Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Étapes de préparation des données
L'expérience de préparation des données d'Amazon Quick Sight propose onze types d'étapes puissants qui vous permettent de transformer systématiquement vos données. Chaque étape a un objectif spécifique dans le flux de travail de préparation des données.
Les étapes peuvent être configurées via une interface intuitive dans le volet de configuration, avec un retour immédiat visible dans le volet d'aperçu. Les étapes peuvent être combinées de manière séquentielle pour créer des transformations de données sophistiquées sans nécessiter d'expertise SQL.
Chaque étape peut recevoir l'entrée d'une table physique ou la sortie d'une étape précédente. La plupart des étapes n'acceptent qu'une seule entrée, les étapes Ajouter et Joindre étant des exceptions : elles nécessitent exactement deux entrées.
Input
L'étape de saisie lance votre flux de travail de préparation des données dans Quick Sight en vous permettant de sélectionner et d'importer des données provenant de plusieurs sources pour les transformer lors des étapes suivantes.
Options de saisie
-
Ajouter un ensemble de données
Tirez parti des ensembles de données Quick Sight existants comme sources d'entrée, en vous appuyant sur des données déjà préparées et optimisées par votre équipe.
-
Ajouter une source de données
Connectez-vous directement à des bases de données telles qu'Amazon Redshift, Athena, RDS ou à d'autres sources prises en charge en sélectionnant des objets de base de données spécifiques et en fournissant des paramètres de connexion.
-
Ajouter un téléchargement de fichier
Importez des données directement à partir de fichiers locaux dans des formats tels que CSV, TSV, Excel ou JSON.
Configuration
L'étape de saisie ne nécessite aucune configuration. Le volet d'aperçu affiche vos données importées ainsi que les informations sur la source, notamment les détails de connexion, le nom de la table et les métadonnées des colonnes.
Notes d’utilisation
-
Plusieurs étapes de saisie peuvent exister au sein d'un même flux de travail.
-
Vous pouvez ajouter des étapes de saisie à tout moment dans votre flux de travail.
Ajouter des colonnes calculées
L'étape Ajouter des colonnes calculées vous permet de créer de nouvelles colonnes à l'aide d'expressions au niveau des lignes qui effectuent des calculs sur des colonnes existantes. Vous pouvez créer de nouvelles colonnes à l'aide de fonctions et d'opérateurs scalaires (au niveau des lignes) et appliquer des calculs au niveau des lignes qui font référence à des colonnes existantes.
Configuration
Pour configurer l'étape Ajouter des colonnes calculées, dans le volet Configuration :
-
Donnez un nom à votre nouvelle colonne calculée.
-
Enregistrez votre calcul.
-
Prévisualisez les résultats de l'expression.
-
Ajoutez d'autres colonnes calculées selon vos besoins.
Notes d’utilisation
-
Seuls les calculs scalaires (au niveau des lignes) sont pris en charge dans cette étape.
-
Dans SPICE, les colonnes calculées sont matérialisées et fonctionnent comme des colonnes standard dans les étapes suivantes.
Modifier le type de données
Quick Sight simplifie la gestion des types de données en prenant en charge quatre types de données abstraits : date decimalinteger,, etstring. Ces types abstraits éliminent la complexité en mappant automatiquement les différents types de données sources à leurs équivalents Quick Sight. Par exemple,tinyint, smallintinteger, et bigint sont tous mappés versinteger, tandis que, datedatetime, et timestamp sont mappés vers. date
Cette abstraction signifie qu'il vous suffit de comprendre les quatre types de données de Quick Sight, car Quick Sight gère automatiquement toutes les conversions de types de données sous-jacents et les calculs lorsque vous interagissez avec différentes sources de données.
Configuration
Pour configurer l'étape Modifier le type de données, dans le volet Configuration :
-
Sélectionnez une colonne à convertir.
-
Choisissez le type de données cible (
stringinteger,decimal, oudate). -
Pour les conversions de dates, spécifiez les paramètres de format et prévisualisez les résultats en fonction des formats d'entrée. Consultez les formats de date pris en charge dans Quick Sight.
-
Ajoutez des colonnes supplémentaires à convertir selon vos besoins.
Notes d’utilisation
-
Convertissez les types de données de plusieurs colonnes en une seule étape pour plus d'efficacité.
-
Lorsque vous utilisez SPICE, tous les changements de type de données sont matérialisés dans les données importées.
