Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Problème RunBooks
La section suivante décrit les problèmes susceptibles de survenir, explique comment les détecter et propose des suggestions pour les résoudre.
-
Notification par e-mail non reçue après la création AWS CloudFormation réussie des piles
Erreur rencontrée pour le paramètre de bloc CIDR lors de la création de l'environnement
CloudFormation échec de création de pile lors de la création de l'environnement
La création d'une pile de ressources externes (démo) échoue avec AdDomainAdminNode CREATE_FAILED
-
Problèmes de gestion des identités
Lorsque je me connecte à l'environnement, je reviens immédiatement à la page de connexion
Erreur « Utilisateur introuvable » lors de la tentative de connexion
Utilisateur ajouté dans Active Directory, mais absent de RES
Utilisateur non disponible lors de la création d'une session
Erreur de dépassement de la limite de taille dans le journal du gestionnaire de CloudWatch clusters
-
J'ai créé le système de fichiers via RES mais il ne se monte pas sur les hôtes VDI
J'ai intégré un système de fichiers via RES mais il ne se monte pas sur les hôtes VDI
-
Je ne parviens pas à read/write le faire à partir d'hôtes VDI
J'ai créé Amazon FSx pour NetApp ONTAP à partir de RES, mais il n'a pas rejoint mon domaine
Problèmes d'installation
Rubriques
Notification par e-mail non reçue après la création AWS CloudFormation réussie des piles
Erreur rencontrée pour le paramètre de bloc CIDR lors de la création de l'environnement
CloudFormation échec de création de pile lors de la création de l'environnement
La création d'une pile de ressources externes (démo) échoue avec AdDomainAdminNode CREATE_FAILED
........................
AWS CloudFormation la pile ne parvient pas à être créée avec le message « message d'échec WaitCondition reçu ». Erreur : États. TaskFailed»
Pour identifier le problème, examinez le groupe de CloudWatch journaux Amazon nommé<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>. S'il existe plusieurs groupes de journaux portant le même nom, examinez le premier disponible. Un message d'erreur dans les journaux fournira plus d'informations sur le problème.
Note
Vérifiez que les valeurs des paramètres ne comportent pas d'espaces.
........................
Notification par e-mail non reçue après la création AWS CloudFormation réussie des piles
Si aucune invitation par e-mail n'a été reçue après la création réussie des AWS CloudFormation piles, vérifiez les points suivants :
-
Vérifiez que le paramètre d'adresse e-mail a été correctement saisi.
Si l'adresse e-mail est incorrecte ou n'est pas accessible, supprimez et redéployez l'environnement Research and Engineering Studio.
-
Consultez la EC2 console Amazon pour trouver des preuves de l'existence d'instances cycliques.
Si certaines EC2 instances Amazon avec le
<envname>préfixe apparaissent comme terminées puis sont remplacées par une nouvelle instance, il se peut qu'il y ait un problème avec le réseau ou la configuration d'Active Directory. -
Si vous avez déployé les recettes AWS High Performance Compute pour créer vos ressources externes, vérifiez que le VPC, les sous-réseaux privés et publics et les autres paramètres sélectionnés ont été créés par la pile.
Si l'un des paramètres est incorrect, vous devrez peut-être supprimer et redéployer l'environnement RES. Pour de plus amples informations, veuillez consulter Désinstallez le produit.
-
Si vous avez déployé le produit avec vos propres ressources externes, vérifiez que le réseau et Active Directory correspondent à la configuration attendue.
Il est essentiel de confirmer que les instances d'infrastructure ont bien rejoint Active Directory. Essayez les étapes ci-dessous Instances en cycle ou contrôleur VDC en état d'échec pour résoudre le problème.
........................
Instances en cycle ou contrôleur VDC en état d'échec
La cause la plus probable de ce problème est l'incapacité des ressources à se connecter ou à rejoindre Active Directory.
Pour vérifier le problème :
-
À partir de la ligne de commande, démarrez une session avec SSM sur l'instance en cours d'exécution du vdc-controller.
-
Exécutez
sudo su -. -
Exécutez
systemctl status sssd.
Si le statut est inactif, en échec ou si des erreurs apparaissent dans les journaux, cela signifie que l'instance n'a pas pu rejoindre Active Directory.
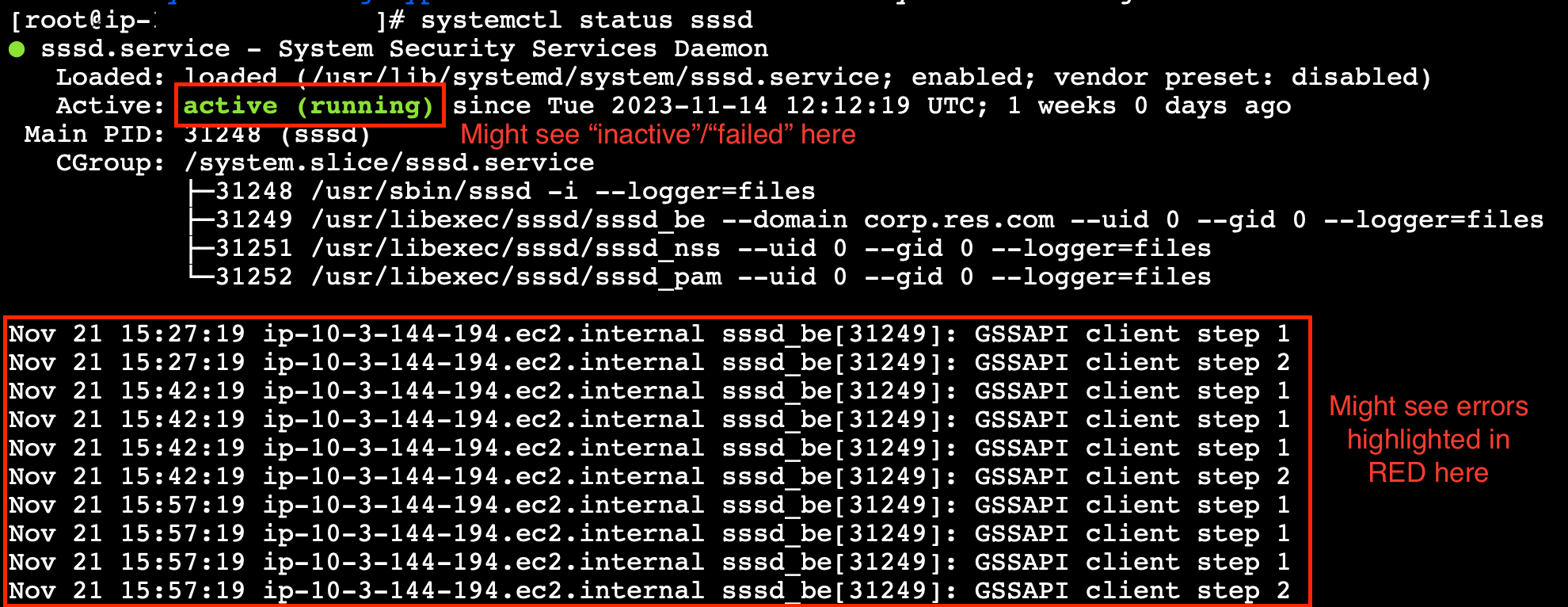
Journal des erreurs SSM
Pour résoudre le problème :
-
À partir de la même instance de ligne de commande, exécutez
cat /root/bootstrap/logs/userdata.logpour examiner les journaux.
Le problème peut avoir l'une des trois causes profondes possibles.
Passez en revue les journaux. Si le message suivant se répète plusieurs fois, cela signifie que l'instance n'a pas pu rejoindre Active Directory.
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
Vérifiez que les valeurs des paramètres suivants ont été saisies correctement lors de la création de la pile RES.
-
directoryservice.ldap_connection_uri
-
directoryservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.ou
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
directoryservice.name
-
-
Mettez à jour les valeurs incorrectes dans la table DynamoDB. La table se trouve dans la console DynamoDB sous Tables. Le nom de la table doit être
<stack name>.cluster-settings -
Après avoir mis à jour la table, supprimez le gestionnaire de clusters et le contrôleur vdc qui exécutent actuellement les instances de l'environnement. Le dimensionnement automatique démarrera de nouvelles instances en utilisant les dernières valeurs de la table DynamoDB.
Si les journaux sont renvoyésInsufficient permissions to modify computer account, le ServiceAccount nom saisi lors de la création de la pile est peut-être incorrect.
-
Depuis la AWS console, ouvrez Secrets Manager.
-
Recherchez
directoryserviceServiceAccountUsername. Le secret devrait être<stack name>-directoryservice-ServiceAccountUsername -
Ouvrez le secret pour afficher la page de détails. Sous Valeur secrète, choisissez Récupérer la valeur secrète, puis Texte en clair.
-
Si la valeur a été mise à jour, supprimez les instances de cluster-manager et vdc-controller en cours d'exécution de l'environnement. Auto Scaling démarrera de nouvelles instances en utilisant la dernière valeur de Secrets Manager.
Si les journaux s'affichentInvalid credentials, le ServiceAccount mot de passe saisi lors de la création de la pile est peut-être incorrect.
-
Depuis la AWS console, ouvrez Secrets Manager.
-
Recherchez
directoryserviceServiceAccountPassword. Le secret devrait être<stack name>-directoryservice-ServiceAccountPassword -
Ouvrez le secret pour afficher la page de détails. Sous Valeur secrète, choisissez Récupérer la valeur secrète, puis Texte en clair.
-
Si vous avez oublié le mot de passe ou si vous n'êtes pas certain que le mot de passe saisi est correct, vous pouvez le réinitialiser dans Active Directory et Secrets Manager.
