Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Alih-alih mereplikasi seluruh database, Anda dapat menerapkan satu atau beberapa filter untuk secara selektif menyertakan atau mengecualikan tabel tertentu. Ini membantu Anda mengoptimalkan kinerja penyimpanan dan kueri dengan memastikan bahwa hanya data yang relevan yang ditransfer. Saat ini, penyaringan terbatas pada tingkat database dan tabel. Pemfilteran tingkat kolom dan baris tidak didukung.
Pemfilteran data dapat berguna ketika Anda ingin:
-
Menghemat biaya dengan melakukan analisis hanya menggunakan subset tabel daripada seluruh armada database.
-
Saring informasi sensitif—seperti nomor telepon, alamat, atau detail kartu kredit—dari tabel tertentu.
Anda dapat menambahkan filter data ke integrasi nol-ETL menggunakan, AWS Command Line Interface (AWS CLI) Konsol Manajemen AWS, atau Amazon RDS API.
Jika integrasi memiliki cluster yang disediakan sebagai targetnya, cluster harus berada di patch 180 atau lebih tinggi untuk menggunakan pemfilteran data.
Topik
Format filter data
Anda dapat menentukan beberapa filter untuk satu integrasi. Setiap filter menyertakan atau mengecualikan tabel database yang ada dan masa depan yang cocok dengan salah satu pola dalam ekspresi filter. Integrasi Amazon RDS Zero-ETL menggunakan sintaks filter Maxwell untuk pemfilteran data.
Setiap filter memiliki elemen-elemen berikut:
| Elemen | Deskripsi |
|---|---|
| Jenis filter |
Jenis |
| Ekspresi filter |
Daftar pola yang dipisahkan koma. Ekspresi harus menggunakan sintaks filter Maxwell |
| Pola |
Anda dapat menentukan nama literal, atau menentukan ekspresi reguler. catatanUntuk , ekspresi reguler didukung dalam database dan nama tabel. Untuk , ekspresi reguler hanya didukung dalam skema dan nama tabel, bukan dalam nama database. Anda tidak dapat menyertakan filter tingkat kolom atau daftar denylist. Integrasi tunggal dapat memiliki maksimum 99 pola total. Di konsol, Anda dapat memasukkan pola dalam satu ekspresi filter, atau menyebarkannya di antara beberapa ekspresi. Pola tunggal tidak dapat melebihi 256 karakter panjangnya. |
penting
Jika Anda memilih sumber , Anda harus menentukan setidaknya satu pola filter data. Minimal, pola harus menyertakan database tunggal (database-name.*.*
Gambar berikut menunjukkan struktur di konsol:
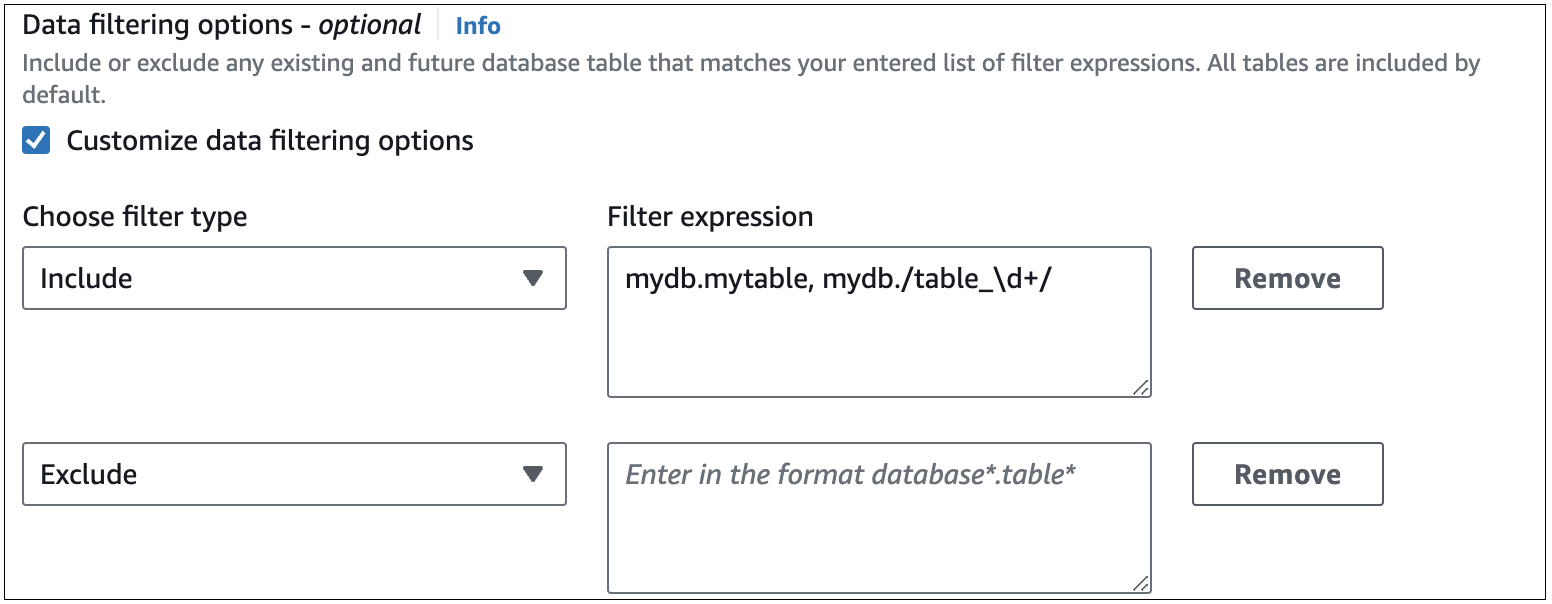
penting
Jangan sertakan informasi identitas pribadi, rahasia, atau sensitif dalam pola filter Anda.
