Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menambahkan data ke sumber Klaster DB Aurora dan menanyakannya
Untuk menyelesaikan pembuatan integrasi nol-ETL yang mereplikasi data dari Amazon Aurora ke Amazon Redshift, Anda harus membuat database di tujuan target.
Untuk koneksi dengan Amazon Redshift, sambungkan ke klaster atau grup kerja Amazon Redshift Anda dan buat database dengan referensi ke pengenal integrasi Anda. Kemudian, Anda dapat menambahkan data ke sumber Anda Aurora DB cluster dan melihatnya direplikasi di Amazon Redshift atau. Amazon SageMaker
Topik
Membuat database target
Sebelum Anda dapat mulai mereplikasi data ke Amazon Redshift, setelah Anda membuat integrasi, Anda harus membuat database di gudang data target Anda. Database ini harus menyertakan referensi ke identifier integrasi. Anda dapat menggunakan konsol Amazon Redshift atau Editor kueri v2 untuk membuat basis data.
Untuk petunjuk cara membuat basis data tujuan, lihat Membuat basis data tujuan di Amazon Redshift.
Menambahkan data ke sumbernya Klaster DB
Setelah Anda mengkonfigurasi integrasi Anda, Anda dapat mengisi sumber DB cluster dengan data yang ingin Anda replikasi ke gudang data Anda.
catatan
Ada perbedaan antara tipe data di Aurora dan gudang analitik target. Untuk tabel pemetaan jenis data, lihat Perbedaan tipe data antara Aurora dan basis data Amazon Redshift.
Pertama, sambungkan ke cluster DB sumber menggunakan klien MySQL atau PostgreSQL pilihan Anda. Untuk petunjuk, lihat Menghubungkan ke klaster DB Amazon Aurora.
Kemudian, buat tabel dan masukkan urutan data sampel.
penting
Pastikan tabel memiliki kunci primer. Jika tidak, tabel tidak dapat direplikasi ke gudang data target.
Utilitas pg_dump dan pg_restore PostgreSQL awalnya membuat tabel tanpa kunci utama dan kemudian menambahkannya setelahnya. Jika Anda menggunakan salah satu utilitas ini, sebaiknya buat skema terlebih dahulu, lalu muat data dalam perintah terpisah.
MySQL RDS untuk
Contoh berikut menggunakan utilitas MySQL Workbench
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
PostgreSQL
Contoh berikut menggunakan terminal interaktif PostgreSQL psql. Saat menghubungkan ke klaster, sertakan basis data bernama yang Anda tentukan saat membuat integrasi.
psql -hmycluster.cluster-123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Menanyakan Aurora data di Amazon Redshift
Setelah Anda menambahkan data ke Aurora DB cluster, itu direplikasi ke database tujuan dan siap untuk ditanyakan.
Untuk mengueri data yang direplikasi
-
Buka konsol Amazon Redshift dan pilih Editor kueri v2 dari panel navigasi kiri.
-
Hubungkan ke klaster atau grup kerja Anda dan pilih basis data tujuan Anda (yang Anda buat dari integrasi) dari menu dropdown (destination_database dalam contoh ini). Untuk petunjuk cara membuat basis data tujuan, lihat Membuat basis data tujuan di Amazon Redshift.
-
Gunakan pernyataan SELECT untuk menanyakan data Anda. Dalam contoh ini, Anda dapat menjalankan perintah berikut untuk memilih semua data dari tabel yang Anda buat di sumber Aurora DB cluster:
SELECT * frommy_db."books_table";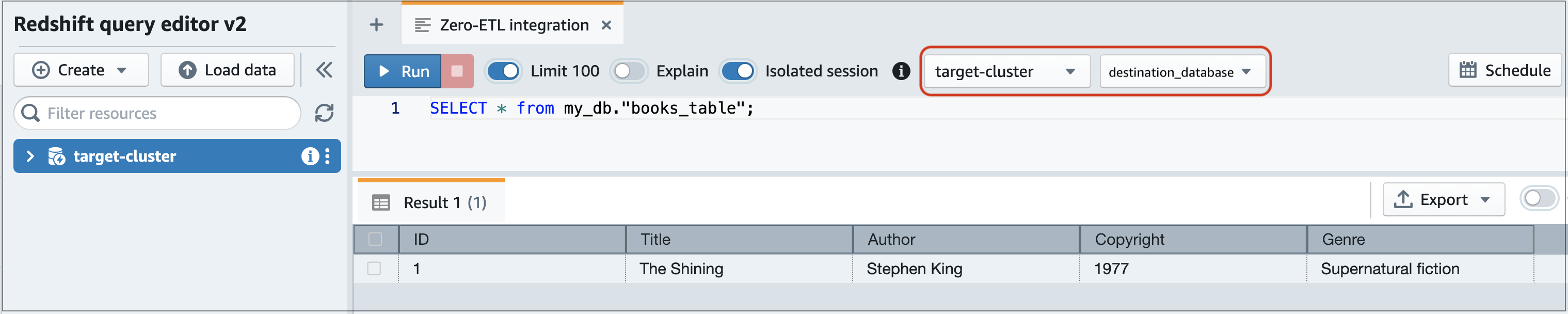
-
my_db -
books_table
-
Anda juga dapat menanyakan data menggunakan klien baris perintah. Contoh:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
catatan
Untuk kepekaan huruf besar/kecil, gunakan tanda kutip ganda (" ") untuk nama skema, tabel, dan kolom. Untuk informasi selengkapnya, lihat enable_case_sensitive_identifier.
