Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Doa Model
CloudWatch observabilitas AI generatif memungkinkan Anda memantau kinerja Model Invocations. Anda dapat melacak metrik seperti jumlah pemanggilan, penggunaan token, dan kesalahan menggunakan tampilan out-of-box. Untuk visibilitas mendetail ke dalam konten pemanggilan, seperti input dan output, aktifkan logging Pemanggilan Batuan Dasar dan kirim log ke. CloudWatch Untuk informasi selengkapnya, lihat Menyiapkan tujuan CloudWatch Log dan Membantu melindungi data log sensitif dengan masking.
Mengaktifkan pemanggilan model di Amazon Bedrock
catatan
Anda harus mengaktifkan pencatatan pemanggilan Model di Amazon Bedrock untuk melihat pemanggilan.
Untuk mengaktifkan pencatatan pemanggilan model di Amazon Bedrock, ikuti langkah-langkah berikut.
-
Buka konsol Amazon Bedrock di https://console.aws.amazon.com/bedrock/
. -
Pilih Pengaturan.
-
Di bawah Pencatatan pemanggilan model, pilih Pencatatan pemanggilan model.
-
Pilih tipe data yang diperlukan untuk disertakan dalam log. Pilih untuk mengirim CloudWatch log ke Log saja atau Amazon S3 dan CloudWatch Log jika Anda sudah menerbitkan ke Amazon S3.
-
Di bawah konfigurasi CloudWatch Log, buat nama grup log dan pilih peran layanan yang sesuai.
-
Pilih tipe data yang diperlukan untuk disertakan dalam log.
-
Pilih Simpan setelan
Anda dapat melihat dasbor pra-konfigurasi secara otomatis saat Anda mulai menggunakan pemanggilan Amazon Bedrock. Setelah mengaktifkan
Model Invocation logging, Anda dapat melihat dasbor default dan mengakses tabel pemanggilan di bawahnya.
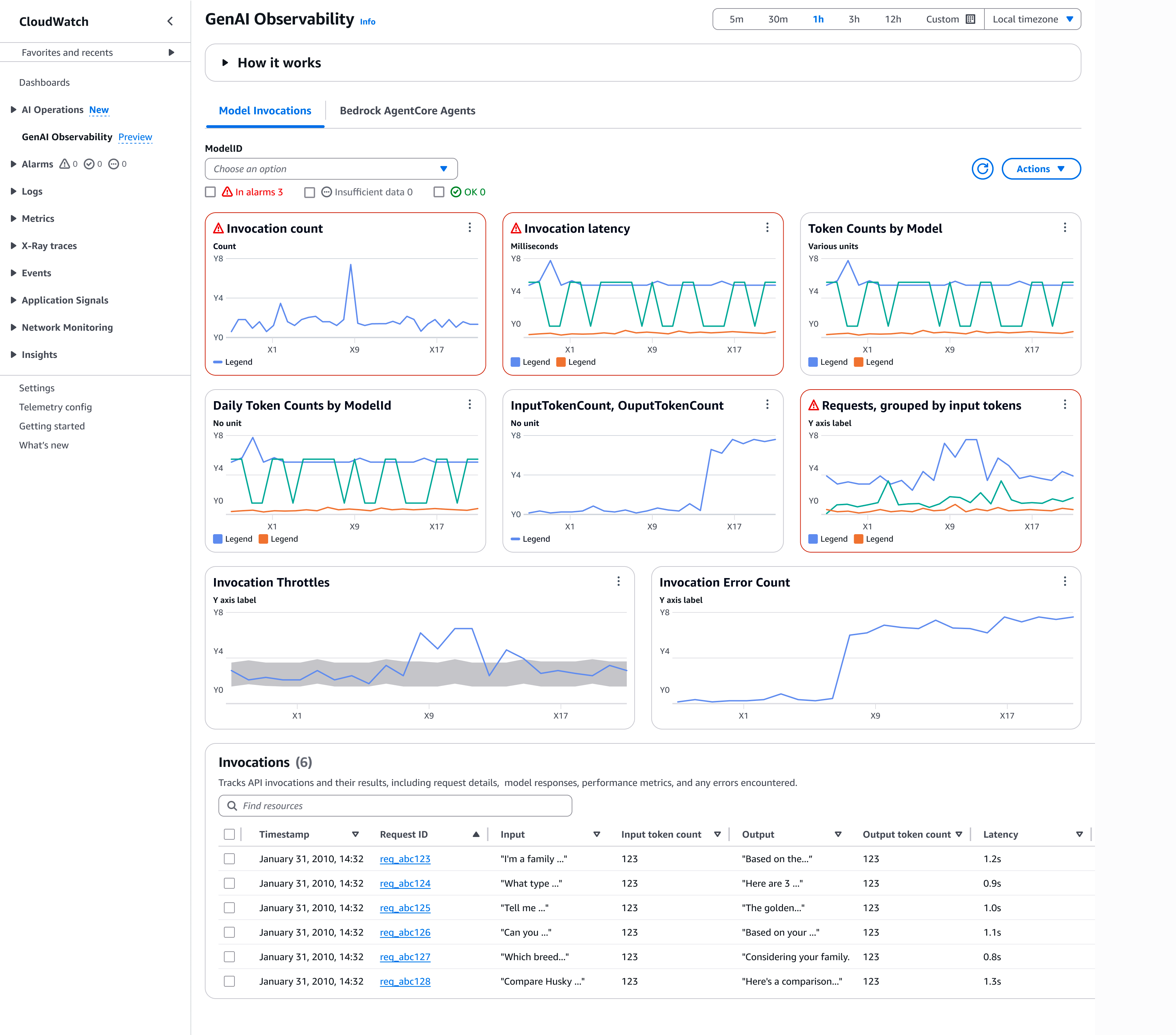
-
Jumlah pemanggilan — Jumlah permintaan yang berhasil untuk operasi Converse,, ConverseStreamInvokeModel, dan API InvokeModelWithResponseStream
