Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolution des problèmes
Les questions fréquentes (FAQ) suivantes peuvent vous aider à résoudre les problèmes liés à vos points de terminaison d'inférence asynchrone Amazon SageMaker.
Vous pouvez utiliser les méthodes suivantes pour déterminer le nombre d'instances derrière votre point de terminaison :
Vous pouvez utiliser l’API DescribeEndpoint SageMaker AI pour décrire le nombre d’instances situées derrière le point de terminaison à tout instant.
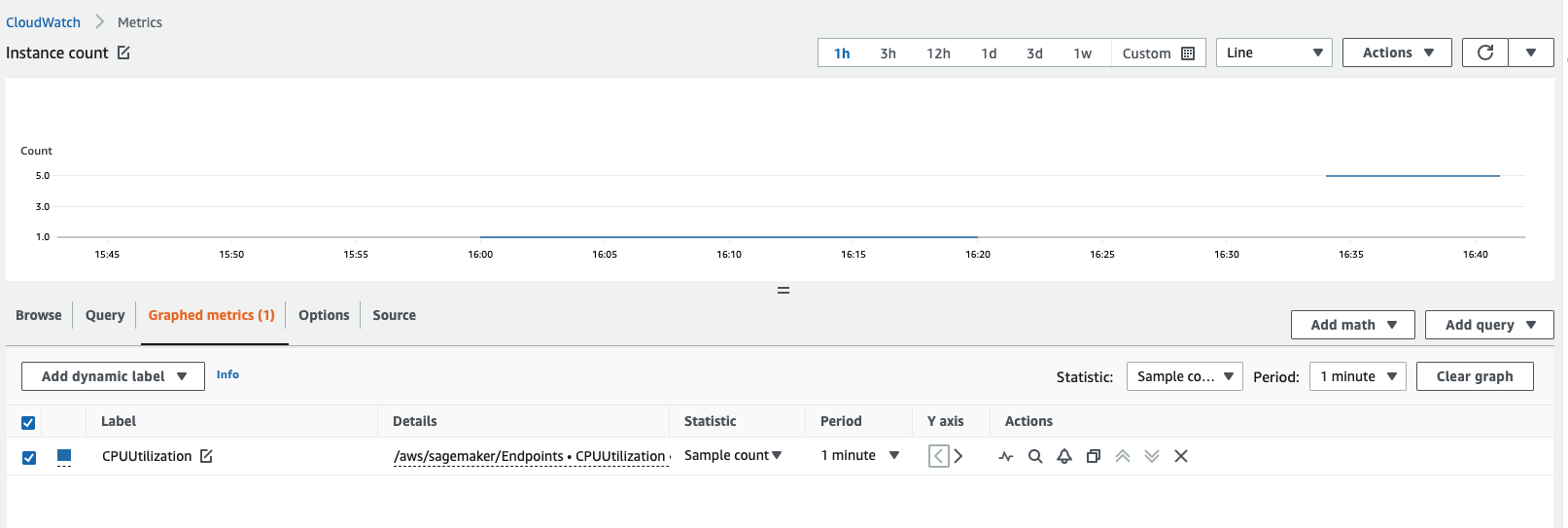
Vous pouvez obtenir le nombre d'instances en consultant vos métriques Amazon CloudWatch. Consultez les métriques de vos instances de point de terminaison, telles que
CPUUtilizationouMemoryUtilization, et vérifiez les statistiques relatives au nombre d'échantillons sur une période d'une minute. Ce nombre doit être égal au nombre d'instances actives. La capture d'écran suivante montre la métriqueCPUUtilizationreprésentée graphiquement dans la console CloudWatch, où la valeur Statistique est définie surSample count, la valeur Période est définie sur1 minuteet le nombre obtenu est 5.
Les tableaux suivants présentent les variables d’environnement réglables courantes pour les conteneurs SageMaker AI par type de cadre.