Perbedaan tipe data antara Aurora dan basis data Amazon Redshift
tipe data untuk tipe data tujuan yang sesuai. Amazon Aurora saat ini hanya mendukung jenis data ini untuk integrasi nol-ETL.
Jika tabel di cluster DB sumber Anda menyertakan tipe data yang tidak didukung, tabel tidak sinkron dan tidak dapat dikonsumsi oleh target tujuan. Streaming dari sumber ke target berlanjut, tetapi tabel dengan jenis data yang tidak didukung tidak tersedia. Untuk memperbaiki tabel dan membuatnya tersedia di tujuan target, Anda harus secara manual mengembalikan perubahan yang melanggar dan kemudian menyegarkan integrasi dengan menjalankanALTER DATABASE...INTEGRATION
REFRESH.
catatan
Anda tidak dapat menyegarkan integrasi nol-ETL dengan lakehouse. Amazon SageMaker Sebagai gantinya, hapus dan coba buat integrasi lagi.
Aurora MySQL
| Jenis data Aurora MySQL | Jenis data target | Deskripsi | Batasan |
|---|---|---|---|
| INT | INTEGER | Bilangan bulat empat byte bertanda | Tidak ada |
| SMALLINT | SMALLINT | Bilangan bulat dua byte bertanda | Tidak ada |
| TINYINT | SMALLINT | Bilangan bulat dua byte bertanda | Tidak ada |
| MEDIUMINT | INTEGER | Bilangan bulat empat byte bertanda | Tidak ada |
| BIGINT | BIGINT | Bilangan bulat delapan byte bertanda | Tidak ada |
| INT UNSIGNED | BIGINT | Bilangan bulat delapan byte bertanda | Tidak ada |
| TINYINT UNSIGNED | SMALLINT | Bilangan bulat dua byte bertanda | Tidak ada |
| MEDIUMINT UNSIGNED | INTEGER | Bilangan bulat empat byte bertanda | Tidak ada |
| BIGINT UNSIGNED | DECIMAL(20,0) | Numerik persis dari presisi yang dapat dipilih | Tidak ada |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | Numerik persis dari presisi yang dapat dipilih |
Presisi lebih besar dari 38 dan penskalaan lebih besar dari 37 tidak didukung |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | Numerik persis dari presisi yang dapat dipilih |
Presisi lebih besar dari 38 dan penskalaan lebih besar dari 37 tidak didukung |
| FLOAT4/REAL | REAL | Angka floating-point presisi tunggal | Tidak ada |
| FLOAT4/REAL TIDAK DITANDATANGANI | REAL | Angka floating-point presisi tunggal | Tidak ada |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Angka floating-point presisi ganda | Tidak ada |
| DOUBLE/REAL/FLOAT8 TIDAK DITANDATANGANI | DOUBLE PRECISION | Angka floating-point presisi ganda | Tidak ada |
| BIT(n) | VARBYTE(8) | Variable-length nilai biner | Tidak ada |
| BINER (n) | VARBYTE(n) | Variable-length nilai biner | Tidak ada |
| VARBINER (n) | VARBYTE(n) | Variable-length nilai biner | Tidak ada |
| CHAR(n) | VARCHAR(n) | Variable-length nilai string | Tidak ada |
| VARCHAR(n) | VARCHAR(n) | Variable-length nilai string | Tidak ada |
| TEXT | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| TINYTEXT | VARCHAR(255) | Variable-length nilai string hingga 255 karakter | Tidak ada |
| MEDIUMTEXT | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| LONGTEXT | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| ENUM | VARCHAR(1020) | Variable-length nilai string hingga 1.020 karakter | Tidak ada |
| SET | VARCHAR(1020) | Variable-length nilai string hingga 1.020 karakter | Tidak ada |
| DATE | DATE | Tanggal kalender (tahun, bulan, hari) | Tidak ada |
| DATETIME | TIMESTAMP | Tanggal dan waktu (tanpa zona waktu) | Tidak ada |
| TIMESTAMP(p) | TIMESTAMP | Tanggal dan waktu (tanpa zona waktu) | Tidak ada |
| TIME | VARCHAR(18) | Variable-length nilai string hingga 18 karakter | Tidak ada |
| YEAR | VARCHAR(4) | Variable-length nilai string hingga 4 karakter | Tidak ada |
| JSON | SUPER | Data atau dokumen semi-terstruktur sebagai nilai | Tidak ada |
Aurora PostgreSQL
Zero-ETL integrasi untuk tidak mendukung tipe data kustom atau tipe data yang dibuat oleh ekstensi.
