Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Déploiement de modèles pour l’inférence en temps réel
Important
Les politiques IAM personnalisées qui permettent à Amazon SageMaker Studio ou Amazon SageMaker Studio Classic de créer des SageMaker ressources Amazon doivent également accorder des autorisations pour ajouter des balises à ces ressources. L’autorisation d’ajouter des balises aux ressources est requise, car Studio et Studio Classic balisent automatiquement toutes les ressources qu’ils créent. Si une politique IAM autorise Studio et Studio Classic à créer des ressources mais n'autorise pas le balisage, des erreurs « AccessDenied » peuvent se produire lors de la tentative de création de ressources. Pour de plus amples informations, veuillez consulter Fournir des autorisations pour le balisage des ressources d' SageMaker IA.
AWS politiques gérées pour Amazon SageMaker AIqui donnent des autorisations pour créer des SageMaker ressources incluent déjà des autorisations pour ajouter des balises lors de la création de ces ressources.
Il existe plusieurs options pour déployer un modèle à l'aide des services d'hébergement SageMaker AI. Vous pouvez déployer un modèle de manière interactive avec SageMaker Studio. Vous pouvez également déployer un modèle par programmation à l'aide d'un AWS SDK, tel que le SDK Python ou le SDK pour SageMaker Python (Boto3). Vous pouvez également effectuer un déploiement à l'aide du AWS CLI.
Avant de commencer
Avant de déployer un modèle d' SageMaker IA, repérez et notez les points suivants :
-
L' Région AWS endroit où se trouve votre compartiment Amazon S3
-
Le chemin d’accès d’URI Amazon S3 où sont stockés les artefacts du modèle
-
Le rôle de l'IAM pour l'IA SageMaker
-
Le chemin de registre d'URI Docker Amazon ECR pour l'image personnalisée contenant le code d'inférence, ou le framework et la version d'une image Docker intégrée prise en charge et par AWS
Pour obtenir la liste des réseaux Services AWS disponibles dans chacun d'entre eux Région AWS, voir Cartes des régions et réseaux périphériques
Important
Le compartiment Amazon S3 où les artefacts de modèle sont stockés doit se trouver dans la même Région AWS que le modèle qui vous êtes en train de créer.
Utilisation partagée des ressources avec plusieurs modèles
Vous pouvez déployer un ou plusieurs modèles sur un point de terminaison avec Amazon SageMaker AI. Lorsque plusieurs modèles partagent un point de terminaison, ils utilisent conjointement les ressources qui y sont hébergées, telles que les instances de calcul de ML, les processeurs et les accélérateurs. Le moyen le plus flexible de déployer plusieurs modèles sur un point de terminaison consiste à définir chaque modèle en tant que composant d’inférence.
Composants Inférence
Un composant d'inférence est un objet d'hébergement d' SageMaker IA que vous pouvez utiliser pour déployer un modèle sur un point de terminaison. Dans les paramètres du composant d’inférence, vous spécifiez le modèle, le point de terminaison et la manière dont le modèle utilise les ressources hébergées par le point de terminaison. Pour spécifier le modèle, vous pouvez spécifier un objet du modèle SageMaker AI, ou vous pouvez directement spécifier les artefacts et l'image du modèle.
Dans les paramètres, vous pouvez optimiser l’utilisation des ressources en personnalisant la manière dont les cœurs de processeur, les accélérateurs et la mémoire requis sont alloués au modèle. Vous pouvez déployer plusieurs composants d’inférence sur un point de terminaison, chaque composant d’inférence contenant un modèle et les besoins d’utilisation des ressources pour ce modèle.
Après avoir déployé un composant d'inférence, vous pouvez appeler directement le modèle associé lorsque vous utilisez l' InvokeEndpoint action dans l' SageMaker API.
Les composants d’inférence offrent les avantages suivants :
- Flexibilité
-
Le composant d’inférence dissocie les détails de l’hébergement du modèle du point de terminaison lui-même. Cela offre plus de flexibilité et de contrôle sur la manière dont les modèles sont hébergés et servis avec un point de terminaison. Vous pouvez héberger plusieurs modèles sur la même infrastructure et vous pouvez ajouter ou supprimer des modèles d’un point de terminaison selon les besoins. Vous pouvez mettre à jour chaque modèle de manière indépendante.