Renommer les colonnes
L'étape Renommer les colonnes vous permet de modifier les noms des colonnes afin qu'ils soient plus descriptifs, faciles à utiliser et conformes aux conventions de dénomination de votre organisation.
Configuration
Pour configurer l'étape Renommer les colonnes, dans le volet Configuration :
-
Sélectionnez une colonne à nommer.
-
Entrez un nouveau nom pour la colonne sélectionnée.
-
Ajoutez d'autres colonnes à renommer selon vos besoins.
Notes d’utilisation
-
Tous les noms de colonnes doivent être uniques dans votre ensemble de données.
Sélectionnez les colonnes
L'étape Sélectionner les colonnes vous permet de rationaliser votre jeu de données en incluant, en excluant et en réorganisant les colonnes. Cela permet d'optimiser votre structure de données en supprimant les colonnes inutiles et en organisant les colonnes restantes dans un ordre logique à des fins d'analyse.
Configuration
Pour configurer l'étape Sélectionner les colonnes, dans le volet Configuration :
-
Choisissez des colonnes spécifiques à inclure dans votre sortie.
-
Sélectionnez les colonnes dans l'ordre de votre choix pour établir la séquence.
-
Utilisez Sélectionner tout pour inclure les colonnes restantes dans leur ordre d'origine.
-
Excluez les colonnes indésirables en les laissant non sélectionnées.
Caractéristiques principales
-
Les colonnes de sortie apparaissent dans l'ordre de sélection.
-
Tout sélectionner préserve la séquence de colonnes d'origine.
Notes d’utilisation
-
Les colonnes non sélectionnées sont supprimées des étapes suivantes.
-
Optimisez la taille du jeu de données en supprimant les colonnes inutiles.
Ajout
L'étape Ajouter combine verticalement deux tables, comme dans le cas d'une opération SQL UNION ALL. Quick Sight fait automatiquement correspondre les colonnes par nom plutôt que par séquence, ce qui permet une consolidation efficace des données, même lorsque les tables ont des ordres de colonnes différents ou un nombre variable de colonnes.
Configuration
Pour configurer l'étape Ajouter, dans le volet Configuration :
-
Sélectionnez deux tables d'entrée à ajouter.
-
Passez en revue la séquence des colonnes de sortie.
-
Examinez les colonnes présentes dans les deux tables par rapport aux colonnes présentes dans les tables individuelles.
Fonctions principales
-
Fait correspondre les colonnes par nom plutôt que par séquence.
-
Conserve toutes les lignes des deux tables, y compris les doublons.
-
Supporte les tables avec différents nombres de colonnes.
-
Suit la séquence de colonnes du tableau 1 pour les colonnes correspondantes, puis ajoute des colonnes uniques à partir du tableau 2.
-
Affiche des indicateurs de source clairs pour toutes les colonnes
Notes d’utilisation
-
Utilisez d'abord l'étape Renommer lorsque vous ajoutez des colonnes portant des noms différents.
-
Chaque étape d'ajout combine exactement deux tables ; utilisez des étapes d'ajout supplémentaires pour d'autres tables.
Joindre
L'étape Joindre combine horizontalement les données de deux tables en fonction des valeurs correspondantes dans des colonnes spécifiées. Quick Sight prend en charge les types de jointure externe gauche, externe droite, externe complète et interne, offrant ainsi des options flexibles pour vos besoins analytiques. Cette étape inclut la résolution intelligente des conflits de colonnes qui gère automatiquement les noms de colonnes dupliqués. Bien que les jointures automatiques ne soient pas disponibles en tant que type de jointure spécifique, vous pouvez obtenir des résultats similaires en utilisant la divergence des flux de travail.
Configuration
Pour configurer l'étape Joindre, dans le volet Configuration :
-
Sélectionnez deux tables d'entrée à joindre.
-
Choisissez votre type de jointure (extérieur gauche, extérieur droit, extérieur complet ou intérieur).
-
Spécifiez les clés de jointure de chaque table.
-
Vérifiez les conflits de noms de colonnes résolus automatiquement.
Fonctions principales
-
Prend en charge plusieurs types de jointure pour différents besoins analytiques.
-
Résout automatiquement les noms de colonnes dupliqués.
-
Accepte les colonnes calculées comme clés de jointure.
Notes d’utilisation
-
Les clés de jointure doivent avoir des types de données compatibles ; utilisez l'étape Modifier le type de données si nécessaire.