-
Pour réinitialiser le mot de passe dans AWS Managed Microsoft AD :
-
Ouvrez la AWS console et accédez à AWS Directory Service.
-
Sélectionnez l'ID de répertoire pour votre répertoire RES, puis choisissez Actions.
-
Choisissez Réinitialiser le mot de passe utilisateur.
-
Entrez le ServiceAccount nom d'utilisateur.
-
Entrez un nouveau mot de passe, puis choisissez Réinitialiser le mot de passe.
-
-
Pour réinitialiser le mot de passe dans Secrets Manager, procédez comme suit :
-
Ouvrez la AWS console et accédez à Secrets Manager.
-
Recherchez
directoryserviceServiceAccountPassword. Le secret devrait être<stack name>-directoryservice-ServiceAccountPassword -
Ouvrez le secret pour afficher la page de détails. Sous Valeur secrète, sélectionnez Récupérer la valeur secrète et choisissez Texte en clair.
-
Tâche de sélection Modifier.
-
Définissez un nouveau mot de passe pour l' ServiceAccount utilisateur et sélectionnez Enregistrer.
-
-
-
Si vous avez mis à jour la valeur, supprimez les instances de cluster-manager et vdc-controller en cours d'exécution de l'environnement. La mise à l'échelle automatique démarrera les nouvelles instances en utilisant la dernière valeur.
........................
La CloudFormation pile d'environnements ne parvient pas à être supprimée en raison d'une erreur d'objet dépendant
Si la suppression de la <env-name>-vdcvdcdcvhostsecuritygroup, cela peut être dû à une EC2 instance Amazon lancée dans un sous-réseau ou un groupe de sécurité créé par RES à l'aide de la AWS
console.
Pour résoudre le problème, recherchez et mettez fin à toutes les EC2 instances Amazon lancées de cette manière. Vous pouvez ensuite reprendre la suppression de l'environnement.
........................
Erreur rencontrée pour le paramètre de bloc CIDR lors de la création de l'environnement
Lors de la création d'un environnement, une erreur apparaît pour le paramètre de bloc CIDR avec un statut de réponse de [FAILED].
Exemple d'erreur :
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
Pour résoudre le problème, le format attendu est x.x.x.0/24 ou x.x.x.0/32.
........................
CloudFormation échec de création de pile lors de la création de l'environnement
La création d'un environnement implique une série d'opérations de création de ressources. Dans certaines régions, un problème de capacité peut survenir et entraîner l'échec de la création d'une CloudFormation pile.
Dans ce cas, supprimez l'environnement et réessayez de le créer. Vous pouvez également réessayer la création dans une autre région.
........................
La création d'une pile de ressources externes (démo) échoue avec AdDomainAdminNode CREATE_FAILED
Si la création de la pile d'environnement de démonstration échoue avec l'erreur suivante, cela peut être dû au fait que l'application de EC2 correctifs Amazon s'est produite de manière inattendue lors du provisionnement après le lancement de l'instance.
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
Pour déterminer la cause de l'échec :
-
Dans le gestionnaire d'état SSM, vérifiez si les correctifs sont configurés et s'ils sont configurés pour toutes les instances.
-
Dans l'historique RunCommand/Automation d'exécution du SSM, vérifiez si l'exécution d'un document SSM lié aux correctifs coïncide avec le lancement d'une instance.
-
Dans les fichiers journaux des EC2 instances Amazon de l'environnement, consultez la journalisation des instances locales pour déterminer si l'instance a redémarré pendant le provisionnement.
Si le problème est dû à l'application de correctifs, retardez l'application des correctifs pour les instances RES au moins 15 minutes après le lancement.
........................
Problèmes de gestion des identités
La plupart des problèmes liés à l'authentification unique (SSO) et à la gestion des identités sont dus à une mauvaise configuration. Pour plus d'informations sur la configuration de votre configuration SSO, voir :
Pour résoudre d'autres problèmes liés à la gestion des identités, consultez les rubriques de résolution des problèmes suivantes :
Rubriques
Lorsque je me connecte à l'environnement, je reviens immédiatement à la page de connexion
Erreur « Utilisateur introuvable » lors de la tentative de connexion
Utilisateur ajouté dans Active Directory, mais absent de RES
Utilisateur non disponible lors de la création d'une session
Erreur de dépassement de la limite de taille dans le journal du gestionnaire de CloudWatch clusters
........................
Je ne suis pas autorisé à effectuer iam : PassRole
Si vous recevez un message d'erreur indiquant que vous n'êtes pas autorisé à exécuter l'PassRole action iam :, vos politiques doivent être mises à jour pour vous permettre de transmettre un rôle à RES.
Certains AWS services vous permettent de transmettre un rôle existant à ce service au lieu de créer un nouveau rôle de service ou un rôle lié à un service. Pour ce faire, un utilisateur doit disposer des autorisations nécessaires pour transmettre le rôle au service.
L'exemple d'erreur suivant se produit lorsqu'un utilisateur IAM nommé marymajor essaie d'utiliser la console pour effectuer une action dans RES. Toutefois, l’action nécessite que le service ait des autorisations accordées par un rôle de service. Mary ne dispose pas des autorisations nécessaires pour transférer le rôle au service.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
Dans ce cas, les politiques de Mary doivent être mises à jour pour lui permettre d'effectuer l'PassRole action iam :. Si vous avez besoin d'aide, contactez votre AWS administrateur. Votre administrateur vous a fourni vos informations d’identification de connexion.
........................
Je souhaite autoriser des personnes extérieures à mon AWS compte à accéder à mon studio de recherche et d'ingénierie sur les AWS ressources
Vous pouvez créer un rôle que les utilisateurs provenant d’autres comptes ou les personnes extérieures à votre organisation pourront utiliser pour accéder à vos ressources. Vous pouvez spécifier qui est autorisé à assumer le rôle. Pour les services qui prennent en charge les politiques basées sur les ressources ou les listes de contrôle d'accès (ACLs), vous pouvez utiliser ces politiques pour autoriser les utilisateurs à accéder à vos ressources.
Pour plus d’informations, consultez les éléments suivants :
-
Pour savoir comment fournir un accès à vos ressources sur les AWS comptes que vous possédez, consultez la section Fournir un accès à un utilisateur IAM sur un autre AWS compte que vous possédez dans le Guide de l'utilisateur IAM.
-
Pour savoir comment fournir l'accès à vos ressources à des AWS comptes tiers, consultez la section Fournir un accès aux AWS comptes détenus par des tiers dans le guide de l'utilisateur IAM.
-
Pour savoir comment fournir un accès via la fédération d'identité, consultez la section Fournir un accès aux utilisateurs authentifiés de manière externe (fédération d'identité) dans le guide de l'utilisateur IAM.
-
Pour connaître la différence entre l'utilisation de rôles et de politiques basées sur les ressources pour l'accès entre comptes, consultez la section En quoi les rôles IAM diffèrent des politiques basées sur les ressources dans le Guide de l'utilisateur IAM.
........................
Lorsque je me connecte à l'environnement, je reviens immédiatement à la page de connexion
Ce problème se produit lorsque votre intégration SSO est mal configurée. Pour déterminer le problème, consultez les journaux de l'instance du contrôleur et vérifiez que les paramètres de configuration ne contiennent pas d'erreurs.
Pour consulter les journaux :
-
Ouvrez la CloudWatch console
. -
Dans Groupes de journaux, recherchez le groupe nommé
/.<environment-name>/cluster-manager -
Ouvrez le groupe de journaux pour rechercher d'éventuelles erreurs dans les flux de journaux.
Pour vérifier les paramètres de configuration :
-
Ouvrez la console DynamoDB
-
Dans Tables, recherchez la table nommée
<environment-name>.cluster-settings -
Ouvrez le tableau et sélectionnez Explorer les éléments du tableau.
-
Développez la section des filtres et entrez les variables suivantes :
-
Nom de l'attribut — clé
-
État — contient
-
Valeur — SSO
-
-
Sélectionnez Exécuter.
-
Dans la chaîne renvoyée, vérifiez que les valeurs de configuration SSO sont correctes. S'ils sont incorrects, remplacez la valeur de la clé sso_enabled par False.
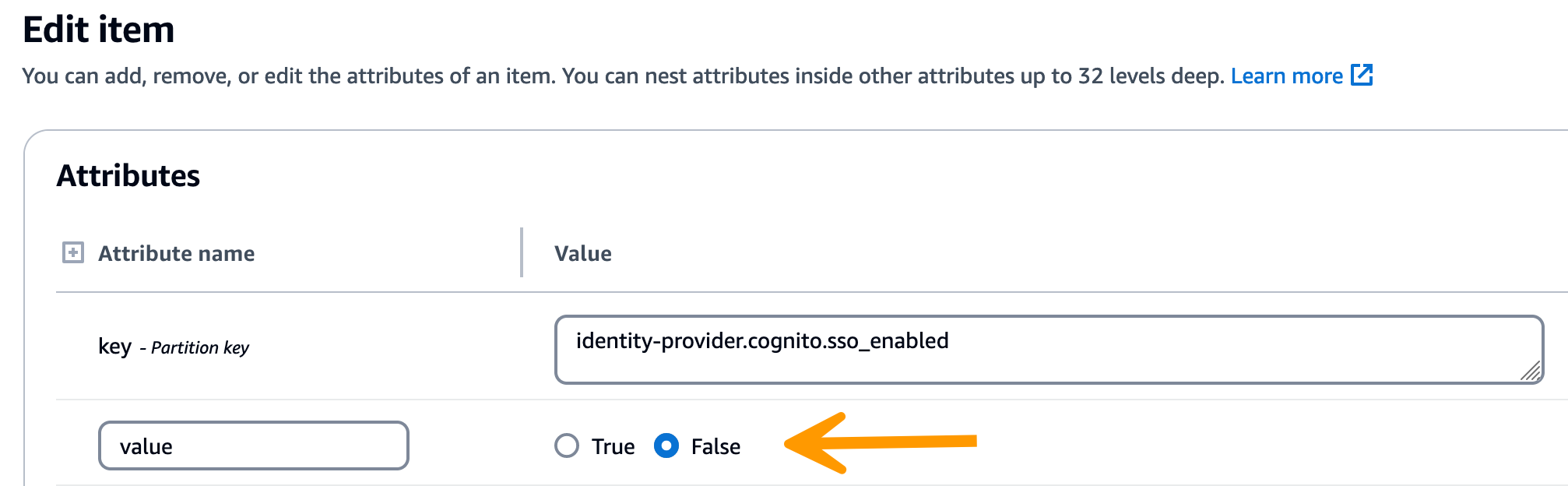
-
Retournez à l'interface utilisateur RES pour reconfigurer le SSO.