- Capacité de mise à l’échelle
-
Vous pouvez spécifier le nombre de copies de chaque modèle à héberger et vous pouvez définir un nombre minimum de copies pour garantir que le modèle charge la quantité requise pour répondre aux demandes. Vous pouvez réduire verticalement n’importe quelle copie de composant d’inférence jusqu’à zéro, ce qui libère de l’espace pour qu’une autre copie puisse augmenter verticalement.
SageMaker L'IA emballe vos modèles sous forme de composants d'inférence lorsque vous les déployez en utilisant :
-
SageMaker Studio classique.
-
Le SDK SageMaker Python pour déployer un objet Model (dans lequel vous définissez le type de point de terminaison sur
EndpointType.INFERENCE_COMPONENT_BASED). -
AWS SDK pour Python (Boto3) pour définir les
InferenceComponentobjets que vous déployez sur un point de terminaison.
Déployez des modèles avec SageMaker Studio
Procédez comme suit pour créer et déployer votre modèle de manière interactive via SageMaker Studio. Pour plus d’informations sur Studio, consultez la documentation Studio. Pour plus d'informations sur les différents scénarios de déploiement, consultez le blog Package et déployez facilement des modèles de ML et des LLM classiques avec Amazon SageMaker AI —
Préparation de vos artefacts et de vos autorisations
Complétez cette section avant de créer un modèle dans SageMaker Studio.
Deux options s’offrent à vous pour importer vos artefacts et créer un modèle dans Studio :
-
Vous pouvez apporter une archive
tar.gzprépackagée, qui doit inclure les artefacts de votre modèle, tout code d’inférence personnalisé et toutes les dépendances répertoriées dans un fichierrequirements.txt. -
SageMaker L'IA peut emballer vos artefacts pour vous. Vous n'avez qu'à importer les artefacts de votre modèle brut et toutes les dépendances dans un
requirements.txtfichier, et l' SageMaker IA peut vous fournir le code d'inférence par défaut (ou vous pouvez remplacer le code par défaut par votre propre code d'inférence personnalisé). SageMaker L'IA prend en charge cette option pour les frameworks suivants : PyTorch, XGBoost.
En plus d'apporter votre modèle, votre rôle Gestion des identités et des accès AWS (IAM) et un conteneur Docker (ou le framework et la version souhaités pour lesquels SageMaker AI dispose d'un conteneur prédéfini), vous devez également accorder des autorisations pour créer et déployer des modèles via SageMaker AI Studio.
La AmazonSageMakerFullAccesspolitique doit être attachée à votre rôle IAM afin de pouvoir accéder à l' SageMaker IA et aux autres services pertinents. Pour connaître les prix des types d'instances dans Studio, vous devez également joindre la AWS PriceListServiceFullAccesspolitique (ou, si vous ne souhaitez pas joindre la politique dans son intégralité, plus précisément l'pricing:GetProductsaction).
Si vous choisissez de charger les artefacts de votre modèle lors de la création d’un modèle (ou de charger un exemple de fichier de données utiles pour les recommandations d’inférence), vous devez créer un compartiment Amazon S3. Le nom du compartiment doit être préfixé par le mot SageMaker AI. Les capitalisations alternatives de l' SageMaker IA sont également acceptables : Sagemaker ou. sagemaker
Nous vous recommandons d’utiliser la convention de dénomination des compartiments sagemaker-{. Ce compartiment est utilisé pour stocker les artefacts que vous chargez.Region}-{accountID}
Après avoir créé le compartiment, attachez-lui la politique CORS (cross-origin resource sharing, partage des ressources entre origines multiples) suivante :
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
Vous pouvez attacher une politique CORS à un compartiment Amazon S3 à l’aide de l’une des méthodes suivantes :
-
Via la page Modifier le partage des ressources cross-origin (CORS)
de la console Amazon S3 -
Utilisation de l'API Amazon S3 PutBucketCors
-
À l'aide de la commande put-bucket-cors AWS CLI :
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
Création d’un modèle déployable
Au cours de cette étape, vous créez une version déployable de votre modèle dans SageMaker AI en fournissant vos artefacts ainsi que des spécifications supplémentaires, telles que le conteneur et le framework souhaités, tout code d'inférence personnalisé et les paramètres réseau.
