Amazon Redshift ne prendra plus en charge la création de nouveaux UDFs Python à partir du patch 198. Les fonctions Python définies par l’utilisateur existantes continueront de fonctionner normalement jusqu’au 30 juin 2026. Pour plus d’informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Machine learning
Le machine learning d’Amazon Redshift (Amazon Redshift ML) est un service robuste, basé sur le cloud, qui facilite l’utilisation de la technologie de machine learning par les analystes et les scientifiques des données de tous niveaux de compétence. Amazon Redshift ML utilise un modèle pour générer des résultats. Vous pouvez utiliser les modèles des manières suivantes :
Vous pouvez fournir les données que vous souhaitez pour entraîner un modèle et les métadonnées associées aux données en entrée à Amazon Redshift. Amazon Redshift ML crée ensuite des modèles dans Amazon SageMaker AI qui capturent des modèles dans les données d'entrée. En utilisant vos propres données pour le modèle, vous pouvez utiliser Amazon Redshift ML pour identifier les tendances des données, telles que la prévision du taux de désabonnement, la valeur du cycle de vie du client ou la prévision des revenus. Vous pouvez utiliser ces modèles pour générer des prédictions pour de nouvelles données entrées sans encourir de coûts supplémentaires.
Vous pouvez utiliser l’un des modèles de fondation (FM) fournis par Amazon Bedrock, tels que Claude ou Amazon Titan. À l’aide d’Amazon Bedrock, vous pouvez associer la puissance des grands modèles linguistiques (LLM) à vos données d’analyse dans Amazon Redshift en quelques étapes. En utilisant un grand modèle de langage (LLM) externe, vous pouvez utiliser Amazon Redshift pour effectuer le traitement du langage naturel (NLP) sur vos données. Vous pouvez utiliser le traitement du langage naturel pour des applications telles que la génération de texte, l’analyse des sentiments ou la traduction. Pour plus d’informations sur l’utilisation d’Amazon Bedrock avec Amazon Redshift, consultez Intégrations d’Amazon Redshift ML à Amazon Bedrock.
Note
Refus d'utiliser vos données pour améliorer le service
Si vous utilisez des modèles Amazon Bedrock, nous vous encourageons à lire les AWS politiques relatives à la manière dont le service Amazon Bedrock gère vos données. Vous devez déterminer si vous devez utiliser une politique de désinscription pour empêcher le service d’utiliser vos données pour améliorer le modèle ou le service, si Amazon Bedrock implémente une telle fonctionnalité à l’avenir. Pour vous assurer que le service n'utilise pas vos données à de telles fins, utilisez la politique générale de AWS désinscription.
Pour plus d’informations, consultez les ressources suivantes :
Note
Les grands modèles de langage peuvent générer des informations inexactes ou incomplètes. Nous vous recommandons de vérifier les informations produites par les grands modèles de langage pour vous assurer qu’elles sont exactes et complètes.
Comment Amazon Redshift ML fonctionne avec Amazon AI SageMaker
Amazon Redshift fonctionne avec Amazon SageMaker AI Autopilot pour obtenir automatiquement le meilleur modèle et rendre la fonction de prédiction disponible dans Amazon Redshift.
Le schéma suivant illustre le fonctionnement d'Amazon Redshift ML.
