Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mise à l’échelle d’un entraînement
Les sections suivantes décrivent les scénarios dans lesquels vous souhaiterez peut-être étendre la formation, ainsi que la manière dont vous pouvez le faire en utilisant AWS les ressources. Vous pouvez avoir besoin de mettre à l’échelle un entraînement dans l’un des cas suivants :
-
Mise à l’échelle d’un seul GPU à plusieurs GPU
-
Mise à l'échelle d'une seule instance à plusieurs instances
-
Utilisation de scripts d’entraînement personnalisés
Mise à l’échelle d’un seul GPU à plusieurs GPU
La quantité de données ou la taille du modèle utilisé en machine learning peut créer des situations où le temps d'entraînement d'un modèle est supérieur au temps dont vous disposez. Parfois, le format du modèle ou le volume des données rend l'entraînement impossible. Une solution consiste à augmenter le nombre de GPU que vous utilisez pour l'entraînement. Sur une instance avec plusieurs GPU, comme une instance p3.16xlarge avec huit GPU, les données et le traitement sont divisés entre les huit GPU. L'utilisation de bibliothèques d'entraînement distribué peut accélérer de façon quasi linéaire le temps nécessaire à l'entraînement de votre modèle. Cela prend un peu plus 1/8 de temps qu'p3.2xlargeavec un seul GPU.
| Type d’instance | Processeurs graphiques |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
Note
Les types d'instances ml utilisés par l' SageMaker entraînement ont le même nombre de GPU que les types d'instances p3 correspondants. Par exemple, une instance ml.p3.8xlarge a le même nombre de GPU qu'une instance p3.8xlarge - 4.
Mise à l'échelle d'une seule instance à plusieurs instances
Pour augmenter la mise à l'échelle de votre entraînement, vous pouvez utiliser plus d'instances. Vous devrez toutefois choisir un type d'instance plus grand avant d'ajouter d'autres instances. Consultez le tableau précédent pour voir combien de GPU contient chaque type d'instance p3.
Si vous êtes passé d'un seul GPU sur une instance p3.2xlarge à quatre GPU sur une instance p3.8xlarge, mais que vous avez besoin de plus de puissance de traitement, il peut être avantageux du point de vue des performances et des coûts de choisir une instance p3.16xlarge avant d'augmenter le nombre d'instances. Selon les bibliothèques que vous utilisez, en continuant votre entraînement sur une seule instance, vous améliorez les performances et réduisez les coûts par rapport à un scénario à plusieurs instances.
Lorsque vous êtes prêt à augmenter le nombre d'instances, vous pouvez le faire à l'aide de la estimator fonction SageMaker AI Python SDK en définissant votreinstance_count. Vous pouvez, par exemple, définir instance_type = p3.16xlarge et instance_count =
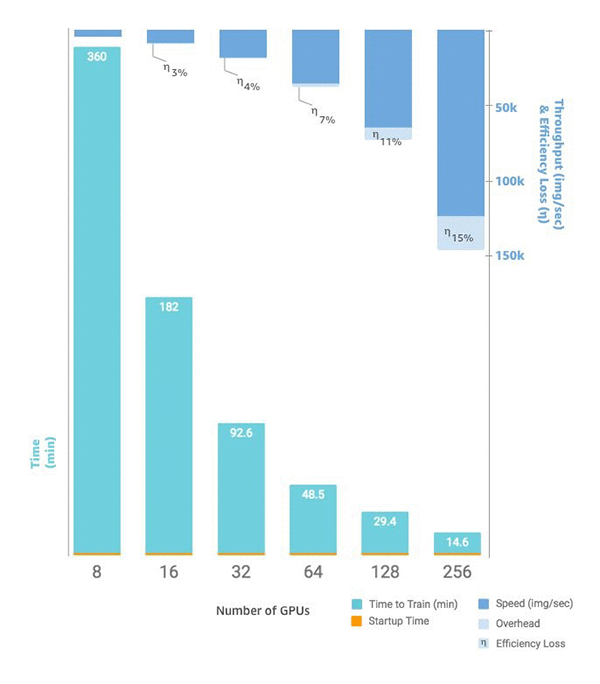
2. Au lieu d'avoir huit GPU sur une seule instance p3.16xlarge, vous disposez de 16 GPU sur deux instances identiques. Le graphique suivant montre la mise à l'échelle et le débit en commençant par huit GPU
Scripts d'entraînement personnalisés
Bien que l' SageMaker IA facilite le déploiement et la mise à l'échelle du nombre d'instances et de GPU, en fonction du framework de votre choix, la gestion des données et des résultats peut s'avérer très difficile. C'est pourquoi des bibliothèques de support externes sont souvent utilisées. Cette forme la plus élémentaire de formation distribuée nécessite la modification de votre script d'entraînement pour gérer la distribution des données.
SageMaker L'IA prend également en charge Horovod et la mise en œuvre de formations distribuées natives à chaque framework d'apprentissage profond majeur. Si vous choisissez d'utiliser des exemples issus de ces frameworks, vous pouvez suivre le guide des conteneurs de l' SageMaker IA pour les Deep Learning Containers, ainsi que divers exemples de blocs-notes