Filter data di AWS CLI
Saat menggunakan AWS CLI untuk menambahkan filter data, sintaksnya sedikit berbeda dari konsol. Anda harus menetapkan jenis filter (IncludeatauExclude) untuk setiap pola satu per satu, sehingga Anda tidak dapat mengelompokkan beberapa pola di bawah satu jenis filter.
Misalnya, di konsol Anda dapat mengelompokkan pola dipisahkan koma berikut di bawah satu Include pernyataan:
mydb.mytable,mydb./table_\d+/
mydb.myschema.mytable,mydb.myschema./table_\d+/
Namun, saat menggunakan AWS CLI, filter data yang sama harus dalam format berikut:
'include:mydb.mytable, include:mydb./table_\d+/'
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Filter logika
Jika Anda tidak menentukan filter data apa pun dalam integrasi Anda, Amazon RDS mengasumsikan filter include:*.* default, yang mereplikasi semua tabel ke gudang data target. Namun, jika Anda menambahkan setidaknya satu filter, logika default beralih keexclude:*.*, yang mengecualikan semua tabel secara default. Ini memungkinkan Anda secara eksplisit menentukan database dan tabel mana yang akan disertakan dalam replikasi.
Misalnya, jika Anda menentukan filter berikut:
'include: db.table1, include: db.table2'
Amazon RDS mengevaluasi filter sebagai berikut:
'exclude:*.*, include: db.table1, include: db.table2'
Oleh karena itu, Amazon RDS hanya table1 mereplikasi table2 dan dari database db bernama ke gudang data target.
Filter prioritas
Amazon RDS mengevaluasi filter data dalam urutan yang Anda tentukan. Dalam Konsol Manajemen AWS, ia memproses ekspresi filter dari kiri ke kanan dan atas ke bawah. Filter kedua atau pola individual yang mengikuti yang pertama dapat menimpanya.
Misalnya, jika filter pertama adalahInclude books.stephenking, itu hanya mencakup stephenking tabel dari books database. Namun, jika Anda menambahkan filter keduaExclude books.*, itu akan menggantikan filter pertama. Ini mencegah tabel apa pun dari books indeks direplikasi ke gudang data target.
Ketika Anda menentukan setidaknya satu filter, logika dimulai dengan mengasumsikan secara exclude:*.* default, yang secara otomatis mengecualikan semua tabel dari replikasi. Sebagai praktik terbaik, tentukan filter dari yang paling luas hingga yang paling spesifik. Mulailah dengan satu atau beberapa Include pernyataan untuk menentukan data yang akan direplikasi, lalu tambahkan Exclude filter untuk menghapus tabel tertentu secara selektif.
Prinsip yang sama berlaku untuk filter yang Anda definisikan menggunakan AWS CLI. Amazon RDS mengevaluasi pola filter ini dalam urutan yang Anda tentukan, sehingga sebuah pola dapat menggantikan pola yang Anda tentukan sebelumnya.