........................
Erreur « Utilisateur introuvable » lors de la tentative de connexion
Si un utilisateur reçoit le message d'erreur « Utilisateur introuvable » lorsqu'il essaie de se connecter à l'interface RES, alors que l'utilisateur est présent dans Active Directory :
-
Si l'utilisateur n'est pas présent dans RES et que vous l'avez récemment ajouté à AD
-
Il est possible que l'utilisateur ne soit pas encore synchronisé avec RES. RES se synchronise toutes les heures, vous devrez donc peut-être attendre et vérifier que l'utilisateur a été ajouté après la prochaine synchronisation. Pour synchroniser immédiatement, suivez les étapes décrites dansUtilisateur ajouté dans Active Directory, mais absent de RES.
-
-
Si l'utilisateur est présent dans RES :
-
Assurez-vous que le mappage des attributs est correctement configuré. Pour de plus amples informations, veuillez consulter Configuration de votre fournisseur d'identité pour l'authentification unique (SSO).
-
Assurez-vous que l'objet et l'e-mail SAML correspondent tous deux à l'adresse e-mail de l'utilisateur.
-
........................
Utilisateur ajouté dans Active Directory, mais absent de RES
Si vous avez ajouté un utilisateur à Active Directory mais qu'il est absent de RES, la synchronisation AD doit être déclenchée. La synchronisation AD est effectuée toutes les heures par une fonction Lambda qui importe des entrées AD dans l'environnement RES. Parfois, il y a un délai avant l'exécution du prochain processus de synchronisation après l'ajout de nouveaux utilisateurs ou groupes. Vous pouvez lancer la synchronisation manuellement depuis le service Amazon Simple Queue.
Lancez le processus de synchronisation manuellement :
-
Ouvrez la console Amazon SQS
. -
Dans Files d'attente, sélectionnez
<environment-name>-cluster-manager-tasks.fifo. -
Sélectionnez Envoyer et recevoir des messages.
-
Dans le champ Corps du message, entrez :
{ "name": "adsync.sync-from-ad", "payload": {} } -
Pour l'ID du groupe de messages, entrez :
adsync.sync-from-ad -
Pour l'ID de déduplication des messages, entrez une chaîne alphanumérique aléatoire. Cette entrée doit être différente de tous les appels effectués au cours des cinq minutes précédentes, sinon la demande sera ignorée.
........................
Utilisateur non disponible lors de la création d'une session
Si vous êtes un administrateur qui crée une session, mais que vous constatez qu'un utilisateur figurant dans Active Directory n'est pas disponible lors de la création d'une session, il se peut que l'utilisateur doive se connecter pour la première fois. Les sessions ne peuvent être créées que pour les utilisateurs actifs. Les utilisateurs actifs doivent se connecter à l'environnement au moins une fois.
........................
Erreur de dépassement de la limite de taille dans le journal du gestionnaire de CloudWatch clusters
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
Si vous recevez cette erreur dans le journal du CloudWatch gestionnaire de clusters, la recherche LDAP a peut-être renvoyé trop d'enregistrements utilisateur. Pour résoudre ce problème, augmentez la limite de résultats de recherche LDAP de votre fournisseur de services Internet.
........................
Stockage
Rubriques
J'ai créé le système de fichiers via RES mais il ne se monte pas sur les hôtes VDI
J'ai intégré un système de fichiers via RES mais il ne se monte pas sur les hôtes VDI
Je ne parviens pas à read/write le faire à partir d'hôtes VDI
J'ai créé Amazon FSx pour NetApp ONTAP à partir de RES, mais il n'a pas rejoint mon domaine
........................
J'ai créé le système de fichiers via RES mais il ne se monte pas sur les hôtes VDI
Les systèmes de fichiers doivent être dans l'état « Disponible » avant de pouvoir être montés par des hôtes VDI. Suivez les étapes ci-dessous pour vérifier que le système de fichiers est dans l'état requis.
Amazon EFS
-
Accédez à la console Amazon EFS
. -
Vérifiez que l'état du système de fichiers est disponible.
-
Si l'état du système de fichiers n'est pas disponible, attendez avant de lancer les hôtes VDI.
-
Accédez à la FSx console Amazon
. -
Vérifiez que le statut est disponible.
-
Si le statut n'est pas disponible, attendez avant de lancer les hôtes VDI.
........................
J'ai intégré un système de fichiers via RES mais il ne se monte pas sur les hôtes VDI
Les systèmes de fichiers intégrés à RES doivent avoir les règles de groupe de sécurité requises configurées pour permettre aux hôtes VDI de monter les systèmes de fichiers. Ces systèmes de fichiers étant créés en externe à RES, RES ne gère pas les règles de groupe de sécurité associées.
Le groupe de sécurité associé aux systèmes de fichiers intégrés doit autoriser le trafic entrant suivant :
Trafic NFS (port : 2049) depuis les hôtes Linux VDC
Trafic SMB (port : 445) depuis les hôtes Windows VDC
........................
Je ne parviens pas à read/write le faire à partir d'hôtes VDI
ONTAP prend en charge les styles de sécurité UNIX, NTFS et MIXED pour les volumes. Les styles de sécurité déterminent le type d'autorisations qu'ONTAP utilise pour contrôler l'accès aux données et le type de client qui peut modifier ces autorisations.
Par exemple, si un volume utilise le style de sécurité UNIX, les clients SMB peuvent toujours accéder aux données (à condition qu'ils s'authentifient et autorisent correctement) en raison de la nature multiprotocole d'ONTAP. ONTAP utilise toutefois des autorisations UNIX que seuls les clients UNIX peuvent modifier à l'aide d'outils natifs.
Exemples de cas d'utilisation relatifs à la gestion des autorisations
Utilisation d'un volume de style UNIX avec des charges de travail Linux
Les autorisations peuvent être configurées par le sudoer pour les autres utilisateurs. Par exemple, ce qui suit accorderait à tous les membres des read/write autorisations <group-ID> complètes sur le /<project-name> répertoire :
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Utilisation d'un volume de style NTFS avec des charges de travail Linux et Windows
Les autorisations de partage peuvent être configurées à l'aide des propriétés de partage d'un dossier spécifique. Par exemple, pour un utilisateur user_01 et un dossiermyfolder, vous pouvez définir des autorisations de Full ControlChange, ou Read pour Allow ou Deny :
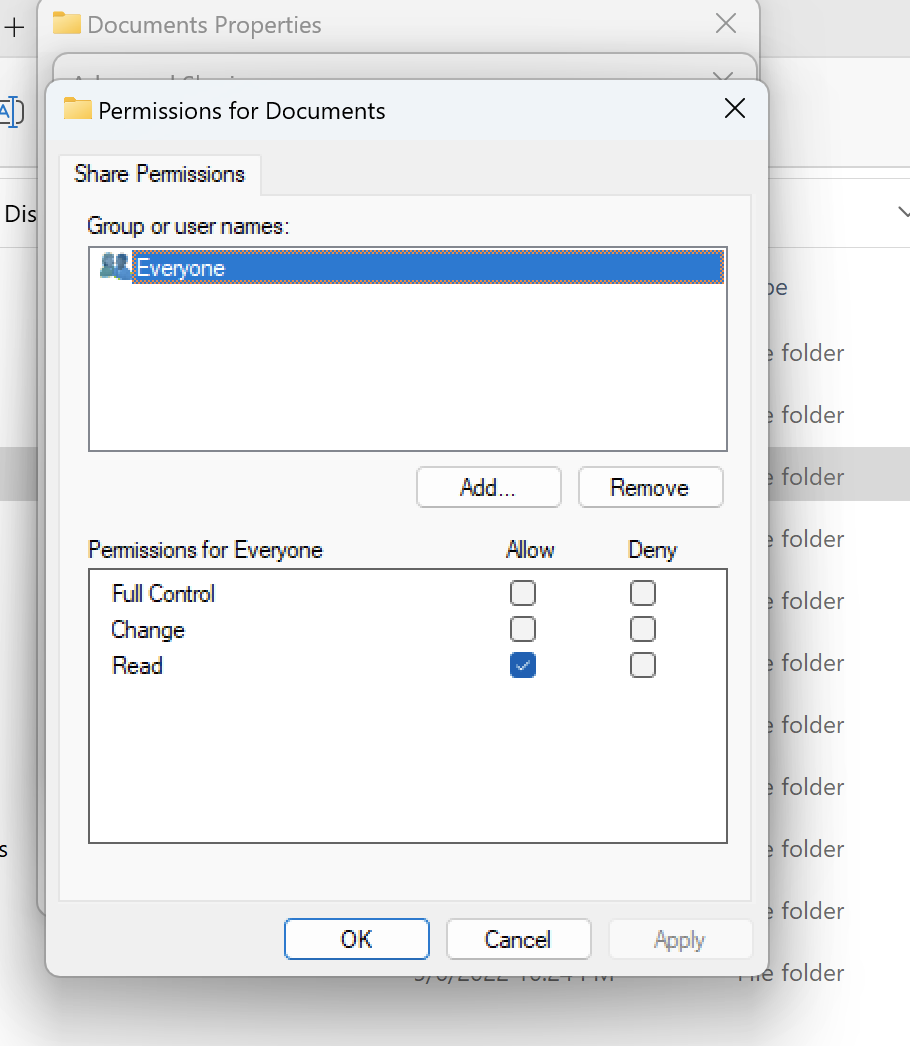
Si le volume doit être utilisé à la fois par des clients Linux et Windows, nous devons configurer un mappage de noms sur la SVM qui associera tout nom d'utilisateur Linux au même nom d'utilisateur au format de nom de domaine NetBIOS de domaine \ nom d'utilisateur. Cela est nécessaire pour traduire entre les utilisateurs de Linux et de Windows. Pour référence, voir Activation des charges de travail multiprotocoles avec Amazon FSx pour NetApp
........................
