
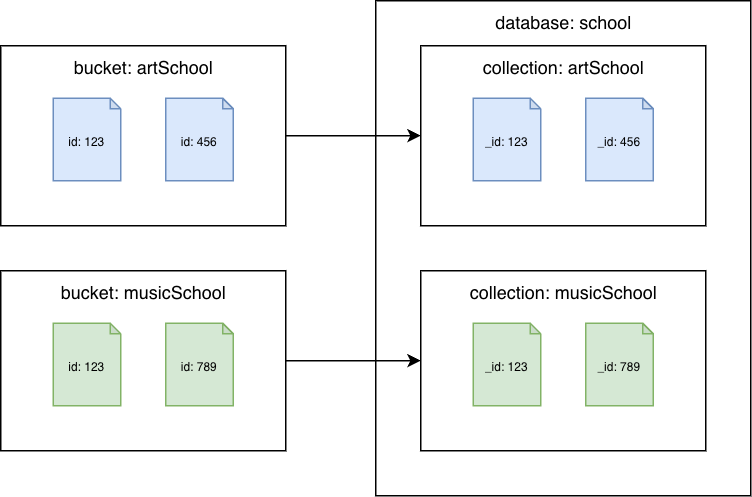
Couchbase Server 6.x atau sebelumnya
Bucket Couchbase ke koleksi Amazon DocumentDB
Migrasikan setiap bucket ke koleksi Amazon DocumentDB yang berbeda. Dalam skenario ini, id nilai dokumen Couchbase akan digunakan sebagai nilai Amazon DocumentDB. _id
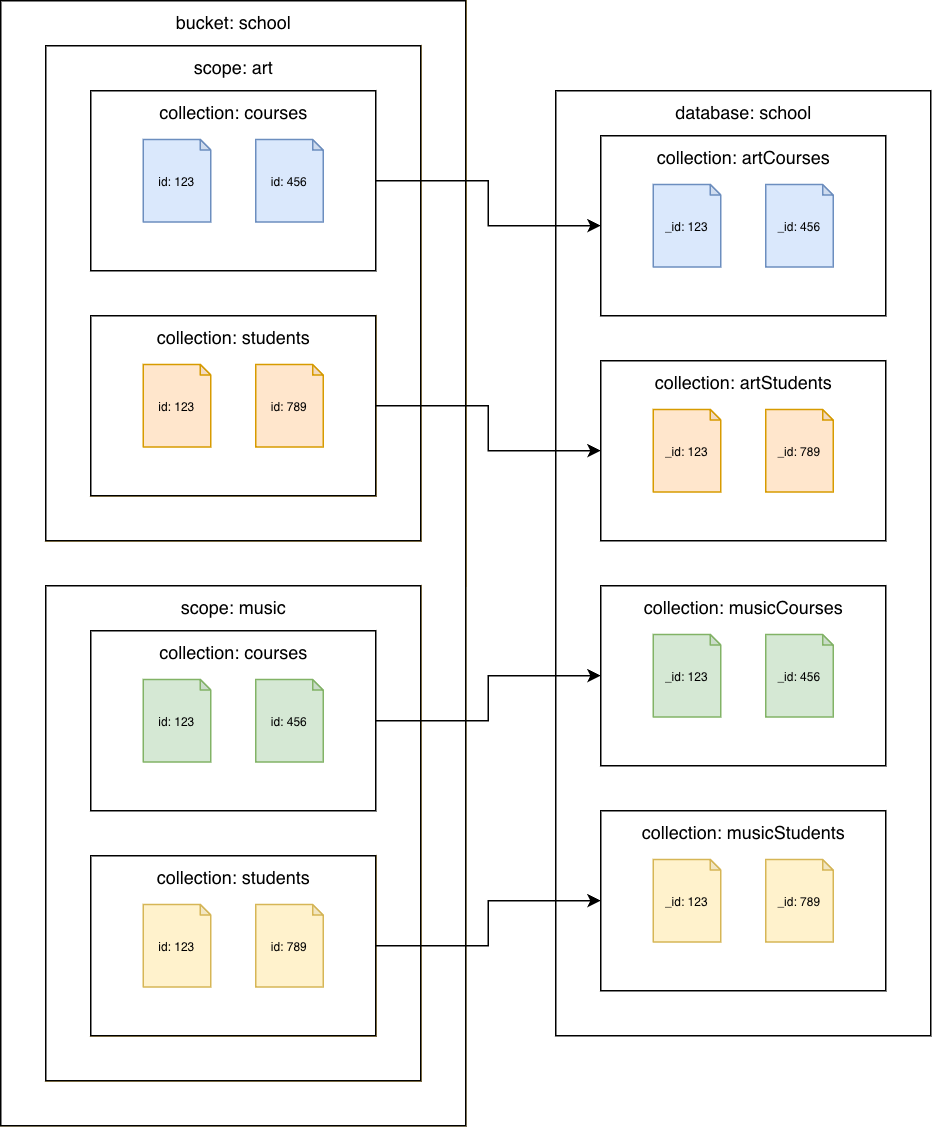
Couchbase Server 7.0 atau yang lebih baru
Koleksi Couchbase ke koleksi Amazon DocumentDB
Migrasikan setiap koleksi ke koleksi Amazon DocumentDB yang berbeda. Dalam skenario ini, id nilai dokumen Couchbase akan digunakan sebagai nilai Amazon DocumentDB. _id
Migrasi
Migrasi indeks
Migrasi ke Amazon DocumentDB melibatkan transfer tidak hanya data tetapi juga indeks untuk mempertahankan kinerja kueri dan mengoptimalkan operasi database. Bagian ini menguraikan step-by-step proses terperinci untuk memigrasikan indeks ke Amazon DocumentDB sambil memastikan kompatibilitas dan efisiensi.