TensorFlow
| Variable d'environnement | Description |
|---|---|
|
|
Pour les modèles basés sur Tensorflow, le binaire |
|
|
Ce paramètre régit la fraction de la mémoire GPU disponible pour initialiser CUDA/cuDNN et les autres bibliothèques GPU. |
|
Elle est liée à la variable |
|
Elle est liée à la variable |
|
Cela régit le nombre de processus d'application de travail que Gunicorn est invité à générer pour traiter les demandes. Cette valeur est utilisée en combinaison avec d'autres paramètres pour dériver un ensemble qui maximise le débit d'inférence. En plus de cela, la variable |
|
Cela régit le nombre de processus d'application de travail que Gunicorn est invité à générer pour traiter les demandes. Cette valeur est utilisée en combinaison avec d'autres paramètres pour dériver un ensemble qui maximise le débit d'inférence. En plus de cela, la variable |
|
Python utilise OpenMP en interne pour implémenter le multithreading au sein des processus. Généralement, des threads équivalents au nombre de cœurs CPU sont générés. Mais lorsqu'il est implémenté en plus du multithreading simultané (SMT), tel que la technologie Hyper-Threading d'Intel, un certain processus peut sursouscrire un cœur en particulier en générant deux fois plus de threads que le nombre réel de cœurs de processeur. Dans certains cas, un binaire Python peut générer jusqu'à quatre fois plus de threads que de cœurs de processeur disponibles. Par conséquent, le paramètre idéal pour ce paramètre, si vous avez sursouscrit des cœurs disponibles à l'aide de threads de travail, est |
|
|
Dans certains cas, la désactivation de MKL peut accélérer l'inférence si |
PyTorch
| Variable d'environnement | Description |
|---|---|
|
|
Il s'agit du délai de traitement par lots maximal que TorchServe attend de recevoir. |
|
|
Si TorchServe ne reçoit pas le nombre de demandes spécifié dans |
|
|
Nombre minimal d'applications de travail auquel TorchServe est autorisé à réduire la capacité. |
|
|
Nombre maximal d'applications de travail auquel TorchServe est autorisé à augmenter la capacité. |
|
|
Délai après lequel l'inférence expire en l'absence de réponse. |
|
|
Taille de charge utile maximale pour TorchServe. |
|
|
Taille de réponse maximale pour TorchServe. |
Serveur multimodèle (MMS)
| Variable d'environnement | Description |
|---|---|
|
|
Il est utile de régler ce paramètre dans un scénario où le type de la charge utile de demande d'inférence est important et si, en raison de cette taille, la consommation de mémoire de tas de la JVM dans laquelle cette file d'attente est maintenue peut être plus élevée. Dans l'idéal, vous pouvez réduire les besoins en mémoire de tas de la JVM et permettre aux applications de travail Python d'allouer plus de mémoire pour la prise en charge réelle du modèle. La JVM sert uniquement à recevoir les requêtes HTTP, à les mettre en file d'attente et à les distribuer aux applications de travail basées sur Python pour l'inférence. Si vous augmentez la variable |
|
|
Ce paramètre est destiné au service du modèle backend et peut être utile à régler, car il s'agit du composant essentiel du service de modèle global, sur la base duquel Python traite les threads de génération pour chaque modèle. Si ce composant est plus lent (ou s'il n'est pas réglé correctement), le réglage frontal risque de ne pas être efficace. |
Vous pouvez utiliser le même conteneur pour l'inférence asynchrone que pour l'inférence en temps réel ou la transformation par lots. Vous devez confirmer que les délais d'expiration et les limites de taille de charge utile sur votre conteneur sont définis pour gérer des charges utiles plus importantes et des délais d'expiration plus longs.
Reportez-vous aux limites suivantes pour l'inférence asynchrone :
Limite de taille de charge utile : 1 Go
Limite de délai d'expiration : une demande peut prendre jusqu'à 60 minutes.
Durée de vie (TTL) des messages en file d'attente : 6 heures
Nombre de messages pouvant être placés dans Amazon SQS : illimité. Toutefois, il existe un quota de 120 000 messages en cours pour une file d’attente standard et de 20 000 pour une file d’attente FIFO.
En général, avec l'inférence asynchrone, vous pouvez monter en puissance en fonction des invocations ou des instances. Pour les métriques d'invocation, il est judicieux de consulter votre métrique ApproximateBacklogSize, qui correspond au nombre d'éléments de votre file d'attente qui doivent encore être traités. Vous pouvez utiliser cette métrique ou votre métrique InvocationsPerInstance pour comprendre à quel TPS vous êtes peut-être limité. Au niveau de l'instance, vérifiez votre type d'instance et son utilisation du CPU/GPU pour définir à quel moment monter en puissance. Si la capacité d'une instance unique dépasse 60-70 %, cela est souvent bon signe et indique que vous saturez votre matériel.