-
Chaque étape de jointure combine exactement deux tables ; utilisez des étapes de jointure supplémentaires pour plus de tables.
-
Créez une étape de renommage après la jointure pour personnaliser les en-têtes de colonne résolus automatiquement.
Regrouper
L'étape Agrégation vous permet de synthétiser les données en groupant les colonnes et en appliquant des opérations d'agrégation. Cette puissante transformation condense les données détaillées en résumés significatifs basés sur les dimensions que vous avez spécifiées. Quick Sight simplifie les opérations SQL complexes grâce à une interface intuitive, offrant des fonctions d'agrégation complètes, notamment des opérations de chaîne avancées telles que ListAgg etListAgg distinct.
Configuration
Pour configurer l'étape d'agrégation, dans le volet Configuration :
-
Sélectionnez les colonnes à regrouper.
-
Choisissez des fonctions d'agrégation pour les colonnes de mesure.
-
Personnalisez les noms des colonnes de sortie.
-
Pour
ListAggetListAgg distinct:-
Sélectionnez la colonne à agréger.
-
Choisissez un séparateur (virgule, tiret, point-virgule ou ligne verticale).
-
-
Prévisualisez les données résumées.
Fonctions prises en charge par type de données
| Type de données | Fonctions prises en charge |
|---|---|
|
Numérique |
|
|
Date |
|
|
String |
|
Fonctions principales
-
Applique différentes fonctions d'agrégation aux colonnes au cours de la même étape.
-
Grouper par sans fonctions d'agrégation agit comme SQL SELECT DISTINCT.
-
ListAggconcatène toutes les valeurs ;ListAgg distinctinclut uniquement les valeurs uniques. -
ListAggles fonctions conservent l'ordre de tri croissant par défaut.
Notes d’utilisation
-
L'agrégation réduit considérablement le nombre de lignes dans votre ensemble de données.
-
ListAggetListAgg distinctsoutiennentdateles valeurs, mais nondatetime. -
Utilisez des séparateurs pour personnaliser le résultat de la concaténation de chaînes.
Filtre
L'étape Filtrer vous permet d'affiner votre jeu de données en n'incluant que les lignes répondant à des critères spécifiques. Vous pouvez appliquer plusieurs conditions de filtre en une seule étape, en les combinant de AND manière logique afin de concentrer votre analyse sur les données pertinentes.
Configuration
Pour configurer l'étape Filtrer, dans le volet Configuration :
-
Sélectionnez une colonne à filtrer.
-
Choisissez un opérateur de comparaison.
-
Spécifiez les valeurs de filtre en fonction du type de données de la colonne.
-
Ajoutez des conditions de filtre supplémentaires sur différentes colonnes si nécessaire.
Note
-
Filtres de chaîne avec « est dedans » ou « n'est pas dedans » : entrez plusieurs valeurs (une par ligne).
-
Filtres numériques et de date : entrez des valeurs uniques (sauf « entre » qui nécessite deux valeurs).
Opérateurs pris en charge par type de données
| Type de données | Opérateurs pris en charge |
|---|---|
|
Nombre entier et décimal |
Est égal, n'est pas égal Supérieur à, Inférieur à Est supérieur ou égal à, Est inférieur ou égal à Est comprise entre |
|
Date |
Avant, après Est comprise entre Est après ou égal à, Est antérieur ou égal à |
|
String |
Est égal, n'est pas égal Commence par, se termine par Contient, Ne contient pas Est dedans, n'est pas dedans |
Notes d’utilisation
-
Appliquez plusieurs conditions de filtre en une seule étape.
-
Mélangez les conditions entre différents types de données.
-
Prévisualisez les résultats filtrés en temps réel.