Contoh berikut menunjukkan cara kerja penyaringan data untuk contoh nol-ETL:
-
Sertakan semua database dan semua tabel:
'include: *.*' -
Sertakan semua tabel dalam
booksdatabase:'include: books.*' -
Kecualikan tabel apa pun bernama
mystery:'include: *.*, exclude: *.mystery' -
Sertakan dua tabel spesifik dalam
booksdatabase:'include: books.stephen_king, include: books.carolyn_keene' -
Sertakan semua tabel dalam
booksdatabase, kecuali yang berisi substringmystery:'include: books.*, exclude: books./.*mystery.*/' -
Sertakan semua tabel dalam
booksdatabase, kecuali yang dimulai denganmystery:'include: books.*, exclude: books./mystery.*/' -
Sertakan semua tabel dalam
booksdatabase, kecuali yang diakhiri denganmystery:'include: books.*, exclude: books./.*mystery/' -
Sertakan semua tabel dalam
booksdatabase yang dimulai dengantable_, kecuali yang bernamatable_stephen_king. Misalnya,table_moviesatautable_booksakan direplikasi, tetapi tidaktable_stephen_king.'include: books./table_.*/, exclude: books.table_stephen_king'
Contoh berikut menunjukkan cara kerja penyaringan data untuk PostgreSQL Zero-ETL:
-
Sertakan semua tabel dalam
booksdatabase:'include: books.*.*' -
Kecualikan tabel apa pun yang disebutkan
mysterydalambooksdatabase:'include: books.*.*, exclude: books.*.mystery' -
Sertakan satu tabel dalam
booksdatabase dalammysteryskema, dan satu tabel dalamemployeedatabase dalamfinanceskema:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Sertakan semua tabel dalam
booksdatabase danscience_fictionskema, kecuali yang berisi substringking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Sertakan semua tabel dalam
booksdatabase, kecuali yang memiliki nama skema yang dimulai dengansci:'include: books.*.*, exclude: books./sci.*/.*' -
Sertakan semua tabel dalam
booksdatabase, kecuali yang ada dimysteryskema yang diakhiri denganking:'include: books.*.*, exclude: books.mystery./.*king/' -
Sertakan semua tabel dalam
booksdatabase yang dimulai dengantable_, kecuali yang bernamatable_stephen_king. Misalnya,table_moviesdalamfictionskema dantable_booksskema direplikasi, tetapi tidaktable_stephen_kingdi salah satumysteryskema:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
RDS untuk contoh Oracle
Contoh berikut menunjukkan cara kerja penyaringan data untuk RDS untuk integrasi Nol-ETL Oracle:
-
Sertakan semua tabel dalam database buku:
'include: books.*.*' -
Kecualikan setiap tabel bernama misteri dalam database buku:
'include: books.*.*, exclude: books.*.mystery' -
Sertakan satu tabel dalam database buku dalam skema misteri, dan satu tabel dalam database karyawan dalam skema keuangan:
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Sertakan semua tabel dalam skema misteri dalam database buku:
'include: books.mystery.*'
Pertimbangan sensitivitas kasus
Oracle Database dan Amazon Redshift menangani casing nama objek secara berbeda, yang memengaruhi konfigurasi filter data dan kueri target. Perhatikan hal-hal berikut:
-
Oracle Database menyimpan database, skema, dan nama objek dalam huruf besar kecuali secara eksplisit dikutip dalam pernyataan.
CREATEMisalnya, jika Anda membuatmytable(tanpa tanda kutip), kamus data Oracle menyimpan nama tabel sebagaiMYTABLE. Jika Anda mengutip nama objek, kamus data mempertahankan kasus ini. -
Zero-ETL filter data peka huruf besar/kecil dan harus sesuai dengan kasus nama objek yang tepat seperti yang muncul di kamus data Oracle.
-
Amazon Redshift menanyakan default ke nama objek huruf kecil kecuali dikutip secara eksplisit. Misalnya, kueri
MYTABLE(tanpa tanda kutip) mencarimytable.
Perhatikan perbedaan kasus saat Anda membuat filter Amazon Redshift dan menanyakan datanya.
Membuat integrasi huruf besar
Ketika Anda membuat tabel tanpa menentukan nama dalam tanda kutip ganda, database Oracle menyimpan nama dalam huruf besar dalam kamus data. Misalnya, Anda dapat membuat MYTABLE menggunakan salah satu pernyataan SQL berikut.
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Karena Anda tidak mengutip nama tabel dalam pernyataan sebelumnya, database Oracle menyimpan nama objek dalam huruf besar sebagai. MYTABLE
Untuk mereplikasi tabel ini ke Amazon Redshift, Anda harus menentukan nama huruf besar di filter data perintah Anda. create-integration Nama Zero-ETL filter dan nama kamus data Oracle harus cocok.
