Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Visualisez les résultats AI/ML du modèle à l'aide de Flask et AWS Elastic Beanstalk
Chris Caudill et Durga Sury, Amazon Web Services
Résumé
La visualisation des résultats des services d'intelligence artificielle et d'apprentissage automatique (AI/ML) nécessite souvent des appels d'API complexes qui doivent être personnalisés par vos développeurs et ingénieurs. Cela peut s'avérer un inconvénient si vos analystes souhaitent explorer rapidement un nouveau jeu de données.
Vous pouvez améliorer l'accessibilité de vos services et proposer une forme d'analyse de données plus interactive en utilisant une interface utilisateur (UI) Web qui permet aux utilisateurs de télécharger leurs propres données et de visualiser les résultats du modèle dans un tableau de bord.
Ce modèle utilise Flask
Conditions préalables et limitations
Conditions préalables
Un actif Compte AWS.
AWS Command Line Interface (AWS CLI), installé et configuré sur votre machine locale. Pour plus d'informations à ce sujet, consultez la section Principes de base de la configuration dans la AWS CLI documentation. Vous pouvez également utiliser un environnement de développement AWS Cloud9 intégré (IDE) ; pour plus d'informations à ce sujet, consultez le didacticiel Python AWS Cloud9 et la prévisualisation des applications en cours d'exécution dans l' AWS Cloud9 IDE dans la AWS Cloud9 documentation.
Remarque : n' AWS Cloud9 est plus disponible pour les nouveaux clients. Les clients existants de AWS Cloud9 peuvent continuer à utiliser le service normalement. En savoir plus
Compréhension du framework d'applications Web de Flask. Pour plus d'informations sur Flask, consultez le Quickstart
dans la documentation de Flask. Python version 3.6 ou ultérieure, installé et configuré. Vous pouvez installer Python en suivant les instructions de la section Configuration de votre environnement de développement Python dans la AWS Elastic Beanstalk documentation.
Interface de ligne de commande Elastic Beanstalk (EB CLI), installée et configurée. Pour plus d'informations à ce sujet, consultez Installer l'interface de ligne de commande EB et configurer l'interface de ligne de commande EB dans la documentation d'Elastic Beanstalk.
Limites
L'application Flask de ce modèle est conçue pour fonctionner avec des fichiers .csv qui utilisent une seule colonne de texte et sont limités à 200 lignes. Le code de l'application peut être adapté pour gérer d'autres types de fichiers et volumes de données.
L'application ne prend pas en compte la conservation des données et continue d'agréger les fichiers utilisateur téléchargés jusqu'à ce qu'ils soient supprimés manuellement. Vous pouvez intégrer l'application à Amazon Simple Storage Service (Amazon S3) pour le stockage d'objets persistants ou utiliser une base de données telle qu'Amazon DynamoDB pour le stockage clé-valeur sans serveur.
L'application ne prend en compte que les documents en anglais. Cependant, vous pouvez utiliser Amazon Comprehend pour détecter la langue principale d'un document. Pour plus d'informations sur les langues prises en charge pour chaque action, consultez la référence des API dans la documentation Amazon Comprehend.
Architecture
Architecture d'application Flask
Flask est un framework léger pour développer des applications Web en Python. Il est conçu pour combiner le puissant traitement des données de Python avec une interface utilisateur Web riche. L'application Flask du modèle vous montre comment créer une application Web qui permet aux utilisateurs de télécharger des données, d'envoyer les données à Amazon Comprehend pour inférence, puis de visualiser les résultats. La structure de l'application est la suivante :
static— Contient tous les fichiers statiques compatibles avec l'interface utilisateur Web (par exemple JavaScript, le CSS et les images)templates— Contient toutes les pages HTML de l'applicationuserData— Stocke les données utilisateur téléchargéesapplication.py— Le fichier d'application Flaskcomprehend_helper.py— Fonctions permettant de passer des appels d'API à Amazon Comprehendconfig.py— Le fichier de configuration de l'applicationrequirements.txt— Les dépendances Python requises par l'application
Le application.py script contient les fonctionnalités de base de l'application Web, qui se composent de quatre routes Flask. Le schéma suivant montre ces itinéraires Flask.

