Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
# Transformation de données
Amazon SageMaker Data Wrangler propose de nombreuses transformations de données ML pour rationaliser le nettoyage, la transformation et la mise en valeur de vos données. Lorsque vous ajoutez une transformation, elle ajoute une étape au flux de données. Chaque transformation que vous ajoutez modifie votre jeu de données et génère un nouveau nom de données. Toutes les transformations suivantes s'appliquent au dataframe résultant.
Data Wrangler inclut des transformations intégrées, que vous pouvez utiliser pour transformer des colonnes sans code. Vous pouvez également ajouter des transformations personnalisées à l'aide PySpark de Python (fonction définie par l'utilisateur), de pandas et PySpark de SQL. Certaines transformations sont appliquées directement, tandis que d’autres créent une nouvelle colonne de sortie dans votre jeu de données.
Vous pouvez appliquer des transformations à plusieurs colonnes en même temps. Par exemple, vous pouvez supprimer plusieurs colonnes d'une seule étape.
Vous ne pouvez appliquer les transformations **Traitement numérique** et **Gestion des éléments manquants** qu’à une seule colonne.
Lisez cette page pour en savoir plus sur ces transformations intégrées et personnalisées.
## Interface utilisateur de transformation
La plupart des transformations intégrées sont situées dans l’onglet **Prepare (Préparation)** de l’interface utilisateur Data Wrangler. Vous pouvez accéder aux transformations Join (Joindre) et Concatenate (Concaténer) via la vue de flux de données. Utilisez le tableau suivant pour avoir un aperçu de ces deux vues.
------
#### [ Transform ]
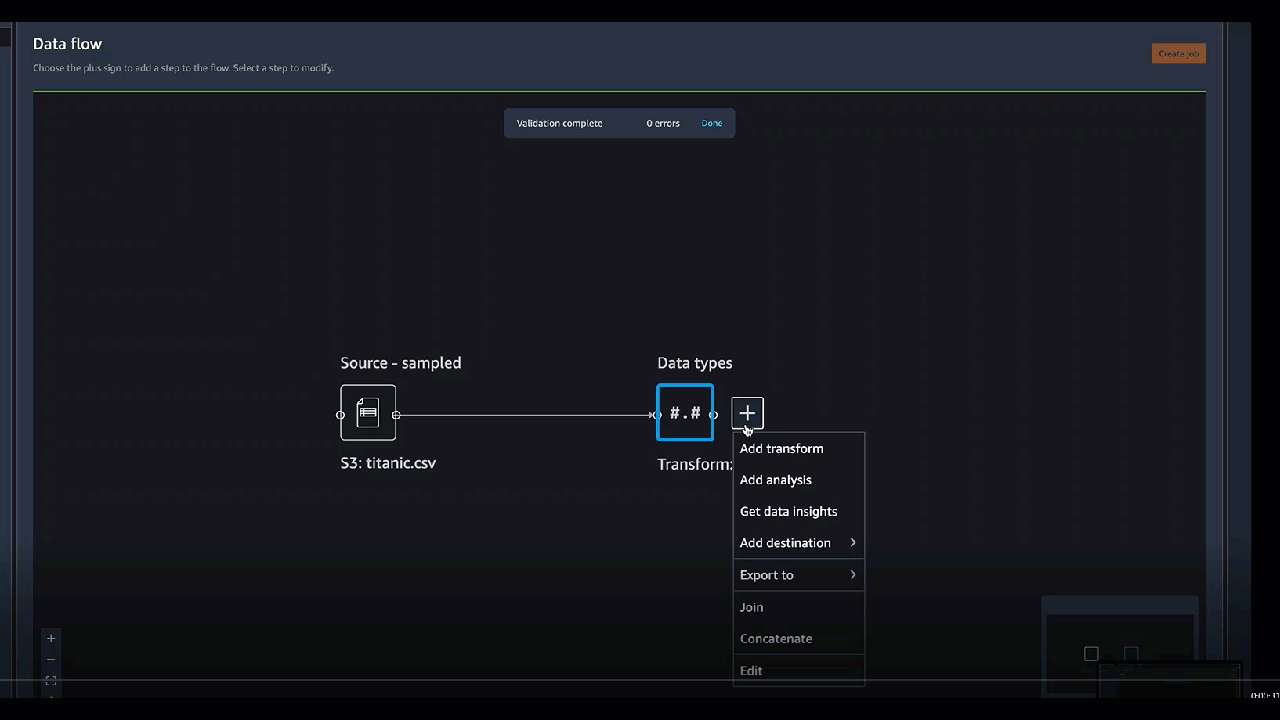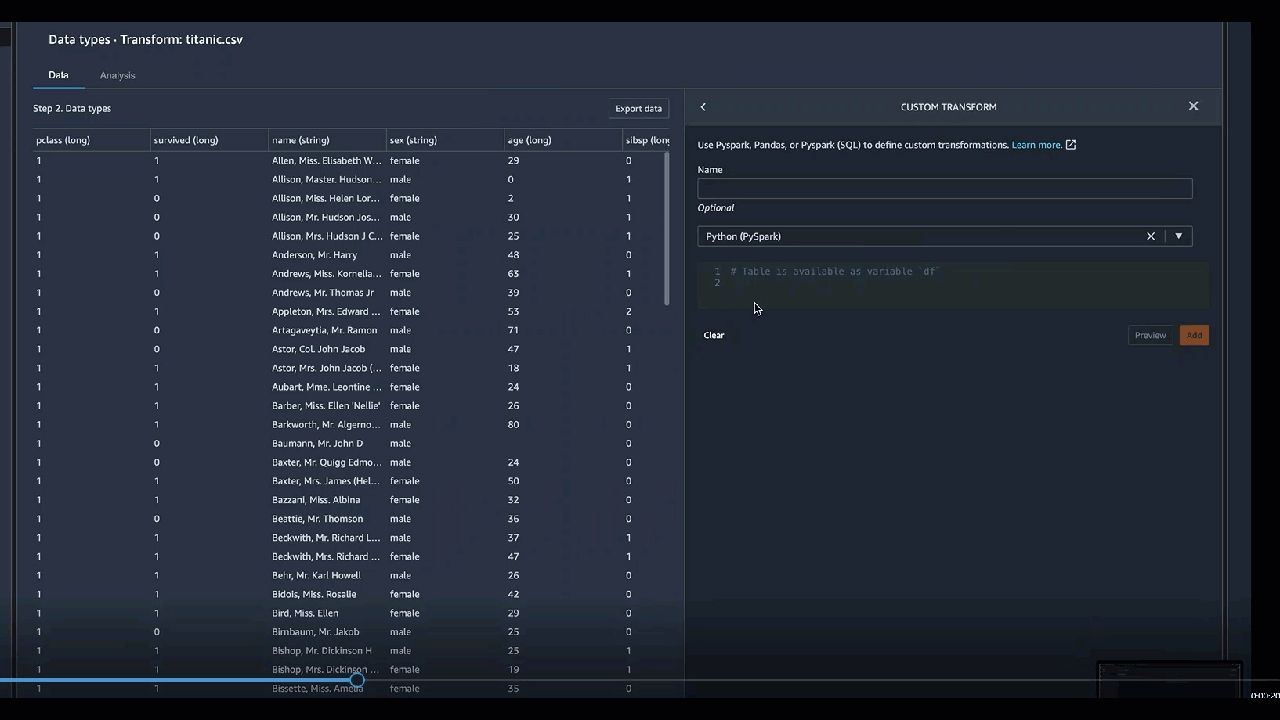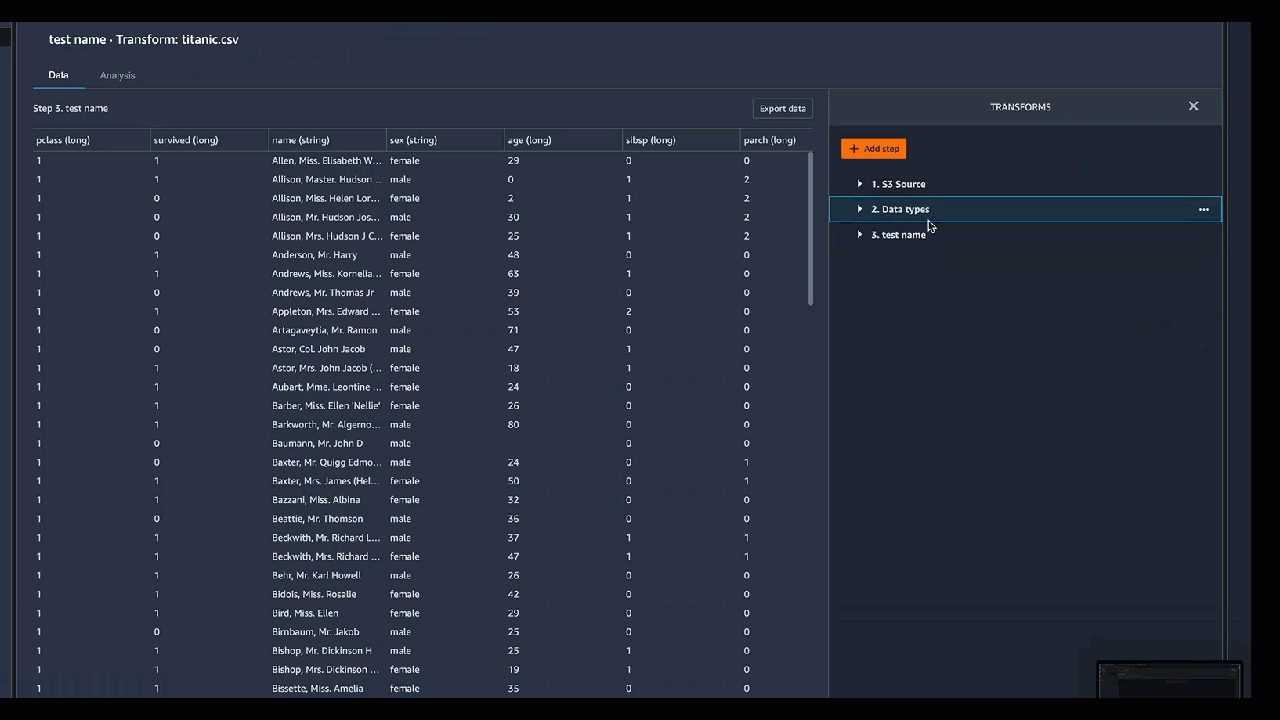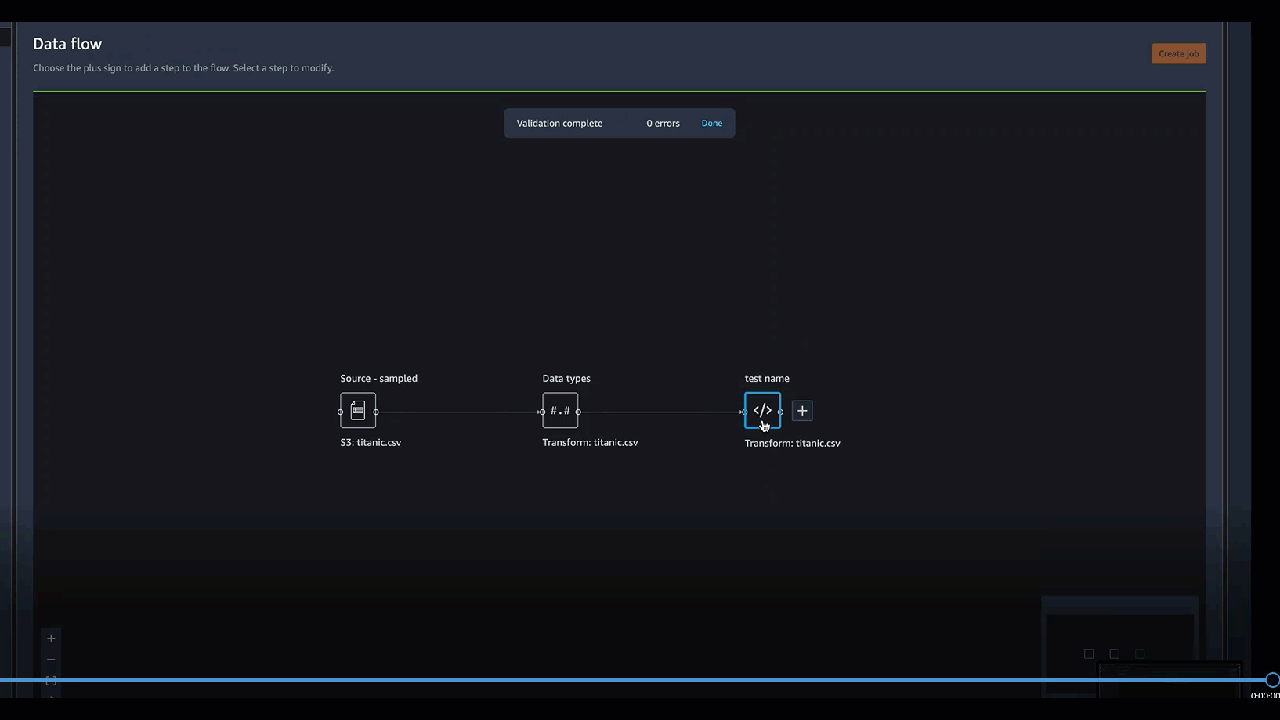
Vous pouvez ajouter une transformation à n'importe quelle étape de votre flux de données. Utilisez la procédure suivante pour ajouter une transformation à votre flux de données.
Pour ajouter une étape à votre flux de données, procédez comme suit.
1. Cliquez sur le symbole **\+** à côté de l'étape dans le flux de données.
1. Choisissez **Ajouter une transformation**.
1. Choisissez **Ajouter une étape**.
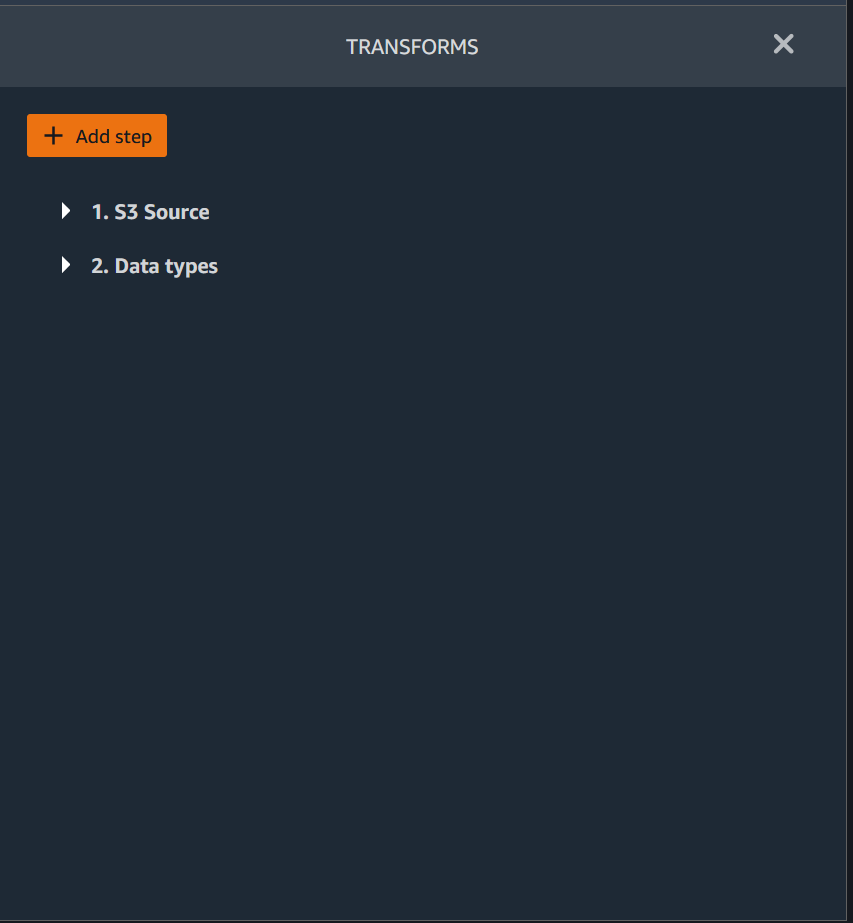
1. Choisissez une transformation.
1. (Facultatif) Vous pouvez rechercher la transformation que vous souhaitez utiliser. Data Wrangler met en évidence la requête dans les résultats.
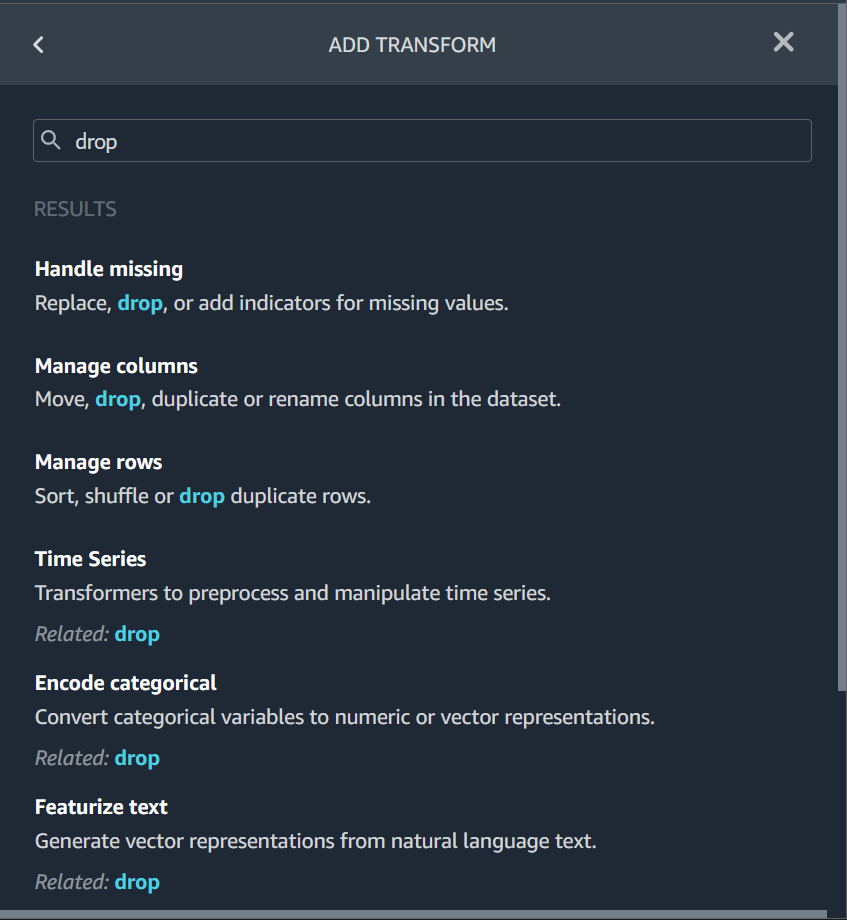
------
#### [ Join View ]
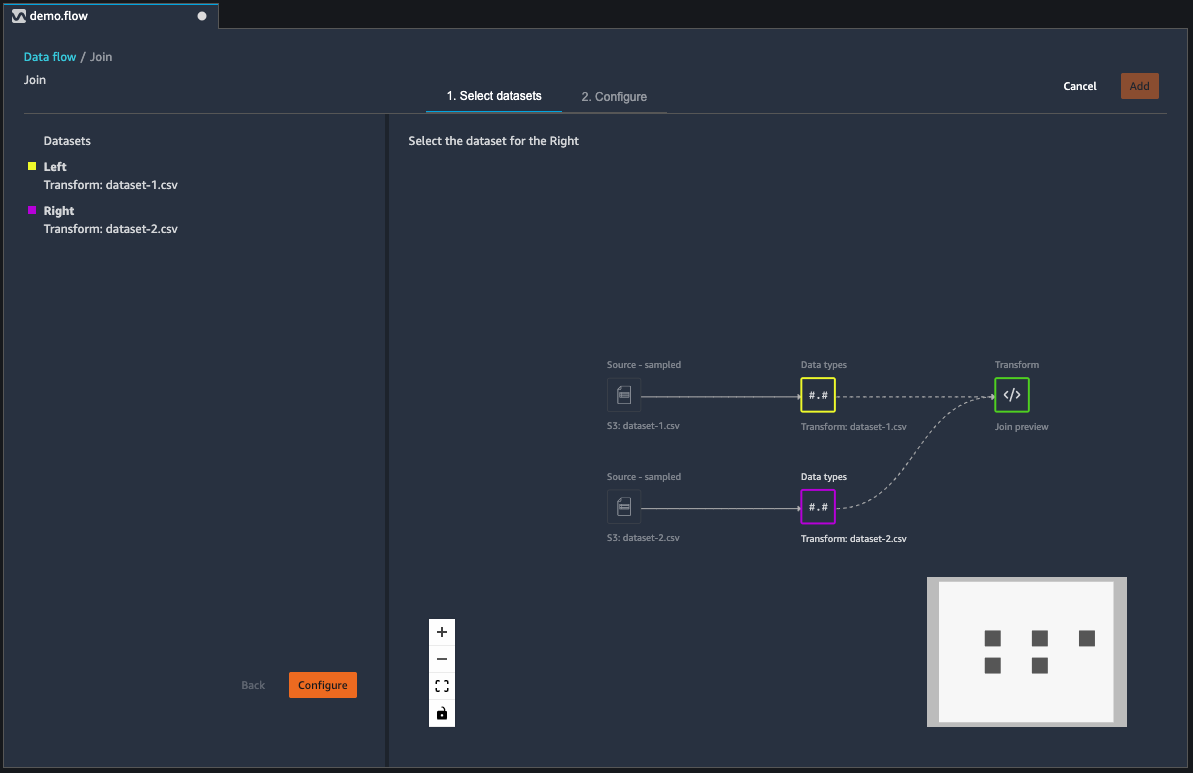
Pour joindre deux jeux de données, sélectionnez le premier jeu de données de votre flux de données et cliquez sur **Join (Joindre)**. Lorsque vous cliquez sur **Join** (Joindre), des résultats semblables à ceux de l'image suivante s'affichent. Vos jeux de données gauche et droite s’affichent dans le volet de gauche. Le volet principal affiche votre flux de données, avec le jeu de données nouvellement joint ajouté.