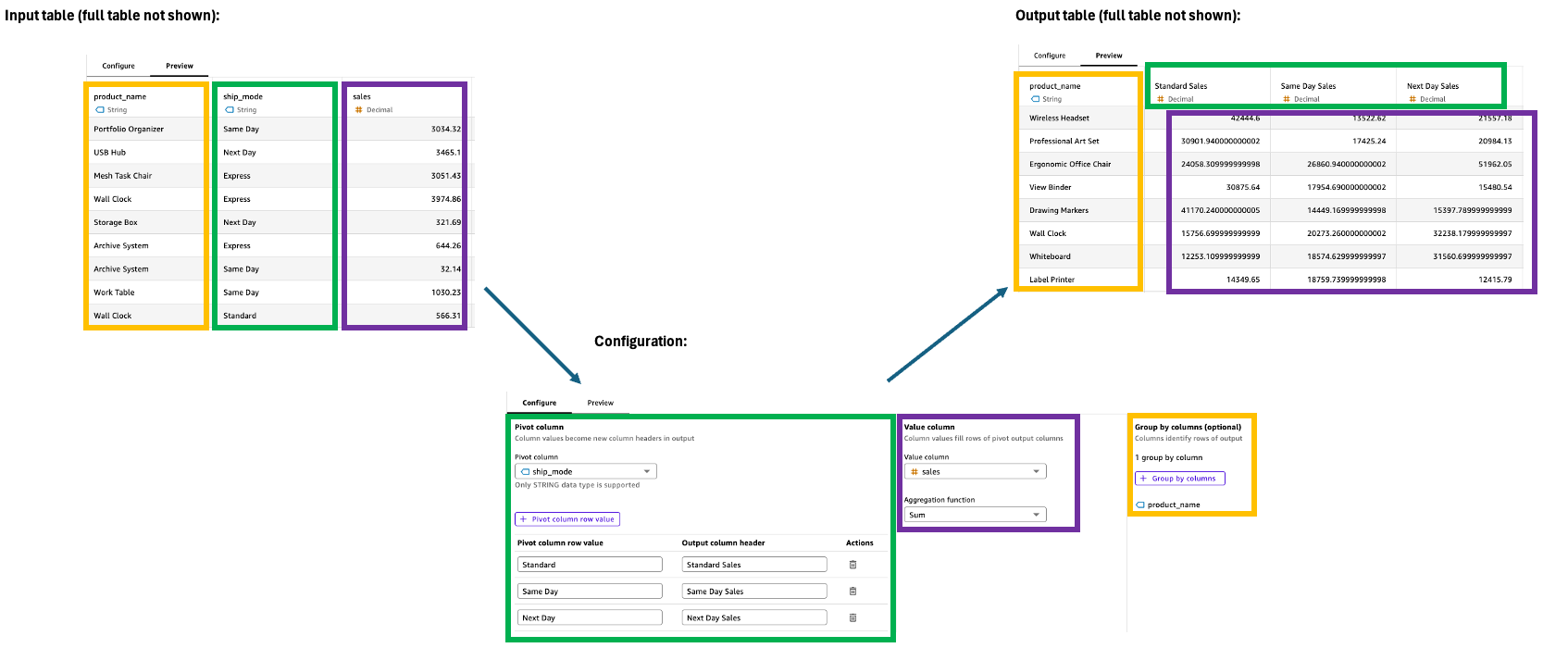
Pivot
L'étape Pivot transforme les valeurs des lignes en colonnes uniques, convertissant les données d'un format long en un format large pour faciliter la comparaison et l'analyse. Cette transformation nécessite des spécifications pour le filtrage, l'agrégation et le regroupement des valeurs afin de gérer efficacement les colonnes de sortie.
Configuration
Pour configurer l'étape Pivot, utilisez ce qui suit dans le volet Configuration :
-
Colonne pivotante : sélectionnez la colonne dont les valeurs deviendront des en-têtes de colonne (par exemple, Catégorie).
-
Valeur de la ligne de colonne pivotante : filtrez les valeurs spécifiques à inclure (par exemple, technologie, fournitures de bureau).
-
En-tête de colonne de sortie : personnalisez les nouveaux en-têtes de colonne (par défaut, les valeurs des colonnes pivotent).
-
Colonne de valeurs : sélectionnez la colonne à agréger (par exemple, Ventes).
-
Fonction d'agrégation : choisissez la méthode d'agrégation (par exemple, Sum).
-
Regrouper par : Spécifiez les colonnes d'organisation (par exemple, Segment).
Opérateurs pris en charge par type de données
| Type de données | Opérateurs pris en charge |
|---|---|
|
Nombre entier et décimal |
|
|
Date |
|
|
String |
|
Notes d’utilisation
-
Chaque colonne pivotée contient les valeurs agrégées de la colonne de valeurs.
-
Personnalisez les en-têtes de colonne pour plus de clarté.
-
Prévisualisez les résultats de transformation en temps réel.