/est la racine de l'application et dirige les utilisateurs vers laupload.htmlpage (stockée dans letemplatesrépertoire)./saveFileest une route qui est invoquée après qu'un utilisateur télécharge un fichier. Cette route reçoit unePOSTdemande via un formulaire HTML, qui contient le fichier téléchargé par l'utilisateur. Le fichier est enregistré dans leuserDatarépertoire et l'itinéraire redirige les utilisateurs vers l'/dashboarditinéraire./dashboardrenvoie les utilisateurs vers ladashboard.htmlpage. Dans le code HTML de cette page, il exécute le JavaScript codestatic/js/core.jsqui lit les données de l'/dataitinéraire, puis crée des visualisations pour la page./dataest une API JSON qui présente les données à visualiser dans le tableau de bord. Cet itinéraire lit les données fournies par l'utilisateur et utilise les fonctions inclusescomprehend_helper.pypour envoyer les données utilisateur à Amazon Comprehend à des fins d'analyse des sentiments et de reconnaissance d'entités nommées (NER). La réponse Amazon Comprehend est formatée et renvoyée sous forme d'objet JSON.
Architecture de déploiement
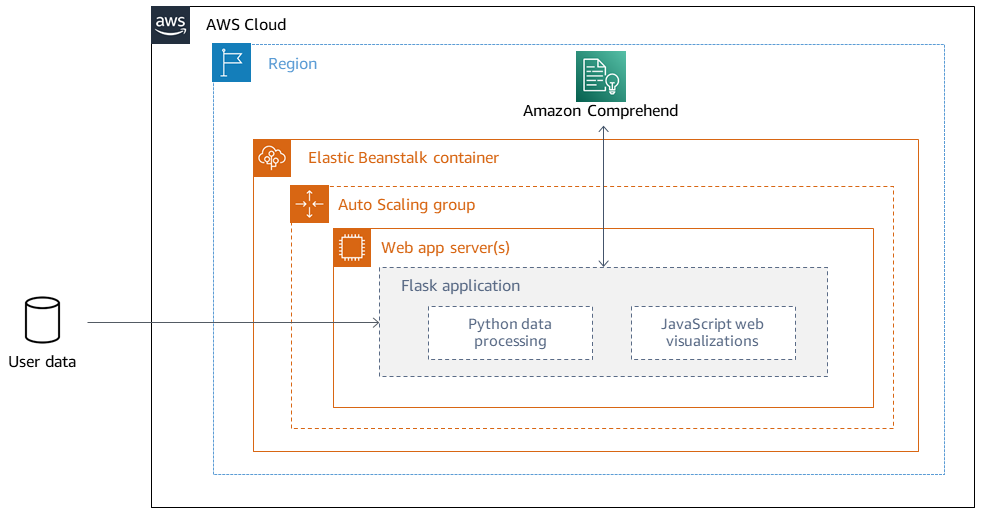
Considérations relatives à la conception
Pour plus d'informations sur les considérations relatives à la conception des applications déployées à l'aide d'Elastic Beanstalk AWS Cloud sur le, consultez la documentation. AWS Elastic Beanstalk
Pile technologique
Amazon Comprehend
Elastic Beanstalk
Flask
Automatisation et mise à l'échelle
Les déploiements d'Elastic Beanstalk sont automatiquement configurés avec des équilibreurs de charge et des groupes de dimensionnement automatique. Pour plus d'options de configuration, consultez la section Configuration des environnements Elastic Beanstalk dans la documentation Elastic Beanstalk.
Outils
AWS Command Line Interface (AWS CLI) est un outil unifié qui fournit une interface cohérente pour interagir avec toutes les parties d'AWS.
Amazon Comprehend utilise le traitement du langage naturel (NLP) pour extraire des informations sur le contenu des documents sans nécessiter de prétraitement spécial.
AWS Elastic Beanstalkvous permet de déployer et de gérer rapidement des applications dans le AWS Cloud sans avoir à vous renseigner sur l'infrastructure qui exécute ces applications.