J'ai créé Amazon FSx pour NetApp ONTAP à partir de RES, mais il n'a pas rejoint mon domaine
Actuellement, lorsque vous créez Amazon FSx pour NetApp ONTAP à partir de la console RES, le système de fichiers est provisionné mais il ne rejoint pas le domaine. Pour associer la SVM du système de fichiers ONTAP créée à votre domaine, consultez Joindre SVMs à un Microsoft Active Directory et suivez les étapes indiquées sur la console Amazon FSx
Une fois qu'elle est jointe au domaine, modifiez la clé de configuration DNS SMB dans le tableau DynamoDB des paramètres du cluster :
-
Accédez à la console Amazon DynamoDB
. -
Sélectionnez Tables, puis choisissez
<stack-name>-cluster-settings. -
Sous Explorer les éléments du tableau, développez les filtres et entrez le filtre suivant :
Nom de l'attribut - clé
État : égal à
-
Valeur -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
Sélectionnez l'article renvoyé, puis Actions, Modifier l'article.
-
Mettez à jour la valeur avec le nom DNS SMB que vous avez copié précédemment.
-
Sélectionnez Enregistrer et fermez.
En outre, assurez-vous que le groupe de sécurité associé au système de fichiers autorise le trafic conformément aux recommandations de la section Contrôle d'accès au système de fichiers avec Amazon VPC. Les nouveaux hôtes VDI utilisant le système de fichiers pourront désormais monter la SVM et le système de fichiers joints au domaine.
Vous pouvez également intégrer un système de fichiers existant déjà joint à votre domaine à l'aide de la fonctionnalité RES Onboard File System : dans Gestion de l'environnement, sélectionnez Systèmes de fichiers, Système de fichiers intégré.
........................
Instantanés
Rubriques
........................
Un instantané a le statut Echoué
Sur la page RES Snapshots, si un instantané a le statut Echec, vous pouvez en déterminer la cause en accédant au groupe de CloudWatch journaux Amazon du gestionnaire de clusters au moment où l'erreur s'est produite.
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
Un instantané ne s'applique pas avec des journaux indiquant que les tables n'ont pas pu être importées.
Si un instantané pris à partir d'un environnement précédent ne s'applique pas dans un nouvel environnement, consultez les CloudWatch journaux du gestionnaire de clusters pour identifier le problème. Si le problème indique que les tables requises ne peuvent pas être importées, vérifiez que l'instantané est dans un état valide.
-
Téléchargez le fichier metadata.json et vérifiez que le ExportStatus statut des différentes tables est COMPLETED. Assurez-vous que le
ExportManifestchamp est défini dans les différentes tables. Si les champs ci-dessus ne sont pas définis, l'état de l'instantané n'est pas valide et ne peut pas être utilisé avec la fonctionnalité d'application d'un instantané. -
Après avoir lancé la création d'un instantané, assurez-vous que le statut de l'instantané passe à TERMINÉ dans RES. Le processus de création d'un instantané prend de 5 à 10 minutes. Rechargez ou revisitez la page de gestion des instantanés pour vous assurer que le cliché a été créé avec succès. Cela garantira que l'instantané créé est dans un état valide.
........................
Infrastructure
........................
Groupes cibles d'équilibreur de charge dépourvus d'instances saines
Si des problèmes tels que des messages d'erreur du serveur apparaissent dans l'interface utilisateur ou si les sessions de bureau ne peuvent pas se connecter, cela peut indiquer un problème dans l'infrastructure EC2 des instances Amazon.
Les méthodes permettant de déterminer la source du problème consistent à vérifier d'abord dans la EC2 console Amazon la présence d' EC2 instances Amazon qui semblent se terminer à plusieurs reprises et être remplacées par de nouvelles instances. Si tel est le cas, la vérification des CloudWatch journaux Amazon peut en déterminer la cause.
Une autre méthode consiste à vérifier les équilibreurs de charge du système. Cela indique qu'il peut y avoir des problèmes avec le système si les équilibreurs de charge, trouvés sur la EC2 console Amazon, n'affichent aucune instance saine enregistrée.
Voici un exemple d'apparence normale :
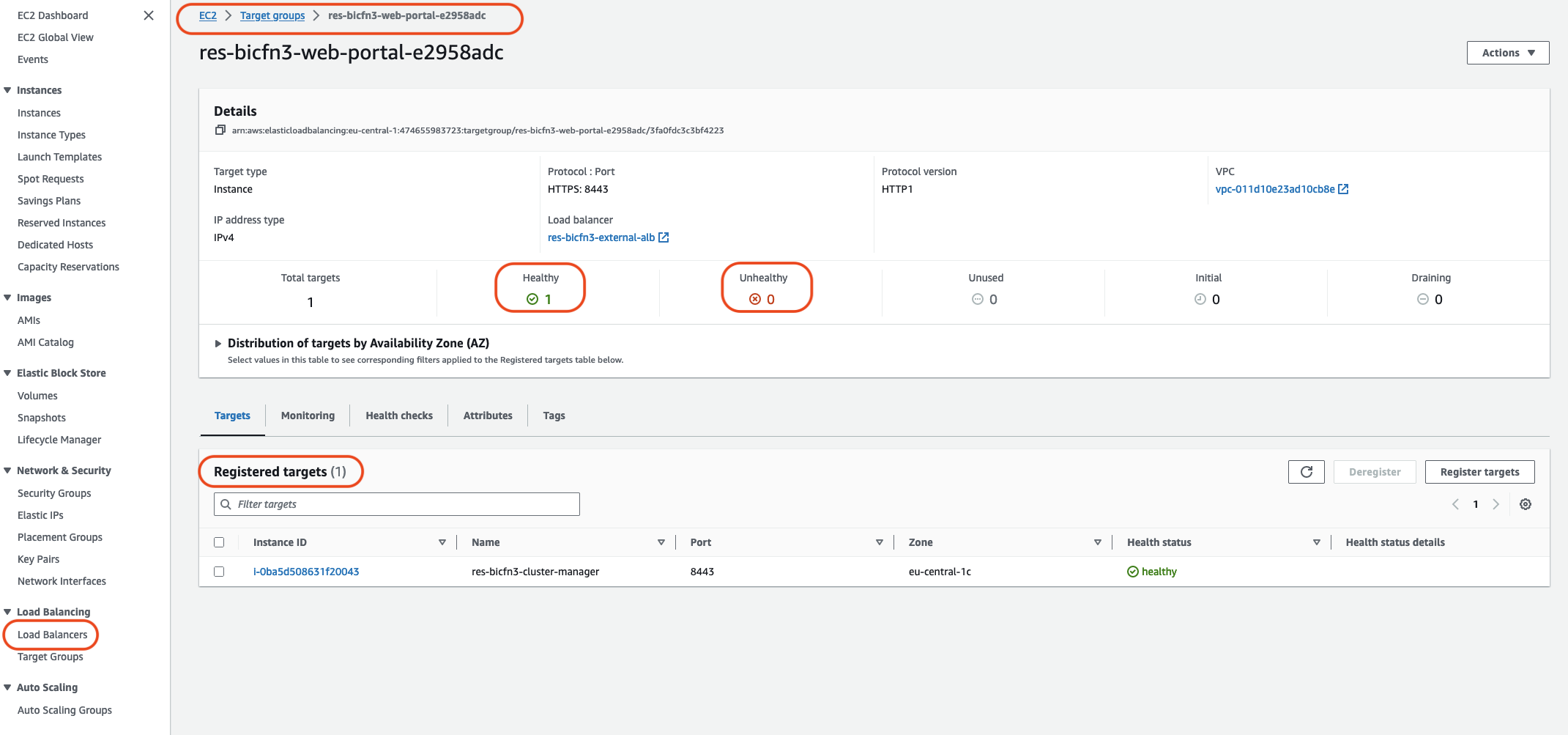
Si l'entrée Healthy est 0, cela indique qu'aucune EC2 instance Amazon n'est disponible pour traiter les demandes.
Si l'entrée Unhealthy n'est pas égale à 0, cela indique qu'une EC2 instance Amazon est peut-être en cours de cycle. Cela peut être dû au fait que le logiciel d'application installé ne passe pas les tests de santé.
Si les entrées saines et malsaines sont toutes deux égales à 0, cela indique une erreur de configuration potentielle du réseau. Par exemple, les sous-réseaux public et privé peuvent ne pas avoir de correspondance AZs. Dans ce cas, un texte supplémentaire peut apparaître sur la console indiquant que l'état du réseau existe.
........................
Lancement de bureaux virtuels
........................
