Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Composants d'architecture d'un entrepôt de données Amazon Redshift
Nous vous recommandons d'avoir une connaissance de base des principaux composants de l'architecture d'un entrepôt de données Amazon Redshift. Ces connaissances peuvent vous aider à mieux comprendre comment concevoir vos requêtes et vos tables pour des performances optimales.
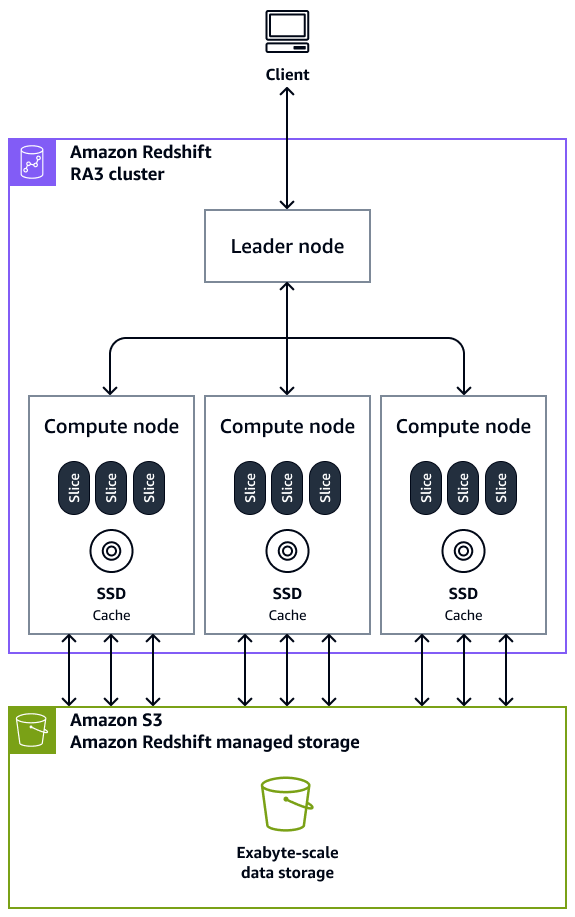
Un entrepôt de données dans Amazon Redshift comprend les principaux composants de l'architecture suivants :
-
Clusters : un cluster, composé d'un ou de plusieurs nœuds de calcul, est le composant d'infrastructure principal d'un entrepôt de données Amazon Redshift. Les nœuds de calcul sont transparents pour les applications externes, mais votre application cliente n'interagit directement qu'avec le nœud principal. Un cluster typique possède au moins deux nœuds de calcul. Les nœuds de calcul sont coordonnés par le biais du nœud principal.
-
Nœud principal : un nœud principal gère les communications pour les programmes clients et tous les nœuds de calcul. Un nœud principal prépare également les plans d'exécution d'une requête chaque fois qu'une requête est soumise à un cluster. Lorsque les plans sont prêts, le nœud principal compile le code, le distribue aux nœuds de calcul, puis affecte des tranches de données à chaque nœud de calcul pour traiter les résultats de la requête.
-
Nœud de calcul : un nœud de calcul exécute une requête. Le nœud principal compile le code pour les éléments individuels du plan afin d'exécuter la requête et attribue le code aux nœuds de calcul individuels. Les nœuds de calcul exécutent le code compilé et renvoient les résultats intermédiaires au nœud principal pour l’agrégation finale. Chaque nœud de calcul possède son propre processeur, sa propre mémoire et son propre stockage sur disque. Lorsque votre charge de travail augmente, vous pouvez augmenter la capacité de calcul et la capacité de stockage d'un cluster en augmentant le nombre de nœuds, en mettant à niveau le type de nœud, ou les deux.