Elastic Beanstalk CLI (EB CLI) est une AWS Elastic Beanstalk interface de ligne de commande qui fournit des commandes interactives pour simplifier la création, la mise à jour et la surveillance d'environnements à partir d'un référentiel local.
Le framework Flask
effectue le traitement des données et les appels d'API à l'aide de Python et propose une visualisation Web interactive avec Plotly.
Référentiel de code
Le code de ce modèle est disponible dans le AWS Elastic Beanstalk référentiel GitHub Visualize AI/ML model results using Flask
Épopées
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Clonez le GitHub dépôt. | Extrayez le code de l'application à partir des résultats du AI/ML modèle GitHub Visualize à l'aide de Flask et
NoteAssurez-vous de configurer vos clés SSH avec GitHub. | Developer |
Installez les modules Python. | Une fois le dépôt cloné, un nouveau
| Développeur Python |
Testez l'application localement. | Démarrez le serveur Flask en exécutant la commande suivante :
Cela renvoie des informations sur le serveur en cours d'exécution. Vous devriez pouvoir accéder à l'application en ouvrant un navigateur et en vous rendant sur http://localhost:5000 NoteSi vous exécutez l'application dans un AWS Cloud9 IDE, vous devez remplacer la
Vous devez annuler cette modification avant le déploiement. | Développeur Python |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Lancez l'application Elastic Beanstalk. | Pour lancer votre projet en tant qu'application Elastic Beanstalk, exécutez la commande suivante depuis le répertoire racine de votre application :
Important
Exécutez la | Architecte, développeur |
Déployez l'environnement Elastic Beanstalk. | Exécutez la commande suivante depuis le répertoire racine de l'application :
Note
| Architecte, développeur |
Autorisez votre déploiement à utiliser Amazon Comprehend. | Bien que votre application soit déployée avec succès, vous devez également fournir à votre déploiement un accès à Amazon Comprehend. Attachez la
Important
| Développeur, architecte de sécurité |
Accédez à votre application déployée. | Une fois votre application déployée avec succès, vous pouvez la visiter en exécutant la Vous pouvez également exécuter la | Architecte, développeur |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Autorisez Elastic Beanstalk à accéder au nouveau modèle. | Assurez-vous qu'Elastic Beanstalk dispose des autorisations d'accès requises pour votre nouveau modèle de point de terminaison. Par exemple, si vous utilisez un point de terminaison Amazon SageMaker AI, votre déploiement doit être autorisé à appeler le point de terminaison. Pour plus d'informations à ce sujet, consultez InvokeEndpointla documentation Amazon SageMaker AI. | Développeur, architecte de sécurité |
Envoyez les données utilisateur vers un nouveau modèle. | Pour modifier le modèle de machine learning sous-jacent dans cette application, vous devez modifier les fichiers suivants :
| Scientifique des données |
Mettez à jour les visualisations du tableau de bord. | Généralement, l'incorporation d'un nouveau modèle de machine learning signifie que les visualisations doivent être mises à jour pour refléter les nouveaux résultats. Ces modifications sont apportées dans les fichiers suivants :
| Développeur Web |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Mettez à jour le fichier d'exigences de votre application. | Avant d'envoyer des modifications à Elastic Beanstalk,
| Développeur Python |
Redéployez l'environnement Elastic Beanstalk. | Pour vous assurer que les modifications apportées à votre application sont reflétées dans votre déploiement d'Elastic Beanstalk, accédez au répertoire racine de votre application et exécutez la commande suivante :
Cela envoie la version la plus récente du code de l'application à votre déploiement Elastic Beanstalk existant. | Administrateur système, architecte |
Résolution des problèmes
| Problème | Solution |
|---|---|
| Si cette erreur se produit lors de l'exécution |
| Cette erreur se produit dans les journaux de déploiement car Elastic Beanstalk s'attend à ce que le code Flask soit nommé.