Créez un modèle déployable dans SageMaker Studio en procédant comme suit :
-
Ouvrez l'application SageMaker Studio.
-
Dans le volet de navigation de gauche, choisissez Modèles.
-
Choisissez l’onglet Modèles déployables.
-
Sur la page Modèles déployables, choisissez Créer.
-
Sur la page Créer un modèle déployable, dans le champ Nom du modèle, saisissez un nom pour le modèle.
Vous trouverez plusieurs autres sections à remplir sur la page Créer un modèle déployable.
La section Définition de conteneur ressemble à la capture d’écran suivante :
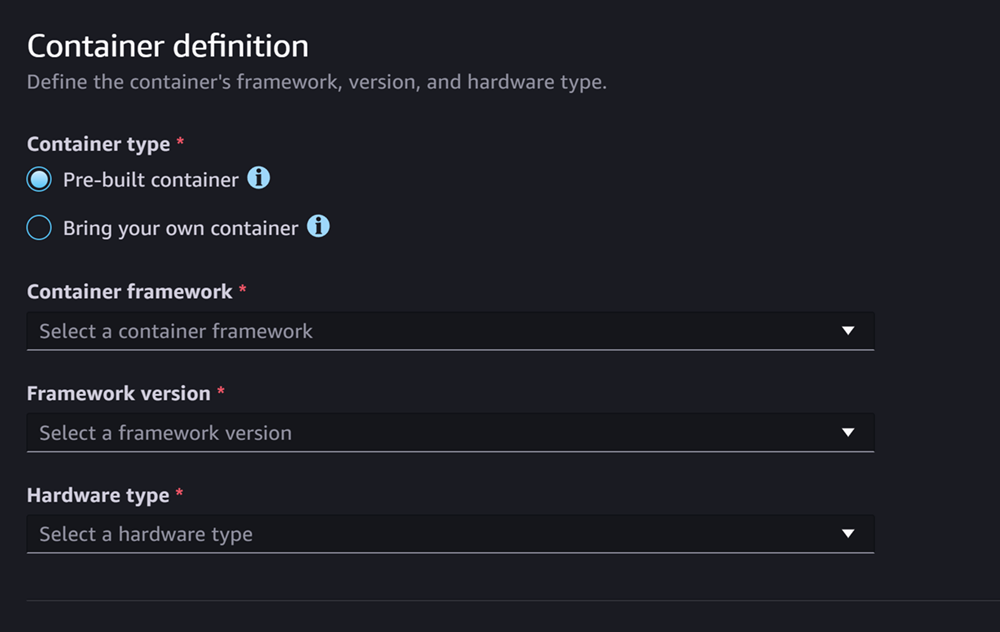
Pour Définition du conteneur section, procédez comme suit :
-
Pour le type de Pre-built conteneur, sélectionnez un conteneur si vous souhaitez utiliser un conteneur géré par l' SageMaker IA, ou sélectionnez Apportez votre propre conteneur si vous avez votre propre conteneur.
-
Si vous avez sélectionné Pre-built un conteneur, sélectionnez le framework de conteneur, la version du framework et le type de matériel que vous souhaitez utiliser.
-
Si vous avez sélectionné Apporter votre propre conteneur, saisissez un chemin d’accès Amazon ECR pour le Chemin d’accès ECR vers l’image du conteneur.
Ensuite, remplissez la section Artefacts, qui ressemble à la capture d’écran suivante :

Pour Artefacts section, procédez comme suit :
-
Si vous utilisez l'un des frameworks pris en charge par l' SageMaker IA pour empaqueter des artefacts de modèles (PyTorch ou XGBoost), vous pouvez choisir l'option Télécharger des artefacts pour les artefacts. Avec cette option, vous pouvez simplement spécifier les artefacts de votre modèle brut, tout code d'inférence personnalisé dont vous disposez et votre fichier requirements.txt, et l' SageMaker IA se charge de l'empaquetage de l'archive pour vous. Procédez comme suit :
-
Pour Artefacts, sélectionnez Charger les artefacts pour continuer à fournir vos fichiers. Sinon, si vous avez déjà une archive
tar.gzcontenant vos fichiers de modèle, votre code d’inférence et votre fichierrequirements.txt, sélectionnez URI S3 d’entrée vers les artefacts prépackagés. -
Si vous avez choisi de télécharger vos artefacts, alors pour le compartiment S3, entrez le chemin Amazon S3 vers un compartiment dans lequel vous souhaitez que l' SageMaker IA stocke vos artefacts après les avoir emballés pour vous. Ensuite, procédez comme suit.