Lorsque vous cliquez sur **Configure** (Configurer) pour configurer votre jointure, vous voyez des résultats semblables à ceux affichés dans l’image suivante. Votre configuration de jointure s'affiche dans le volet de gauche. Vous pouvez utiliser ce volet pour choisir le nom du jeu de données joint, le type de jointure et les colonnes à joindre. Le volet principal affiche trois tableaux. Les deux premiers tableaux affichent les jeux de données gauche et droit respectivement à gauche et à droite. Sous ce tableau, vous pouvez prévisualiser le jeu de données joint.
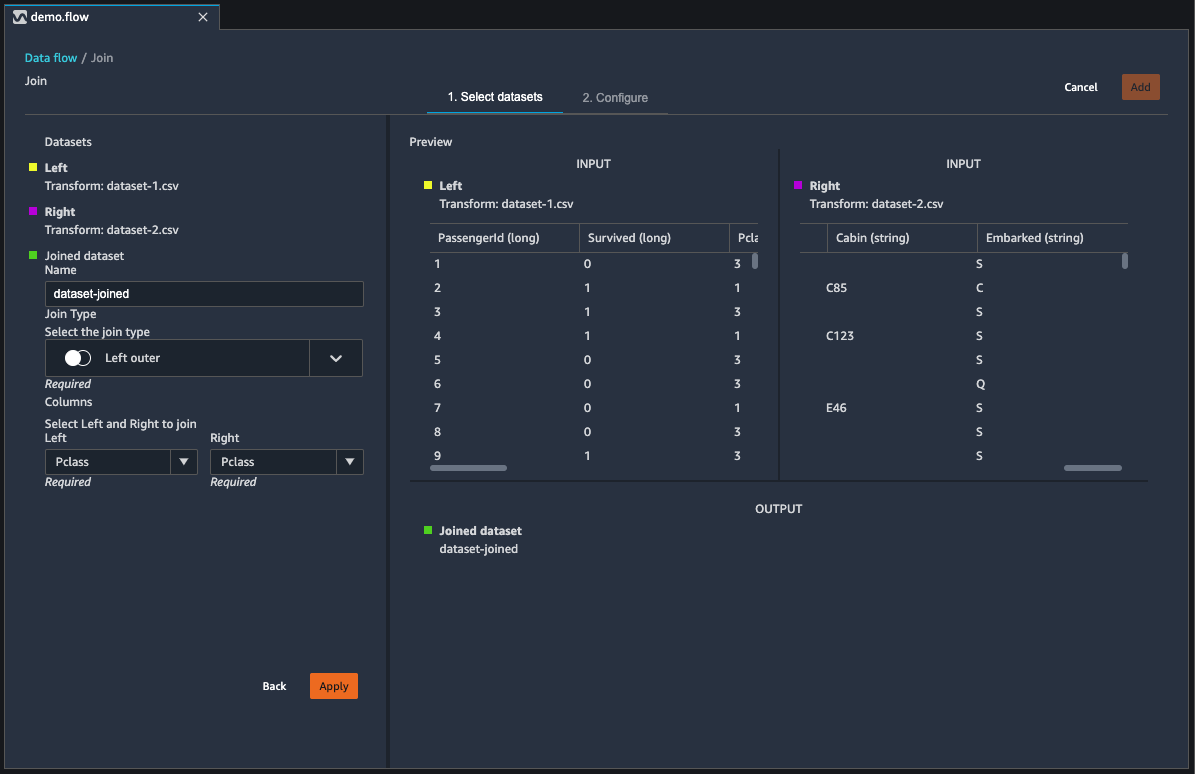
Pour en savoir plus, consultez [Joindre des jeux de données](#data-wrangler-transform-join).
------
#### [ Concatenate View ]
Pour concaténer deux jeux de données, sélectionnez le premier jeu de données de votre flux de données et cliquez sur **Concatenate (Concaténer)**. Lorsque vous cliquez sur **Concatenate**, vous verrez des résultats similaires à ceux affichés dans l'image suivante. Vos jeux de données gauche et droite s'affichent dans le volet de gauche. Le volet principal affiche votre flux de données, avec le jeu de données nouvellement concaténé ajouté.
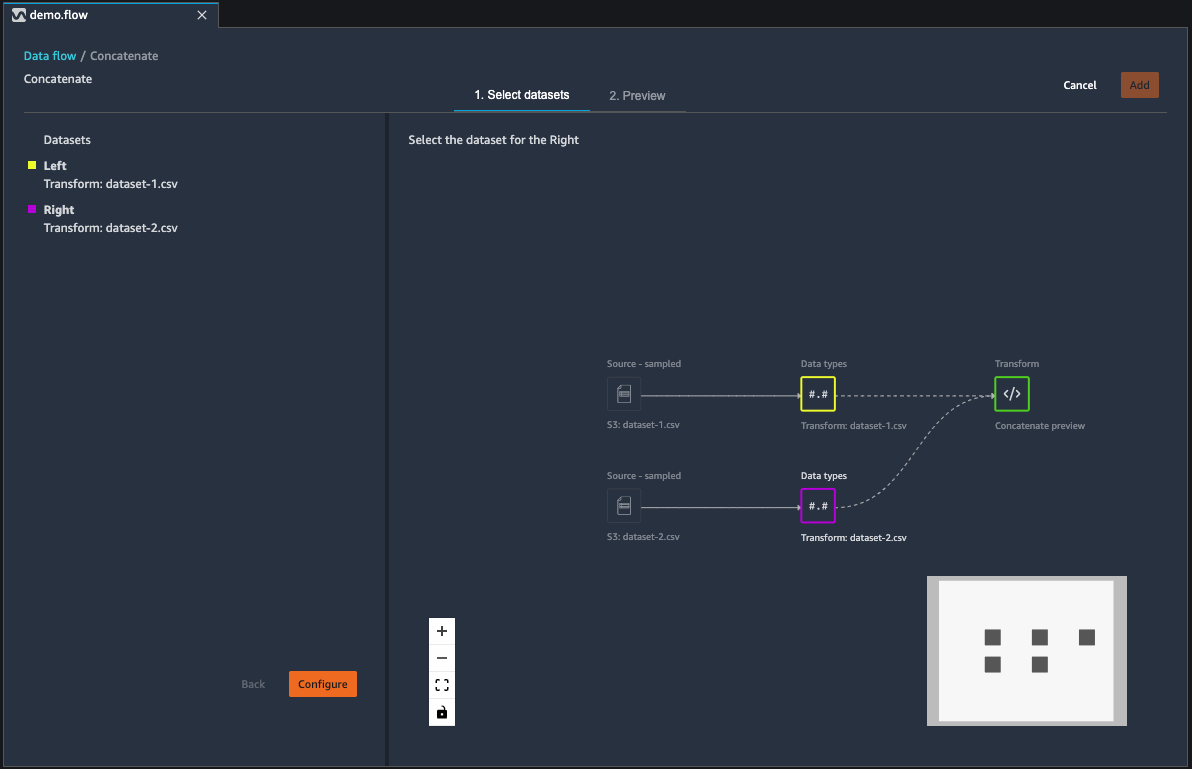
Lorsque vous cliquez sur **Configure** (Configurer) pour configurer votre concaténation, vous voyez des résultats semblables à ceux affichés dans l’image suivante. Votre configuration de concaténation s'affiche dans le volet de gauche. Vous pouvez utiliser ce volet pour choisir le nom du jeu de données concaténé, et choisir de supprimer les doublons après la concaténation et d’ajouter des colonnes pour indiquer le dataframe source. Le volet principal affiche trois tableaux. Les deux premiers tableaux affichent les jeux de données gauche et droit respectivement à gauche et à droite. Sous ce tableau, vous pouvez prévisualiser le jeu de données concaténé.
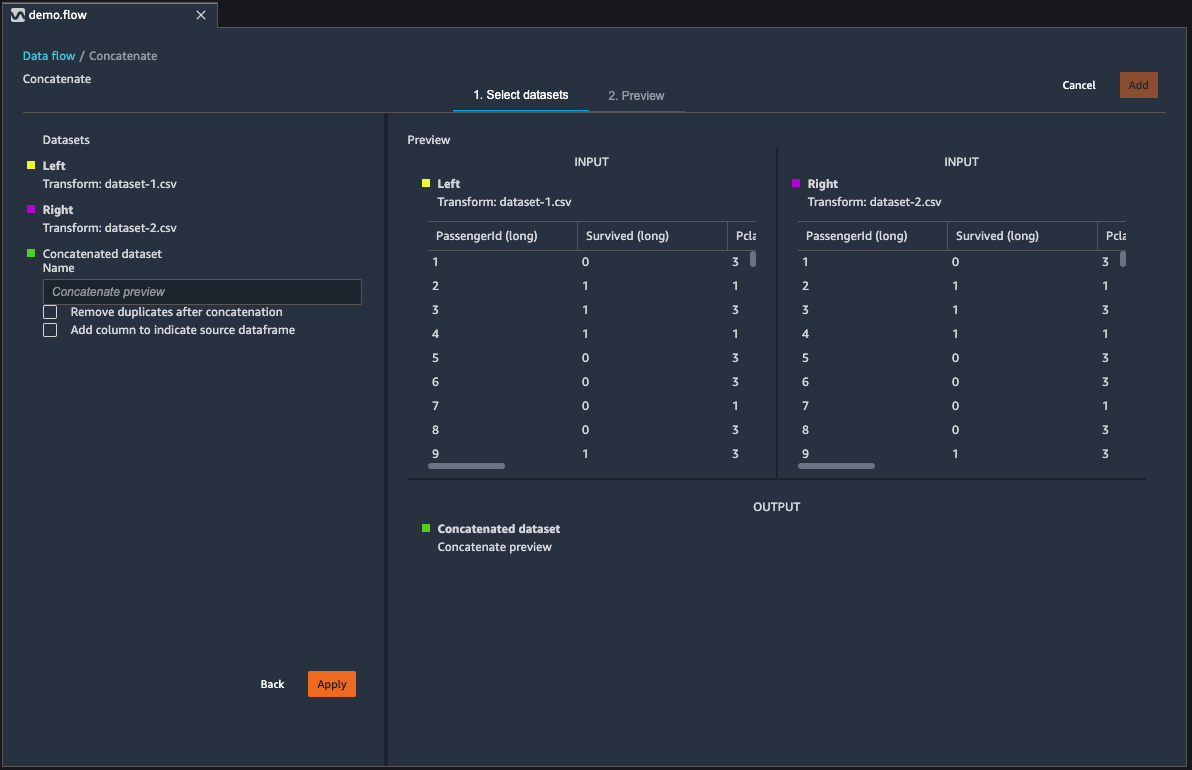
Pour en savoir plus, consultez [Concaténer des jeux de données](#data-wrangler-transform-concatenate).
------
## Joindre des jeux de données
Vous joignez des dataframes directement dans votre flux de données. Lorsque vous joignez deux jeux de données, le jeu de données joint résultant apparaît dans votre flux. Les types de jointure suivants sont pris en charge par Data Wrangler.
+ **Externe gauche** : inclut toutes les lignes de la table de gauche. Si la valeur de la colonne jointe dans une ligne du tableau de gauche ne correspond à aucune valeur de ligne du tableau de droite, cette ligne contient des valeurs nulles pour toutes les colonnes du tableau de droite dans le tableau joint.
+ **Anti gauche** : inclut les lignes de la table de gauche qui ne contiennent pas de valeurs dans la table de droite pour la colonne jointe.
+ **Left Semi** – Inclut une seule ligne de la table de gauche pour toutes les lignes identiques répondant aux critères de l'instruction de jointure. Ceci exclut les lignes en double de la table de gauche qui correspondent aux critères de la jointure.
+ **Externe droite** : inclut toutes les lignes de la table de droite. Si la valeur de la colonne jointe dans une ligne de la table de droite ne correspond à aucune valeur de ligne de la table de gauche, cette ligne contient des valeurs nulles pour toutes les colonnes de table de gauche de la table jointe.
+ **INNER** – Inclut les lignes des tables de gauche et de droite qui contiennent des valeurs correspondantes dans la colonne jointe.
+ **Externe complète** : inclut toutes les lignes des tables de gauche et de droite. Si la valeur de ligne de la colonne jointe dans l'une ou l'autre des tables ne correspond pas, des lignes séparées sont créées dans la table jointe. Si une ligne ne contient pas de valeur pour une colonne de la table jointe, null est inséré pour cette colonne.
+ **Croisée cartésienne** : inclut les lignes qui combinent chaque ligne de la première table avec chaque ligne de la seconde table. Il s'agit d'un [produit cartésien](https://en.wikipedia.org/wiki/Cartesian_product) des lignes des tables de la jointure. Le résultat de ce produit est la taille de la table de gauche multipliée par la taille de la table de droite. Par conséquent, nous vous recommandons de faire preuve de prudence lorsque vous utilisez cette jointure entre des jeux de données très volumineux.
Utilisez la procédure suivante pour joindre deux dataframes.
1. Cliquez sur le symbole **\+** en regard de la base de données de gauche que vous souhaitez joindre. Le premier dataframe que vous sélectionnez est toujours la table de gauche de votre jointure.
1. Choisissez **Join** (Joindre).
1. Sélectionnez le dataframe de droite. Le deuxième dataframe que vous sélectionnez est toujours la table de droite dans votre jointure.
1. Sélectionnez **Configure** (Configurer) pour configurer votre jointure.
1. Donnez un nom à votre jeu de données joint en utilisant le champ **Name (Nom)**.
1. Sélectionnez un **Join type (Type de jointure)**.
1. Sélectionnez une colonne dans les tableaux de gauche et de droite pour effectuer la jointure.
1. Cliquez sur **Apply** (Appliquer) pour afficher un aperçu du jeu de données joint à droite.
1. Pour ajouter le tableau joint à votre flux de données, sélectionnez **Add** (Ajouter).
## Concaténer des jeux de données
**Concaténez deux jeux de données :**
1. Sélectionnez le symbole **\+** à côté du dataframe de gauche que vous souhaitez concaténer. Le premier dataframe que vous sélectionnez est toujours la table de gauche de votre concaténation.
1. Cliquez sur **Concatenate** (Concaténer).
1. Sélectionnez le dataframe de droite. Le deuxième dataframe que vous sélectionnez est toujours la table de droite dans votre concaténation.
1. Cliquez sur **Configure** (Configurer) pour configurer votre concaténation.
1. Donnez un nom à votre jeu de données concaténé en utilisant le champ **Name (Nom)**.
1. (Facultatif) Cochez la case en regard de **Remove duplicates after concatenation** (Supprimer les doublons après concaténation) pour supprimer les colonnes en double.
1. (Facultatif) Cochez la case en regard de **Add column to indicate source dataframe** (Ajouter une colonne pour indiquer le nom de base de données source) si, pour chaque colonne du nouveau jeu de données, vous souhaitez ajouter un indicateur de la source de la colonne.
1. Cliquez sur **Apply** (Appliquer) pour afficher un aperçu du nouveau jeu de données.
1. Cliquez sur **Add** (Ajouter) pour ajouter le nouveau jeu de données à votre flux de données.
## Équilibrage des données
Vous pouvez équilibrer les données des jeux de données présentant une catégorie sous-représentée. L'équilibrage d'un jeu de données peut vous aider à créer de meilleurs modèles pour la classification binaire.
**Note**
Vous ne pouvez pas équilibrer les jeux de données contenant des vecteurs de colonne.
Vous pouvez utiliser l'opération **Balance data** (Équilibrer les données) pour équilibrer vos données à l'aide de l'un des opérateurs suivants :
+ *Suréchantillonnage aléatoire* : duplique aléatoirement des échantillons de la catégorie minoritaire. Par exemple, si vous essayez de détecter une fraude, il est possible que vos données ne présentent que 10 % de cas de fraude. Pour obtenir une proportion égale de cas frauduleux et non frauduleux, cet opérateur duplique de façon aléatoire les cas de fraude au sein du jeu de données 8 fois.
+ *Sous-échantillonnage aléatoire* : à peu près équivalent à un suréchantillonnage aléatoire. Supprime aléatoirement les échantillons de la catégorie surreprésentée pour obtenir la proportion d'échantillons souhaitée.
+ *SMOTE (Synthetic Minority Oversampling Technique)* : utilise des échantillons de la catégorie sous-représentée pour interpoler de nouveaux échantillons minoritaires synthétiques. Pour plus d'informations sur SMOTE, consultez la description suivante.
Vous pouvez utiliser toutes les transformations pour des jeux de données contenant à la fois des fonctions numériques et non numériques. SMOTE interpole les valeurs en utilisant des échantillons voisins. Data Wrangler utilise la distance du coefficient de détermination pour déterminer le voisinage afin d'interpoler des échantillons supplémentaires. Data Wrangler utilise uniquement des fonctions numériques pour calculer les distances entre les échantillons du groupe sous-représenté.
Pour deux échantillons réels du groupe sous-représenté, Data Wrangler interpole les fonctions numériques en utilisant une moyenne pondérée. Il affecte aléatoirement un poids à ces échantillons dans la plage de [0, 1]. Pour les fonctions numériques, Data Wrangler interpole les échantillons à l'aide d'une moyenne pondérée des échantillons. Pour les échantillons A et B, Data Wrangler pourrait affecter aléatoirement un poids de 0,7 à A et de 0,3 à B. Par conséquent, l'échantillon interpolé aurait une valeur de 0,7A \+ 0,3B.
Data Wrangler interpole des fonctions non numériques en réalisant une copie à partir de l'un des échantillons réels interpolés. Il copie les échantillons en affectant aléatoirement une probabilité à chaque échantillon. Pour les échantillons A et B, il peut affecter les probabilités 0,8 à A et 0,2 à B. Selon les probabilités affectées, il copie A 80 % du temps.