-
Latensi doa — Latensi pemanggilan
-
Jumlah Token menurut Model — Jumlah token berdasarkan model yang digambarkan oleh jumlah token masukan dan jumlah token keluaran
-
Jumlah Token Harian berdasarkan ModelID — Jumlah token total harian berdasarkan ID model
-
InputTokenCount, OutputTokenCount — Jumlah total token dalam input dan output di akun ini di seluruh model yang dipilih
-
Permintaan, dikelompokkan berdasarkan token masukan — Jumlah permintaan yang dikelompokkan berdasarkan token masukan ke dalam 6 rentang. Setiap baris mewakili jumlah permintaan yang termasuk dalam rentang tertentu
-
Invocation Throttles — Jumlah pemanggilan yang dibatasi oleh sistem. Jumlah throttle yang Anda lihat akan tergantung pada pengaturan coba ulang Anda di SDK. Untuk informasi selengkapnya, lihat Mencoba lagi perilaku di AWS SDK dan Panduan Referensi Alat
-
Jumlah Kesalahan Pemanggilan - Jumlah pemanggilan yang menghasilkan kesalahan sisi server dan sisi klien
Untuk menggunakan dasbor pemanggilan model, ikuti langkah-langkah ini.
-
Arahkan kursor ke grafik metrik apa pun untuk melihat detail pemanggilan. Anda dapat memilih ikon Alarm untuk diatur
Alarmsuntuk memantau kualitas dan kinerja aplikasi. -
Di bawah drop-down ModelID, Anda dapat memilih ID model untuk melihat metrik yang sesuai.
-
Pilih Lihat dalam CloudWatch metrik untuk melihat metrik dasbor di bawah. CloudWatch
-
Pilih Periode override untuk menyesuaikan jangka waktu metrik (misalnya, 1 menit, 1 jam, atau 6 jam).
-
Di bawah Pemanggilan, pilih ID Permintaan untuk melihat detail permintaan. Anda dapat melihat detail input dan output pemanggilan model di panel kanan.