-
Pour Charger les artefacts de modèle, chargez vos fichiers de modèle.
-
Pour le code d'inférence, sélectionnez Utiliser le code d'inférence par défaut si vous souhaitez utiliser le code par défaut fourni par l' SageMaker IA pour servir l'inférence. Sinon, sélectionnez Charger un code d’inférence personnalisé pour utiliser votre propre code d’inférence.
-
Pour Charger requirements.txt, chargez un fichier texte répertoriant les dépendances que vous souhaitez installer lors de l’exécution.
-
-
Si vous n'utilisez pas de framework compatible avec l' SageMaker IA pour empaqueter les artefacts du modèle, Studio vous propose l'option Pre-packagedartefacts, et vous devez fournir tous vos artefacts déjà empaquetés sous forme d'
tar.gzarchive. Procédez comme suit :-
Pour les Pre-packaged artefacts, sélectionnez l'URI S3 d'entrée pour les artefacts de modèles préemballés si votre
tar.gzarchive a déjà été téléchargée sur Amazon S3. Sélectionnez Télécharger des artefacts de modèles préemballés si vous souhaitez télécharger directement vos archives vers SageMaker AI. -
Si vous avez sélectionné URI S3 d’entrée pour les artefacts de modèle prépackagés, saisissez le chemin Amazon S3 vers votre archive pour URI S3. Sinon, sélectionnez et chargez l’archive à partir de votre machine locale.
-
La section suivante est Sécurité, qui ressemble à la capture d’écran suivante :
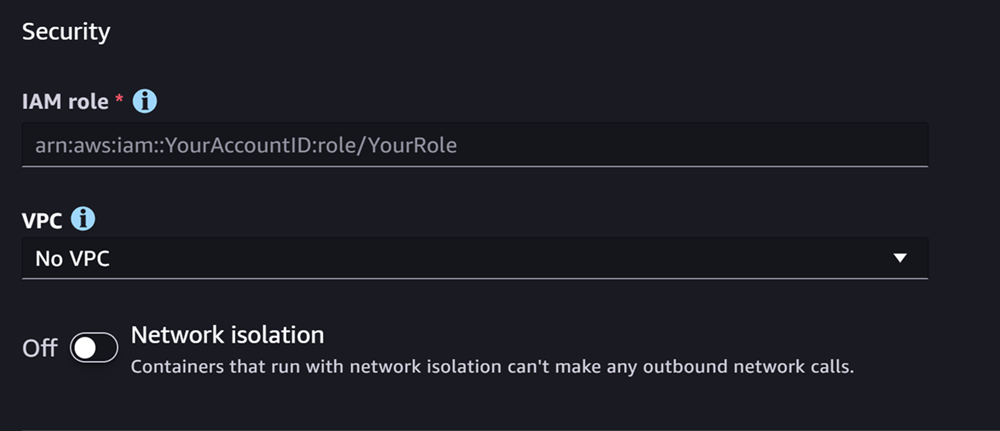
Pour Sécurité section, procédez comme suit :
-
Pour Rôle IAM, saisissez l’ARN pour un rôle IAM.
-
(Facultatif) Pour Cloud privé virtuel (VPC), vous pouvez sélectionner un VPC Amazon pour stocker votre configuration et vos artefacts de modèle.
-
(Facultatif) Activez le bouton Isolement de réseau si vous souhaitez restreindre l’accès Internet de votre conteneur.