## Transformations personnalisées
Le groupe **Custom Transforms** vous permet d'utiliser Python (fonction définie par l'utilisateur) PySpark, pandas ou PySpark (SQL) pour définir des transformations personnalisées. Pour ces trois options, vous utilisez la variable `df` pour accéder au dataframe auquel vous souhaitez appliquer la transformation. Pour appliquer votre code personnalisé à votre dataframe, attribuez au dataframe les transformations que vous avez apportées à la variable `df`. Si vous n’utilisez pas Python (fonction définie par l’utilisateur), vous n’avez pas besoin d’inclure une instruction de retour. Cliquez sur **Preview** (Aperçu) pour afficher un aperçu du résultat de la transformation personnalisée. Cliquez sur **Add** (Ajouter) pour ajouter la transformation personnalisée à votre liste **Previous steps** (Étapes précédentes).
Vous pouvez importer les bibliothèques populaires suivantes à l'aide d'une instruction `import` dans le bloc de code de la transformation personnalisée :
+ NumPy version 1.19.0
+ scikit-learn version 0.23.2
+ SciPy version 1.5.4
+ pandas version 1.0.3
+ PySpark version 3.0.0
**Important**
**Custom transform** (Transformation personnalisée) ne prend pas en charge les colonnes avec des espaces ou des caractères spéciaux dans le nom. Nous vous recommandons de spécifier des noms de colonnes contenant uniquement des caractères alphanumériques et des traits de soulignement. Vous pouvez utiliser la transformation **Rename column** (Renommer une colonne) dans le groupe de transformation **Manage columns** (Gérer les colonnes) pour supprimer des espaces du nom d'une colonne. Vous pouvez également ajouter une **Custom transform (Transformation personnalisée)** **Python (Pandas)** similaire à ce qui suit pour supprimer des espaces de plusieurs colonnes en une seule étape. Cet exemple modifie les colonnes nommées `A column` et `B column` en `A_column` et `B_column`, respectivement.
```
df.rename(columns={"A column": "A_column", "B column": "B_column"})
```
Si vous incluez des instructions d’impression dans le bloc de code, le résultat apparaît lorsque vous cliquez sur **Preview (Aperçu)**. Vous pouvez redimensionner le panneau du transformateur de code personnalisé. Le redimensionnement du panneau offre plus d’espace pour écrire du code. L'image suivante illustre le redimensionnement du panneau.
Vous trouverez ci-dessous du contexte et des exemples supplémentaires pour écrire du code de transformation personnalisé.
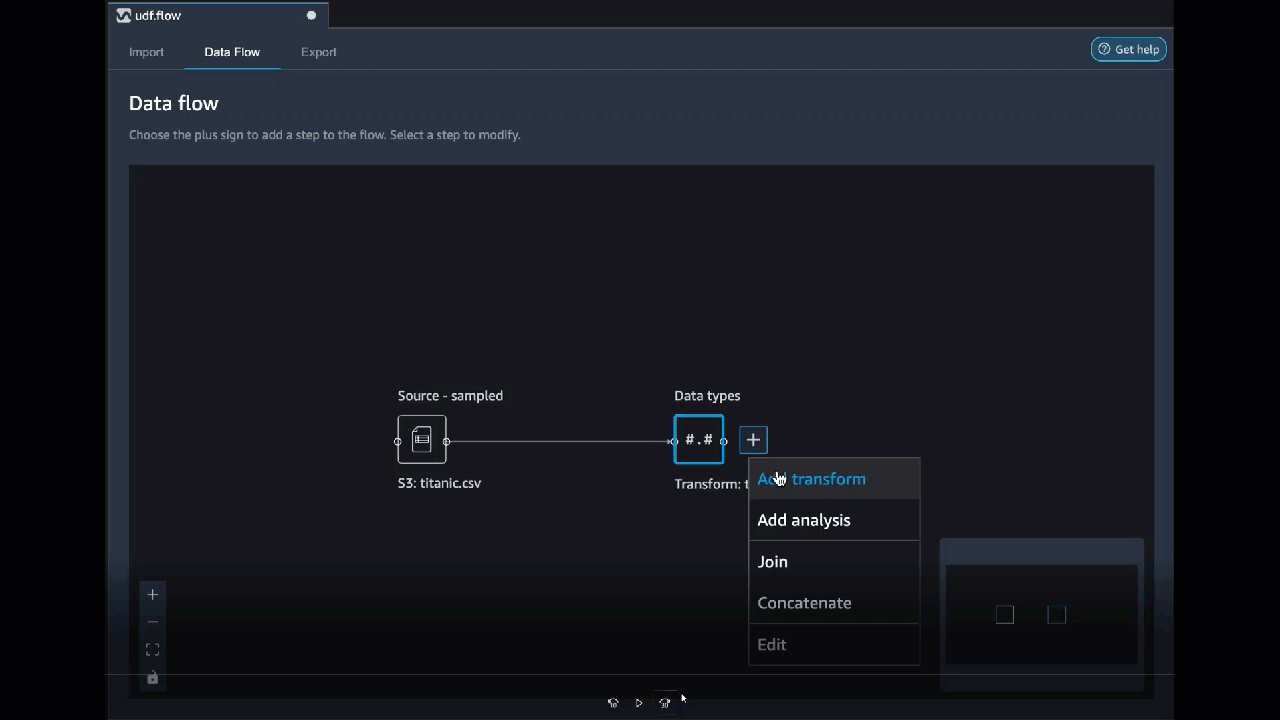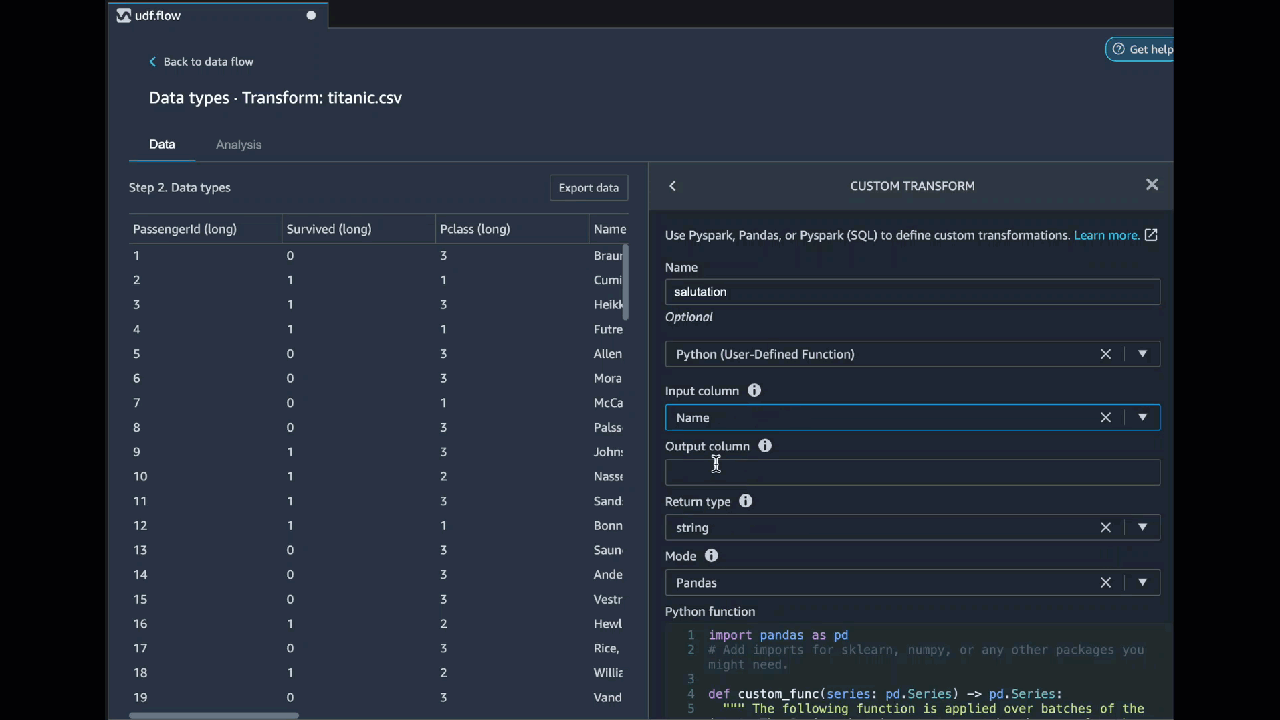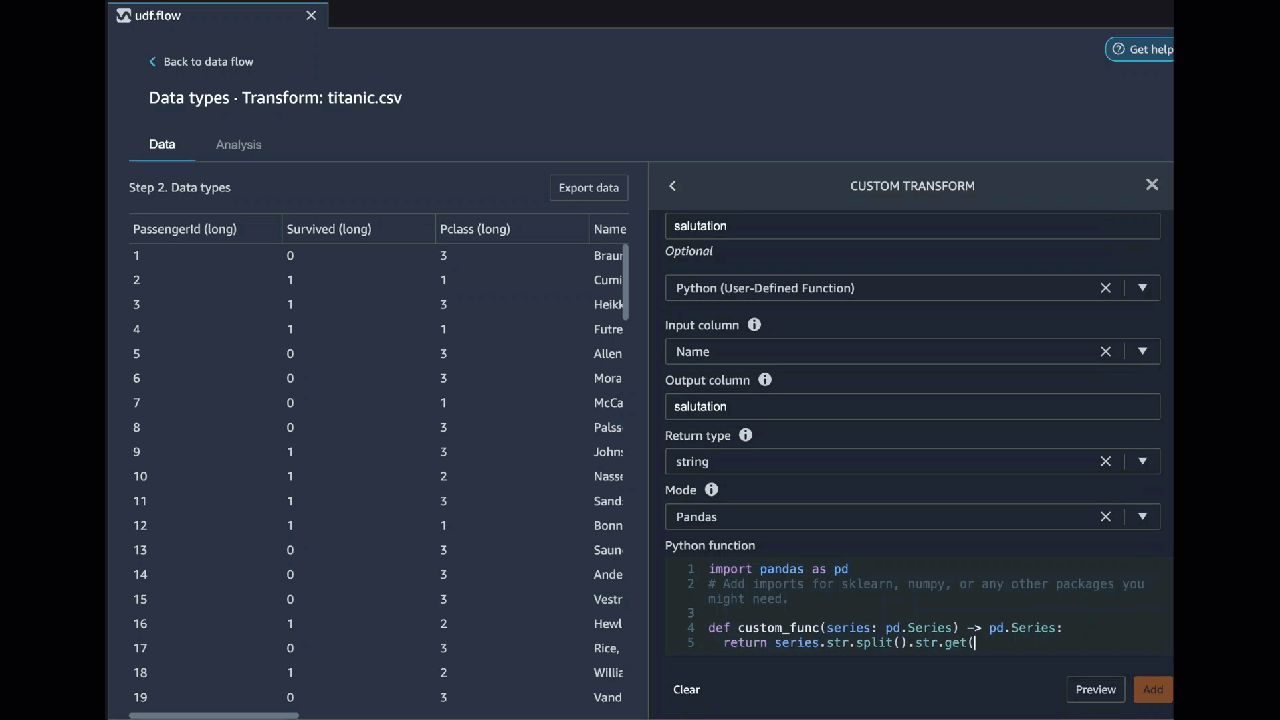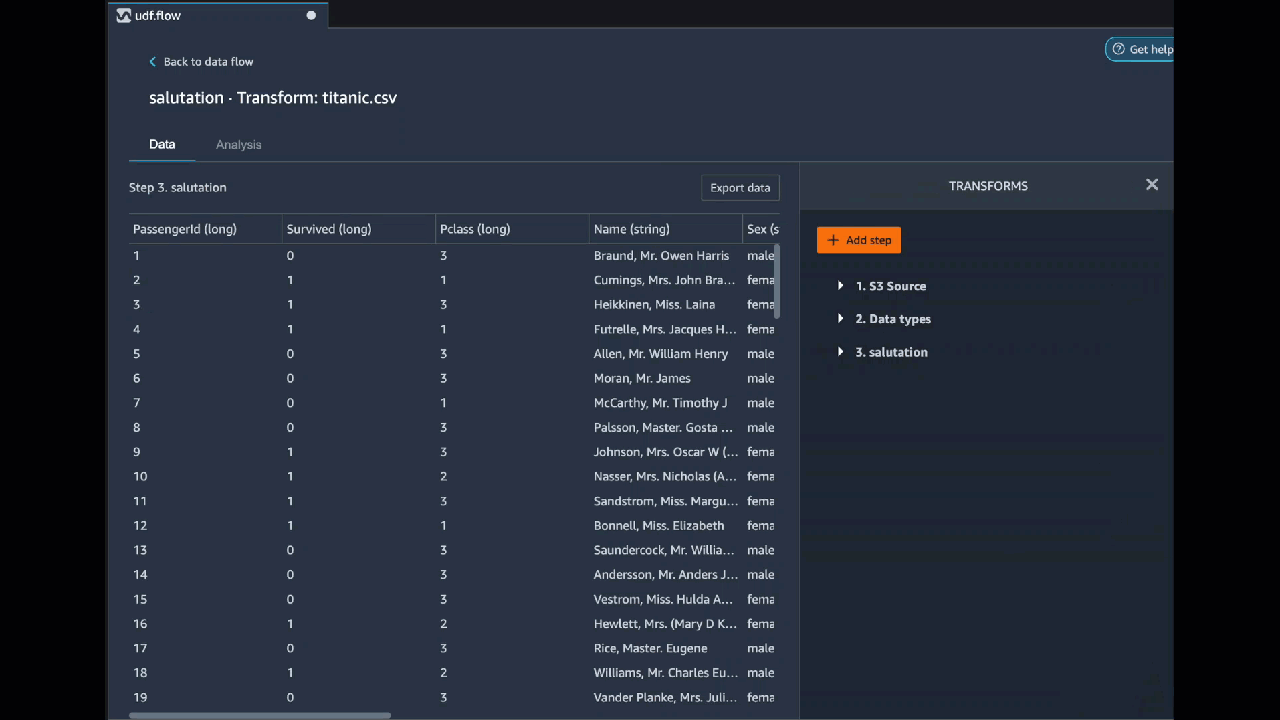
**Python (fonction définie par l’utilisateur)**
La fonction Python vous permet d'écrire des transformations personnalisées sans avoir besoin de connaître Apache Spark ou Pandas. Data Wrangler est optimisé pour exécuter rapidement votre code personnalisé. Vous obtenez des performances similaires en utilisant du code Python personnalisé et un plugin Apache Spark.
Pour utiliser le bloc de code Python (fonction définie par l’utilisateur), spécifiez ce qui suit :
+ **Input column** (Colonne d'entrée) : colonne d'entrée dans laquelle vous appliquez la transformation.
+ **Mode** : mode de scripting, pandas ou Python.
+ **Return type** (Type de retour) : type de données de la valeur que vous renvoyez.
L'utilisation du mode pandas offre de meilleures performances. Le mode Python facilite l'écriture de transformations en utilisant des fonctions Python pures.
La vidéo suivante présente un exemple d'utilisation de code personnalisé pour créer une transformation. Il utilise le jeu de données [Titanic](https://s3.us-west-2.amazonaws.com/amazon-sagemaker-data-wrangler-documentation-artifacts/walkthrough_titanic.csv) pour créer une colonne avec la civilité de la personne.
**PySpark**
L'exemple suivant extrait la date et l'heure d'un horodatage.
```
from pyspark.sql.functions import from_unixtime, to_date, date_format
df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP'))
df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn(
'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
```
**pandas**
L'exemple suivant fournit une vue d'ensemble du dataframe auquel vous ajoutez des transformations.
```
df.info()
```
**PySpark (SQL)**
L'exemple suivant permet de créer un nouveau dataframe avec quatre colonnes : *name* (nom), *fare* (tarif), *pclass* (classe de passager), *survived* (survivant).
```
SELECT name, fare, pclass, survived FROM df
```
Si vous ne savez pas comment vous en servir PySpark, vous pouvez utiliser des extraits de code personnalisés pour vous aider à démarrer.
Data Wrangler possède une collection interrogeable d'extraits de code. Vous pouvez utiliser les extraits de code pour effectuer des tâches telles que la suppression de colonnes, le regroupement par colonnes ou la modélisation.
Pour utiliser un extrait de code, choisissez **Search example snippets** (Rechercher dans les exemples d'extraits) et spécifiez une requête dans la barre de recherche. Le texte que vous spécifiez dans la requête ne doit pas nécessairement correspondre exactement au nom de l'extrait de code.
L'exemple suivant montre un extrait de code **Drop duplicate rows** (Supprimer les doublons de lignes) qui peut supprimer des lignes contenant des données similaires dans votre jeu de données. Vous pouvez trouver l'extrait de code en recherchant l'un des éléments suivants :
+ Duplicates (doublons)
+ Identical (éléments identiques)
+ Remove (suppression)
L'extrait de code suivant contient des commentaires qui vous aident à comprendre les modifications que vous devez apporter. Pour la plupart des extraits de code, vous devez spécifier les noms de colonnes de votre jeu de données dans le code.
```
# Specify the subset of columns
# all rows having identical values in these columns will be dropped
subset = ["col1", "col2", "col3"]
df = df.dropDuplicates(subset)
# to drop the full-duplicate rows run
# df = df.dropDuplicates()
```
Pour utiliser un extrait de code, copiez et collez son contenu dans le champ **Custom transform** (Transformation personnalisée). Vous pouvez copier et coller plusieurs extraits de code dans le champ de transformation personnalisé.
## Formule personnalisée
Utilisez **Custom formula (Formule personnalisée)** pour définir une nouvelle colonne à l'aide d'une expression Spark SQL pour interroger des données dans le dataframe actuel. La requête doit utiliser les conventions des expressions Spark SQL.
**Important**
**Custom formula** (Formule personnalisée) ne prend pas en charge les colonnes avec des espaces ou des caractères spéciaux dans le nom. Nous vous recommandons de spécifier des noms de colonnes contenant uniquement des caractères alphanumériques et des traits de soulignement. Vous pouvez utiliser la transformation **Rename column** (Renommer une colonne) dans le groupe de transformation **Manage columns** (Gérer les colonnes) pour supprimer des espaces du nom d'une colonne. Vous pouvez également ajouter une **Custom transform (Transformation personnalisée)** **Python (Pandas)** similaire à ce qui suit pour supprimer des espaces de plusieurs colonnes en une seule étape. Cet exemple modifie les colonnes nommées `A column` et `B column` en `A_column` et `B_column`, respectivement.
```
df.rename(columns={"A column": "A_column", "B column": "B_column"})
```
Vous pouvez utiliser cette transformation pour effectuer des opérations sur les colonnes, en référençant les colonnes par leur nom. Par exemple, en supposant que le dataframe actuel contient des colonnes nommées *col\_a* et *col\_b*, vous pouvez utiliser l'opération suivante pour produire une **Output column (Colonne de sortie)** qui est le produit de ces deux colonnes en utilisant le code suivant :
```
col_a * col_b
```
Les autres opérations courantes sont les suivantes, en supposant qu'un dataframe contient les colonnes `col_a` et `col_b` :
+ Concaténer deux colonnes : `concat(col_a, col_b)`
+ Ajouter deux colonnes : `col_a + col_b`
+ Soustraire deux colonnes : `col_a - col_b`
+ Diviser deux colonnes : `col_a / col_b`
+ Prendre la valeur absolue d'une colonne : `abs(col_a)`
Pour plus d’informations, consultez la [documentation Spark](http://spark.apache.org/docs/latest/api/python) sur la sélection des données.
## Réduire la dimensionnalité dans un jeu de données
Réduisez la dimensionnalité de vos données à l'aide de l'analyse des composants principaux (PCA). La dimensionnalité de votre jeu de données correspond au nombre de fonctionnalités. Lorsque vous utilisez la réduction de dimensionnalité dans Data Wrangler, vous obtenez un nouvel ensemble de fonctionnalités appelées composants. Chaque composant explique une partie de la variabilité des données.