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
Secara default, Amazon Redshift menyimpan data dalam huruf kecil. Untuk melakukan kueri MYTABLE dalam database yang direplikasi di Amazon Redshift, Anda harus mengutip MYTABLE nama huruf besar sehingga cocok dengan kasus di kamus data Oracle.
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
Kueri berikut tidak menggunakan mekanisme kutipan. Mereka semua mengembalikan kesalahan karena mereka mencari tabel Amazon Redshift bernamamytable, yang menggunakan nama huruf kecil default, tetapi tabel tersebut dinamai MYTABLE dalam kamus data Oracle.
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
Kueri berikut menggunakan mekanisme kutipan untuk menentukan nama kasus campuran. Semua kueri mengembalikan kesalahan karena mereka mencari tabel Amazon Redshift yang tidak diberi nama. MYTABLE
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
Membuat integrasi huruf kecil
Dalam contoh alternatif berikut, Anda menggunakan tanda kutip ganda untuk menyimpan nama tabel dalam huruf kecil di kamus data Oracle. Anda membuat mytable sebagai berikut.
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Database Oracle menyimpan nama tabel seperti mytable dalam huruf kecil. Untuk mereplikasi tabel ini ke Amazon Redshift, Anda harus menentukan mytable nama huruf kecil di filter data Anda. Zero-ETL
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Saat Anda menanyakan tabel ini di database yang direplikasi di Amazon Redshift, Anda dapat menentukan nama huruf kecil. mytable Query berhasil karena mencari tabel bernamamytable, yang merupakan nama tabel dalam kamus data Oracle.
SELECT * FROM targetdb1."REINVENT".mytable;
Karena Amazon Redshift default ke nama objek huruf kecil, kueri berikut juga berhasil ditemukan. mytable
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
Kueri berikut menggunakan mekanisme kutipan untuk nama objek. Mereka semua mengembalikan kesalahan karena mereka mencari tabel Amazon Redshift yang namanya berbeda dari. mytable
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
Buat tabel dengan integrasi kasus campuran
Dalam contoh berikut, Anda menggunakan tanda kutip ganda untuk menyimpan nama tabel dalam huruf kecil di kamus data Oracle. Anda membuat MyTable sebagai berikut.
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Database Oracle menyimpan nama tabel ini seperti MyTable halnya kasus campuran. Untuk mereplikasi tabel ini ke Amazon Redshift, Anda harus menentukan nama kasus campuran dalam filter data.
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Saat Anda menanyakan tabel ini di database yang direplikasi di Amazon Redshift, Anda harus menentukan MyTable nama kasus campuran dengan mengutip nama objek.
SELECT * FROM targetdb1."REINVENT"."MyTable";
Karena Amazon Redshift default ke nama objek huruf kecil, kueri berikut tidak menemukan objek karena mereka mencari nama huruf kecil. mytable
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
catatan
Anda tidak dapat menggunakan ekspresi reguler dalam nilai filter untuk nama database, skema, atau nama tabel di RDS untuk integrasi Oracle.
Menambahkan filter data ke integrasi
Anda dapat mengonfigurasi pemfilteran data menggunakan Konsol Manajemen AWS, API AWS CLI, atau Amazon RDS.
penting
Jika Anda menambahkan filter setelah membuat integrasi, Amazon RDS memperlakukannya seolah-olah selalu ada. Ini menghapus data apa pun di gudang data target yang tidak cocok dengan kriteria pemfilteran baru dan menyinkronkan ulang semua tabel yang terpengaruh.
Untuk menambahkan filter data ke integrasi nol-ETL
Masuk ke Konsol Manajemen AWS dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Di panel navigasi, pilih Zero-ETL integrasi. Pilih integrasi yang ingin Anda tambahkan filter data, lalu pilih Ubah.