Un bureau virtuel qui fonctionnait auparavant ne peut plus se connecter correctement
Si une connexion de bureau se ferme ou si vous ne pouvez plus vous y connecter, le problème peut être dû à la défaillance de l' EC2 instance Amazon sous-jacente ou à la résiliation ou à l'arrêt de l' EC2 instance Amazon en dehors de l'environnement RES. L'état de l'interface utilisateur d'administration peut continuer à indiquer qu'il est prêt, mais les tentatives de connexion échouent.
La EC2 console Amazon doit être utilisée pour déterminer si l'instance a été résiliée ou arrêtée. En cas d'arrêt, essayez de le redémarrer. Si l'état est résilié, un autre bureau devra être créé. Toutes les données stockées dans le répertoire personnel de l'utilisateur doivent toujours être disponibles au démarrage de la nouvelle instance.
Si l'instance qui a échoué précédemment apparaît toujours dans l'interface utilisateur d'administration, il peut être nécessaire de la fermer à l'aide de l'interface utilisateur d'administration.
........................
Je ne peux lancer que 5 bureaux virtuels
La limite par défaut du nombre de bureaux virtuels qu'un utilisateur peut lancer est de 5. Cela peut être modifié par un administrateur à l'aide de l'interface utilisateur d'administration comme suit :
Accédez aux paramètres du bureau.
Sélectionnez l'onglet Serveur.
Dans le panneau DCV Session, cliquez sur l'icône d'édition à droite.
Modifiez la valeur du champ Sessions autorisées par utilisateur à la nouvelle valeur souhaitée.
Sélectionnez Submit (Envoyer).
Actualisez la page pour confirmer que le nouveau paramètre est en place.
........................
Les tentatives de connexion Windows pour ordinateur de bureau échouent avec le message « La connexion a été fermée ». Erreur de transport »
Si une connexion de bureau Windows échoue avec le message d'erreur « La connexion a été fermée » s'affiche dans l'interface utilisateur. « Erreur de transport », la cause peut être due à un problème dans le logiciel du serveur DCV lié à la création de certificats sur l'instance Windows.
Le groupe de CloudWatch log Amazon <envname>/vdc/dcv-connection-gateway peut enregistrer l'erreur de tentative de connexion avec des messages similaires aux suivants :
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
Dans ce cas, une solution peut être d'utiliser le gestionnaire de session SSM pour ouvrir une connexion à l'instance Windows et supprimer les 2 fichiers relatifs aux certificats suivants :
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
Les fichiers doivent être automatiquement recréés et une tentative de connexion ultérieure peut réussir.
Si cette méthode résout le problème et si les nouveaux lancements de postes de travail Windows produisent la même erreur, utilisez la fonction Create Software Stack pour créer une nouvelle pile logicielle Windows de l'instance fixe avec les fichiers de certificat régénérés. Cela peut produire une pile logicielle Windows qui peut être utilisée pour des lancements et des connexions réussis.
........................
VDIs bloqué dans l'état de provisionnement
Si le lancement d'un poste de travail reste en état de provisionnement dans l'interface utilisateur d'administration, cela peut être dû à plusieurs raisons.
Pour en déterminer la cause, examinez les fichiers journaux de l'instance de bureau et recherchez les erreurs susceptibles d'être à l'origine du problème. Ce document contient une liste de fichiers journaux et de groupes de CloudWatch journaux Amazon contenant des informations pertinentes dans la section intitulée Sources d'informations utiles sur les journaux et les événements.
Les causes potentielles de ce problème sont les suivantes.
-
L'identifiant AMI utilisé a été enregistré en tant que pile logicielle mais n'est pas pris en charge par RES.
Le script de provisionnement bootstrap n'a pas pu se terminer car l'AMI ne dispose pas de la configuration attendue ou de l'outillage requis. Les fichiers journaux de l'instance, par exemple
/root/bootstrap/logs/sur une instance Linux, peuvent contenir des informations utiles à ce sujet. AMIs les identifiants extraits du AWS Marketplace peuvent ne pas fonctionner pour les instances de bureau RES. Ils doivent être testés pour confirmer s'ils sont pris en charge. -
Les scripts de données utilisateur ne sont pas exécutés lorsque l'instance de bureau virtuel Windows est lancée à partir d'une AMI personnalisée.
Par défaut, les scripts de données utilisateur s'exécutent une seule fois lors du lancement d'une EC2 instance Amazon. Si vous créez une AMI à partir d'une instance de bureau virtuel existante, puis que vous enregistrez une pile logicielle auprès de l'AMI et que vous essayez de lancer un autre bureau virtuel avec cette pile logicielle, les scripts de données utilisateur ne s'exécuteront pas sur la nouvelle instance de bureau virtuel.
Pour résoudre le problème, ouvrez une fenêtre de PowerShell commande en tant qu'administrateur sur l'instance de bureau virtuel d'origine que vous avez utilisée pour créer l'AMI, puis exécutez la commande suivante :
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –ScheduleCréez ensuite une nouvelle AMI à partir de l'instance. Vous pouvez utiliser la nouvelle AMI pour enregistrer des piles de logiciels et lancer de nouveaux bureaux virtuels par la suite. Notez que vous pouvez également exécuter la même commande sur l'instance qui reste dans l'état de provisionnement et redémarrer l'instance pour corriger la session de bureau virtuel, mais vous rencontrerez à nouveau le même problème lors du lancement d'un autre bureau virtuel à partir de l'AMI mal configurée.
........................
VDIs passer à l'état d'erreur après le lancement
- Problème possible 1 : le système de fichiers personnel possède un répertoire pour l'utilisateur avec différentes autorisations POSIX.
-
C'est peut-être le problème que vous rencontrez si les scénarios suivants sont vrais :
-
La version RES déployée est 2024.01 ou supérieure.
-
Lors du déploiement de la pile RES, l'attribut for
EnableLdapIDMappinga été défini surTrue. -
Le système de fichiers home spécifié lors du déploiement de la pile RES était utilisé dans une version antérieure à RES 2024.01 ou dans un environnement précédent avec
EnableLdapIDMappingune valeur définie sur.False
Étapes de résolution : supprimez les répertoires utilisateur du système de fichiers.
-
SSM vers l'hôte du gestionnaire de clusters.
-
cd /home. -
ls- doit répertorier les répertoires dont les noms de répertoire correspondent aux noms d'utilisateur, tels queadmin1,admin2.. et ainsi de suite. -
Supprimez les répertoires,
sudo rm -r 'dir_name'. Ne supprimez pas les répertoires ssm-user et ec2-user. -
Si les utilisateurs sont déjà synchronisés avec le nouvel environnement, supprimez ceux de l'utilisateur de la table DDB de l'utilisateur (sauf clusteradmin).
-
Lancez la synchronisation AD :
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-adexécutez-la dans le gestionnaire de clusters Amazon. EC2 -
Redémarrez l'instance VDI dans l'
Errorétat indiqué sur la page Web RES. Vérifiez que le VDI passe à l'Readyétat en 20 minutes environ.
-
........................
Composant de bureau virtuel
Rubriques
........................
L' EC2 instance Amazon s'affiche à plusieurs reprises comme terminée dans la console
Si une instance d'infrastructure apparaît à plusieurs reprises comme étant terminée dans la EC2 console Amazon, la cause peut être liée à sa configuration et dépendre du type d'instance d'infrastructure. Les méthodes suivantes permettent d'en déterminer la cause.
Si l'instance vdc-controller affiche des états de terminaison répétés dans la EC2 console Amazon, cela peut être dû à une balise secrète incorrecte. Les secrets conservés par RES comportent des balises utilisées dans le cadre des politiques de contrôle d'accès IAM associées aux EC2 instances Amazon de l'infrastructure. Si le contrôleur vdc fonctionne en cycle et que l'erreur suivante apparaît dans le groupe de CloudWatch journaux, cela peut être dû au fait qu'un secret n'a pas été correctement étiqueté. Notez que le secret doit être marqué comme suit :
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
Le message du CloudWatch journal Amazon correspondant à cette erreur s'affichera comme suit :
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Vérifiez les balises de l' EC2 instance Amazon et confirmez qu'elles correspondent à la liste ci-dessus.
........................
L'instance vdc-controller est en cours de cycle car le module AD/eVDI ne parvient pas à rejoindre le module AD/eVDI et affiche un échec du contrôle de santé de l'API
Si le module eVDI échoue lors de son contrôle de santé, il affichera ce qui suit dans la section État de l'environnement.