Le premier composant est à l'origine de la plus grande variation des données. Le deuxième composant est à l'origine de la deuxième plus grande variation des données, et ainsi de suite.
Vous pouvez utiliser la réduction de dimensionnalité pour réduire la taille des jeux de données que vous utilisez pour entraîner des modèles. Au lieu d'utiliser les fonctionnalités de votre jeu de données, vous pouvez utiliser les composants principaux.
Pour effectuer l'analyse PCA, Data Wrangler crée des axes pour vos données. Un axe est une combinaison affine de colonnes dans votre jeu de données. Le premier composant principal est la valeur sur l'axe qui présente la plus grande variance. Le deuxième composant principal est la valeur sur l'axe qui présente la deuxième plus grande variance. Le nième composant principal est la valeur sur l'axe qui présente la nième plus grande variance.
Vous pouvez configurer le nombre de composants principaux renvoyés par Data Wrangler. Vous pouvez soit spécifier directement le nombre de composant principaux, soit spécifier le pourcentage de seuil de variance. Chaque composant principal explique l'ampleur de la variance des données. Par exemple, vous pouvez avoir un composant principal ayant la valeur 0,5. Le composant explique alors 50 % de la variation des données. Lorsque vous spécifiez un pourcentage de seuil de variance, Data Wrangler renvoie le plus petit nombre de composants correspondant au pourcentage que vous spécifiez.
Voici des exemples de composants principaux avec le degré de variance qu'ils expliquent dans les données.
+ Composant 1 — 0,5
+ Composant 2 — 0,45
+ Composant 3 — 0,05
Si vous spécifiez un pourcentage de seuil de variance de `94` ou `95`, Data Wrangler renvoie les composants 1 et 2. Si vous spécifiez un pourcentage de seuil de variance de `96`, Data Wrangler renvoie les trois composants principaux.
Vous pouvez utiliser la procédure suivante pour exécuter l'analyse PCA sur votre jeu de données.
Pour exécuter l'analyse PCA sur votre jeu de données, procédez comme suit.
1. Ouvrez votre flux de données Data Wrangler.
1. Choisissez le **\+**, puis sélectionnez **Add transform** (Ajouter une transformation).
1. Choisissez **Ajouter une étape**.
1. Choisissez **Dimensionality Reduction** (Réduction de dimensionnalité).
1. Pour **Input Columns** (Colonnes d'entrée), choisissez les fonctionnalités que vous souhaitez réduire en composants principaux.
1. (Facultatif) Pour **Number of principal components** (Nombre de composants principaux), choisissez le nombre de composants principaux que Data Wrangler renvoie dans votre jeu de données. Si vous spécifiez une valeur pour ce champ, vous ne pouvez pas spécifier de valeur pour le champ **Variance threshold percentage** (Pourcentage de seuil de variance).
1. (Facultatif) Pour **Variance threshold percentage** (Pourcentage de seuil de variance), spécifiez le pourcentage de variation des données que vous souhaitez expliquer par les composants principaux. Data Wrangler utilise la valeur par défaut `95` si vous ne spécifiez aucune valeur pour le seuil de variance. Vous ne pouvez pas spécifier de pourcentage de seuil de variance si vous avez spécifié une valeur dans le champ **Number of principal components** (Nombre de composants principaux).
1. (Facultatif) Désélectionnez **Center** (Centrer) pour ne pas utiliser la moyenne des colonnes comme centre des données. Par défaut, Data Wrangler centre les données sur la moyenne avant de les mettre à l'échelle.
1. (Facultatif) Désélectionnez **Scale** (Mettre à l'échelle) pour ne pas mettre les données à l'échelle avec l'écart type de l'unité.
1. (Facultatif) Choisissez **Columns** (Colonnes) pour afficher les composants dans des colonnes séparées. Choisissez **Vector** (Vecteur) pour générer les composants sous la forme d'un vecteur unique.
1. (Facultatif) Pour **Output column** (Colonne de sortie), spécifiez le nom de la colonne de sortie. Si vous affichez les composants sur des colonnes distinctes, le nom que vous spécifiez est un préfixe. Si vous affichez les composants sous la forme d'un vecteur, le nom que vous spécifiez est le nom de la colonne vectorielle.
1. (Facultatif) Sélectionnez **Keep input columns** (Conserver les colonnes d'entrée). Nous recommandons de ne pas sélectionner cette option si vous prévoyez d'utiliser uniquement les composants principaux pour entraîner votre modèle.
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
## Encodage catégoriel
Les données catégorielles sont généralement composées d'un nombre fini de catégories, où chacune d'elles est représentée par une chaîne. Par exemple, si vous disposez d'une table de données client, une colonne indiquant le pays dans lequel vit une personne est de type catégorie. Les catégories seraient *Afghanistan*, *Albania* (Albanie), *Algeria* (Algérie), etc. Les données de catégorie peuvent être *nominales* ou *ordinales*. Les catégories ordinales ont un ordre inhérent, et les catégories nominales n’en ont pas. Le diplôme le plus élevé obtenu (*High school* (Baccalauréat), *Bachelors* (Licence), *Masters* (Maîtrise), etc.) est un exemple de catégories ordinales.
Le codage des données catégorielles est le processus de création d’une représentation numérique pour les catégories. Par exemple, si vos catégories sont *Chien* et *Chat*, vous pouvez encoder ces informations en deux vecteurs : `[1,0]` pour représenter *Chien*, et `[0,1]` pour représenter *Chat*.
Lorsque vous encodez des catégories ordinales, vous devez parfois traduire l’ordre naturel des catégories dans votre codage. Par exemple, vous pouvez représenter le degré le plus élevé obtenu avec la carte suivante : `{"High school": 1, "Bachelors": 2, "Masters":3}`.
Utilisez le codage catégoriel pour encoder des données catégorielles au format chaîne dans des tableaux d’entiers.
Les codeurs catégoriels Data Wrangler créent des codages pour toutes les catégories qui existent dans une colonne au moment de la définition de l'étape. Si de nouvelles catégories ont été ajoutées à une colonne lorsque vous démarrez une tâche Data Wrangler pour traiter votre jeu de données au temps *t*, et que cette colonne était l'entrée d'une transformation d'encodage catégoriel Data Wrangler au temps *t-1*, ces nouvelles catégories sont considérées comme *manquantes* dans la tâche Data Wrangler. L'option que vous sélectionnez pour **Invalid handling strategy (Politique de gestion non valide)** est appliquée à ces valeurs manquantes. Voici des exemples de cas où cela peut se produire :
+ Lorsque vous utilisez un fichier .flow pour créer une tâche Data Wrangler dans le but de traiter un jeu de données mis à jour après la création du flux de données. Par exemple, vous pouvez utiliser un flux de données pour traiter régulièrement les données de vente chaque mois. Si ces données de vente sont mises à jour chaque semaine, de nouvelles catégories peuvent être introduites dans des colonnes pour lesquelles une étape de codage catégoriel est définie.
+ Lorsque vous sélectionnez **Sampling (Échantillonnage)** lors de l'importation de votre jeu de données, il se peut que certaines catégories soient exclues de l'échantillon.
Dans ces situations, ces nouvelles catégories sont considérées comme des valeurs manquantes dans la tâche Data Wrangler.
Vous pouvez choisir entre un *codage ordinal* ou un *codage à chaud* et le configurer. Utilisez les sections suivantes pour en savoir plus sur ces options.
Les deux transformations créent une nouvelle colonne nommée **Output column name (Nom de colonne de sortie)**. Vous spécifiez le format de sortie de cette colonne avec **Output style (Style de sortie)** :
+ Choisissez **Vector (Vecteur)** pour produire une seule colonne avec un vecteur fragmenté.
+ Choisissez **Columns (Colonne)** pour créer une colonne pour chaque catégorie avec une variable indicatrice pour savoir si le texte de la colonne d'origine contient une valeur égale à cette catégorie.
### Encodage ordinal
Choisissez **Ordinal encode (Encodage ordinal)** pour encoder les catégories dans un entier compris entre 0 et le nombre total de catégories dans **Input column (Colonne d'entrée)** que vous sélectionnez.
**Invalid handing strategy (Politique de remise non valide)** : sélectionnez une méthode pour gérer les valeurs invalides ou manquantes.
+ Choisissez **Skip (Ignorer)** si vous souhaitez omettre les lignes avec des valeurs manquantes.
+ Choisissez **Keep (Conserver)** pour conserver les valeurs manquantes comme dernière catégorie.
+ Choisissez **Error (Erreur)** si vous voulez que Data Wrangler lance une erreur si des valeurs manquantes sont rencontrées dans **Input column (Colonne d'entrée)**.
+ Choisissez **Replace with NaN (Remplacer par NaN)** pour remplacer les valeurs manquantes par NaN. Cette option est recommandée si votre algorithme ML peut gérer les valeurs manquantes. Sinon, les trois premières options de cette liste pourraient produire de meilleurs résultats.
### Encodage à chaud
Choisissez **One-hot encode (Encodage à chaud)** pour **Transform (Transformation)** afin d'utiliser un codage à chaud. Configurez cette transformation à l'aide des éléments suivants :
+ **Drop last category (Supprimer la dernière catégorie)** : si la valeur est `True`, la dernière catégorie n'a pas d'index correspondant dans le codage à chaud. Lorsque des valeurs manquantes sont possibles, une catégorie manquante est toujours la dernière et si la valeur est `True`, cela signifie qu'une valeur manquante donne lieu à un vecteur entièrement nul.
+ **Invalid handing strategy (Politique de remise non valide)** : sélectionnez une méthode pour gérer les valeurs invalides ou manquantes.
+ Choisissez **Skip (Ignorer)** si vous souhaitez omettre les lignes avec des valeurs manquantes.
+ Choisissez **Keep (Conserver)** pour conserver les valeurs manquantes comme dernière catégorie.
+ Choisissez **Error (Erreur)** si vous voulez que Data Wrangler lance une erreur si des valeurs manquantes sont rencontrées dans **Input column (Colonne d'entrée)**.
+ **Is input ordinal encoded (L'entrée est codée en ordinal)** : sélectionnez cette option si le vecteur d'entrée contient des données encodées en ordinal. Cette option nécessite que les données d'entrée contiennent des entiers non négatifs. Si la valeur est **Vrai**, l’entrée *i* est codée en tant que vecteur avec une valeur non nulle dans la *i*ème position.
### Encodage des similarités
Utilisez l'encodage des similarités lorsque vous disposez des éléments suivants :
+ Un grand nombre de variables catégorielles
+ Des données bruyantes
L'encodeur de similarités crée des incorporations pour les colonnes contenant des données catégorielles. Une incorporation est un mappage d'objets discrets, tels que des mots, sur des vecteurs de nombres réels. L'encodeur encode des chaînes similaires à des vecteurs contenant des valeurs similaires. Par exemple, il crée des encodages très semblables pour « Californie » et « Calfornie ».
Data Wrangler convertit chaque catégorie du jeu de données en un ensemble de jetons à l'aide d'un générateur de jetons trigramme. Il convertit les jetons en une incorporation à l'aide d'un encodage à hachage minimal.
L’exemple suivant montre comment l’encodeur de similarités crée des vecteurs à partir de chaînes.
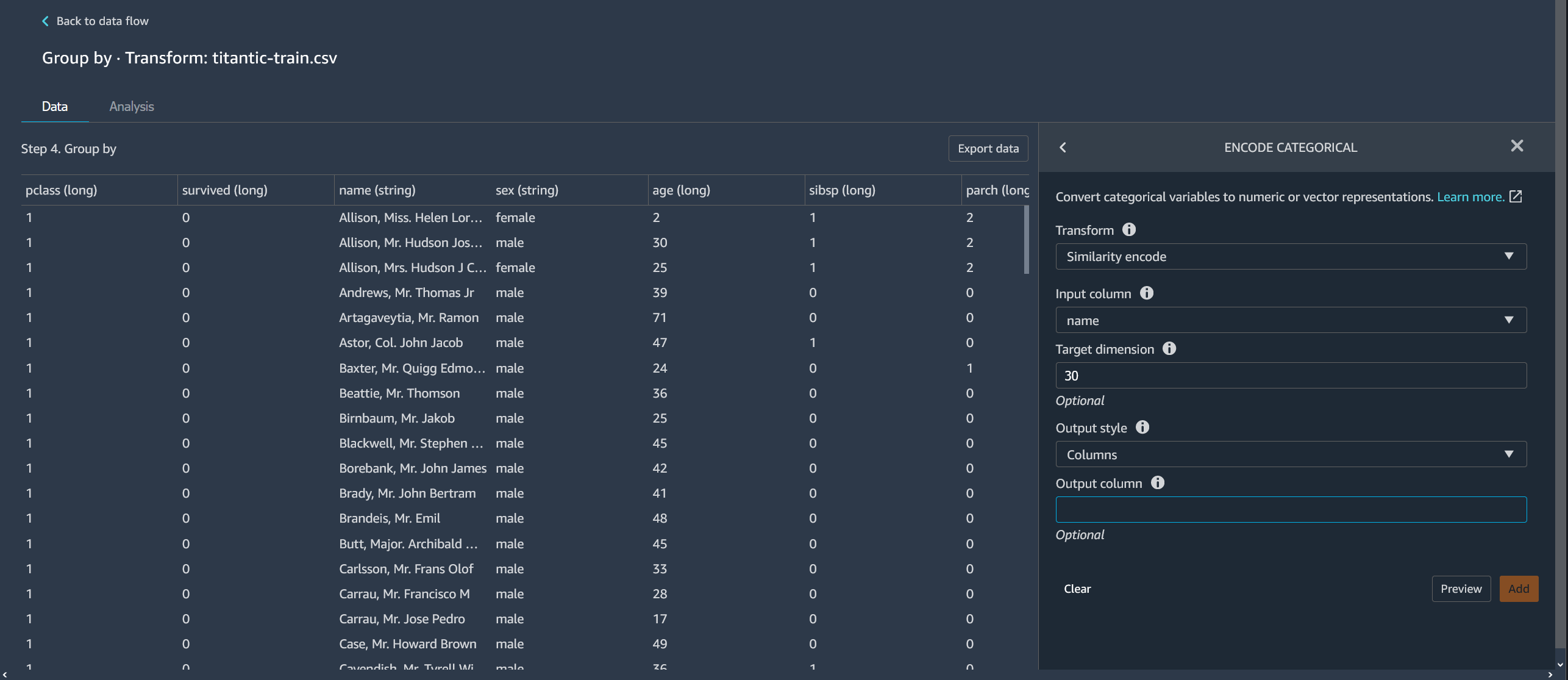
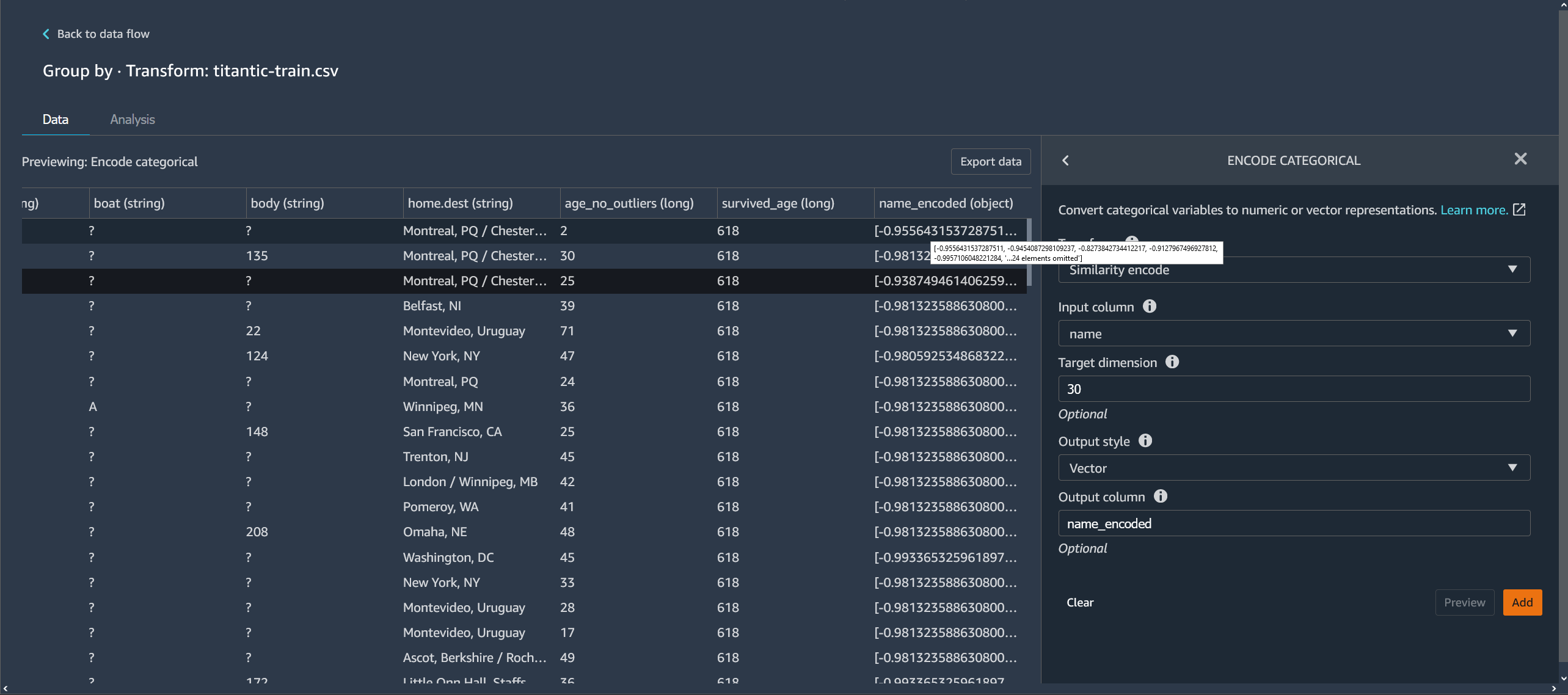
Les encodages de similarités créés par Data Wrangler :
+ présentent une faible dimensionnalité ;
+ sont évolutifs pour un grand nombre de catégories ;
+ sont robustes et résistants au bruit.
Pour les raisons précédentes, l'encodage des similarités est plus polyvalent qu'un encodage à chaud.
Pour ajouter l'encodage des similarités comme transformation à votre jeu de données, procédez comme suit.
Pour utiliser l’encodage des similarités, procédez comme suit.
1. Connectez-vous à la [console Amazon SageMaker AI](https://console.aws.amazon.com/sagemaker/).
1. Choisissez **Ouvrir Studio Classic**.
1. Choisissez **Lancer l’application**.
1. Choisissez **Studio**.
1. Spécifiez votre flux de données.
1. Choisissez une étape avec une transformation.
1. Choisissez **Ajouter une étape**.
1. Choisissez **Encode categorical** (Encodage catégoriel).
1. Spécifiez les paramètres suivants :
+ **Transform** (Transformation) : **Similarity encode** (Encodage des similarités)
+ **Colonne d’entrée** : colonne contenant les données catégorielles que vous encodez.
+ **Target dimension** (Dimension cible) : (facultatif) dimension du vecteur d'incorporation catégoriel. La valeur par défaut est 30. Nous recommandons d'utiliser une dimension cible plus grande si vous disposez d'un jeu de données volumineux comportant de nombreuses catégories.
+ **Output style** (Style de sortie) : choisissez **Vector** (Vecteur) pour obtenir un vecteur unique avec toutes les valeurs encodées. Choisissez **Colonne** pour obtenir les valeurs encodées dans des colonnes distinctes.
+ **Colonne de sortie** : (facultatif) nom de la colonne de sortie pour une sortie encodée dans un vecteur. Pour une sortie encodée dans des colonnes, il s'agit du préfixe du nom des colonnes suivi du numéro répertorié.