| Jenis data Amazon Redshift | Deskripsi | Batasan | |
|---|---|---|---|
| array | SUPER | Data atau dokumen semi-terstruktur sebagai nilai | Tidak ada |
| bigint | BIGINT | Bilangan bulat delapan byte bertanda | Tidak ada |
| bigserial | BIGINT | Bilangan bulat delapan byte bertanda | Tidak ada |
| bit varying(n) | VARBYTE(n) | Variable-length nilai biner hingga 16.777.216 byte | Tidak ada |
| bit(n) | VARBYTE(n) | Variable-length nilai biner hingga 16.777.216 byte | Tidak ada |
| sedikit, sedikit bervariasi | VARBYTE (16777216) | Variable-length nilai biner hingga 16.777.216 byte | Tidak ada |
| boolean | BOOLEAN | Boolean logis () true/false | Tidak ada |
| bytea | VARBYTE (16777216) | Variable-length nilai biner hingga 16.777.216 byte | Tidak ada |
| arang (n) | CHAR(n) | Fixed-length nilai string karakter hingga 65.535 byte | Tidak ada |
| char bervariasi (n) | VARCHAR(65535) | Variable-length nilai string karakter hingga 65.535 karakter | Tidak ada |
| cid | BIGINT |
Bilangan bulat delapan byte bertanda |
Tidak ada |
| cidr |
VARCHAR(19) |
Variable-length nilai string hingga 19 karakter |
Tidak ada |
| date | DATE | Tanggal kalender (tahun, bulan, hari) |
Nilai lebih besar dari 294.276 A.D. tidak didukung |
| double precision | DOUBLE PRECISION | Angka floating-point presisi ganda | Nilai subnormal tidak sepenuhnya didukung |
|
gtsvektor |
VARCHAR(65535) |
Variable-length nilai string hingga 65.535 karakter |
Tidak ada |
| inet |
VARCHAR(19) |
Variable-length nilai string hingga 19 karakter |
Tidak ada |
| integer | INTEGER | Bilangan bulat empat byte bertanda | Tidak ada |
|
int2vektor |
SUPER | Data atau dokumen semi-terstruktur sebagai nilai. | Tidak ada |
| interval | INTERVAL | Durasi waktu | Hanya jenis INTERVAL yang menentukan tahun ke bulan atau hari ke kualifikasi kedua yang didukung. |
| json | SUPER | Data atau dokumen semi-terstruktur sebagai nilai | Tidak ada |
| jsonb | SUPER | Data atau dokumen semi-terstruktur sebagai nilai | Tidak ada |
| jsonpath | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
|
macaddr |
VARCHAR (17) | Variable-length nilai string hingga 17 karakter | Tidak ada |
|
macaddr8 |
VARCHAR (23) | Variable-length nilai string hingga 23 karakter | Tidak ada |
| money | DECIMAL(20,3) | Jumlah mata uang | Tidak ada |
| name | VARCHAR (64) | Variable-length nilai string hingga 64 karakter | Tidak ada |
| numeric(p,s) | DECIMAL(p,s) | User-defined nilai presisi tetap |
|
| oid | BIGINT | Bilangan bulat delapan byte bertanda | Tidak ada |
| oidvektor | SUPER | Data atau dokumen semi-terstruktur sebagai nilai. | Tidak ada |
| pg_brin_bloom_summary | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| pg_dependencies | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| pg_lsn | VARCHAR (17) | Variable-length nilai string hingga 17 karakter | Tidak ada |
| pg_mcv_list | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| pg_ndistinct | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| pg_node_pohon | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| pg_snapshot | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| real | REAL | Angka floating-point presisi tunggal | Nilai subnormal tidak sepenuhnya didukung |
| refkursor | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| smallint | SMALLINT | Bilangan bulat dua byte bertanda | Tidak ada |
| smallserial | SMALLINT | Bilangan bulat dua byte bertanda | Tidak ada |
| serial | INTEGER | Bilangan bulat empat byte bertanda | Tidak ada |
| text | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| masa | VARCHAR (23) | Variable-length nilai string hingga 23 karakter | Tidak ada |
| waktu [(p)] tanpa zona waktu | VARCHAR(19) | Variable-length nilai string hingga 19 karakter | Nilai Infinity dan -Infinity tidak didukung |