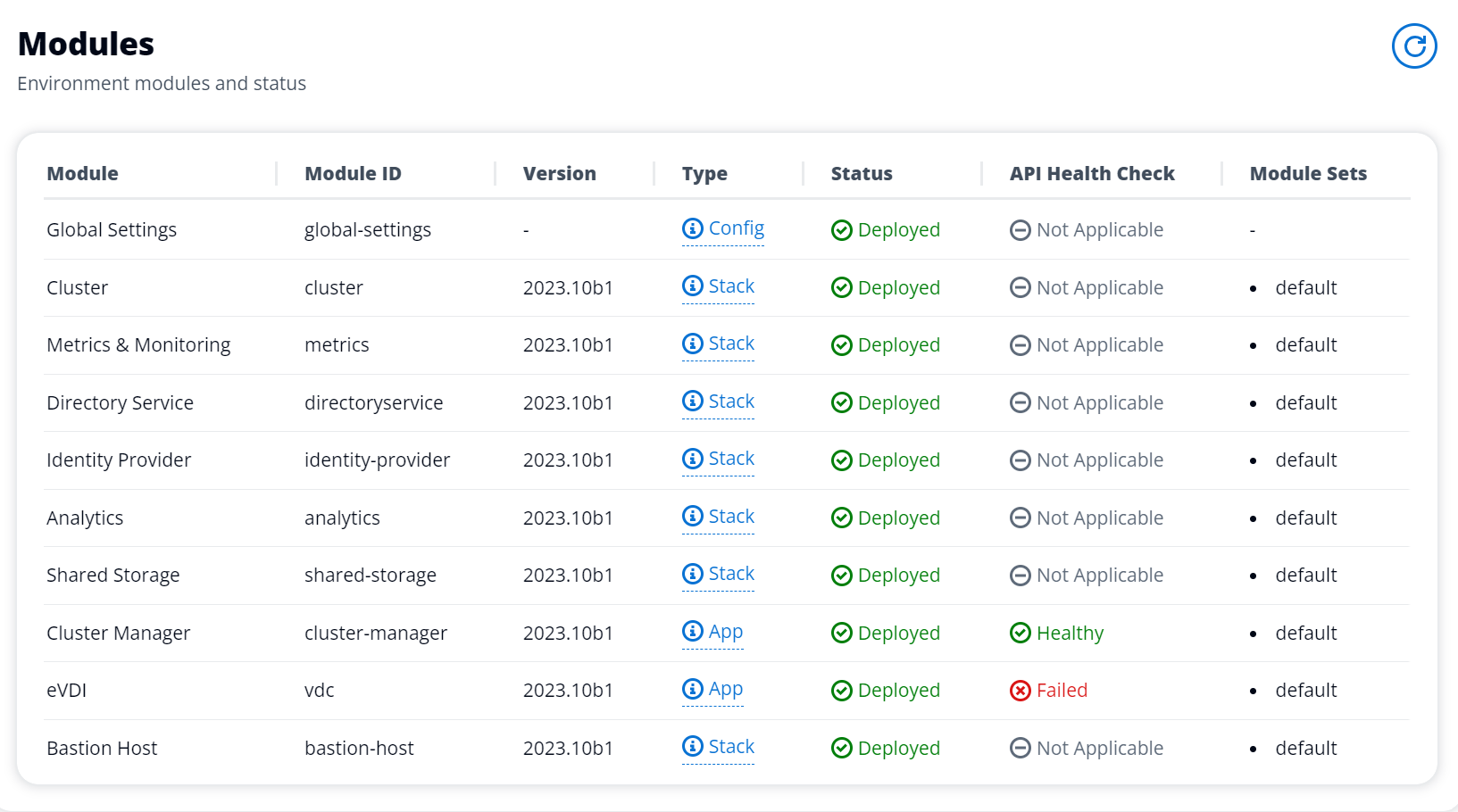
Dans ce cas, le chemin général pour le débogage consiste à consulter les journaux du gestionnaire de clusters CloudWatch<env-name>/cluster-manager.)
Problèmes possibles :
-
Si les journaux contiennent le texte
Insufficient permissions, assurez-vous que le ServiceAccount nom d'utilisateur indiqué lors de la création de la pile res est correctement orthographié.Exemple de ligne de journal :
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
Vous pouvez accéder au ServiceAccount nom d'utilisateur fourni lors du déploiement de RES depuis la SecretsManager console
. Trouvez le secret correspondant dans le gestionnaire de secrets et sélectionnez Récupérer le texte brut. Si le nom d'utilisateur est incorrect, sélectionnez Modifier pour mettre à jour la valeur secrète. Arrêtez les instances actuelles de cluster-manager et de vdc-controller. Les nouvelles instances apparaîtront dans un état stable. -
Le nom d'utilisateur doit être ServiceAccount « » si vous utilisez les ressources créées par la pile de ressources externes fournie. Si le
DisableADJoinparamètre a été défini sur False lors de votre déploiement de RES, assurez-vous que l'utilisateur ServiceAccount « » est autorisé à créer des objets informatiques dans l'AD.
-
-
Si le nom d'utilisateur utilisé est correct, mais que les journaux contiennent le texte
Invalid credentials, le mot de passe que vous avez saisi est peut-être erroné ou a expiré.Exemple de ligne de journal :
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
Vous pouvez lire le mot de passe que vous avez saisi lors de la création de l'environnement en accédant au secret qui stocke le mot de passe dans la console Secrets Manager
. Sélectionnez le secret (par exemple <env_name>directoryserviceServiceAccountPassword), puis sélectionnez Récupérer du texte brut. -
Si le mot de passe indiqué dans le secret est incorrect, sélectionnez Modifier pour mettre à jour sa valeur dans le secret. Arrêtez les instances actuelles de cluster-manager et de vdc-controller. Les nouvelles instances utiliseront le mot de passe mis à jour et apparaîtront dans un état stable.
-
Si le mot de passe est correct, il se peut qu'il ait expiré dans l'Active Directory connecté. Vous devez d'abord réinitialiser le mot de passe dans Active Directory, puis mettre à jour le secret. Vous pouvez réinitialiser le mot de passe de l'utilisateur dans Active Directory à partir de la console Directory Service
: -
Choisissez l'ID de répertoire approprié
-
Sélectionnez Actions, Réinitialiser le mot de passe utilisateur, puis remplissez le formulaire avec le nom d'utilisateur (par exemple, ServiceAccount « ») et le nouveau mot de passe.
-
Si le nouveau mot de passe est différent du mot de passe précédent, mettez-le à jour dans le secret Secret Manager correspondant (par exemple,
<env_name>directoryserviceServiceAccountPassword. -
Arrêtez les instances actuelles de cluster-manager et de vdc-controller. Les nouvelles instances apparaîtront dans un état stable.
-
-
........................
Le projet n'apparaît pas dans le menu déroulant lorsque vous modifiez la Suite logicielle pour l'ajouter
Ce problème peut être lié au problème suivant associé à la synchronisation du compte utilisateur avec AD. Si ce problème apparaît, vérifiez la présence de l'erreur <user-home-init> account not available yet. waiting for user to be synced « » dans le groupe de journaux CloudWatch Amazon du gestionnaire de clusters afin de déterminer si la cause est identique ou liée.
........................
Le journal CloudWatch Amazon du gestionnaire de clusters indique que « user-home-init < > le compte n'est pas encore disponible. En attente de synchronisation de l'utilisateur » (où le compte est un nom d'utilisateur)
L'abonné SQS est occupé et bloqué dans une boucle infinie car il ne peut pas accéder au compte utilisateur. Ce code est déclenché lorsque vous essayez de créer un système de fichiers personnel pour un utilisateur lors de la synchronisation utilisateur.
La raison pour laquelle il ne parvient pas à accéder au compte utilisateur peut être que RES n'a pas été configuré correctement pour l'AD utilisé. Par exemple, le ServiceAccountUsername paramètre utilisé lors de la création de BI/RES l'environnement n'était pas la bonne valeur, par exemple en utilisant « ServiceAccount » au lieu de « Admin ».
........................
Lors de la tentative de connexion, Windows Desktop indique « Votre compte a été désactivé. Veuillez consulter votre administrateur. »
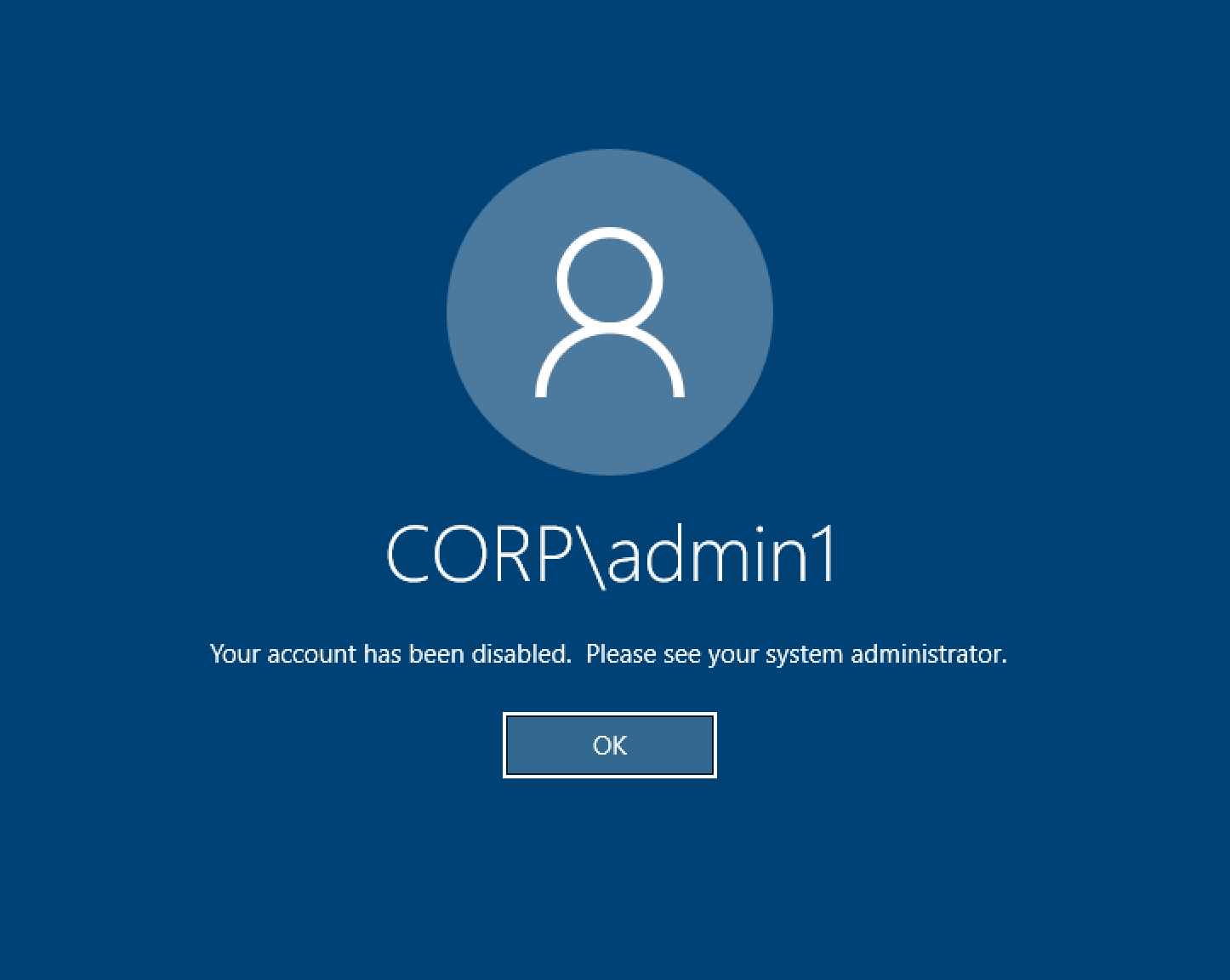
Si l'utilisateur ne parvient pas à se reconnecter à un écran verrouillé, cela peut indiquer qu'il a été désactivé dans l'AD configuré pour RES après s'être connecté avec succès via SSO.