## Texte enrichi
Utilisez le groupe de transformation **Featurize Text** (Texte enrichi) pour inspecter les colonnes de type chaîne de caractères et utiliser l'encapsulation de texte pour enrichir ces colonnes.
Ce groupe de caractéristiques contient deux caractéristiques, *Statistiques de caractères* et *Vectoriser*. Utilisez les sections suivantes pour en apprendre plus sur ces options. Pour les deux options, **Input column (Colonne d'entrée)** doit contenir des données de texte (type chaîne).
### Statistiques de caractères
Utilisez **Statistiques de caractères** pour générer des statistiques pour chaque ligne d’une colonne contenant des données textuelles.
Cette transformation calcule les ratios et les dénombrements suivants pour chaque ligne, et crée une nouvelle colonne pour signaler le résultat. La nouvelle colonne est nommée en utilisant le nom de la colonne en entrée comme préfixe et un suffixe spécifique au ratio ou au nombre.
+ **Number of words** (Nombre de mots) : nombre total de mots dans cette ligne. Le suffixe de cette colonne de sortie est `-stats_word_count`.
+ **Number of characters** (Nombre de caractères) : nombre total de caractères dans cette ligne. Le suffixe de cette colonne de sortie est `-stats_char_count`.
+ **Ratio of upper** (Ratio des majuscules) : nombre de caractères majuscules, de A à Z, divisé par le nombre total de caractères dans la colonne. Le suffixe de cette colonne de sortie est `-stats_capital_ratio`.
+ **Ratio of lower** (Ratio des minuscules) : nombre de caractères minuscules, de a à z, divisé par le nombre total de caractères dans la colonne. Le suffixe de cette colonne de sortie est `-stats_lower_ratio`.
+ **Ratio of digits** (Ratio des chiffres) : ratio du nombre de chiffres dans une ligne unique par rapport à la somme des chiffres dans la colonne d'entrée. Le suffixe de cette colonne de sortie est `-stats_digit_ratio`.
+ **Special characters ratio** (Ration des caractères spéciaux) : ratio des caractères non alphanumériques (caractères tels que \#\$&%:@) par rapport à la somme de tous les caractères dans la colonne d'entrée. Le suffixe de cette colonne de sortie est `-stats_special_ratio`.
### Vectorisation
La vectorisation de texte consiste à mettre en correspondance des mots ou des phrases d’un vocabulaire avec des vecteurs de nombres réels. Utilisez la transformation d'encapsulation de texte de Data Wrangler pour créer des jetons et vectoriser les données de texte en vecteurs TF-IDF (fréquence de document inverse).
Lorsque TF-IDF est calculé pour une colonne de données textuelles, chaque mot de chaque phrase est converti en nombre réel qui représente son importance sémantique. Des nombres plus élevés sont associés à des mots moins fréquents, qui ont tendance à être plus significatifs.
Lorsque vous définissez une étape de transformation **Vectorize** (Vectorisation), Data Wrangler utilise les données de votre jeu de données pour définir le vectorisateur de comptage et les méthodes TF-IDF. Ces mêmes méthodes sont utilisées lors de l'exécution d'une tâche Data Wrangler.
Vous configurez cette transformation à l’aide des éléments suivants :
+ **Output column name** (Nom de colonne de sortie) : cette transformation crée une nouvelle colonne avec l'encapsulation du texte. Utilisez ce champ pour spécifier un nom pour cette colonne de sortie.
+ **Tokenizer (Créateur de jetons)** : un tokenizer convertit la phrase en une liste de mots, ou *jetons*.
Choisissez **Standard** pour utiliser un tokenizer qui sépare les mots par des espaces vides et convertit chaque mot en minuscules. Par exemple, `"Good dog"` est tokenizé en `["good","dog"]`.
Choisissez **Custom (Personnalisé)** pour utiliser un tokenizer personnalisé. Si vous choisissez **Custom (Personnalisé)**, vous pouvez utiliser les champs suivants pour configurer le jeton :
+ **Minimum token length (Longueur minimum du jeton)** : longueur minimale, en caractères, pour qu'un jeton soit valide. La valeur par défaut est `1` . Par exemple, si vous spécifiez `3` comme longueur minimale du jeton, les mots comme `a, at, in` sont supprimés de la phrase tokenisée.
+ **Should regex split on gaps (La regex doit-elle se diviser en espaces)** : si cette option est sélectionnée, **regex** se divise en espaces. Sinon, la valeur correspond aux jetons. La valeur par défaut est `True` .
+ **Regex pattern (Motif Regex)** : modèle regex qui définit le processus de création de jeton. La valeur par défaut est `' \\ s+'` .
+ **To lowercase** (En minuscules) : si cette option est sélectionnée, Data Wrangler convertit tous les caractères en minuscules avant la création de jeton. La valeur par défaut est `True` .
Pour en savoir plus, consultez la rubrique sur la [création de jetons](https://spark.apache.org/docs/latest/ml-features#tokenizer) de la documentation Spark.
+ **Vectoriseur** : le vectoriseur convertit la liste des jetons en un vecteur numérique fragmenté. Chaque jeton correspond à un index dans le vecteur et une valeur non-nulle indique l'existence du jeton dans la phrase d'entrée. Vous avez le choix entre deux options de vectoriseur, *Count (Nombre)* et *Hashing (Hachage)*.
+ **Count vectorize (Comptage vectoriel)** permet des personnalisations qui filtrent des jetons peu fréquents ou trop courants. **Les paramètres de comptage vectoriel** comprennent notamment :
+ **Minimum term frequency (Périodicité minimum)** : dans chaque ligne, les termes (jetons) avec une fréquence plus faible sont filtrés. Si vous spécifiez un entier, il s'agit d'un seuil absolu (inclusif). Si vous spécifiez une fraction comprise entre 0 (inclusif) et 1, le seuil est relatif au nombre total de termes. La valeur par défaut est `1` .
+ **Minimum document frequency (Fréquence minimale des documents)** : nombre minimum de lignes dans lesquelles un terme (jeton) doit apparaître pour être inclus. Si vous spécifiez un entier, il s'agit d'un seuil absolu (inclusif). Si vous spécifiez une fraction comprise entre 0 (inclusif) et 1, le seuil est relatif au nombre total de termes. La valeur par défaut est `1` .
+ **Maximum document frequency (Fréquence maximale des documents)** : nombre maximal de documents (lignes) dans lesquels un terme (jeton) peut apparaître pour être inclus. Si vous spécifiez un entier, il s'agit d'un seuil absolu (inclusif). Si vous spécifiez une fraction comprise entre 0 (inclusif) et 1, le seuil est relatif au nombre total de termes. La valeur par défaut est `0.999` .
+ **Maximum vocabulary size (Taille maximum du vocabulaire)** : taille maximale du vocabulaire. Le vocabulaire est composé de tous les termes (jetons) de toutes les lignes de la colonne. La valeur par défaut est `262144` .
+ **Binary outputs (Sorties binaires)** : si cette option est sélectionnée, les sorties vectorielles n'incluent pas le nombre d'apparitions d'un terme dans un document, mais constituent plutôt un indicateur binaire de son apparition. La valeur par défaut est `False` .
Pour en savoir plus sur cette option, consultez la documentation de Spark sur [CountVectorizer](https://spark.apache.org/docs/latest/ml-features#countvectorizer).
+ **Hachage** est plus rapide sur le plan informatique. **Les paramètres de hachage** comprennent notamment :
+ **Number of features during hashing (Nombre de fonctions pendant le hachage)** : un vectorisateur de hachage mappe les jetons à un index vectoriel en fonction de leur valeur de hachage. Cette fonction détermine le nombre de valeurs de hachage possibles. Les valeurs élevées entraînent moins de collisions entre les valeurs de hachage, mais un vecteur de sortie de dimension plus élevée.
Pour en savoir plus sur cette option, consultez la documentation de Spark sur [FeatureHasher](https://spark.apache.org/docs/latest/ml-features#featurehasher)
+ **Apply IDF** (Appliquer IDF) : applique une transformation IDF qui multiplie la fréquence du terme par la fréquence du document inverse standard utilisée pour l'encapsulation TF-IDF. Les **paramètres IDF** comprennent les suivants :
+ **Minimum document frequency (Fréquence minimale des documents)** : nombre minimal de documents (lignes) dans lesquels un terme (jeton) doit apparaître pour être inclus. Si **count\_vectorize** est le vectorisateur choisi, nous vous recommandons de conserver la valeur par défaut et de ne modifier que le champ **min\_doc\_freq** dans **Count vectorize parameters (Paramètres de comptage vectoriel)**. La valeur par défaut est `5` .
+ **Output format (Format de sortie)** : le format de sortie de chaque ligne.
+ Choisissez **Vector (Vecteur)** pour produire une seule colonne avec un vecteur fragmenté.
+ Choisissez **Flattened (Aplati)** pour créer une colonne pour chaque catégorie avec une variable indicatrice indiquant si le texte de la colonne d'origine contient une valeur égale à cette catégorie. Vous ne pouvez choisir flattened (aplati) que lorsque **Vectoriseur** est défini sur **Comptage vectoriel**.
## Transformer les séries temporelles
Dans Data Wrangler, vous pouvez transformer les données de séries temporelles. Les valeurs d'un jeu de données de séries temporelles sont indexées à une heure spécifique. Par exemple, un jeu de données qui affiche le nombre de clients dans un magasin pour chaque heure de la journée est un jeu de données de série temporelle. Le tableau suivant présente un exemple d'un jeu de données de série temporelle.
Nombre de clients par heure dans un magasin
| Nombre de clients | Heure (heure) |
| --- | --- |
| 4 | 09:00 |
| 10 | 10h00 |
| 14 | 11h00 |
| 25 | 12h00 |
| 20 | 13h00 |
| 18 | 14h00 |
Dans le tableau précédent, la colonne **Nombre de clients** contient les données en séries chronologiques. Les données de séries temporelles sont indexées aux données horaires dans la colonne **Time (hour)** (Heure (heure)).
Vous devrez peut-être effectuer une série de transformations sur vos données pour les obtenir dans un format que vous pouvez utiliser pour votre analyse. Utilisez le groupe de transformation **Times series** (Séries temporelles) pour transformer vos données de séries temporelles. Pour plus d’informations sur les transformations que vous pouvez effectuer, consultez les sections suivantes.
**Topics**
+ [Grouper par série temporelle](#data-wrangler-group-by-time-series)
+ [Rééchantillonner les données de séries temporelles](#data-wrangler-resample-time-series)
+ [Gestion des données de séries temporelles manquantes](#data-wrangler-transform-handle-missing-time-series)
+ [Validation de l'horodatage de vos données de séries temporelles](#data-wrangler-transform-validate-timestamp)
+ [Standardisation de la longueur des séries temporelles](#data-wrangler-transform-standardize-length)
+ [Extraire des fonctions de vos données de séries temporelles](#data-wrangler-transform-extract-time-series-features)
+ [Utiliser des ressources décalées issues de vos données de séries temporelles](#data-wrangler-transform-lag-time-series)
+ [Créer une plage de date/heure dans votre série temporelle](#data-wrangler-transform-datetime-range)
+ [Utiliser une fenêtre propagée dans votre série temporelle](#data-wrangler-transform-rolling-window)
### Grouper par série temporelle
Vous pouvez utiliser l’opération Group by (Regrouper par) afin de regrouper des données de séries temporelles pour des valeurs spécifiques dans une colonne.
Par exemple, le tableau suivant suit la consommation quotidienne moyenne d'électricité d'un ménage.
Consommation quotidienne moyenne d'électricité d'un ménage
| ID du ménage | Horodatage quotidien | Consommation d'électricité (kWh) | Nombre d'occupants du ménage |
| --- | --- | --- | --- |
| ménage\_0 | 01/01/2020 | 30 | 2 |
| ménage\_0 | 02/01/2020 | 40 | 2 |
| ménage\_0 | 04/01/2020 | 35 | 3 |
| ménage\_1 | 02/01/2020 | 45 | 3 |
| ménage\_1 | 03/01/2020 | 55 | 4 |
Si vous choisissez de regrouper les ménages par ID, le tableau suivant s'affiche.
Consommation d'électricité regroupée par ID de ménage
| ID du ménage | Série Consommation d'électricité (kWh) | Série Nombre d'occupants du ménage |
| --- | --- | --- |
| ménage\_0 | [30, 40, 35] | [2, 2, 3] |
| ménage\_1 | [45, 55] | [3, 4] |
Chaque entrée de la séquence des séries temporelles est classée en fonction de l'horodatage correspondant. Le premier élément de la séquence correspond au premier horodatage de la série. Pour `household_0`, `30` est la première valeur de la série **Consommation d’électricité**. La valeur de `30` correspond au premier horodatage de `1/1/2020`.
Vous pouvez inclure l’horodatage de début et l’horodatage de fin. Le tableau suivant illustre la manière dont ces informations s'affichent.
Consommation d'électricité regroupée par ID de ménage
| ID du ménage | Série Consommation d'électricité (kWh) | Série Nombre d'occupants du ménage | Start\_Time | End\_Time |
| --- | --- | --- | --- | --- |
| ménage\_0 | [30, 40, 35] | [2, 2, 3] | 01/01/2020 | 04/01/2020 |
| ménage\_1 | [45, 55] | [3, 4] | 02/01/2020 | 03/01/2020 |
Vous pouvez utiliser la procédure suivante pour regrouper par colonne de séries temporelles.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Séries temporelles**.
1. Sous **Transform** (Transformer), choisissez **Group by** (Grouper par).
1. Spécifiez une colonne dans **Group by this column** (Grouper par cette colonne).
1. Pour **Appliquer aux colonnes**, spécifiez une valeur.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Rééchantillonner les données de séries temporelles
Les données de séries temporelles contiennent généralement des observations qui ne sont pas effectuées à intervalles réguliers. Par exemple, un jeu de données peut comporter des observations enregistrées toutes les heures et d'autres observations enregistrées toutes les deux heures.
De nombreuses analyses, telles que les algorithmes de prédiction, exigent que les observations soient effectuées à intervalles réguliers. Le rééchantillonnage vous permet d'établir des intervalles réguliers pour les observations de votre jeu de données.
Vous pouvez rééchantillonner ou sous-échantillonner une série temporelle. Le sous-échantillonnage augmente l'intervalle entre les observations dans le jeu de données. Par exemple, si vous sous-échantillonnez les observations qui sont effectuées toutes les heures ou toutes les deux heures, chaque observation de votre jeu de données est effectuée toutes les deux heures. Les observations horaires sont agrégées en une seule valeur à l'aide d'une méthode d'agrégation telle que la moyenne ou la médiane.
Le suréchantillonnage réduit l'intervalle entre les observations dans le jeu de données. Par exemple, si vous rééchantillonnez les observations effectuées toutes les deux heures en observations horaires, vous pouvez utiliser une méthode d'interpolation pour déduire les observations horaires de celles qui sont effectuées toutes les deux heures. Pour plus d'informations sur les méthodes d'interpolation, voir [pandas. DataFrame.interpoler](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html).
Vous pouvez rééchantillonner à la fois des données numériques et non numériques.
Utilisez l’opération **Resample** (Rééchantillonner) pour rééchantillonner vos données de séries temporelles. Si vous avez plusieurs séries temporelles dans votre jeu de données, Data Wrangler standardise l’intervalle de temps pour chaque série temporelle.
Voici un exemple de sous-échantillonnage des données de séries temporelles en utilisant la moyenne comme méthode d'agrégation. Les données sont sous-échantillonnées toutes les deux heures à toutes les heures.
Lectures de températures horaires plus d'un jour avant le sous-échantillonnage
| Horodatage | Température (Celsius) |
| --- | --- |
| 12h00 | 30 |
| 1h00 | 32 |
| 2h00 | 35 |
| 3h00 | 32 |
| 4h00 | 30 |
Lectures de températures sous-échantillonnées toutes les deux heures
| Horodatage | Température (Celsius) |
| --- | --- |
| 12h00 | 30 |
| 2:00 | 33,5 |
| 4h00 | 35 |
Vous pouvez utiliser la procédure suivante pour rééchantillonner des données de séries temporelles.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Rééchantillonner**.
1. Pour **Horodatage**, choisissez la colonne d’horodatage.
1. Pour **Frequency unit** (Unité de fréquence), spécifiez la fréquence que vous rééchantillonnez.
1. (Facultatif) Spécifiez une valeur pour **Quantité de fréquence**.
1. Configurez la transformation en spécifiant les champs restants.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Gestion des données de séries temporelles manquantes
Si vous ne disposez pas de valeurs dans votre jeu de données, vous pouvez effectuer l'une des actions suivantes :
+ Pour les jeux de données comportant plusieurs séries temporelles, supprimez les séries temporelles qui comportent des valeurs manquantes supérieures à un seuil spécifié.
+ Imputez les valeurs manquantes d'une série temporelle en utilisant d'autres valeurs de la série temporelle.
L'imputation d'une valeur manquante implique le remplacement des données en spécifiant une valeur ou en utilisant une méthode inférentielle. Voici les méthodes que vous pouvez utiliser pour l'imputation :
+ Valeur constante : remplacez toutes les données manquantes dans votre jeu de données par une valeur que vous spécifiez.
+ Valeur la plus courante : remplacez toutes les données manquantes par la valeur ayant la fréquence la plus élevée dans le jeu de données.
+ Remplissage avant : utilisez le remplissage avant pour remplacer les valeurs manquantes par la valeur non manquante qui précède les valeurs manquantes. Pour la séquence [2, 4, 7, NaN, NaN, NaN, 8], toutes les valeurs manquantes sont remplacées par 7. La séquence résultant de l'utilisation d'un remplissage avant est [2, 4, 7, 7, 7, 7, 8].
+ Remplissage arrière : utilisez le remplissage arrière pour remplacer les valeurs manquantes par la valeur non manquante qui suit les valeurs manquantes. Pour la séquence : [2, 4, 7, NaN, NaN, NaN, 8], toutes les valeurs manquantes sont remplacées par 8. La séquence résultant de l'utilisation d'un remplissage arrière est [2, 4, 7, 8, 8, 8, 8].
+ Interpolation : utilise une fonction d'interpolation pour imputer les valeurs manquantes. Pour plus d'informations sur les fonctions que vous pouvez utiliser pour l'interpolation, voir [pandas. DataFrame.interpoler](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html).
Certaines méthodes d'imputation ne peuvent pas imputer toutes les valeurs manquantes de votre jeu de données. Par exemple, le **remplissage avant** ne peut pas imputer une valeur manquante qui apparaît au début de la série temporelle. Vous pouvez imputer les valeurs à l'aide d'un remplissage avant ou d'un remplissage arrière.
Vous pouvez imputer des valeurs manquantes dans une cellule ou dans une colonne.
L'exemple suivant montre comment les valeurs sont imputées dans une cellule.
Consommation d'électricité avec des valeurs manquantes
| ID du ménage | Série Consommation d'électricité (kWh) |
| --- | --- |
| ménage\_0 | [30, 40, 35, NaN, NaN] |
| ménage\_1 | [45, NaN, 55] |
Consommation d'électricité avec valeurs imputées à l'aide d'un remplissage à terme
| ID du ménage | Série Consommation d'électricité (kWh) |
| --- | --- |
| ménage\_0 | [30, 40, 35, 35, 35] |
| ménage\_1 | [45, 45, 55] |
L'exemple suivant montre comment les valeurs sont imputées dans une colonne.
Consommation quotidienne moyenne d'électricité d'un ménage avec des valeurs manquantes
| ID du ménage | Consommation d'électricité (kWh) |
| --- | --- |
| ménage\_0 | 30 |
| ménage\_0 | 40 |
| ménage\_0 | NaN |
| ménage\_1 | NaN |
| ménage\_1 | NaN |
Consommation quotidienne moyenne d'électricité d'un ménage avec des valeurs imputées à l'aide d'un remplissage à terme
| ID du ménage | Consommation d'électricité (kWh) |
| --- | --- |
| ménage\_0 | 30 |
| ménage\_0 | 40 |
| ménage\_0 | 40 |
| ménage\_1 | 40 |
| ménage\_1 | 40 |
Vous pouvez utiliser la procédure suivante pour gérer les valeurs manquantes.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Handle missing** (Gérer les valeurs manquantes).