Enfin, vous pouvez éventuellement remplir la section Options avancées, qui ressemble à la capture d’écran suivante :
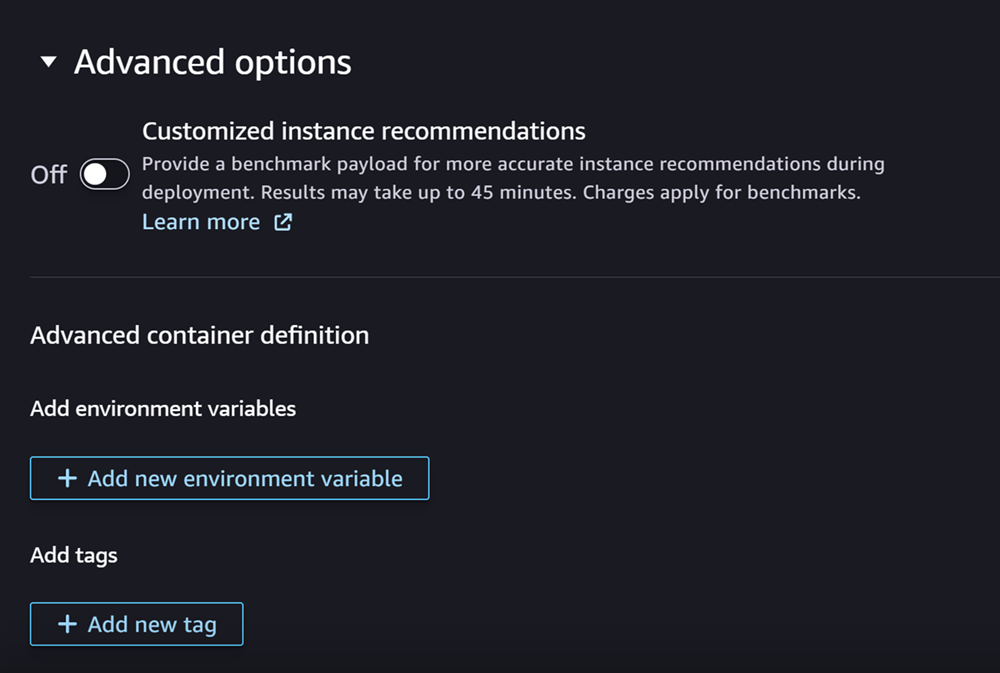
(Facultatif) Pour Options avancées section, procédez comme suit :
-
Activez le bouton Recommandations d'instance personnalisées si vous souhaitez exécuter une tâche Amazon SageMaker Inference Recommender sur votre modèle après sa création. Inference Recommender est une fonctionnalité qui vous fournit des types d’instance recommandés pour optimiser les performances et les coûts d’inférence. Vous pouvez consulter ces recommandations d’instances lorsque vous préparez le déploiement de votre modèle.
-
Pour Ajouter des variables d’environnement, saisissez une variable d’environnement pour votre conteneur sous forme de paires clé-valeur.
-
Pour Balises, saisissez toutes les balises sous forme de paires clé-valeur.
-
Après avoir terminé la configuration de votre modèle et de votre conteneur, sélectionnez Créer un modèle déployable.
Vous devriez maintenant disposer dans SageMaker Studio d'un modèle prêt à être déployé.
Déployer votre modèle
Enfin, vous déployez le modèle que vous avez configuré à l’étape précédente sur un point de terminaison HTTPS. Vous pouvez déployer un modèle unique ou plusieurs modèles sur le point de terminaison.
Compatibilité entre le modèle et le point de terminaison
Avant de pouvoir déployer un modèle sur un point de terminaison, le modèle et le point de terminaison doivent être compatibles en ayant les mêmes valeurs pour les paramètres suivants :
-
Le rôle IAM
-
Le VPC Amazon, y compris ses sous-réseaux et groupes de sécurité
-
L’isolement du réseau (activé ou désactivé)
Studio vous empêche de déployer des modèles sur des points de terminaison incompatibles de la manière suivante :
-
Si vous tentez de déployer un modèle sur un nouveau point de terminaison, l' SageMaker IA configure le point de terminaison avec des paramètres initiaux compatibles. Si vous interrompez la compatibilité en modifiant ces paramètres, Studio affiche une alerte et empêche votre déploiement.
-
Si vous tentez de déployer sur un point de terminaison existant et que celui-ci est incompatible, Studio affiche une alerte et empêche votre déploiement.
-
Si vous tentez d’ajouter plusieurs modèles à un déploiement, Studio vous empêche de déployer des modèles incompatibles entre eux.