Nous ne recommandons pas l'utilisation de plusieurs politiques de mise à l'échelle, car cela peut engendrer des conflits et créer de la confusion au niveau du matériel, ce qui peut entraîner des retards lors d'une montée en puissance.
Vérifiez si votre conteneur est capable de gérer simultanément des demandes ping et d'invocation. Les demandes d’invocation SageMaker AI prennent environ 3 minutes, et pendant ce temps, plusieurs demandes ping finissent généralement par échouer en raison de l’expiration du délai imparti à SageMaker AI pour détecter votre conteneur comme Unhealthy.
Oui. MaxConcurrentInvocationsPerInstance est une fonctionnalité des points de terminaison asynchrones. Cela ne dépend pas de l'implémentation du conteneur personnalisé. MaxConcurrentInvocationsPerInstance contrôle la fréquence à laquelle les demandes d'invocation sont envoyées au conteneur client. Si cette valeur est définie sur 1, une seule demande est envoyée au conteneur à la fois, quel que soit le nombre d'applications de travail présentes sur le conteneur client.
L'erreur signifie que le conteneur client a renvoyé une erreur. SageMaker AI ne contrôle pas le comportement des conteneurs client. SageMaker AI renvoie simplement la réponse du ModelContainer et ne réessaie pas. Si vous le souhaitez, vous pouvez configurer l'invocation pour réessayer en cas d'échec. Nous vous suggérons d'activer la journalisation des conteneurs et de consulter vos journaux de conteneurs pour trouver la cause première de l'erreur 500 dans votre modèle. Vérifiez également les métriques CPUUtilization et MemoryUtilization correspondantes au point de défaillance. Vous pouvez également configurer S3FailurePath sur la réponse du modèle dans Amazon SNS dans le cadre des notifications d'erreur asynchrone pour enquêter sur les défaillances.
Vous pouvez vérifier la métrique InvocationsProcesssed, qui doit correspondre au nombre d'invocations que vous prévoyez de traiter en une minute sur la base d'une simultanéité unique.
La bonne pratique consiste à activer Amazon SNS, qui est un service de notification destiné aux applications orientées messagerie, avec plusieurs abonnés demandant et recevant des notifications « push » de messages à caractère urgent via divers protocoles de transport, dont notamment HTTP, Amazon SQS et la messagerie électronique. L'inférence asynchrone publie des notifications lorsque vous créez un point de terminaison avec CreateEndpointConfig et spécifiez une rubrique Amazon SNS.
Pour utiliser Amazon SNS afin de vérifier les résultats de prédiction à partir de votre point de terminaison asynchrone, vous devez d'abord créer une rubrique, vous abonner à la rubrique, confirmer votre abonnement à la rubrique et noter l'Amazon Resource Name (ARN) de cette rubrique. Pour obtenir des informations détaillées sur la création, l'abonnement et la recherche de l'Amazon ARN d'une rubrique Amazon SNS, consultez Configuration d'Amazon SNS dans le Guide du développeur Amazon SNS. Pour plus d'informations sur l'utilisation d'Amazon SNS avec l'inférence asynchrone, consultez Vérification des résultats de prédiction.
Oui. L'inférence asynchrone fournit un mécanisme permettant de réduire à zéro le nombre d'instances en l'absence de demandes. Si votre point de terminaison a été réduit à zéro instance au cours de ces périodes, votre point de terminaison ne sera pas de nouveau augmenté tant que le nombre de demandes dans la file d'attente ne dépassera pas la cible spécifiée dans votre politique de mise à l'échelle. Cela peut entraîner de longs délais d'attente pour les demandes dans la file d'attente. Dans de tels cas, si vous souhaitez augmenter le nombre d'instances à partir de zéro pour les nouvelles demandes tout en restant sous la cible de file d'attente spécifiée, vous pouvez utiliser une politique de mise à l'échelle supplémentaire appelée HasBacklogWithoutCapacity. Pour plus d'informations sur la façon de définir cette politique de mise à l'échelle, consultez Mise à l'échelle automatique d'un point de terminaison asynchrone.
Pour obtenir la liste exhaustive des instances prises en charge par l'inférence asynchrone par région, consultez Tarification d'Amazon SageMaker