La connexion SSO devrait échouer si le compte utilisateur a été désactivé dans AD.
........................
Problèmes liés aux options DHCP avec la configuration d' external/customer AD
Si vous rencontrez un message d'erreur indiquant que "The connection has been closed. Transport
error" vous utilisez les bureaux virtuels Windows lorsque vous utilisez RES avec votre propre Active Directory, consultez le CloudWatch journal dcv-connection-gateway Amazon pour trouver un résultat similaire à ce qui suit :
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
Si vous utilisez un contrôleur de domaine AD pour vos options DHCP pour votre propre VPC, vous devez :
-
Ajoutez le AmazonProvided DNS aux deux contrôleurs de domaine IPs.
-
Définissez le nom de domaine sur ec2.internal.
Un exemple est présenté ici. Sans cette configuration, le bureau Windows vous donnera une erreur de transport, car il RES/DCV recherche le nom d'hôte ip-10-0-x-xx.ec2.internal.

........................
Erreur Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Lorsque vous utilisez le navigateur Web Firefox, le message d'erreur de type MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING peut s'afficher lorsque vous essayez de vous connecter à un bureau virtuel.
Vous pouvez résoudre ce problème en suivant les instructions disponibles sur : https://really-simple-ssl.com/mozilla_pkix_error_required_tls_feature_missing
........................
Suppression d'environnements
........................
res-xxx-cluster pile dans l'état « DELETE_FAILED » et ne peut pas être supprimée manuellement en raison de l'erreur « Le rôle n'est pas valide ou ne peut pas être assumé »
Si vous remarquez que la pile « res-xxx-cluster » est dans l'état « DELETE_FAILED » et ne peut pas être supprimée manuellement, vous pouvez effectuer les étapes suivantes pour la supprimer.
Si vous voyez la pile dans un état « DELETE_FAILED », essayez d'abord de la supprimer manuellement. Une boîte de dialogue confirmant Delete Stack peut s'afficher. Sélectionnez Delete (Supprimer).
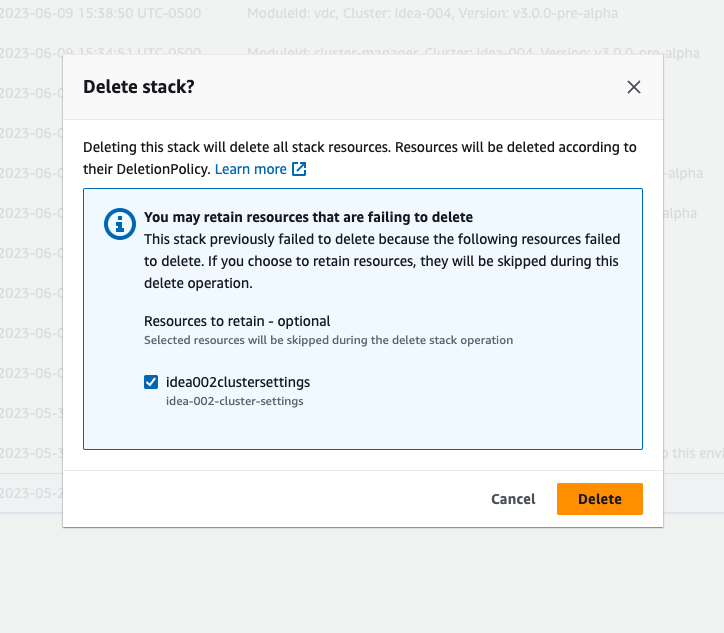
Parfois, même si vous supprimez toutes les ressources de pile requises, vous pouvez toujours voir le message vous demandant de sélectionner les ressources à conserver. Dans ce cas, sélectionnez toutes les ressources comme « ressources à conserver » et sélectionnez Supprimer.
Vous pouvez voir un message d'erreur qui ressemble à Role: arn:aws:iam::... is Invalid or cannot
be assumed

Cela signifie que le rôle requis pour supprimer la pile a été supprimé avant la pile. Pour contourner ce problème, copiez le nom du rôle. Accédez à la console IAM et créez un rôle portant ce nom à l'aide des paramètres indiqués ici, à savoir :
-
Pour Type d'entité de confiance, sélectionnez AWS service.
-
Pour Cas d'utilisation, sous
Use cases for other AWS servicesChoisirCloudFormation.
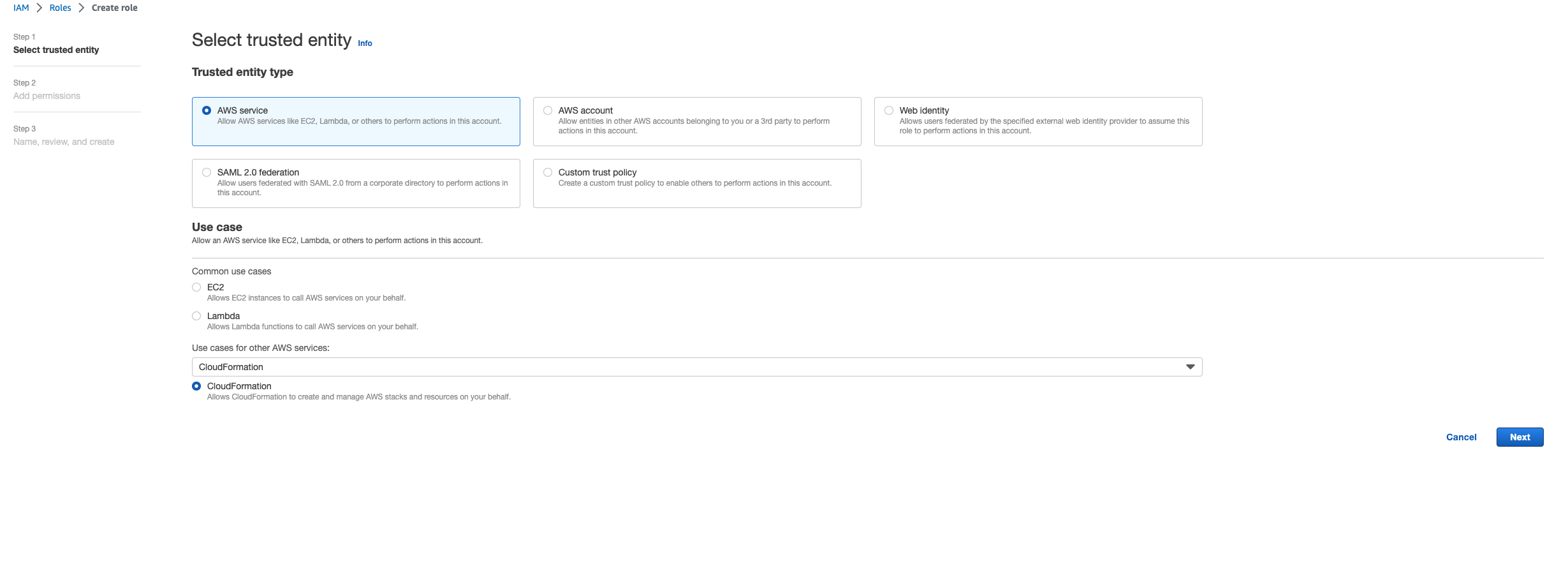
Sélectionnez Suivant. Assurez-vous d'accorder les autorisations aux rôles AWSCloudFormationFullAccess « » et AdministratorAccess « ». Votre page d'évaluation doit ressembler à ceci :
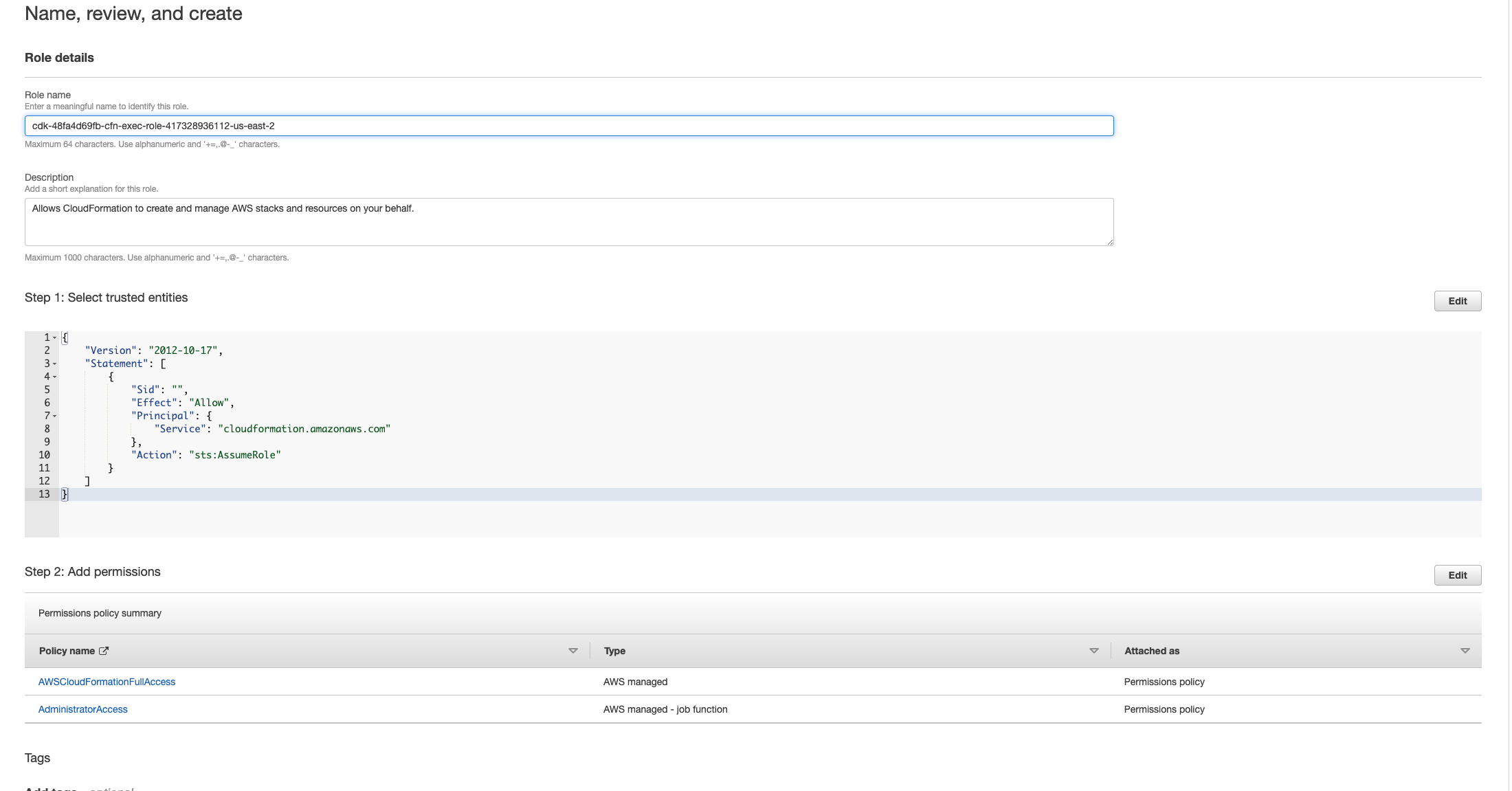
Retournez ensuite sur la CloudFormation console et supprimez la pile. Vous devriez maintenant être en mesure de le supprimer depuis que vous avez créé le rôle. Enfin, accédez à la console IAM et supprimez le rôle que vous avez créé.
........................
Collecte de journaux
Connexion à une EC2 instance depuis la EC2 console
-
Suivez ces instructions pour vous connecter à votre EC2 instance Linux.
-
Suivez ces instructions pour vous connecter à votre EC2 instance Windows. Ouvrez ensuite Windows PowerShell pour exécuter n'importe quelle commande.
Collecte des journaux des hôtes de l'infrastructure
-
Cluster-manager : récupérez les journaux du gestionnaire de cluster aux emplacements suivants et joignez-les au ticket.
-
Tous les journaux du groupe de CloudWatch journaux
<env-name>/cluster-manager. -
Tous les journaux situés dans le
/root/bootstrap/logsrépertoire de l'<env-name>-cluster-managerEC2 instance. Suivez les instructions liées à la section « Connexion à une EC2 instance depuis la EC2 console » au début de cette section pour vous connecter à votre instance.
-
-
Contrôleur VDC : récupérez les journaux du contrôleur VDC aux emplacements suivants et joignez-les au ticket.
-
Tous les journaux du groupe de CloudWatch journaux
<env-name>/vdc-controller. -
Tous les journaux situés dans le
/root/bootstrap/logsrépertoire de l'<env-name>-vdc-controllerEC2 instance. Suivez les instructions liées à la section « Connexion à une EC2 instance depuis la EC2 console » au début de cette section pour vous connecter à votre instance.
-
L'un des moyens d'obtenir facilement les journaux est de suivre les instructions de la Téléchargement de journaux depuis des EC2 instances Linux section. Le nom du module serait le nom de l'instance.
Collecte des journaux VDI
- Identifiez l' EC2 instance Amazon correspondante
-
Si un utilisateur lançait un VDI avec un nom de session