-
Di bawah Sumber, tambahkan satu atau lebih
IncludedanExcludepernyataan.Gambar berikut menunjukkan contoh filter data untuk integrasi MySQL:
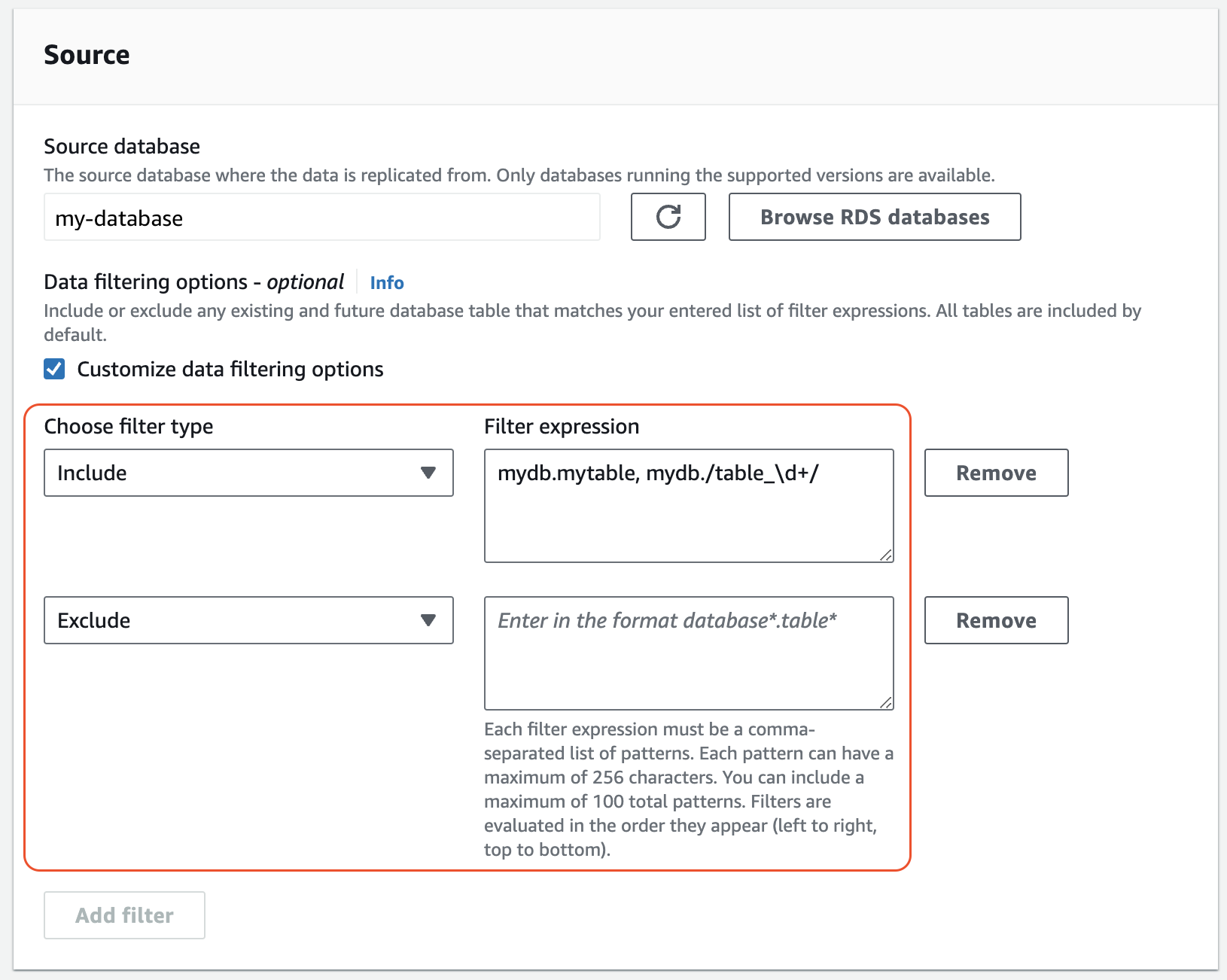
-
Jika Anda puas dengan perubahan, pilih Lanjutkan dan Simpan perubahan.
Untuk menambahkan filter data ke integrasi nol-ETL menggunakan AWS CLI, panggil perintah modify-integration.--data-filter parameter dengan daftar filter Maxwell yang dipisahkan koma. Include Exclude
contoh
Contoh berikut menambahkan pola filter kemy-integration.
Untuk Linux, macOS, atau Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Untuk Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Untuk memodifikasi integrasi nol-ETL menggunakan RDS API, panggil operasi. ModifyIntegration Tentukan pengidentifikasi integrasi dan berikan daftar pola filter yang dipisahkan koma.
Menghapus filter data dari integrasi
Saat Anda menghapus filter data dari integrasi, Amazon RDS mengevaluasi kembali filter yang tersisa seolah-olah filter yang dihapus tidak pernah ada. Kemudian mereplikasi data yang sebelumnya dikecualikan yang sekarang memenuhi kriteria ke dalam gudang data target. Ini memicu sinkronisasi ulang semua tabel yang terpengaruh.