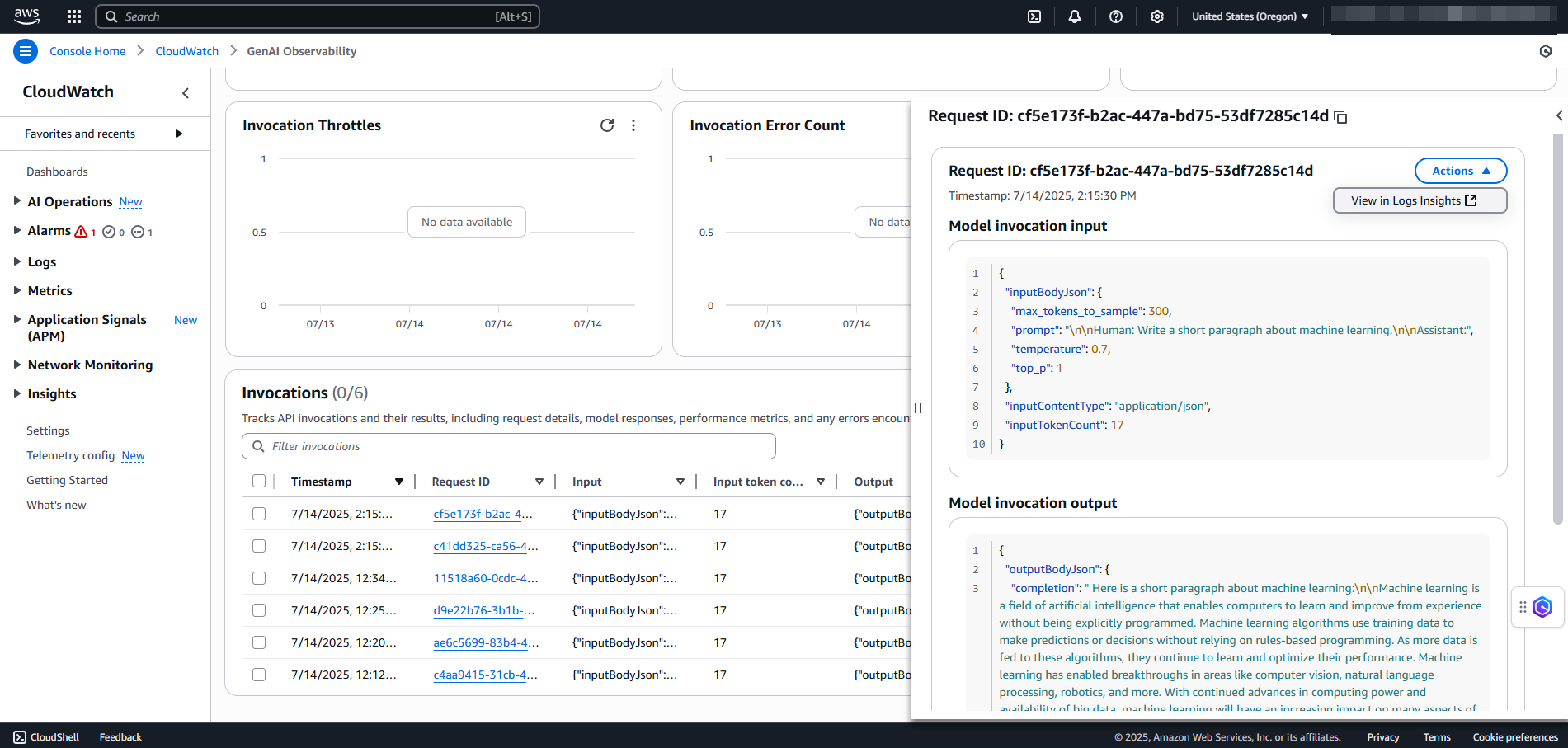
Pada halaman ID Permintaan, di bawah menu tarik-turun Tindakan, pilih Lihat di Wawasan Log untuk melihat log masuk. CloudWatch Untuk informasi selengkapnya, lihat Menganalisis data CloudWatch log dengan Wawasan Log.