1. Pour **Time series input type** (Type d'entrée de série temporelle), indiquez si vous souhaitez gérer les valeurs manquantes à l'intérieur d'une cellule ou le long d'une colonne.
1. Pour **Impute missing values for this column** (Imputer les valeurs manquantes de cette colonne), spécifiez la colonne contenant les valeurs manquantes.
1. Pour **Method for imputing values** (Méthode d'imputation des valeurs), sélectionnez une méthode.
1. Configurez la transformation en spécifiant les champs restants.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Si vous avez des valeurs manquantes, vous pouvez spécifier une méthode pour les imputer sous **Method for imputing values** (Méthode d'imputation des valeurs).
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Validation de l'horodatage de vos données de séries temporelles
Il se peut que certaines données d’horodatage ne soient pas valides. Vous pouvez utiliser la fonction **Validate time stamp** (Valider l'horodatage) pour déterminer si les horodatages de votre jeu de données sont valides. Votre horodatage peut être invalide pour une ou plusieurs des raisons suivantes :
+ Votre colonne d'horodatage présente des valeurs manquantes.
+ Les valeurs de votre colonne d'horodatage ne sont pas formatées correctement.
Si vous avez des horodatages non valides dans votre jeu de données, vous ne pouvez pas effectuer votre analyse correctement. Vous pouvez utiliser Data Wrangler pour identifier les horodatages non valides et comprendre où vous devez nettoyer vos données.
La validation des séries temporelles fonctionne de l’une des deux manières suivantes :
Vous pouvez configurer Data Wrangler pour effectuer l'une des actions suivantes s'il rencontre des valeurs manquantes dans votre jeu de données :
+ Supprimez les lignes avec les valeurs manquantes ou non valides.
+ Identifiez les lignes avec les valeurs manquantes ou non valides.
+ Lancez une erreur s’il détecte des valeurs manquantes ou non valides dans votre jeu de données.
Vous pouvez valider les horodatages sur les colonnes de type `timestamp` ou `string`. Si la colonne comporte le type `string`, Data Wrangler convertit le type de la colonne en `timestamp` et effectue la validation.
Vous pouvez utiliser la procédure suivante pour valider les horodatages dans votre jeu de données.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Valider les horodatages**.
1. Pour **Timestamp Column** (Colonne d'horodatage), choisissez la colonne d'horodatage.
1. Pour **Policy** (Politique), choisissez si vous souhaitez gérer les horodatages manquants.
1. (Facultatif) Pour **Colonne de sortie**, spécifiez le nom de la colonne de sortie.
1. Si la colonne de date et d’heure est formatée pour le type de chaîne, choisissez **Conversion en valeur datetime**.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Standardisation de la longueur des séries temporelles
Si des données de séries temporelles sont stockées sous forme de tableaux, vous pouvez standardiser chaque série temporelle à la même longueur. La standardisation de la longueur du tableau de séries temporelles peut faciliter l’exécution de votre analyse sur les données.
Vous pouvez standardiser vos séries temporelles pour les transformations de données nécessitant la correction de la longueur de vos données.
De nombreux algorithmes ML exigent que vous aplatiez vos données de séries temporelles avant de les utiliser. L'aplatissement des données de séries temporelles consiste à séparer chaque valeur de la série temporelle dans sa propre colonne dans un jeu de données. Le nombre de colonnes d'un jeu de données ne peut pas changer. Par conséquent, les longueurs de la série temporelle doivent être standardisées en aplatissant chaque tableau en un ensemble de ressources.
Chaque série temporelle est définie sur la longueur que vous spécifiez sous forme de quantile ou de centile du jeu de séries temporelles. Par exemple, vous pouvez avoir trois séquences ayant les longueurs suivantes :
+ 3
+ 4
+ 5
Vous pouvez définir la longueur de toutes les séquences comme étant la longueur de la séquence ayant la longueur du 50e centile.
Des valeurs manquantes sont ajoutées aux tableaux de séries temporelles qui sont inférieures à la longueur spécifiée. Voici un exemple de format de standardisation de série temporelle en longueur supérieure : [2, 4, 5, NaN, NaN, NaN].
Vous pouvez utiliser différentes approches pour gérer les valeurs manquantes. Pour plus d’informations sur ces approches, consultez [Gestion des données de séries temporelles manquantes](#data-wrangler-transform-handle-missing-time-series).
Les tableaux de séries temporelles qui sont plus longues que la longueur spécifiée sont tronqués.
Vous pouvez utiliser la procédure suivante pour standardiser la longueur des séries temporelles.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Standardize length** (Standardiser la longueur).
1. Pour **Standardiser la longueur des séries temporelles de la colonne**, choisissez une colonne.
1. (Facultatif) Pour **Output column** (Colonne de sortie), spécifiez le nom de la colonne de sortie. Si vous ne spécifiez pas de nom, la transformation est effectuée sur place.
1. Si la colonne de date et d'heure (datetime) est formatée pour le type de chaîne, choisissez **Cast to datetime** (Conversion en valeur datetime).
1. Choisissez **Cutoff quantile** (Quantile de coupure) et spécifiez un quantile pour définir la longueur de la séquence.
1. Choisissez **Aplatir la sortie** pour afficher les valeurs de la série temporelle dans des colonnes distinctes.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Extraire des fonctions de vos données de séries temporelles
Si vous exécutez une classification ou un algorithme de régression sur vos données de séries temporelles, nous vous recommandons d'extraire des ressources de la série temporelle avant d'exécuter l'algorithme. L'extraction de ressources peut améliorer la performance de votre algorithme.
Utilisez les options suivantes pour choisir la façon dont vous souhaitez extraire des ressources de vos données :
+ Utilisez **Minimal subset** (Sous-ensemble minimal) pour spécifier l'extraction de 8 ressources que vous savez utiles dans les analyses en aval. Vous pouvez utiliser un sous-ensemble minimal lorsque vous devez effectuer des calculs rapidement. Vous pouvez également l'utiliser lorsque votre algorithme ML présente un risque élevé de surajustement et que vous souhaitez lui fournir moins de ressources.
+ Utilisez **Efficient subset** (Sous-ensemble efficace) pour spécifier l'extraction du plus grand nombre de ressources possibles sans toutefois extraire de ressources qui sont gourmandes en calcul dans vos analyses.
+ Utilisez **All features** (Toutes les ressources) pour spécifier l'extraction de toutes les ressources de la série de réglage.
+ Utilisez **Manual subset** (Sous-ensemble manuel) pour choisir une liste de ressources qui, selon vous, expliquent bien la variation de vos données.
Suivez la procédure suivante pour extraire des ressources de vos données de séries temporelles.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Extract features** (Extraire des ressources).
1. Pour **Extraire des ressources de cette colonne**, choisissez une colonne.
1. (Facultatif) Sélectionnez **Flatten** (Aplatir) pour afficher les fonctions dans des colonnes distinctes.
1. Pour **Stratégie**, choisissez une stratégie pour extraire les ressources.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Utiliser des ressources décalées issues de vos données de séries temporelles
Dans de nombreux cas d'utilisation, la meilleure façon de prédire le comportement futur de vos séries temporelles consiste à utiliser leur comportement le plus récent.
Voici les utilisations les plus courantes des entités décalées :
+ Collecter les dernières valeurs. Par exemple, pour le temps, t \+ 1, vous collectez t, t - 1, t - 2 et t - 3.
+ Collecter des valeurs correspondant au comportement saisonnier dans les données. Par exemple, pour prédire l'occupation d'un restaurant à 13h00, vous pouvez utiliser les ressources depuis 13h00 la veille. L'utilisation des ressources depuis 12h00 ou 11h00 le même jour peut altérer la qualité de la prédiction par rapport à l'utilisation des ressources des jours précédents.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Lag features** (Ressources de décalage).
1. Pour **Générer des fonctions de décalage pour cette colonne**, choisissez une colonne.
1. Pour **Timestamp Column** (Colonne d'horodatage), choisissez la colonne contenant les horodatages.
1. Pour **Décalage**, spécifiez la durée du décalage.
1. (Facultatif) Configurez la sortie à l'aide de l'une des options suivantes :
+ **Inclure l’intégralité de la fenêtre de décalage**
+ **Flatten the output** (Aplatir la sortie)
+ **Drop rows withou history** (Supprimer les lignes sans historique)
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Créer une plage de date/heure dans votre série temporelle
Il se peut que vous ayez des données de séries temporelles qui n'ont pas d'horodatage. Si vous savez que les observations ont été effectuées à intervalles réguliers, vous pouvez générer des horodatages pour la série temporelle dans une colonne distincte. Pour générer des horodatages, vous spécifiez la valeur de l'horodatage de début et la fréquence des horodatages.
Voici un exemple de données de séries temporelles pour le nombre de clients d’un restaurant.
Données de séries temporelles sur le nombre de clients dans un restaurant
| Nombre de clients |
| --- |
| 10 |
| 14 |
| 24 |
| 40 |
| 30 |
| 20 |
Si vous savez que le restaurant a ouvert ses portes à 17h00 et que des observations sont effectuées toutes les heures, vous pouvez ajouter une colonne d'horodatage correspondant aux données de séries temporelles. Vous pouvez voir la colonne d’horodatage dans le tableau suivant.
Données de séries temporelles sur le nombre de clients dans un restaurant
| Nombre de clients | Horodatage |
| --- | --- |
| 10 | 13h00 |
| 14 | 14h00 |
| 24 | 15h00 |
| 40 | 16h00 |
| 30 | 17h00 |
| 20 | 18h00 |
Utilisez la procédure suivante pour ajouter une plage de date/heure à vos données.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Plage de date/heure**.
1. Pour **Frequency type** (Type de fréquence), choisissez l'unité utilisée pour mesurer la fréquence des horodatages.
1. Pour **Starting timestamp** (Horodatage de début), spécifiez l'horodatage de début.
1. Pour **Colonne de sortie**, spécifiez le nom de la colonne de sortie.
1. (Facultatif) Configurez la sortie à l'aide des champs restants.
1. Choisissez **Prévisualisation** pour générer une prévisualisation de la transformation.
1. Choisissez **Add** (Ajouter) pour ajouter la transformation au flux de données Data Wrangler.
### Utiliser une fenêtre propagée dans votre série temporelle
Vous pouvez extraire des ressources sur une période donnée. Par exemple, pour le temps, *t*, et une longueur de fenêtre temporelle de 3, et pour la ligne qui indique le *t*-ème horodatage, nous ajoutons les ressources extraites de la série temporelle aux temps *t* - 3, *t* -2 et *t* - 1. Pour en savoir plus sur l’extraction des ressources, consultez [Extraire des fonctions de vos données de séries temporelles](#data-wrangler-transform-extract-time-series-features).
Vous pouvez utiliser la procédure suivante pour extraire des ressources sur une période.
1. Ouvrez votre flux de données Data Wrangler.
1. Si vous n'avez pas importé votre jeu de données, importez-le sous l'onglet **Import data** (Importer des données).
1. Dans votre flux de données, sous **Data types** (Types de données), choisissez le **\+**, puis sélectionnez **Add transformation** (Ajouter une transformation).
1. Choisissez **Add step** (Ajouter une étape).
1. Choisissez **Rolling window features** (Ressources de fenêtre propagée).
1. Pour **Générer des ressources de fenêtre propagée pour cette colonne**, choisissez une colonne.
1. Pour **Timestamp Column** (Colonne d'horodatage), choisissez la colonne contenant les horodatages.
1. (Facultatif) Pour **Colonne de sortie**, définissez le nom de la colonne de sortie.
1. Pour **Taille de fenêtre**, spécifiez la taille de la fenêtre.
1. Pour **Strategy** (Stratégie), choisissez la stratégie d'extraction.
1. Choisissez **Preview** (Prévisualisation) pour générer une prévisualisation de la transformation.
1. Choisissez **Ajouter** pour ajouter la transformation au flux de données Data Wrangler.
## Date/Heure enrichie
Utilisez **Featurize date/time** (Date/Heure enrichie) pour créer une encapsulation vectorielle représentant un champ date/heure. Pour utiliser cette transformation, vos données de date/heure doivent être dans l'un des formats suivants :
+ Chaînes décrivant la date/heure : par exemple, `"January 1st, 2020, 12:44pm"`.
+ Un horodatage unix : un horodatage unix décrit le nombre de secondes, de millisecondes, de microsecondes ou de nanosecondes à partir du 01/01/1970.
Vous pouvez choisir de **déduire le format date/heure** et de fournir un **format date/heure**. Si vous fournissez un format date/heure, vous devez utiliser les codes décrits dans la [documentation Python](https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes). Les options que vous choisissez pour ces deux configurations ont des répercussions sur la rapidité de l'opération et sur les résultats finaux.
+ L’option la plus manuelle et la plus rapide sur le plan informatique consiste à spécifier un **Format date/heure** et à sélectionner **Non** pour **Déduire le format date/heure**.
+ Pour réduire le travail manuel, vous pouvez choisir **Infer datetime format** (Déduire le format date/heure) et ne pas spécifier de format date/heure. Il s'agit également d'une opération rapide sur le plan du calcul ; cependant, le premier format date/heure rencontré dans la colonne d'entrée est supposé être le format de la colonne entière. Si la colonne présente d’autres formats, ces valeurs sont NaN dans la sortie finale. En déduisant le format date/heure, vous pouvez obtenir des chaînes non analysées.
+ Si vous ne spécifiez aucun format et que vous sélectionnez **Non** pour **Déduire le format date/heure**, vous obtenez les résultats les plus robustes. Toutes les chaînes de date/heure valides sont analysées. Toutefois, cette opération peut être beaucoup plus lente que les deux premières options de cette liste.
Lorsque vous utilisez cette transformation, vous spécifiez une **Input column** (Colonne d'entrée) qui contient des données de date/heure dans l'un des formats répertoriés ci-dessus. La transformation crée une colonne de sortie nommée **Nom de colonne de sortie**. Le format de la colonne de sortie dépend de votre configuration en utilisant les éléments suivants :
+ **Vecteur** : affiche une seule colonne en tant que vecteur.
+ **Colonnes** : crée une colonne pour chaque entité. Par exemple, si la sortie contient une année, un mois et un jour, trois colonnes distinctes sont créées pour l'année, le mois et le jour.
De plus, vous devez choisir un **Mode de vectorisation**. Pour les modèles linéaires et les réseaux profonds, nous recommandons de choisir le mode **cyclique**. Pour les algorithmes arborescents, nous recommandons d'utiliser le mode **ordinal**.
## Formatage de chaîne
Les transformations **Format string (Formatage de chaîne)** contiennent des opérations de formatage de chaîne standard. Par exemple, vous pouvez utiliser ces opérations pour supprimer des caractères spéciaux, normaliser les longueurs de chaîne et mettre à jour le boîtier de chaîne.
Ce groupe de fonctions contient les transformations suivantes. Toutes les transformations renvoient des copies des chaînes dans **Input column (Colonne d'entrée)** et ajoutent le résultat à une nouvelle colonne de sortie.
| Nom | Fonction |
| --- | --- |
| Left pad | Padding à gauche de la chaîne avec un **caractère de remplissage** de **longueur** donnée. Si la chaîne dépasse la **longueur**, la valeur renvoyée est raccourcie au nombre de caractères de la **longueur**. |
| Right pad | Padding à droite de la chaîne avec un **caractère de remplissage** de **longueur** donnée. Si la chaîne dépasse la **longueur**, la valeur renvoyée est raccourcie au nombre de caractères de la **longueur**. |
| Center (pad on either side) | Padding central de la chaîne (padding ajouté des deux côtés de la chaîne) avec un **caractère de remplissage** de **longueur** donnée. Si la chaîne dépasse la **longueur**, la valeur renvoyée est raccourcie au nombre de caractères de la **longueur**. |
| Prepend zeros | Remplit à gauche une chaîne numérique avec des zéros, jusqu'à une **longueur** donnée. Si la chaîne dépasse la **longueur**, la valeur renvoyée est raccourcie au nombre de caractères de la **longueur**. |
| Strip left and right | Renvoie une copie de la chaîne avec les caractères de début et de fin supprimés. |
| Strip characters from left | Renvoie une copie de la chaîne avec les caractères de début supprimés. |
| Strip characters from right | Renvoie une copie de la chaîne dont les caractères de fin ont été supprimés. |
| Lower case | Convertit toutes les lettres du texte en minuscules. |
| Upper case | Convertit toutes les lettres du texte en majuscules. |
| Capitalize | Convertit en majuscule la première lettre de chaque phrase. |
| Swap case | Convertit tous les caractères majuscules en minuscules et tous les caractères minuscules en majuscules dans la chaîne donnée, et la renvoie. |
| Add prefix or suffix | Ajoute un préfixe et un suffixe à la colonne de chaîne. Vous devez spécifier au moins l'un des éléments **Prefix (Préfixe)** et **Suffix (Suffixe)**. |
| Remove Symbols (Supprimer les symboles) | Supprime les symboles donnés d’une chaîne. Tous les caractères répertoriés sont supprimés. et remplacés par défaut par un espace. |
## Traiter les valeurs aberrantes
Les modèles de machine learning sont sensibles à la distribution et à l'étendue des valeurs de vos caractéristiques. Les valeurs aberrantes, ou rares, peuvent avoir un impact négatif sur la précision des modèles et allonger les durées d'entraînement. Utilisez ce groupe de caractéristiques pour détecter et mettre à jour les valeurs aberrantes dans votre jeu de données.
Lorsque vous définissez une transformation **Handle outliers (Traiter les valeurs aberrantes)**, les statistiques utilisées pour détecter les valeurs aberrantes sont générées sur les données disponibles dans Data Wrangler lors de la définition de cette étape. Ces mêmes statistiques sont utilisées lors de l'exécution d'une tâche Data Wrangler.
Utilisez les sections suivantes pour en apprendre davantage sur les transformations que contient ce groupe. Vous spécifiez un **Output name (Nom de sortie)** et chacune de ces transformations produit une colonne de sortie avec les données résultantes.
### Robust standard deviation numeric outliers (Écarts-types aberrants numériques robustes)
Cette transformation détecte et corrige les valeurs aberrantes dans les caractéristiques numériques à l’aide de statistiques robustes aux valeurs aberrantes.
Vous devez définir un **Upper quantile** (Quantile supérieur) et un **Lower quantile** (Quantile inférieur) pour les statistiques servant à calculer les valeurs aberrantes. Vous devez également spécifier le nombre d’**Écarts-types** à partir duquel une valeur doit s’écarter de la moyenne pour être considérée comme une valeur aberrante. Par exemple, si vous spécifiez 3 pour les **Standard deviations** (Écarts-types), une valeur doit s'écarter de plus de 3 écarts-types de la moyenne pour être considérée comme aberrante.
La méthode **Fix** est la méthode utilisée pour gérer les valeurs aberrantes lorsqu'elles sont détectées. Sélectionnez parmi les éléments suivants :
+ **Clip** (Découper) : utilisez cette option pour découper les valeurs aberrantes à la limite de détection des valeurs aberrantes correspondante.
+ **Remove** (Supprimer) : cette option permet de supprimer des lignes avec des valeurs aberrantes du dataframe.
+ **Invalidate** (Invalider) : utilisez cette option pour remplacer les valeurs aberrantes par des valeurs non valides.
### Écarts-types aberrants numériques
Cette transformation détecte et corrige les valeurs aberrantes dans les entités numériques à l'aide de la moyenne et de l'écart-type.
Vous spécifiez le nombre de **Standard deviations (Écarts-types)** qu'une valeur doit avoir par rapport à la moyenne pour être considérée comme une valeur aberrante. Par exemple, si vous spécifiez 3 pour les **Standard deviations (Écarts-types)**, une valeur doit s'écarter de plus de 3 écarts-types de la moyenne pour être considérée comme aberrante.
