Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan Indeks Sekunder Global untuk kueri agregasi terwujud di DynamoDB
Mempertahankan metrik kunci dan agregasi yang mendekati waktu nyata selain data yang berubah dengan cepat menjadi semakin berharga bagi bisnis untuk mengambil keputusan dengan cepat. Misalnya, perpustakaan musik mungkin ingin menampilkan lagu-lagu yang paling banyak diunduh dalam waktu nyaris nyata, atau platform e-commerce mungkin perlu menampilkan produk yang sedang tren berdasarkan kategori.
Karena DynamoDB tidak mendukung operasi agregasi secara native SUM seperti COUNT atau di seluruh item, menghitung nilai-nilai ini pada waktu baca akan memerlukan pemindaian sejumlah besar item—yang mungkin lambat dan mahal. Sebagai gantinya, Anda dapat menghitung agregasi terlebih dahulu saat data berubah dan menyimpan hasilnya sebagai item biasa di tabel Anda. Pola ini disebut agregasi terwujud.
Topik
Contoh skenario dan pola akses
Pertimbangkan aplikasi perpustakaan musik dengan persyaratan berikut:
Aplikasi ini merekam unduhan lagu individual pada volume tinggi (ribuan per detik).
Pengguna perlu melihat lagu yang paling banyak diunduh untuk bulan tertentu dengan latensi milidetik satu digit.
Aplikasi ini juga perlu mendukung pertanyaan seperti “10 lagu teratas bulan ini” dan “semua lagu yang diunduh pada bulan tertentu.”
Menghitung jumlah unduhan pada waktu baca dengan memindai semua catatan unduhan mungkin mahal pada skala ini. Sebagai gantinya, Anda dapat mempertahankan hitungan berjalan yang diperbarui saat setiap unduhan terjadi, dan menyimpannya dengan cara yang mendukung kueri yang efisien.
Mengapa agregasi pra-komputasi
Ada beberapa pendekatan untuk komputasi agregasi. Tabel berikut membandingkan alternatif umum dan menjelaskan mengapa agregasi terwujud dalam DynamoDB seringkali paling cocok untuk jenis kasus penggunaan ini.
| Pendekatan | Pengorbanan | Kapan harus digunakan |
|---|---|---|
| Pindai dan hitung pada waktu baca | Membutuhkan membaca semua catatan unduhan untuk setiap kueri. Latensi tumbuh dengan volume data dan mengkonsumsi kapasitas baca yang signifikan. | Hanya cocok untuk kumpulan data yang sangat kecil di mana latensi tidak menjadi perhatian. |
| Toko agregasi eksternal (misalnya, Amazon ElastiCache) | Menambahkan kompleksitas operasional dengan layanan terpisah untuk dikelola. Membutuhkan logika sinkronisasi antara DynamoDB dan cache. | Ketika Anda membutuhkan pembacaan sub-milidetik atau logika agregasi kompleks yang melampaui hitungan sederhana. |
| Application-level agregasi saat menulis | Memasangkan logika agregasi ke jalur tulis. Jika aplikasi gagal setelah merekam unduhan tetapi sebelum memperbarui hitungan, agregasi menjadi tidak konsisten. | Saat Anda membutuhkan agregasi yang sinkron dan sangat konsisten dan dapat mentolerir latensi penulisan tambahan. |
| Agregasi terwujud dengan Streams dan Lambda | Memisahkan agregasi dari jalur tulis. Agregasi pada akhirnya konsisten (biasanya beberapa detik di belakang). Menambahkan biaya pemanggilan Lambda. | Ketika Anda membutuhkan agregasi mendekati waktu nyata dengan latensi baca rendah dan dapat mentolerir konsistensi akhirnya. Ini adalah pendekatan yang dijelaskan di halaman ini. |
Pendekatan agregasi terwujud membuat jalur penulisan tetap sederhana (cukup rekam unduhan), menurunkan agregasi ke proses asinkron, dan menyimpan hasilnya di DynamoDB di mana ia dapat ditanyakan dengan latensi milidetik satu digit.
Desain tabel
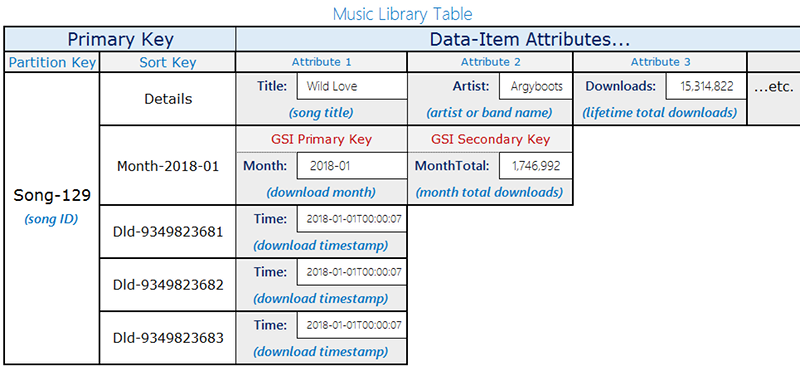
Desain ini menggunakan tabel tunggal dengan dua jenis item yang berbagi kunci partisi yang sama (songID) tetapi menggunakan pola kunci pengurutan yang berbeda untuk membedakannya:
Unduh catatan - Acara unduhan individu. Kunci sortir adalah
DownloadID(pengidentifikasi unik untuk setiap unduhan).Item agregasi bulanan — jumlah Pre-computed unduhan per lagu per bulan. Kunci sortir adalah bulan dalam
YYYY-MMformat (misalnya,2018-01). Item ini juga berisiDownloadCountatribut dengan total berjalan.
