Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
GitHub référentiels
Pour lancer une tâche de formation, vous utilisez des fichiers provenant de deux GitHub référentiels distincts :
Ces référentiels contiennent des composants essentiels pour lancer, gérer et personnaliser les processus d’entraînement de grands modèles de langage (LLM). Vous utilisez les scripts de ces référentiels pour configurer et exécuter les tâches d’entraînement pour vos LLM.
HyperPod référentiel de recettes
Utilisez le référentiel de SageMaker HyperPod recettes
-
main.py: Ce fichier sert de point d'entrée principal pour lancer le processus de soumission d'un poste de formation à un cluster ou à un poste de SageMaker formation. -
launcher_scripts: ce répertoire contient une collection de scripts couramment utilisés, conçus pour faciliter le processus d’entraînement pour divers grands modèles de langage (LLM). -
recipes_collection: ce dossier contient une compilation de recettes LLM prédéfinies, fournies par les développeurs. Les utilisateurs peuvent tirer profit de ces recettes en conjonction avec leurs données personnalisées pour entraîner des modèles LLM adaptés à leurs besoins spécifiques.
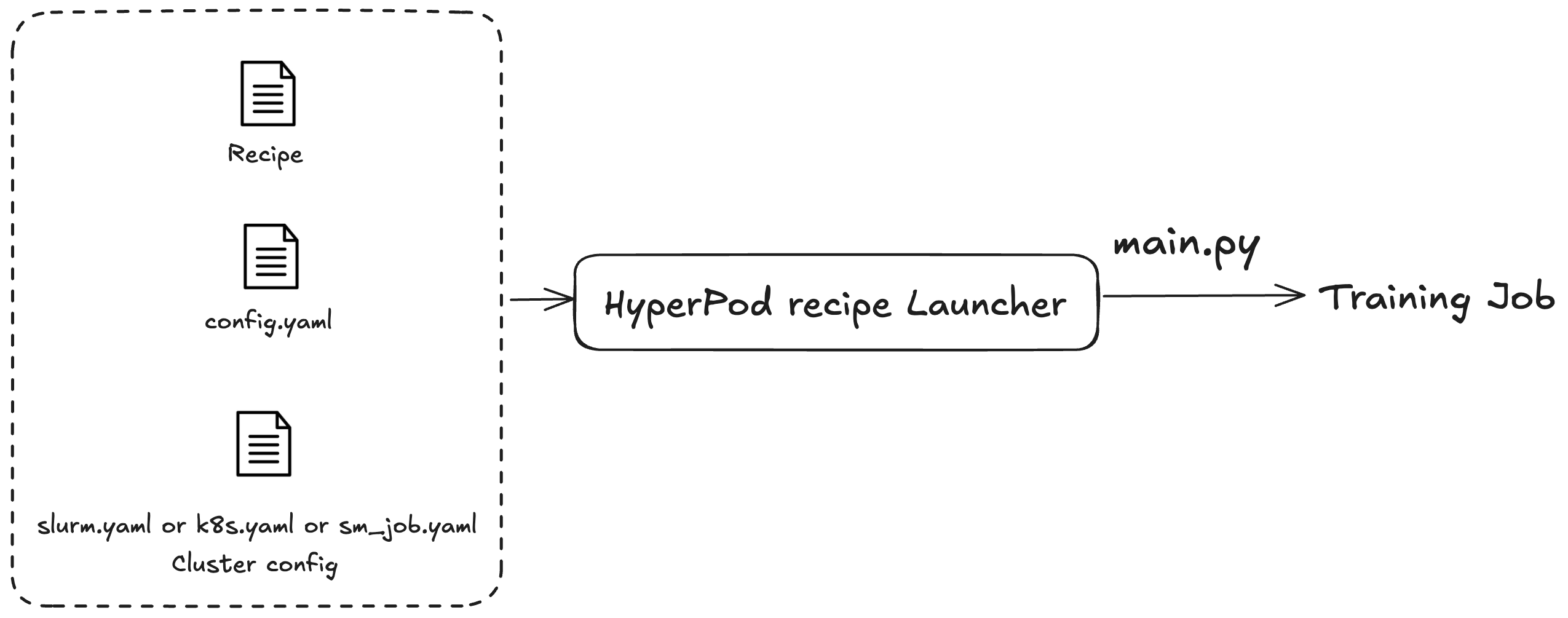
Vous utilisez les SageMaker HyperPod recettes pour lancer des formations ou peaufiner des tâches. Quel que soit le cluster que vous utilisez, le processus de soumission de la tâche est le même. Par exemple, vous pouvez utiliser le même script pour soumettre une tâche à un cluster Slurm ou Kubernetes. Le lanceur distribue une tâche d’entraînement en fonction de trois fichiers de configuration :
-
Configuration générale (
config.yaml) : inclut les paramètres courants tels que les paramètres par défaut ou les variables d’environnement utilisés dans la tâche d’entraînement. -
Configuration du cluster (cluster) : pour les tâches d’entraînement utilisant des clusters uniquement. Si vous soumettez une tâche d’entraînement à un cluster Kubernetes, vous devrez peut-être spécifier des informations telles que le volume, l’étiquette ou la politique de redémarrage. Pour les clusters Slurm, vous devrez peut-être spécifier le nom de la tâche Slurm. Tous ces paramètres sont liés au cluster spécifique que vous utilisez.
-
Recette (recettes) : les recettes contiennent les paramètres de votre tâche d’entraînement, tels que les types de modèles, le degré de partitionnement ou les chemins des jeux de données. Par exemple, vous pouvez définir Llama comme modèle d’entraînement et l’entraîner à l’aide de techniques de parallélisme de modèles ou de données telles que FSDF (Fully Sharded Distributed Parallel) sur huit ordinateurs. Vous pouvez également spécifier différentes fréquences ou différents chemins de points de contrôle pour votre tâche d’entraînement.
Après avoir spécifié une recette, vous exécutez le script de lancement pour spécifier une tâche d’entraînement de bout en bout sur un cluster en fonction des configurations effectuées via le point d’entrée main.py. Chaque recette que vous utilisez est accompagnée de scripts shell situés dans le dossier launch_scripts. Ces exemples vous guident dans la soumission et le lancement de tâches d’entraînement. La figure suivante montre comment un lanceur de SageMaker HyperPod recettes soumet une tâche de formation à un cluster sur la base de ce qui précède. Actuellement, le lanceur de SageMaker HyperPod recettes est construit sur le Nvidia NeMo Framework Launcher. Pour plus d'informations, consultez le Guide du NeMo lanceur
HyperPod référentiel d'adaptateurs de recettes
L'adaptateur SageMaker HyperPod de formation est un cadre de formation. Vous pouvez l’utiliser pour gérer le cycle de vie complet de vos tâches d’entraînement. Utilisez l’adaptateur pour distribuer le pré-entraînement ou le peaufinage de vos modèles sur plusieurs ordinateurs. L’adaptateur utilise différentes techniques de parallélisme pour distribuer l’entraînement. Il gère également la mise en œuvre et la gestion de l’enregistrement des points de contrôle. Pour en savoir plus, consultez Réglages avancés.
Utilisez le référentiel d'adaptateurs de SageMaker HyperPod recettes
-
src: Ce répertoire contient la mise en œuvre de la formation aux modèles Large-scale linguistiques (LLM), qui englobe diverses fonctionnalités telles que le parallélisme des modèles, la formation à précision mixte et la gestion des points de contrôle. -
examples: ce dossier fournit une collection d’exemples illustrant comment créer un point d’entrée pour l’entraînement d’un modèle LLM, qui sert de guide pratique pour les utilisateurs.