Lorsque Studio affiche l’alerte concernant l’incompatibilité du modèle et du point de terminaison, vous pouvez choisir Afficher les détails de l’alerte pour voir quels paramètres sont incompatibles.
Pour déployer un modèle, vous pouvez notamment procéder comme suit dans Studio :
-
Ouvrez l'application SageMaker Studio.
-
Dans le volet de navigation de gauche, choisissez Modèles.
-
Sur la page Modèles, sélectionnez un ou plusieurs modèles dans la liste des modèles d' SageMaker IA.
-
Choisissez Déployer.
-
Pour Nom du point de terminaison, ouvrez le menu déroulant. Vous pouvez sélectionner un point de terminaison existant ou créer un nouveau point de terminaison sur lequel vous déployez le modèle.
-
Pour Type d’instance, sélectionnez le type d’instance à utiliser pour le point de terminaison. Si vous avez déjà exécuté une tâche Inference Recommender pour le modèle, les types d’instance que vous recommandez apparaissent dans la liste sous le titre Recommandé. Sinon, vous verrez quelques Instances potentielles susceptibles de convenir à votre modèle.
Compatibilité des types d'instance pour JumpStart
Si vous déployez un JumpStart modèle, Studio affiche uniquement les types d'instances pris en charge par le modèle.
-
Dans Nombre d’instances initial, saisissez le nombre initial d’instances que vous souhaitez provisionner pour votre point de terminaison.
-
Pour Nombre maximal d’instances, spécifiez le nombre maximum d’instances que le point de terminaison peut mettre en service lorsqu’il augmente verticalement pour faire face à une augmentation du trafic.
-
Si le modèle que vous déployez est l'un des JumpStart LLM les plus utilisés depuis le hub de modèles, l'option Autres configurations apparaît après les champs type d'instance et nombre d'instances.
Pour les JumpStart LLM les plus populaires, AWS propose des types d'instances pré-comparés afin d'optimiser les coûts ou les performances. Ces données peuvent vous aider à choisir le type d’instance à utiliser pour déployer votre LLM. Choisissez Autres configurations pour ouvrir une boîte de dialogue contenant les données préévaluées. Le panneau ressemble à la capture d’écran suivante :
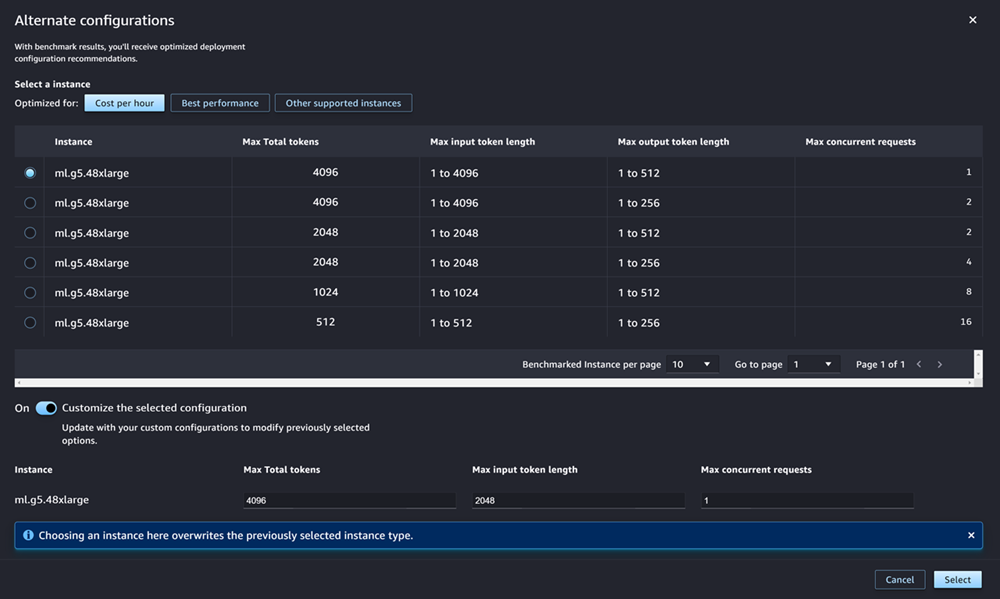
Dans la boîte Autres configurations, procédez comme suit :
-
Sélectionnez un type d’instance. Vous pouvez choisir Coût par heure ou Meilleures performances pour voir les types d’instance qui optimisent le coût ou les performances pour le modèle spécifié. Vous pouvez également sélectionner Autres instances prises en charge pour voir la liste des autres types d'instances compatibles avec le JumpStart modèle. Notez que la sélection d’un type d’instance ici remplace toute sélection d’instance précédente spécifiée à l’étape 6.