-
Tranche de nœud : un nœud de calcul est partitionné en unités appelées tranches. Chaque tranche d'un nœud de calcul reçoit une partie de la mémoire et de l'espace disque du nœud où elle traite une partie de la charge de travail assignée au nœud. Les tranches travaillent alors en parallèle pour terminer l’opération. Les données sont réparties entre les tranches en fonction du style de distribution et de la clé de distribution d'une table donnée. Une distribution uniforme des données permet à Amazon Redshift d'attribuer de manière uniforme les charges de travail aux tranches et de maximiser les avantages du traitement parallèle. Le nombre de tranches par nœud de calcul est déterminé en fonction du type de nœud. Pour plus d'informations, consultez la section Clusters et nœuds dans Amazon Redshift dans la documentation Amazon Redshift.
-
Traitement massivement parallèle (MPP) : Amazon Redshift utilise l'architecture MPP pour traiter rapidement les données, même les requêtes complexes et de grandes quantités de données. Plusieurs nœuds de calcul exécutent le même code de requête sur des portions de données afin d'optimiser le traitement parallèle.
-
Application client — Amazon Redshift s'intègre à divers outils de chargement, d'extraction, de transformation et de chargement (ETL), de reporting de business intelligence (BI), d'exploration de données et d'analyse. Toutes les applications clientes communiquent avec le cluster uniquement via le nœud principal.
Le schéma suivant montre comment les composants de l'architecture d'un entrepôt de données Amazon Redshift fonctionnent ensemble pour accélérer les requêtes.
Le cycle de vie des requêtes comporte sept étapes :
-
Réception et analyse des requêtes :
-
Le nœud principal reçoit la requête et analyse le SQL.
-
L'analyseur produit un arbre de requête initial, qui représente la structure logique de la requête d'origine.
-
Amazon Redshift introduit cet arbre de requêtes dans l'optimiseur de requêtes.
-
-
Optimisation des requêtes :
-
L'optimiseur évalue la requête et, si nécessaire, la réécrit pour optimiser l'efficacité.
-
Ce processus d'optimisation peut impliquer la création de plusieurs requêtes connexes pour en remplacer une seule.
-
-
Génération du plan de requêtes :
-
L'optimiseur génère un plan de requête (ou plusieurs plans, si nécessaire) à exécuter.
-
Le plan de requête spécifie les options d'exécution, telles que les types de jointure, l'ordre de jointure, les méthodes d'agrégation et les exigences de distribution des données.
-
-
Traduction du moteur d'exécution :
-
Le moteur d'exécution traduit le plan de requête en étapes, segments et flux distincts :
-
Étape — Représente une opération individuelle requise lors de l'exécution de la requête. Les étapes peuvent être combinées pour permettre aux nœuds de calcul d'effectuer des requêtes, des jointures ou d'autres opérations de base de données.
-
Segment : combine plusieurs étapes qu'un seul processus peut exécuter. Il s'agit de la plus petite unité de compilation exécutable par une tranche de nœud de calcul. (Une tranche est l'unité de traitement parallèle dans Amazon Redshift.)
-
Stream : ensemble de segments répartis sur les tranches de nœuds de calcul disponibles.
-
-
Le moteur d'exécution génère du code compilé en fonction de ces étapes, segments et flux. Le code compilé s'exécute plus rapidement que le code interprété et consomme moins de capacité de calcul.
-
Le nœud principal diffuse le code compilé aux nœuds de calcul.
-
-
Exécution parallèle :
-
Cette étape a lieu une fois pour chaque flux.
-
Les tranches de nœuds de calcul exécutent des segments de requête en parallèle.
-
Au cours de ce processus, Amazon Redshift optimise les communications réseau, l'utilisation de la mémoire et la gestion des disques afin de transmettre les résultats intermédiaires d'une étape du plan de requêtes à l'autre.
-
Cette optimisation contribue à accélérer l'exécution des requêtes.
-
-
Traitement des flux :
-
Cette étape a lieu une fois pour chaque flux.
-
Le moteur crée des segments exécutables pour chaque flux, pour un traitement parallèle efficace.
-
-
Tri final et agrégation :
-
Le nœud principal prend en charge tout tri ou agrégation final requis par la requête.
-
Une fois terminé, le nœud leader renvoie les résultats au client.
-
Pour plus d'informations sur les composants de l'architecture, consultez la section Architecture du système d'entrepôt de données dans la documentation Amazon Redshift.