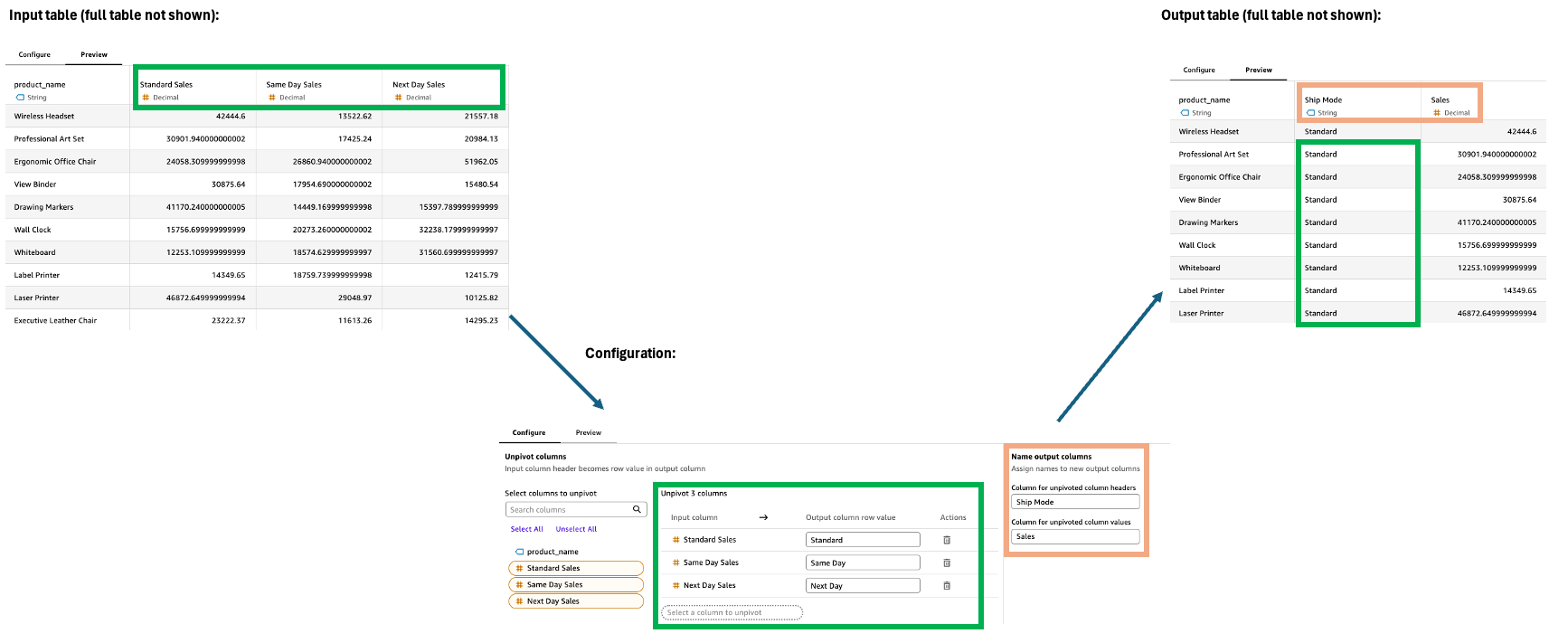
Dépivoter
L'étape Unpivot transforme les colonnes en lignes, convertissant les données larges en un format plus long et plus étroit. Cette transformation permet d'organiser les données réparties sur plusieurs colonnes dans un format plus structuré pour faciliter l'analyse et la visualisation.
Configuration
Pour configurer l'étape Unpivot, dans le volet Configuration :
-
Sélectionnez les colonnes à dépivoter en lignes.
-
Définissez les valeurs des lignes des colonnes de sortie. Le nom de colonne par défaut est le nom d'origine. Certains exemples incluent la technologie, les fournitures de bureau et le mobilier.
-
Nommez les deux nouvelles colonnes de sorties.
-
En-tête de colonne non pivotant : nom des anciens noms de colonne (par exemple, Catégorie)
-
Valeurs de colonne non pivotées : nom des valeurs non pivotées (par exemple, Sales)
-
Fonctions principales
-
Conserve toutes les colonnes non pivotantes de la sortie.
-
Crée automatiquement deux nouvelles colonnes : une pour les anciens noms de colonne et une pour les valeurs correspondantes.
-
Transforme des données étendues en format long.
Notes d’utilisation
-
Toutes les colonnes non pivotantes doivent avoir des types de données compatibles.
-
Le nombre de lignes augmente généralement après le dépivotement.
-
Prévisualisez les modifications en temps réel avant de les appliquer.