-
(Facultatif) Activez le bouton Personnaliser la configuration sélectionnée pour spécifier le Nombre maximum de jetons (le nombre maximum de jetons que vous souhaitez autoriser, qui est la somme de vos jetons d’entrée et de la sortie générée par le modèle), la Longueur maximale du jeton d’entrée (le nombre maximum de jetons que vous souhaitez autoriser pour l’entrée de chaque demande) et le Nombre maximal de requêtes simultanées (le nombre maximum de requêtes que le modèle peut traiter à la fois).
-
Choisissez Sélectionner pour confirmer le type d’instance et les paramètres de configuration.
-
-
Le champ Modèle doit déjà être renseigné avec le nom du ou des modèles que vous déployez. Vous pouvez choisir Ajouter un modèle pour ajouter d’autres modèles au déploiement. Pour chaque modèle ajouté, renseignez les champs suivants :
-
Dans Nombre de cœurs de l’UC, saisissez les cœurs de processeur que vous souhaitez consacrer à l’utilisation du modèle.
-
Pour Nombre minimum de copies, saisissez le nombre minimum de copies de modèle que vous souhaitez héberger sur le point de terminaison à un moment donné.
-
Pour Mémoire minimale de l’UC (Mo), saisissez la quantité minimale de mémoire (en Mo) requise par le modèle.
-
Pour Mémoire maximale de l’UC (Mo), saisissez la quantité maximale de mémoire (en Mo) que vous souhaitez autoriser le modèle à utiliser.
-
-
(Facultatif) Pour Options avancées, procédez comme suit :
-
Pour le rôle IAM, utilisez le rôle d'exécution SageMaker AI IAM par défaut ou spécifiez votre propre rôle doté des autorisations dont vous avez besoin. Notez que ce rôle IAM doit être identique à celui que vous avez spécifié lors de la création du modèle déployable.
-
Pour Cloud privé virtuel (VPC), vous pouvez spécifier le VPC dans lequel vous souhaitez héberger votre point de terminaison.
-
Pour la clé KMS de chiffrement, sélectionnez une AWS KMS clé pour chiffrer les données sur le volume de stockage attaché à l'instance de calcul ML qui héberge le point de terminaison.
-
Activez le bouton Activer l’isolement du réseau pour restreindre l’accès Internet de votre conteneur.
-
Pour Configuration du délai d’attente, saisissez des valeurs dans les champs Expiration de téléchargement des données du modèle (secondes) et Expiration de surveillance de l’état du démarrage du conteneur (secondes). Ces valeurs déterminent le temps maximal accordé par l' SageMaker IA pour télécharger le modèle dans le conteneur et démarrer le conteneur, respectivement.
-
Pour Balises, saisissez toutes les balises sous forme de paires clé-valeur.
Note
SageMaker L'IA configure le rôle IAM, le VPC et les paramètres d'isolation du réseau avec des valeurs initiales compatibles avec le modèle que vous déployez. Si vous interrompez la compatibilité en modifiant ces paramètres, Studio affiche une alerte et empêche votre déploiement.
-
Une fois vos options configurées, la page doit ressembler à la capture d’écran suivante.