VDI1, le nom correspondant de l'instance sur la EC2 console Amazon serait<env-name>-VDI1-<user name>. - Collectez les journaux VDI Linux
-
Connectez-vous à l' EC2 instance Amazon correspondante depuis la EC2 console Amazon en suivant les instructions indiquées dans la section « Connexion à une EC2 instance depuis la EC2 console » au début de cette section. Accédez à tous les journaux dans les
/var/log/dcv/répertoires/root/bootstrap/logset de l' EC2 instance Amazon VDI.L'un des moyens d'obtenir les journaux serait de les télécharger sur s3, puis de les télécharger à partir de là. Pour cela, vous pouvez suivre ces étapes pour obtenir tous les journaux dans un répertoire, puis les télécharger :
-
Procédez comme suit pour copier les journaux DCV dans le
/root/bootstrap/logsrépertoire :sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
Maintenant, suivez les étapes répertoriées dans la section suivante Téléchargement des journaux VDI pour télécharger les journaux.
-
- Collectez les journaux Windows VDI
-
Connectez-vous à l' EC2 instance Amazon correspondante depuis la EC2 console Amazon en suivant les instructions indiquées dans la section « Connexion à une EC2 instance depuis la EC2 console » au début de cette section. Obtenez tous les journaux dans le
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\répertoire de l' EC2 instance VDI.L'un des moyens d'obtenir les journaux serait de les télécharger sur S3, puis de les télécharger à partir de là. Pour ce faire, suivez les étapes répertoriées dans la section suivante-Téléchargement des journaux VDI.
........................
Téléchargement des journaux VDI
Mettez à jour le rôle IAM de l' EC2 instance VDI pour autoriser l'accès à S3.
Accédez à la EC2 console et sélectionnez votre instance VDI.
Sélectionnez le rôle IAM qu'il utilise.
-
Dans la section Politiques d'autorisation du menu déroulant Ajouter des autorisations, sélectionnez Joindre des politiques, puis choisissez la politique AmazonS3 FullAccess.
Sélectionnez Ajouter des autorisations pour joindre cette politique.
-
Ensuite, suivez les étapes ci-dessous en fonction de votre type de VDI pour télécharger les journaux. Le nom du module serait le nom de l'instance.
-
Enfin, modifiez le rôle pour supprimer la
AmazonS3FullAccesspolitique.
Note
Ils VDIs utilisent tous le même rôle IAM qui est <env-name>-vdc-host-role-<region>
........................
Téléchargement de journaux depuis des EC2 instances Linux
Connectez-vous à l' EC2 instance à partir de laquelle vous souhaitez télécharger les journaux et exécutez les commandes suivantes pour télécharger tous les journaux dans un compartiment s3 :
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
Ensuite, accédez à la console S3, sélectionnez le bucket avec son nom <environment_name>-cluster-<region>-<aws_account_number> et téléchargez le <module_name>_logs.tar.gz fichier précédemment téléchargé.
........................
Téléchargement de journaux à partir d' EC2 instances Windows
Connectez-vous à l' EC2 instance à partir de laquelle vous souhaitez télécharger les journaux et exécutez les commandes suivantes pour télécharger tous les journaux dans un compartiment S3 :
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
Ensuite, accédez à la console S3, sélectionnez le bucket avec son nom <environment_name>-cluster-<region>-<aws_account_number> et téléchargez le <module_name>_logs.zip fichier précédemment téléchargé.
........................
Collecte des journaux ECS pour l' WaitCondition erreur
-
Accédez à la pile déployée et choisissez l'onglet Ressources.
-
Développez Deploy ResearchAndEngineeringStudio→ → Installer → Tâches CreateTaskDef→ CreateContainer→ → LogGroup, puis sélectionnez le groupe de journaux pour ouvrir CloudWatch les journaux.
-
Récupérez le dernier journal de ce groupe de journaux.
........................
Environnement de démonstration
........................
Erreur de connexion à l'environnement de démonstration lors du traitement de la demande d'authentification auprès du fournisseur d'identité
Problème
Si vous essayez de vous connecter et que vous recevez une « erreur inattendue lors du traitement de la demande d'authentification auprès du fournisseur d'identité », vos mots de passe ont peut-être expiré. Il peut s'agir du mot de passe de l'utilisateur sous lequel vous essayez de vous connecter ou de votre compte Active Directory Service.
Mitigation
-
Réinitialisez les mots de passe de l'utilisateur et du compte de service dans la console du service d'annuaire
. -
Mettez à jour les mots de passe des comptes de service dans Secrets Manager
pour qu'ils correspondent au nouveau mot de passe que vous avez saisi ci-dessus : -
pour la pile Keycloak : -... PasswordSecret - RESExternal-... - DirectoryService-... avec description : mot de passe pour Microsoft Active Directory
-
pour RES : res- ServiceAccountPassword -... avec description : mot de passe du compte Active Directory Service
-
-
Accédez à la EC2 console
et mettez fin à l'instance du gestionnaire de clusters. Les règles Auto Scaling déclencheront automatiquement le déploiement d'une nouvelle instance.
........................