La méthode **Fix** est la méthode utilisée pour gérer les valeurs aberrantes lorsqu'elles sont détectées. Sélectionnez parmi les éléments suivants :
+ **Clip** (Découper) : utilisez cette option pour découper les valeurs aberrantes à la limite de détection des valeurs aberrantes correspondante.
+ **Remove** (Supprimer) : cette option permet de supprimer des lignes avec des valeurs aberrantes du dataframe.
+ **Invalidate** (Invalider) : utilisez cette option pour remplacer les valeurs aberrantes par des valeurs non valides.
### Quantiles numériques aberrants
Utilisez cette transformation pour détecter et corriger les valeurs aberrantes dans les entités numériques à l’aide de quantiles. Vous pouvez définir un **Upper quantile** (Quantile supérieur) et un **Lower quantile** (Quantile inférieur). Toutes les valeurs situées au-dessus du quantile supérieur ou en dessous du quantile inférieur sont considérées comme des valeurs aberrantes.
La méthode **Fix** est la méthode utilisée pour gérer les valeurs aberrantes lorsqu’elles sont détectées. Sélectionnez parmi les éléments suivants :
+ **Clip** (Découper) : utilisez cette option pour découper les valeurs aberrantes à la limite de détection des valeurs aberrantes correspondante.
+ **Remove** (Supprimer) : cette option permet de supprimer des lignes avec des valeurs aberrantes du dataframe.
+ **Invalidate** (Invalider) : utilisez cette option pour remplacer les valeurs aberrantes par des valeurs non valides.
### Valeurs numériques min-max aberrantes
Cette transformation détecte et corrige les valeurs aberrantes dans les entités numériques à l'aide de seuils supérieurs et inférieurs. Utilisez cette méthode si vous connaissez des valeurs de seuil qui distinguent les valeurs aberrantes.
Vous spécifiez un **Upper threshold (Seuil supérieur)** et un **Lower threshold (Seuil inférieur)**, et si des valeurs se situent au-dessus ou au-dessous de ces seuils, elles sont considérées comme aberrantes.
La méthode **Fix** est la méthode utilisée pour gérer les valeurs aberrantes lorsqu'elles sont détectées. Sélectionnez parmi les éléments suivants :
+ **Clip** (Découper) : utilisez cette option pour découper les valeurs aberrantes à la limite de détection des valeurs aberrantes correspondante.
+ **Remove** (Supprimer) : cette option permet de supprimer des lignes avec des valeurs aberrantes du dataframe.
+ **Invalidate** (Invalider) : utilisez cette option pour remplacer les valeurs aberrantes par des valeurs non valides.
### Remplacer les valeurs rares
Lorsque vous utilisez la transformation **Remplace rare (Remplacer les valeurs rares)**, vous spécifiez un seuil. Data Wrangler recherche toutes les valeurs qui atteignent ce seuil et les remplace par une chaîne que vous spécifiez. Par exemple, vous pouvez utiliser cette transformation pour classer toutes les valeurs aberrantes d'une colonne dans une catégorie « Autres ».
+ **Replacement string (Chaîne de remplacement)** : chaîne par laquelle remplacer les valeurs aberrantes.
+ **Absolute threshold (Seuil absolu)** : une catégorie est rare si le nombre d'instances est inférieur ou égal à ce seuil absolu.
+ **Fraction threshold (Seuil de fraction)** : une catégorie est rare si le nombre d'instances est inférieur ou égal à ce seuil de fraction multiplié par le nombre de lignes.
+ **Max common categories (Nombre maximum de catégories communes)** : nombre maximal de catégories non rares qui restent après l'opération. Si le seuil ne filtre pas suffisamment les catégories, celles qui présentent le plus grand nombre d'apparitions sont classées comme non rares. Si le paramètre est défini sur 0 (par défaut), il n'y a pas de limite fixe au nombre de catégories.
## Handle Missing Values (Gestion des valeurs manquantes)
Les valeurs manquantes sont fréquentes dans les jeux de données de machine learning. Dans certaines situations, il convient d'imputer les données manquantes avec une valeur calculée, telle qu'une valeur moyenne ou catégoriquement commune. Vous pouvez traiter les valeurs manquantes à l'aide de la transformation de groupe **Handle Missing Values (Gestion des valeurs manquantes)**. Ce groupe contient les transformations suivantes.
### Fill Missing (Remplissage des valeurs manquantes)
Utilisez la transformation **Fill missing (Remplissage des valeurs manquantes)** pour remplacer les valeurs manquantes par une **Fill value (Valeur de remplissage)** que vous définissez.
### Impute missing (Imputer les valeurs manquantes)
Utilisez la transformation **Impute missing (Imputer les valeurs manquantes)** pour créer une nouvelle colonne contenant des valeurs imputées où des valeurs manquantes ont été trouvées dans des données catégoriques et numériques en entrée. La configuration dépend de votre type de données.
Pour les données numériques, choisissez une politique d’imputation, utilisée pour déterminer la nouvelle valeur à imputer. Vous pouvez choisir d'imputer la moyenne ou la médiane sur les valeurs présentes dans votre jeu de données. Data Wrangler utilise la valeur calculée pour imputer les valeurs manquantes.
Pour les données catégorielles, Data Wrangler impute les valeurs manquantes en utilisant la valeur la plus fréquente de la colonne. Pour imputer une chaîne personnalisée, utilisez la transformation **Fill missing** (Remplir les valeurs manquantes) à la place.
### Ajouter un indicateur de valeur manquante
Utilisez la transformation **Add Indicator for missing** (Ajouter un indicateur de valeur manquante) pour créer une colonne indicatrice, qui contient un booléen `"false"` si une ligne contient une valeur, et `"true"` si la valeur est manquante dans cette ligne.
### Drop missing (Supprimer les valeurs manquantes)
Utilisez l'option **Drop missing (Supprimer les valeurs manquantes)** pour supprimer les lignes dans lesquelles des valeurs sont manquantes dans **Input column (Colonne d'entrée)**.
## Manage Columns (Gérer les colonnes)
Vous pouvez utiliser les transformations suivantes pour mettre à jour et gérer rapidement les colonnes de votre jeu de données :
| Nom | Fonction |
| --- | --- |
| Drop Column | Supprimer une colonne. |
| Duplicate Column | Dupliquer une colonne. |
| Rename Column | Renommer une colonne. |
| Move Column | Déplacer une colonne dans le jeu de données. Choisissez de déplacer votre colonne vers le début ou la fin du jeu de données, avant ou après une colonne de référence, ou vers un index spécifique. |
## Manage Rows (Gérer les lignes)
Utilisez ce groupe de transformation pour effectuer rapidement des opérations de tri et de mélange sur les lignes. Ce niveau contient les éléments suivants :
+ **Sort (Trier)** : triez le dataframe entier par une colonne donnée. Cochez la case en regard de **Ascending order (Ordre croissant)** pour cette option ; sinon, désactivez la case et l'ordre décroissant est utilisé pour le tri.
+ **Shuffle (Mélanger)** : mélangez aléatoirement toutes les lignes du jeu de données.
## Manage Vectors (Gérer les vecteurs)
Utilisez ce groupe de transformation pour combiner ou aplatir des colonnes vectorielles. Ce groupe contient les transformations suivantes.
+ **Assemble (Assembler)** : utilisez cette transformation pour combiner les vecteurs Spark et les données numériques en une seule colonne. Par exemple, vous pouvez combiner trois colonnes : deux contenant des données numériques et une contenant des vecteurs. Ajoutez toutes les colonnes que vous souhaitez combiner dans **Input columns (Colonnes d'entrée)** et spécifiez un **Output column name (Nom de colonne de sortie)** pour les données combinées.
+ **Aplatir** : utilisez cette transformation pour aplatir une seule colonne contenant des données vectorielles. La colonne d'entrée doit contenir des PySpark vecteurs ou des objets de type tableau. Vous pouvez contrôler le nombre de colonnes créées en spécifiant une **Méthode de détection du nombre de sorties**. Par exemple, si vous sélectionnez **Length of first vector** (Longueur du premier vecteur), le nombre d'éléments dans le premier vecteur ou tableau valide trouvé dans la colonne détermine le nombre de colonnes de sortie créées. Tous les autres vecteurs d’entrée avec trop d’éléments sont tronqués. Les entrées contenant trop peu d'éléments sont remplies NaNs.
Vous spécifiez également un **Output prefix (Préfixe de sortie)**, qui est utilisé comme préfixe pour chaque colonne de sortie.
## Process Numeric (Traitement numérique)
Utilisez le groupe de fonctions **Process Numeric (Traitement numérique)** pour traiter les données numériques. Chaque scalaire de ce groupe est défini à l'aide de la bibliothèque Spark. Les scalaires suivants sont pris en charge :
+ **Redimensionneur standard** : standardisez la colonne en entrée en soustrayant la moyenne de chaque valeur et en mettant à l’échelle la variance unitaire. Pour en savoir plus, consultez la documentation de Spark pour [StandardScaler](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-transform.html).
+ **Redimensionneur robuste** : mettez à l’échelle la colonne d’entrée à l’aide de statistiques robustes vers des valeurs aberrantes. Pour en savoir plus, consultez la documentation de Spark pour [RobustScaler](https://spark.apache.org/docs/latest/ml-features#robustscaler).
+ **Redimensionneur Min Max** : transforme la colonne en entrée en mettant à l’échelle chaque entité à une plage donnée. Pour en savoir plus, consultez la documentation de Spark pour [MinMaxScaler](https://spark.apache.org/docs/latest/ml-features#minmaxscaler).
+ **Redimensionneur absolu Max** : mettez à l’échelle la colonne d’entrée en divisant chaque valeur par la valeur absolue maximale. Pour en savoir plus, consultez la documentation de Spark pour [MaxAbsScaler](https://spark.apache.org/docs/latest/ml-features#maxabsscaler).
## Echantillonnage
Une fois que vous avez importé vos données, vous pouvez utiliser le transformateur d'**échantillonnage** pour prélever un ou plusieurs échantillons. Lorsque vous utilisez le transformateur d'échantillonnage, Data Wrangler échantillonne votre jeu de données d'origine.
Vous pouvez choisir l'une des méthodes d'échantillonnage suivantes :
+ **Limit** (Limite) : échantillonne le jeu de données à partir de la première ligne jusqu'à la limite spécifiée.
+ **Randomized** (Aléatoire) : prélève un échantillon aléatoire d'une taille que vous spécifiez.
+ **Stratified** (Stratifié) : prélève un échantillon aléatoire stratifié.
Vous pouvez stratifier un échantillon aléatoire pour vous assurer qu’il représente la distribution d’origine du jeu de données.
Vous pouvez effectuer la préparation des données pour plusieurs cas d'utilisation. Pour chaque cas d’utilisation, vous pouvez prélever un échantillon différent et appliquer un ensemble de transformations différent.
La procédure suivante décrit le processus de création d’un échantillon aléatoire.
Pour prélever un échantillon aléatoire à partir de vos données.
1. Cliquez sur **\+** à droite du jeu de données que vous avez importé. Le nom de votre jeu de données se trouve sous **\+**.
1. Choisissez **Add transform** (Ajouter une transformation).
1. Choisissez **Sampling** (Échantillonnage).
1. Pour **Sampling method** (Méthode d'échantillonnage), choisissez la méthode d'échantillonnage.
1. Pour **Approximate sample size** (Taille approximative de l'échantillon), choisissez le nombre approximatif d'observations que vous souhaitez dans votre échantillon.
1. (Facultatif) Spécifiez un entier pour **Random Seed** (Nombre aléatoire) afin de créer un échantillon reproductible.
La procédure suivante décrit le processus de création d'un échantillon stratifié.
Pour prélever un échantillon stratifié à partir de vos données.
1. Cliquez sur **\+** à droite du jeu de données que vous avez importé. Le nom de votre jeu de données se trouve sous **\+**.
1. Choisissez **Add transform** (Ajouter une transformation).
1. Choisissez **Sampling** (Échantillonnage).
1. Pour **Sampling method** (Méthode d'échantillonnage), choisissez la méthode d'échantillonnage.
1. Pour **Approximate sample size** (Taille approximative de l'échantillon), choisissez le nombre approximatif d'observations que vous souhaitez dans votre échantillon.
1. Pour **Stratify column** (Stratifier la colonne), indiquez le nom de la colonne sur laquelle vous souhaitez stratifier.
1. (Facultatif) Spécifiez un entier pour **Random Seed** (Nombre aléatoire) afin de créer un échantillon reproductible.
## Search and Edit (Rechercher et modifier)
Utilisez cette section pour rechercher et modifier des motifs spécifiques dans des chaînes. Par exemple, vous pouvez rechercher et mettre à jour des chaînes dans des phrases ou des documents, diviser des chaînes par des délimiteurs et rechercher des occurrences de chaînes spécifiques.
Les transformations suivantes sont prises en charge sous **Search and edit (Rechercher et modifier)**. Toutes les transformations renvoient des copies des chaînes dans **Input column (Colonne d'entrée)** et ajoutent le résultat à une nouvelle colonne de sortie.
| Nom | Fonction |
| --- | --- |
| Find substring | Renvoie l'index de la première occurrence de **Substring** (Sous-chaîne) que vous avez recherchée. Vous pouvez commencer et terminer la recherche aux instants **Start** (Début) et **End** (Fin), respectivement. |
| Find substring (from right) | Renvoie l'index de la dernière occurrence de **Substring** (Sous-chaîne) que vous avez recherchée. Vous pouvez commencer et terminer la recherche respectivement aux instants **Start** (Début) et **End** (Fin). |
| Matches prefix | Renvoie une valeur de type booléenne si la chaîne contient un **Pattern** (Modèle) donné. Un modèle peut être une séquence de caractères ou une expression régulière. En option, vous pouvez rendre le modèle sensible à la casse. |
| Find all occurrences | Renvoie un tableau avec toutes les occurrences d'un modèle donné. Un modèle peut être une séquence de caractères ou une expression régulière. |
| Extract using regex | Renvoie une chaîne qui correspond à un modèle Regex donné. |
| Extract between delimiters | Renvoie une chaîne avec tous les caractères trouvés entre le **délimiteur de gauche** et le **délimiteur de droite**. |
| Extract from position | Renvoie une chaîne, depuis la **position de départ** dans la chaîne d'entrée, qui contient tous les caractères jusqu'à la position de départ plus la **longueur**. |
| Find and replace substring | Renvoie une chaîne dont toutes les correspondances d'un **modèle** (une expression régulière) sont remplacées par une **chaîne de remplacement**. |
| Replace between delimiters | Renvoie une chaîne dont la sous-chaîne trouvée entre la première occurrence d'un **délimiteur de gauche** et la dernière occurrence d'un **délimiteur de droite** est remplacée par une **chaîne de remplacement**. Si aucune correspondance n'est trouvée, rien n'est remplacé. |
| Replace from position | Renvoie une chaîne dont la sous-chaîne située entre la **position de départ** et la **position de départ** plus la **longueur** est remplacée par une **chaîne de remplacement**. Si la **position de départ** plus la **longueur** est supérieure à la longueur de la chaîne de remplacement, la sortie contient **...**. |
| Convert regex to missing | Convertit une chaîne en `None` si elle est invalide et renvoie le résultat. La validité est définie avec une expression régulière dans le **modèle**. |
| Split string by delimiter | Renvoie un tableau de chaînes à partir de la chaîne d’entrée, divisé par le **délimiteur**, avec un **nombre maximal de fractionnements** (facultatif). Le délimiteur est par défaut un espace blanc. |
## Split data
Utilisez la transformation **Split data** (Fractionner les données) pour diviser votre jeu de données en deux ou trois jeux de données. Par exemple, vous pouvez diviser votre jeu de données en un jeu de données utilisé pour l'entraînement de votre modèle et un jeu de données utilisé pour le tester. Vous pouvez déterminer la proportion du jeu de données à inclure dans chaque fractionnement. Par exemple, si vous divisez un jeu de données en deux jeux, le jeu de données d'entraînement peut contenir 80 % des données, tandis que le jeu de données de test en contient 20 %.
Le fractionnement de vos données en trois jeux de données vous permet de créer des jeux de données d'entraînement, de validation et de test. Vous pouvez voir la performance du modèle sur le jeu de données de test en supprimant la colonne cible.
Votre cas d'utilisation détermine la part du jeu de données d'origine que chacun de vos jeux de données reçoit et la méthode que vous utilisez pour diviser les données. Par exemple, vous pouvez utiliser un fractionnement stratifié pour vous assurer que la distribution des observations dans la colonne cible est la même dans tous les jeux de données. Vous pouvez utiliser les transformations de fractionnement suivantes :
+ Fractionnement aléatoire : chaque fractionnement est un échantillon aléatoire, sans chevauchement, du jeu de données d'origine. Pour les jeux de données plus importants, l'utilisation d'un fractionnement aléatoire peut s'avérer coûteuse en ressources informatiques et prendre plus de temps qu'un fractionnement ordonné.
+ Fractionnement ordonné : fractionne le jeu de données en fonction de l'ordre séquentiel des observations. Par exemple, dans le cas d'une répartition 80/20 entre l'entraînement et le test, les premières observations qui représentent 80 % du jeu de données sont placées dans le jeu de données d'entraînement. Les derniers 20 % des observations vont dans le jeu de données de test. Les fractionnements ordonnés permettent de conserver l'ordre existant des données entre les fractionnements.
+ Fractionnement stratifié : fractionne le jeu de données pour s'assurer que le nombre d'observations dans la colonne d'entrée est représenté proportionnellement. Pour une colonne d'entrée comportant les observations 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, une répartition 80/20 sur la colonne signifierait qu'environ 80 % des 1, 80 % des 2 et 80 % des 3 sont intégrés au jeu d'entraînement. Environ 20 % de chaque type d'observation vont au jeu de test.
+ Fractionnement par clé : permet d'éviter que des données ayant la même clé se retrouvent dans plus d'un fractionnement. Par exemple, si vous avez un jeu de données avec la colonne « customer\_id » et que vous l'utilisez comme clé, aucun identifiant de client ne se trouve dans plus d'un fractionnement.
Après avoir fractionné les données, vous pouvez appliquer des transformations supplémentaires à chaque jeu de données. Pour la plupart des cas d'utilisation, cela n'est pas nécessaire.
Data Wrangler calcule les proportions des fractionnements pour dégager les meilleures performances. Vous pouvez choisir un seuil d'erreur pour définir la précision des fractionnements. Les seuils d'erreur inférieurs reflètent plus fidèlement les proportions que vous spécifiez pour les fractionnements. Si vous définissez un seuil d'erreur plus élevé, vous obtenez de meilleures performances, mais une précision moindre.
Pour des données parfaitement réparties, réglez le seuil d'erreur sur 0. Vous pouvez spécifier un seuil compris entre 0 et 1 pour obtenir de meilleures performances. Si vous spécifiez une valeur supérieure à 1, Data Wrangler interprète cette valeur comme 1.
Si votre jeu de données comporte 10 000 lignes et que vous spécifiez une répartition 80/20 avec une erreur de 0,001, vous obtiendrez des observations se rapprochant de l'un des résultats suivants :
+ 8 010 observations dans le jeu d'entraînement et 1 990 dans le jeu de test.
+ 7 990 observations dans le jeu d'entraînement et 2 010 dans le jeu de test.
Le nombre d'observations pour le jeu de test dans l'exemple précédent se situe dans l'intervalle compris entre 8 010 et 7 990.
Par défaut, Data Wrangler utilise une valeur initiale aléatoire pour rendre les fractionnements reproductibles. Vous pouvez spécifier une autre valeur initiale afin de créer un fractionnement reproductible différent.
------
#### [ Randomized split ]
Utilisez la procédure suivante pour effectuer un fractionnement aléatoire sur votre jeu de données.