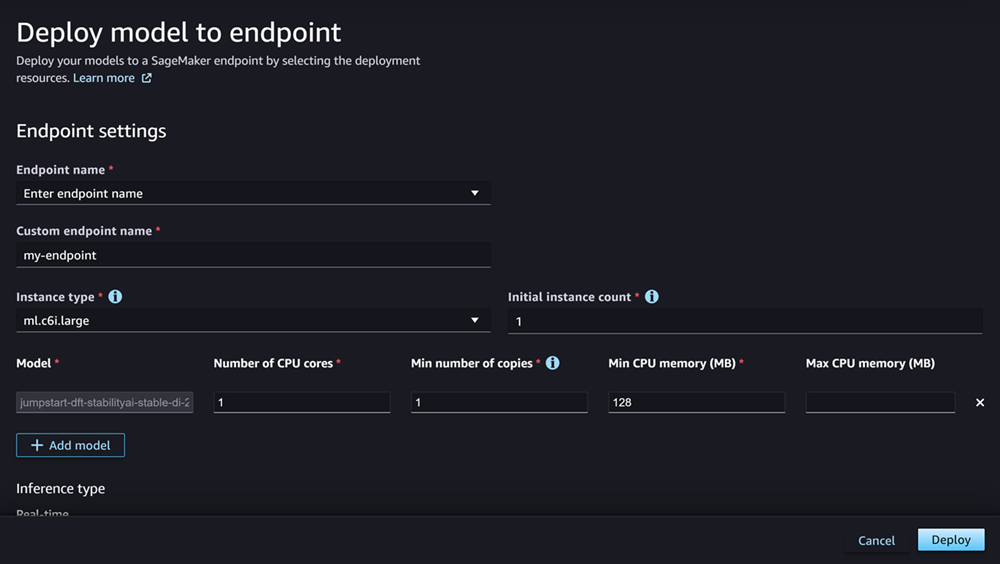
Après avoir configuré votre déploiement, choisissez Déployer pour créer le point de terminaison et déployer votre modèle.
Déploiement de modèles avec les kits SDK Python
À l'aide du SDK SageMaker Python, vous pouvez créer votre modèle de deux manières. La première consiste à créer un objet modèle à partir de la classe Model ou ModelBuilder. Si vous utilisez la classe Model pour créer votre objet Model, vous devez spécifier le package de modèle ou le code d’inférence (en fonction de votre modèle de serveur), les scripts pour gérer la sérialisation et la désérialisation des données entre le client et le serveur, ainsi que toutes les dépendances à charger sur Amazon S3 à des fins de consommation. La deuxième méthode de création de votre modèle consiste à utiliser un ModelBuilder pour lequel vous fournissez des artefacts ou un code d’inférence. ModelBuilder capture automatiquement vos dépendances, en déduit les fonctions de sérialisation et de désérialisation nécessaires et empaquète vos dépendances pour créer votre objet Model. Pour plus d’informations sur ModelBuilder, consultez Créez un modèle dans Amazon SageMaker AI avec ModelBuilder.
La section suivante décrit les deux méthodes permettant de créer votre modèle et de déployer votre objet modèle.
Configuration
Les exemples suivants préparent le processus de déploiement du modèle. Ils importent les bibliothèques nécessaires et définissent l’URL S3 qui localise les artefacts du modèle.
Exemple URL de l’artefact de modèle
Le code suivant permet de créer un exemple d’URL Amazon S3. L’URL localise les artefacts de modèle pour un modèle préentraîné dans un compartiment Amazon S3.
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
L’URL Amazon S3 complète est stockée dans la variable model_url, qui est utilisée dans les exemples suivants.
Présentation de
Il existe plusieurs manières de déployer des modèles avec le SDK SageMaker Python ou le SDK pour Python (Boto3). Les sections suivantes résument les étapes que vous devez suivre pour différentes approches possibles. Ces étapes sont illustrées par les exemples suivants.
Configurer
Les exemples suivants configurent les ressources dont vous avez besoin pour déployer un modèle sur un point de terminaison.
Déploiement
Les exemples suivants déploient un modèle sur un point de terminaison.
Déployez des modèles avec AWS CLI
Vous pouvez déployer un modèle sur un point de terminaison à l'aide du AWS CLI.
Présentation de
Lorsque vous déployez un modèle avec le AWS CLI, vous pouvez le déployer avec ou sans composant d'inférence. Les sections suivantes résument les commandes que vous exécutez pour les deux approches. Ces commandes sont illustrées par les exemples suivants.
Configurer
Les exemples suivants configurent les ressources dont vous avez besoin pour déployer un modèle sur un point de terminaison.
Déploiement
Les exemples suivants déploient un modèle sur un point de terminaison.