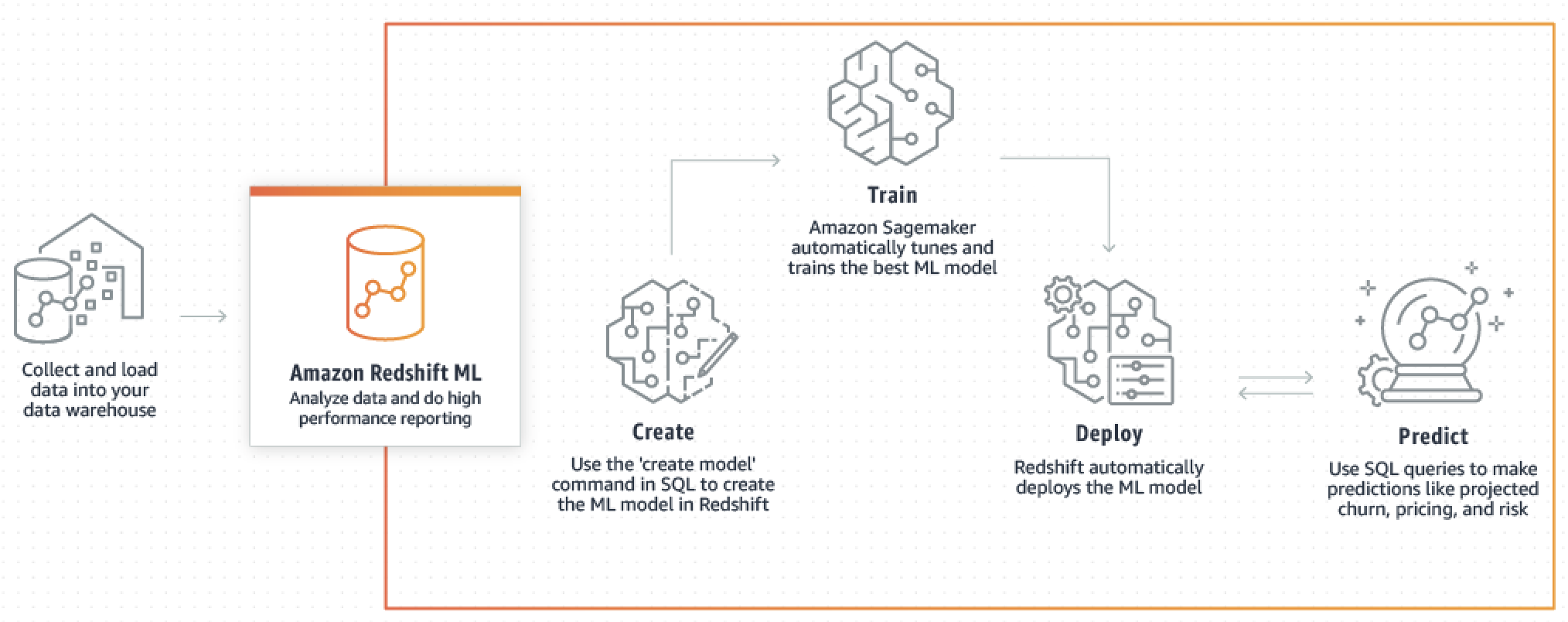
De manière générale, procédez comme suit :
-
Amazon Redshift exporte les données d'entraînement vers Amazon S3.
-
Amazon SageMaker AI Autopilot prétraite les données d'entraînement. Le prétraitement remplit des fonctions importantes, telles que l'imputation des valeurs manquantes. Il reconnaît que certaines colonnes sont catégoriques (comme le code postal), les formate correctement pour l'entraînement, et effectue de nombreuses autres tâches. Choisir les meilleurs préprocesseurs à appliquer à l'ensemble de données d'entraînement est un problème en soi, et Amazon SageMaker AI Autopilot automatise sa solution.
-
Amazon SageMaker AI Autopilot trouve l'algorithme et les hyperparamètres de l'algorithme qui fournissent au modèle les prédictions les plus précises.
-
Amazon Redshift enregistre la fonction de prédiction en tant que fonction SQL dans votre cluster Amazon Redshift.
-
Lorsque vous exécutez des instructions CREATE MODEL, Amazon Redshift utilise Amazon SageMaker AI pour la formation. Par conséquent, il y a un coût associé pour l'entraînement de votre modèle. Il s'agit d'une rubrique distincte pour Amazon SageMaker AI dans votre AWS facture. Vous payez également les frais de stockage de vos données d'entraînement dans Amazon S3. L'inférence qui utilise des modèles créés avec CREATE MODEL pouvant être compilés et exécutés sur votre cluster Redshift ne sera pas facturée. L'utilisation d'Amazon Redshift ML n'entraîne pas de frais supplémentaires pour Amazon Redshift.
Rubriques