Gunakan Amazon Q untuk mengonversi CREATE INDEX pernyataan SQL++ ke perintah Amazon DocumentDB. createIndex()
Unggah <bucket name>file indeks- .txt yang dibuat oleh Discovery Tool untuk Couchbase.
Masukkan prompt berikut:
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q akan menghasilkan perintah Amazon createIndex() DocumentDB yang setara. Perhatikan bahwa Anda mungkin perlu memperbarui nama koleksi berdasarkan cara Anda memetakan bucket, cakupan, dan koleksi Couchbase ke koleksi Amazon DocumentDB.
Contoh:
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Contoh keluaran Amazon Q (kutipan):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Untuk indeks apa pun yang tidak dapat dikonversi oleh Amazon Q, lihat Mengelola indeks Amazon DocumentDB dan Indeks serta properti indeks untuk informasi lebih lanjut.
Kode refactor untuk menggunakan MongoDB APIs
Klien menggunakan Couchbase SDKs untuk terhubung ke Couchbase Server. Klien Amazon DocumentDB menggunakan driver MongoDB untuk terhubung ke Amazon DocumentDB. Semua bahasa yang didukung oleh Couchbase juga SDKs didukung oleh driver MongoDB. Lihat Driver MongoDB
Karena perbedaan antara Couchbase Server dan Amazon DocumentDB, Anda perlu memfaktorkan ulang kode Anda untuk menggunakan MongoDB yang sesuai. APIs APIs Anda dapat menggunakan Amazon Q untuk mengonversi panggilan K/V API dan kueri SQL++ ke MongoDB yang setara: APIs
Unggah file kode sumber.
Masukkan prompt berikut:
Convert the Couchbase API code to Amazon DocumentDB API code
Menggunakan contoh kode Hello Couchbase Python
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Lihat Menghubungkan secara terprogram ke Amazon DocumentDB untuk contoh menghubungkan ke Amazon DocumentDB dengan Python, Node.js, PHP, Go, Java, C#/.NET, R, dan Ruby.
Pilih pendekatan migrasi
Saat memigrasikan data ke Amazon DocumentDB, ada dua opsi:
Migrasi offline
Pertimbangkan migrasi offline saat:
Waktu henti dapat diterima: Migrasi offline melibatkan penghentian operasi penulisan ke database sumber, mengekspor data, dan kemudian mengimpornya ke Amazon DocumentDB. Proses ini menimbulkan downtime untuk aplikasi Anda. Jika aplikasi atau beban kerja Anda dapat mentolerir periode tidak tersedianya ini, migrasi offline adalah opsi yang layak.
Migrasi kumpulan data yang lebih kecil atau melakukan bukti konsep: Untuk kumpulan data yang lebih kecil, waktu yang diperlukan untuk proses ekspor dan impor relatif singkat, membuat migrasi offline menjadi metode yang cepat dan sederhana. Ini juga cocok untuk pengembangan, pengujian, dan proof-of-concept lingkungan di mana downtime kurang kritis.
Kesederhanaan adalah prioritas: Metode offline, menggunakan cbexport dan mongoimport, umumnya merupakan pendekatan yang paling mudah untuk memigrasikan data. Ini menghindari kompleksitas pengambilan data perubahan (CDC) yang terlibat dalam metode migrasi online.