| time [(p)] with time zone | VARCHAR(22) | Variable-length nilai string hingga 22 karakter | Nilai Infinity dan -Infinity tidak didukung |
| stempel waktu [(p)] tanpa zona waktu | TIMESTAMP | Tanggal dan waktu (tanpa zona waktu) |
|
| timestamp [(p)] with time zone | TIMESTAMPTZ | Tanggal dan waktu (dengan zona waktu) |
|
| tsquery | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| tsvektor | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| txid_snapshot | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
| uuid | VARCHAR (36) | Variable-length 36 string karakter | Tidak ada |
| xid | BIGINT | Bilangan bulat delapan byte bertanda | Tidak ada |
| xid8 | DESIMAL (20, 0) | Desimal presisi tetap | Tidak ada |
| xml | VARCHAR(65535) | Variable-length nilai string hingga 65.535 karakter | Tidak ada |
Operasi DDL untuk Aurora PostgreSQL
Zero-ETL integrasi memanfaatkan kesamaan ini untuk merampingkan replikasi data dari RDS untuk ke Amazon Redshift, memetakan database berdasarkan nama dan memanfaatkan database bersama, skema, dan struktur tabel.
Pertimbangkan poin-poin berikut saat mengelola Zero-ETL:
-
Isolasi dikelola di tingkat database.
-
Replikasi terjadi pada tingkat database.
-
Aurora PostgreSQL database PostgreSQL dipetakan ke database Amazon Redshift berdasarkan nama, dengan data mengalir ke database Redshift yang berganti nama sesuai jika aslinya diganti namanya.
Terlepas dari kesamaan mereka, Amazon Redshift memiliki perbedaan penting. Bagian berikut menguraikan respons sistem Amazon Redshift untuk operasi DDL umum.
Operasi basis data
Tabel berikut menunjukkan respon sistem untuk operasi DDL database.
| Operasi DDL | Respon sistem Redshift |
|---|---|
CREATE DATABASE |
Tidak ada operasi |
DROP DATABASE |
Amazon Redshift menghapus semua data dalam database Redshift target. |
RENAME DATABASE |
Amazon Redshift menghapus semua data dalam database target asli dan menyinkronkan ulang data dalam database target baru. Jika database baru tidak ada, Anda harus membuatnya secara manual. Untuk petunjuknya, lihat Membuat database tujuan di Amazon Redshift. |
Operasi skema
Tabel berikut menunjukkan respon sistem untuk operasi skema DDL.
| Operasi DDL | Respon sistem Redshift |
|---|---|
CREATE SCHEMA |
Tidak ada operasi |
DROP SCHEMA |
Amazon Redshift menjatuhkan skema asli. |
RENAME SCHEMA |
Amazon Redshift menghapus skema asli lalu menyinkronkan ulang data dalam skema baru. |
Operasi tabel
Tabel berikut menunjukkan respon sistem untuk operasi tabel DDL.
| Operasi DDL | Respon sistem Redshift |
|---|---|
CREATE TABLE |
Amazon Redshift membuat tabel. Beberapa operasi menyebabkan pembuatan tabel gagal, seperti membuat tabel tanpa kunci utama atau melakukan partisi deklaratif. Untuk informasi selengkapnya, lihat Batasan dan Memecahkan masalah integrasi . |
DROP TABLE |
Amazon Redshift menjatuhkan meja. |
TRUNCATE TABLE |
Amazon Redshift memotong tabel. |
ALTER TABLE
(RENAME...) |
Amazon Redshift mengganti nama tabel atau kolom. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift menjatuhkan tabel dalam skema asli dan menyinkronkan ulang tabel dalam skema baru. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift menambahkan kunci utama dan menyinkronkan ulang tabel. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift menambahkan kolom ke tabel. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift menjatuhkan kolom jika bukan kolom kunci utama. Jika tidak, itu menyinkronkan ulang tabel. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
Jika Anda mengubah tabel menjadi login, Amazon Redshift akan menyinkronkan ulang tabel. Jika Anda mengubah tabel menjadi tidak tercatat, Amazon Redshift akan menjatuhkan tabel. |