Hanya item agregasi bulanan yang berisi Month atribut. Perbedaan ini penting untuk desain GSI jarang yang dijelaskan nanti.
Diagram berikut menunjukkan tata letak tabel dengan kedua jenis item:
| Tipe barang | Kunci partisi (sonGID) | Sortir kunci | Atribut tambahan |
|---|---|---|---|
| Unduh catatan | song1 |
download-abc123 |
UserID, Timestamp |
| Agregasi bulanan | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
Pipa agregasi dengan Streams dan AWS Lambda
Pipa agregasi berfungsi sebagai berikut:
Ketika sebuah lagu diunduh, aplikasi menulis item baru ke meja dengan
Partition-Key=songIDdanSort-Key=DownloadID.DynamoDB Streams menangkap penulisan ini sebagai catatan aliran.
Fungsi Lambda, yang dilampirkan ke aliran, memproses catatan baru. Ini mengidentifikasi
songIDdan bulan berjalan, kemudian memperbarui item agregasi bulanan yang sesuai dengan menambah atribut.DownloadCountItem agregasi yang diperbarui kemudian tersedia untuk kueri melalui GSI yang jarang.
Fungsi Lambda menggunakan UpdateItem panggilan dengan ADD ekspresi untuk meningkatkan jumlah unduhan secara atom. Ini menghindari kondisi balapan baca-modify-tulis:
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
catatan
Jika eksekusi Lambda gagal setelah menulis nilai agregasi yang diperbarui, catatan aliran dapat dicoba ulang. Karena ADD operasi menambah hitungan setiap kali dijalankan, percobaan ulang akan menambah hitungan lebih dari sekali untuk unduhan yang sama, meninggalkan Anda dengan nilai perkiraan. Untuk sebagian besar kasus penggunaan analitik dan papan peringkat, margin kesalahan kecil ini dapat diterima. Jika Anda memerlukan jumlah yang tepat, pertimbangkan untuk menambahkan logika idempotensi—misalnya, dengan menggunakan ekspresi kondisi yang memeriksa apakah spesifik telah diproses. DownloadID
Desain GSI jarang
Untuk melakukan kueri hasil agregat secara efisien, buat indeks sekunder global dengan skema kunci berikut:
Kunci partisi GSI:
Month(String)Kunci sortir GSI:
DownloadCount(Nomor)
GSI ini jarang karena hanya item agregasi bulanan yang berisi atribut. Month Catatan unduhan individual tidak memiliki atribut ini, sehingga secara otomatis dikecualikan dari indeks. Ini berarti GSI hanya berisi item agregasi yang telah dihitung sebelumnya—sebagian kecil dari total item dalam tabel.
GSI yang jarang memberikan dua manfaat utama:
Biaya lebih rendah — Karena hanya item agregasi yang direplikasi ke indeks, Anda mengkonsumsi kapasitas tulis dan penyimpanan yang jauh lebih sedikit dibandingkan dengan indeks yang mencakup setiap item dalam tabel.
Kueri yang lebih cepat — Indeks hanya berisi data yang perlu Anda kueri, sehingga pembacaan efisien dan mengembalikan hasil dengan latensi milidetik satu digit.
Untuk informasi selengkapnya tentang cara kerja indeks sparse, lihat. Memanfaatkan indeks jarang
Menanyakan GSI
Dengan GSI yang jarang, Anda dapat menjawab beberapa jenis kueri secara efisien:
Dapatkan lagu yang paling banyak diunduh untuk bulan tertentu:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
Pengaturan ScanIndexForward untuk false mengurutkan hasil berdasarkan DownloadCount urutan menurun, dan hanya Limit=1 mengembalikan lagu teratas.
Dapatkan 10 lagu teratas untuk bulan tertentu:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
Dapatkan semua lagu diunduh dalam bulan tertentu (diurutkan berdasarkan jumlah unduhan):
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
Pertimbangan-pertimbangan
Ingatlah hal berikut saat menerapkan pola ini:
Konsistensi akhir - Nilai agregasi diperbarui secara asinkron melalui DynamoDB Streams dan Lambda. Biasanya ada penundaan beberapa detik antara unduhan yang direkam dan agregasi yang diperbarui. Ini berarti GSI mencerminkan data mendekati waktu nyata, bukan data waktu nyata.
Konkurensi Lambda - Jika tabel Anda memiliki volume tulis yang tinggi, beberapa pemanggilan Lambda dapat mencoba memperbarui item agregasi yang sama secara bersamaan.
ADDOperasi atom menangani ini dengan aman, tetapi Anda harus memantau metrik konkurensi dan pelambatan Lambda untuk memastikan fungsi Anda dapat mengikuti aliran.Kapasitas tulis GSI - Karena GSI jarang hanya berisi item agregasi, ini membutuhkan kapasitas tulis yang jauh lebih sedikit daripada tabel dasar. Namun, Anda tetap harus menyediakan kapasitas yang cukup (atau menggunakan mode sesuai permintaan) untuk menangani tingkat pembaruan agregasi.
Perkiraan hitungan - Seperti disebutkan sebelumnya, percobaan ulang Lambda dapat menyebabkan jumlah menjadi sedikit terlalu banyak dihitung. Untuk kasus penggunaan yang memerlukan jumlah pasti, terapkan pemeriksaan idempotensi dalam fungsi Lambda.