Tidak ada perubahan berkelanjutan yang perlu direplikasi: Jika database sumber tidak secara aktif menerima perubahan selama migrasi, atau jika perubahan tersebut tidak penting untuk ditangkap dan diterapkan ke target selama proses migrasi, maka pendekatan offline sesuai.
Couchbase Server 6.x atau sebelumnya
Bucket Couchbase ke koleksi Amazon DocumentDB
Ekspor data menggunakan cbexport json--format opsi yang dapat Anda gunakan lines ataulist.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Impor data ke koleksi Amazon DocumentDB menggunakan mongoimport dengan opsi yang sesuai untuk mengimpor baris atau daftar:
baris:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
daftar:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 atau yang lebih baru
Untuk melakukan migrasi offline, gunakan alat cbexport dan mongoimport:
Bucket Couchbase dengan cakupan default dan koleksi default
Ekspor data menggunakan cbexport json--format opsi yang dapat Anda gunakan lines ataulist.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Impor data ke koleksi Amazon DocumentDB menggunakan mongoimport dengan opsi yang sesuai untuk mengimpor baris atau daftar:
baris:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
daftar:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Koleksi Couchbase ke koleksi Amazon DocumentDB
Ekspor data menggunakan cbexport json--include-data opsi untuk mengekspor setiap koleksi. Untuk --format opsi yang dapat Anda gunakan lines ataulist. Gunakan --collection-field opsi --scope-field dan untuk menyimpan nama ruang lingkup dan koleksi di bidang yang ditentukan di setiap dokumen JSON.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
Karena cbexport menambahkan _collection bidang _scope dan ke setiap dokumen yang diekspor, Anda dapat menghapusnya dari setiap dokumen dalam file ekspor melalui pencarian dan penggantian,sed, atau metode apa pun yang Anda inginkan.
Impor data untuk setiap koleksi ke koleksi Amazon DocumentDB menggunakan mongoimport dengan opsi yang sesuai untuk mengimpor baris atau daftar:
baris:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
daftar:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Migrasi online
Pertimbangkan migrasi online saat Anda perlu meminimalkan waktu henti dan perubahan yang sedang berlangsung perlu direplikasi ke Amazon DocumentDB dalam waktu hampir nyata.
Lihat Cara melakukan migrasi langsung dari Couchbase ke Amazon DocumentDB untuk mempelajari cara melakukan migrasi langsung ke Amazon
Couchbase Server 6.x atau sebelumnya
Bucket Couchbase ke koleksi Amazon DocumentDB
Utilitas migrasi untuk Couchbasedocument.id.strategy parameter dikonfigurasi untuk menggunakan nilai kunci pesan sebagai nilai _id bidang (lihat Properti Strategi Id Konektor Sink
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 atau yang lebih baru
Bucket Couchbase dengan cakupan default dan koleksi default
Utilitas migrasi untuk Couchbasedocument.id.strategy parameter dikonfigurasi untuk menggunakan nilai kunci pesan sebagai nilai _id bidang (lihat Properti Strategi Id Konektor Sink
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Koleksi Couchbase ke koleksi Amazon DocumentDB
Konfigurasikan konektor sumber
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
Konfigurasikan konektor sink
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
Validasi
Bagian ini menyediakan proses validasi terperinci untuk memverifikasi konsistensi dan integritas data setelah bermigrasi ke Amazon DocumentDB. Langkah-langkah validasi berlaku terlepas dari metode migrasi.
Topik
Verifikasi bahwa semua koleksi ada di target
Sumber Couchbase
opsi 1: meja kerja kueri
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
opsi 2: alat cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Target Amazon DocumentDB
mongosh (lihat Connect ke cluster Amazon DocumentDB Anda):
db.getSiblingDB('<database>') db.getCollectionNames()
Verifikasi jumlah dokumen antara souce dan cluster target
Sumber Couchbase
Couchbase Server 6.x atau sebelumnya
opsi 1: meja kerja kueri
SELECT COUNT(*) FROM `<bucket>`
opsi 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 atau yang lebih baru
opsi 1: meja kerja kueri
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
opsi 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Target Amazon DocumentDB
mongosh (lihat Connect ke cluster Amazon DocumentDB Anda):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
Bandingkan dokumen antara sumber dan kelompok target
Sumber Couchbase
Couchbase Server 6.x atau sebelumnya
opsi 1: meja kerja kueri
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
opsi 2: cbq
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 atau yang lebih baru
opsi 1: meja kerja kueri
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
opsi 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Target Amazon DocumentDB
mongosh (lihat Connect ke cluster Amazon DocumentDB Anda):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