Pour fractionner votre jeu de données de manière aléatoire, procédez comme suit :
1. Cliquez sur le symbole **\+** à côté du nœud contenant le jeu de données que vous fractionnez.
1. Choisissez **Ajouter une transformation**.
1. Sélectionnez **Split data** (Fractionner les données).
1. (Facultatif) Pour **Splits** (Fractionnements), indiquez les noms et les proportions de chaque fractionnement. La somme des proportions doit être égale à 1.
1. (Facultatif) Cliquez sur le symbole **\+** pour créer un fractionnement supplémentaire.
1. Spécifiez les noms et les proportions de tous les fractionnements. La somme des proportions doit être égale à 1.
1. (Facultatif) Spécifiez une valeur pour **Error threshold** (Seuil d'erreur) autre que la valeur par défaut.
1. (Facultatif) Spécifiez une valeur pour **Random seed** (Valeur initiale aléatoire).
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
------
#### [ Ordered split ]
Utilisez la procédure suivante pour effectuer un fractionnement ordonné sur votre jeu de données.
Pour effectuer un fractionnement ordonné dans votre jeu de données, procédez comme suit.
1. Cliquez sur le symbole **\+** à côté du nœud contenant le jeu de données que vous fractionnez.
1. Choisissez **Ajouter une transformation**.
1. Pour le champ **Transform** (Transformation), choisissez **Ordered split** (Fractionnement ordonné).
1. Sélectionnez **Split data** (Fractionner les données).
1. (Facultatif) Pour **Splits** (Fractionnements), indiquez les noms et les proportions de chaque fractionnement. La somme des proportions doit être égale à 1.
1. (Facultatif) Cliquez sur le symbole **\+** pour créer un fractionnement supplémentaire.
1. Spécifiez les noms et les proportions de tous les fractionnements. La somme des proportions doit être égale à 1.
1. (Facultatif) Spécifiez une valeur pour **Error threshold** (Seuil d'erreur) autre que la valeur par défaut.
1. (Facultatif) Pour le champ **Input column** (Colonne d'entrée), spécifiez une colonne avec des valeurs numériques. Utilise les valeurs des colonnes pour déduire quels enregistrements se trouvent dans chaque fractionnement. Les plus petites valeurs se trouvent dans un fractionnement et les plus grandes valeurs dans les autres.
1. (Facultatif) Sélectionnez **Handle duplicates** (Gérer les doublons) pour ajouter du bruit aux valeurs dupliquées et créer un jeu de données de valeurs entièrement uniques.
1. (Facultatif) Spécifiez une valeur pour **Random seed** (Valeur initiale aléatoire).
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
------
#### [ Stratified split ]
Pour effectuer un fractionnement stratifié sur votre jeu de données, procédez comme suit.
Pour effectuer un fractionnement stratifié dans votre jeu de données, procédez comme suit.
1. Cliquez sur le symbole **\+** à côté du nœud contenant le jeu de données que vous fractionnez.
1. Choisissez **Ajouter une transformation**.
1. Sélectionnez **Split data** (Fractionner les données).
1. Pour **Transform** (Transformation), choisissez **Stratified split** (Fractionnement stratifié).
1. (Facultatif) Pour **Splits** (Fractionnements), indiquez les noms et les proportions de chaque fractionnement. La somme des proportions doit être égale à 1.
1. (Facultatif) Cliquez sur le symbole **\+** pour créer un fractionnement supplémentaire.
1. Spécifiez les noms et les proportions de tous les fractionnements. La somme des proportions doit être égale à 1.
1. Pour le champ **Input column** (Colonne d'entrée), spécifiez une colonne comportant jusqu'à 100 valeurs uniques. Data Wrangler ne peut pas stratifier une colonne avec plus de 100 valeurs uniques.
1. (Facultatif) Spécifiez une valeur pour **Error threshold** (Seuil d'erreur) autre que la valeur par défaut.
1. (Facultatif) Spécifiez une valeur pour **Random seed** (Valeur initiale aléatoire) pour spécifier une valeur initiale différente.
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
------
#### [ Split by column keys ]
Utilisez la procédure suivante pour fractionner par clés de colonne dans votre jeu de données.
Pour fractionner par clés de colonne dans votre jeu de données, procédez comme suit.
1. Cliquez sur le symbole **\+** à côté du nœud contenant le jeu de données que vous fractionnez.
1. Choisissez **Ajouter une transformation**.
1. Sélectionnez **Split data** (Fractionner les données).
1. Pour **Transform** (Transformation), choisissez **Split by key** (Fractionnement par clé).
1. (Facultatif) Pour **Splits** (Fractionnements), indiquez les noms et les proportions de chaque fractionnement. La somme des proportions doit être égale à 1.
1. (Facultatif) Cliquez sur le symbole **\+** pour créer un fractionnement supplémentaire.
1. Spécifiez les noms et les proportions de tous les fractionnements. La somme des proportions doit être égale à 1.
1. Pour le champ **Key columns** (Colonnes clés), indiquez les colonnes dont les valeurs ne doivent pas apparaître dans les deux jeux de données.
1. (Facultatif) Spécifiez une valeur pour **Error threshold** (Seuil d'erreur) autre que la valeur par défaut.
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
------
## Parse Value as Type (Analyser la valeur en tant que type)
Utilisez cette transformation pour convertir une colonne en nouveau type. Les types de données Data Wrangler pris en charge sont :
+ Long
+ Float
+ Booléen
+ Date, au format dd-MM-yyyy, représentant respectivement le jour, le mois et l'année.
+ String
## Validate string (Valider la chaîne)
Utilisez la transformation **Validate string (Valider la chaîne)** pour créer une colonne indiquant qu'une ligne de données textuelles répond à une condition spécifiée. Par exemple, vous pouvez utiliser **Validate string (Valider la chaîne)** pour vérifier qu'une chaîne ne contient que des caractères minuscules. Les transformations suivantes sont prises en charge sous **Validate string (Valider la chaîne)**.
Les transformations suivantes sont incluses dans ce groupe de transformation. Si une transformation génère une valeur booléenne, `True` est représenté par un `1` et `False` est représenté par un `0`.
| Nom | Fonction |
| --- | --- |
| String length | Renvoie `True` si une longueur de chaîne est égale à la longueur spécifiée. Sinon, la valeur renvoyée est `False`. |
| Starts with | Renvoie `True` si une chaîne démarre avec un préfixe spécifié. Sinon, la valeur renvoyée est `False`. |
| Ends with | Renvoie `True` si une longueur de chaîne est égale à la longueur spécifiée. Sinon, la valeur renvoyée est `False`. |
| Is alphanumeric | Renvoie `True` si une chaîne ne contient que des chiffres et des lettres. Sinon, la valeur renvoyée est `False`. |
| Is alpha (letters) | Renvoie `True` si une chaîne ne contient que des lettres. Sinon, la valeur renvoyée est `False`. |
| Is digit | Renvoie `True` si une chaîne ne contient que des chiffres. Sinon, la valeur renvoyée est `False`. |
| Is space | Renvoie `True` si une chaîne ne contient que des chiffres et des lettres. Sinon, la valeur renvoyée est `False`. |
| Is title | Renvoie `True` si une chaîne contient des espaces blancs. Sinon, la valeur renvoyée est `False`. |
| Is lowercase | Renvoie `True` si une chaîne ne contient que des lettres minuscules. Sinon, la valeur renvoyée est `False`. |
| Is uppercase | Renvoie `True` si une chaîne ne contient que des lettres majuscules. Sinon, la valeur renvoyée est `False`. |
| Is numeric | Renvoie `True` si une chaîne ne contient que des nombres. Sinon, la valeur renvoyée est `False`. |
| Is decimal | Renvoie `True` si une chaîne ne contient que des nombres décimaux. Sinon, la valeur renvoyée est `False`. |
## Annulation de l'imbrication des données JSON
Si vous possédez un fichier .csv, certaines valeurs de votre jeu de données peuvent être des chaînes JSON. De même, vous avez peut-être des données imbriquées dans des colonnes d’un fichier Parquet ou d’un document JSON.
Utilisez l'opérateur **Flatten structured** (Aplatir structuré) pour séparer les clés de premier niveau en colonnes distinctes. Une clé de premier niveau est une clé qui n'est pas imbriquée dans une valeur.
Par exemple, vous pouvez avoir un jeu de données doté d'une colonne *personne* contenant des informations démographiques sur chaque personne stockées sous forme de chaînes JSON. Une chaîne JSON peut ressembler à ce qui suit.
```
"{"seq": 1,"name": {"first": "Nathaniel","last": "Ferguson"},"age": 59,"city": "Posbotno","state": "WV"}"
```
L'opérateur **Flatten structured** (Aplatir structuré) convertit les clés de premier niveau suivantes en colonnes supplémentaires dans le jeu de données :
+ seq
+ name
+ age
+ city
+ state
Data Wrangler place les valeurs des clés sous la forme de valeurs dans les colonnes. Le nom des colonnes et les valeurs des chaînes JSON sont indiqués ci-dessous.
```
seq, name, age, city, state
1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV
```
Pour chaque valeur du jeu de données contenant des chaînes JSON, l'opérateur **Flatten structured** (Aplatir structuré) crée des colonnes pour les clés de premier niveau. Pour créer des colonnes pour les clés imbriquées, appelez à nouveau l'opérateur. Dans l'exemple précédent, l'appel de l'opérateur crée les colonnes suivantes :
+ name\_first
+ name\_last
L'exemple suivant illustre le jeu de données résultant du nouvel appel de l'opération.
```
seq, name, age, city, state, name_first, name_last
1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV, Nathaniel, Ferguson
```
Choisissez **Keys to flatten on** (Clés sur lesquelles aplatir) pour spécifier les clés de premier niveau à extraire sous forme de colonnes distinctes. Si vous ne spécifiez pas de clé, Data Wrangler extrait toutes les clés par défaut.
## Éclatement du tableau
Utilisez **Explode array** (Éclater le tableau) pour développer les valeurs du tableau en lignes de sortie distinctes. Par exemple, l'opération peut prendre chaque valeur du tableau [[1, 2, 3,], [4, 5, 6], [7, 8, 9]] et créer une nouvelle colonne avec les lignes suivantes :
```
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]
```
Data Wrangler nomme la nouvelle colonne \_flatten.
Vous pouvez appeler l’opération **Explode array** (Éclater le tableau) plusieurs fois pour obtenir les valeurs imbriquées du tableau dans des colonnes de sortie distinctes. L'exemple suivant montre le résultat obtenu après que l'opération a été appelée plusieurs fois sur un jeu de données avec un tableau imbriqué.
Placement des valeurs d’un tableau imbriqué dans des colonnes distinctes
| id | array | id | array\_items | id | array\_items\_items |
| --- | --- | --- | --- | --- | --- |
| 1 | [ [chat, chien], [chauve-souris, grenouille] ] | 1 | [chat, chien] | 1 | chat |
| 2 | [[rose, pétunia], [lys, marguerite]] | 1 | [chauve-souris, grenouille] | 1 | chien |
| | | 2 | [rose, pétunia] | 1 | chauve-souris |
| | | 2 | [lys, marguerite] | 1 | grenouille |
| | | | 2 | 2 | rose |
| | | | 2 | 2 | pétunia |
| | | | 2 | 2 | lys |
| | | | 2 | 2 | marguerite |
## Transformation des données d'image
Utilisez Data Wrangler pour importer et transformer les images que vous utilisez pour vos pipelines de machine learning (ML). Une fois que vous avez préparé vos données d'image, vous pouvez les exporter de votre flux Data Wrangler vers votre pipeline de machine learning.
Vous pouvez utiliser les informations fournies ici pour vous familiariser avec l'importation et la transformation de données d'image dans Data Wrangler. Data Wrangler utilise OpenCV pour importer des images. Pour plus d'informations sur les formats d'image pris en charge, consultez [Lecture et écriture de fichiers image](https://docs.opencv.org/3.4/d4/da8/group__imgcodecs.html#ga288b8b3da0892bd651fce07b3bbd3a56).
Après vous être familiarisé avec les concepts de transformation de vos données d'image, suivez le didacticiel suivant, intitulé [Préparer les données d'image avec Amazon SageMaker Data Wrangler](https://aws.amazon.com/blogs/machine-learning/prepare-image-data-with-amazon-sagemaker-data-wrangler/).
Les secteurs et les cas d'utilisation suivants sont des exemples dans lesquels l'application du machine learning à des données d'image transformées peut s'avérer utile :
+ Fabrication : identification de défauts sur des articles dans la chaîne d'assemblage
+ Alimentation : identification d'aliments avariés ou pourris
+ Médecine : identification de lésions au niveau des tissus
Lorsque vous travaillez avec des données d'image dans Data Wrangler, vous devez suivre le processus suivant :
1. Importer : choisissez le répertoire contenant les images et sélectionnez-les dans votre compartiment Amazon S3.
1. Transformer : utilisez les transformations intégrées pour préparer les images pour votre pipeline de machine learning.
1. Exporter : exportez les images que vous avez transformées vers un emplacement accessible depuis le pipeline.
Procédez comme suit pour importer vos données d'image.
**Pour importer vos données d'image**
1. Accédez à la page **Créer une connexion**.
1. Choisissez **Amazon S3**.
1. Spécifiez le chemin du fichier Amazon S3 contenant ces données d'image.
1. Pour **Type de fichier**, choisissez **Image**.
1. (Facultatif) Choisissez **Importer des répertoires imbriqués** pour importer des images depuis plusieurs chemins Amazon S3.
1. Choisissez **Importer**.
Data Wrangler utilise la bibliothèque open source [imgaug](https://imgaug.readthedocs.io/en/latest/) pour ses transformations d'image intégrées. Vous pouvez utiliser les transformations intégrées suivantes :
+ **ResizeImage**
+ **EnhanceImage**
+ **CorruptImage**
+ **SplitImage**
+ **DropCorruptedImages**
+ **DropImageDuplicates**
+ **Brightness (Luminosité)**
+ **ColorChannels**
+ **Grayscale**
+ **Effectuer une rotation**
Utilisez la procédure suivante pour transformer vos images sans écrire de code.
**Pour transformer les données d'image sans écrire de code**
1. Dans votre flux Data Wrangler, choisissez le signe **\+** à côté du nœud représentant les images que vous avez importées.
1. Choisissez **Ajouter une transformation**.
1. Choisissez **Ajouter une étape**.
1. Choisissez la transformation et configurez-la.
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
Outre les transformations fournies par Data Wrangler, vous pouvez également utiliser vos propres extraits de code personnalisés. Pour plus d'informations sur l'utilisation d'extraits de code personnalisés, consultez [Transformations personnalisées](#data-wrangler-transform-custom). Vous pouvez importer les bibliothèques OpenCV et imgaug dans vos extraits de code et utiliser les transformations qui leur sont associées. Voici un exemple d'extrait de code qui détecte les périphéries dans ces images.
```
# A table with your image data is stored in the `df` variable
import cv2
import numpy as np
from pyspark.sql.functions import column
from sagemaker_dataprep.compute.operators.transforms.image.constants import DEFAULT_IMAGE_COLUMN, IMAGE_COLUMN_TYPE
from sagemaker_dataprep.compute.operators.transforms.image.decorators import BasicImageOperationDecorator, PandasUDFOperationDecorator
@BasicImageOperationDecorator
def my_transform(image: np.ndarray) -> np.ndarray:
# To use the code snippet on your image data, modify the following lines within the function
HYST_THRLD_1, HYST_THRLD_2 = 100, 200
edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2)
return edges
@PandasUDFOperationDecorator(IMAGE_COLUMN_TYPE)
def custom_image_udf(image_row):
return my_transform(image_row)
df = df.withColumn(DEFAULT_IMAGE_COLUMN, custom_image_udf(column(DEFAULT_IMAGE_COLUMN)))
```
Lorsque vous appliquez des transformations dans votre flux Data Wrangler, Data Wrangler ne les applique qu'à un échantillon des images dans votre jeu de données. Pour optimiser votre expérience avec l'application, Data Wrangler n'applique pas les transformations à toutes vos images.
Pour appliquer les transformations à toutes vos images, exportez votre flux Data Wrangler vers un emplacement Amazon S3. Vous pouvez utiliser les images que vous avez exportées dans vos pipelines d'entraînement ou d'inférence. Utilisez un nœud de destination ou un bloc-notes Jupyter pour exporter vos données. Vous pouvez accéder à l'une ou l'autre méthode pour exporter vos données à partir du flux Data Wrangler. Pour obtenir des informations sur l'utilisation de ces méthodes, consultez [Exporter vers Amazon S3](data-wrangler-data-export.md#data-wrangler-data-export-s3).
## Filtrage des données
Utilisez Data Wrangler pour filtrer les données de vos colonnes. Lorsque vous filtrez les données d'une colonne, vous spécifiez les champs suivants :
+ **Nom de colonne** : nom de la colonne que vous utilisez pour filtrer les données.
+ **Condition** : type de filtre que vous appliquez aux valeurs de la colonne.
+ **Valeur** : valeur ou catégorie de la colonne à laquelle vous appliquez le filtre.
Vous pouvez filtrer les conditions suivantes :
+ **=** : renvoie les valeurs correspondant à la valeur ou à la catégorie que vous spécifiez.
+ **\!=** : renvoie les valeurs ne correspondant pas à la valeur ou à la catégorie que vous spécifiez.
+ **>=** : pour les données **Long** ou **Float**, filtre les valeurs supérieures ou égales à la valeur que vous spécifiez.
+ **<=** : pour les données **Long** ou **Float**, filtre les valeurs inférieures ou égales à la valeur que vous spécifiez.
+ **>** : pour les données **Long** ou **Float**, filtre les valeurs supérieures à la valeur que vous spécifiez.
+ **<** : pour les données **Long** ou **Float**, filtre les valeurs inférieures à la valeur que vous spécifiez.
Pour une colonne contenant les catégories `male` et `female`, vous pouvez filtrer toutes les valeurs `male`. Vous pouvez également filtrer toutes les valeurs `female`. Comme il n'y a que des valeurs `male` et `female` dans la colonne, le filtre renvoie une colonne contenant uniquement des valeurs `female`.
Vous pouvez également ajouter plusieurs filtres. Les filtres peuvent être appliqués sur plusieurs colonnes ou sur la même colonne. Par exemple, si vous créez une colonne dont les valeurs se situent uniquement dans une certaine plage, vous ajoutez deux filtres différents. L'un des filtres indique que la colonne doit avoir des valeurs supérieures à la valeur que vous fournissez. L'autre filtre indique que la colonne doit avoir des valeurs inférieures à la valeur que vous fournissez.
Utilisez la procédure suivante pour ajouter la transformation de filtre à vos données.
**Pour filtrer vos données**
1. Dans votre flux Data Wrangler, choisissez le signe **\+** à côté du nœud contenant les données que vous filtrez.
1. Choisissez **Ajouter une transformation**.
1. Choisissez **Ajouter une étape**.
1. Choisissez **Filtrer les données**.
1. Spécifiez les champs suivants :
+ **Nom de colonne** : colonne que vous filtrez.
+ **Condition** : condition du filtre.
+ **Valeur** : valeur ou catégorie de la colonne à laquelle vous appliquez le filtre.
1. (Facultatif) Choisissez **\+** après le filtre que vous avez créé.
1. Configurez le filtre.
1. Choisissez **Preview** (Aperçu).
1. Choisissez **Ajouter**.
## Mappage de colonnes pour Amazon Personalize
Data Wrangler s'intègre à Amazon Personalize, un service de machine learning entièrement géré qui génère des recommandations d'éléments et des segments d'utilisateurs. Vous pouvez utiliser la transformation **Mapper des colonnes pour Amazon Personalize** afin de convertir vos données dans un format interprétable par Amazon Personalize. Pour plus d'informations sur les transformations spécifiques à Amazon Personalize, consultez [Importation de données à l'aide d'Amazon SageMaker Data Wrangler](https://docs.aws.amazon.com/personalize/latest/dg/preparing-importing-with-data-wrangler.html#dw-transform-data). Pour plus d’informations sur Amazon Personalize, consultez [Qu’est-ce qu’Amazon Personalize ?](https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html).