Assurez-vous de remplacer par le nom Vous pouvez également utiliser Gunicorn et un Procfile. Pour plus d'informations sur cette approche, consultez la section Configuration du serveur WSGI avec un Procfile dans la AWS Elastic Beanstalk documentation. |
| Elastic Beanstalk s'attend à ce que la variable représentant votre application Flask soit nommée.
|
| Utilisez l'interface de ligne de commande EB pour spécifier la paire de clés à utiliser ou pour créer une paire de clés pour les instances Amazon EC2 de votre déploiement. Pour résoudre l'erreur, lancez
Répondez par |
J'ai mis à jour mon code et je l'ai redéployé, mais mon déploiement ne reflète pas mes modifications. | Si vous utilisez un dépôt Git pour votre déploiement, assurez-vous d'ajouter et de valider vos modifications avant de redéployer. |
Vous prévisualisez l'application Flask à partir d'un AWS Cloud9 IDE et vous rencontrez des erreurs. | Pour plus d'informations à ce sujet, consultez la section Prévisualisation des applications en cours d'exécution dans l' AWS Cloud9 IDE dans la AWS Cloud9 documentation. |
Ressources connexes
Informations supplémentaires
Traitement du langage naturel à l'aide d'Amazon Comprehend
En choisissant d'utiliser Amazon Comprehend, vous pouvez détecter des entités personnalisées dans des documents texte individuels en exécutant une analyse en temps réel ou des tâches par lots asynchrones. Amazon Comprehend vous permet également de former des modèles personnalisés de reconnaissance d'entités et de classification de texte qui peuvent être utilisés en temps réel en créant un point de terminaison.
Ce modèle utilise des tâches par lots asynchrones pour détecter les sentiments et les entités d'un fichier d'entrée contenant plusieurs documents. L'exemple d'application fourni par ce modèle est conçu pour que les utilisateurs puissent télécharger un fichier .csv contenant une seule colonne avec un document texte par ligne. Le comprehend_helper.py fichier contenu dans les résultats du AI/ML modèle GitHub Visualize à l'aide de Flask et
BatchDetectEntities
Amazon Comprehend inspecte le texte d'un lot de documents à la recherche d'entités nommées et renvoie l'entité détectée, l'emplacement, le type d'entité, ainsi qu'un score indiquant le niveau de confiance d'Amazon Comprehend. Un maximum de 25 documents peuvent être envoyés en un seul appel d'API, chaque document ayant une taille inférieure à 5 000 octets. Vous pouvez filtrer les résultats pour n'afficher que certaines entités en fonction du cas d'utilisation. Par exemple, vous pouvez ignorer le type d'‘quantity’entité et définir un score de seuil pour l'entité détectée (par exemple, 0,75). Nous vous recommandons d'étudier les résultats correspondant à votre cas d'utilisation spécifique avant de choisir une valeur de seuil. Pour plus d'informations à ce sujet, consultez BatchDetectEntitiesla documentation Amazon Comprehend.
BatchDetectSentiment
Amazon Comprehend inspecte un lot de documents entrants et renvoie le sentiment dominant pour chaque document (POSITIVE, NEUTRALMIXED, ou). NEGATIVE Un maximum de 25 documents peuvent être envoyés en un seul appel d'API, chaque document ayant une taille inférieure à 5 000 octets. L'analyse du sentiment est simple et vous choisissez le sentiment ayant le score le plus élevé à afficher dans les résultats finaux. Pour plus d'informations à ce sujet, consultez BatchDetectSentimentla documentation Amazon Comprehend.
Gestion de la configuration des flasques
Les serveurs Flask utilisent une série de variables de configuration
Dans ce modèle, la configuration est définie config.py et héritée dansapplication.py.
config.pycontient les variables de configuration définies au démarrage de l'application. Dans cette application, uneDEBUGvariable est définie pour indiquer à l'application d'exécuter le serveur en mode débogage. Note
Le mode de débogage ne doit pas être utilisé lors de l'exécution d'une application dans un environnement de production.
UPLOAD_FOLDERest une variable personnalisée qui est définie pour être référencée ultérieurement dans l'application et indiquer où les données utilisateur téléchargées doivent être stockées.application.pylance l'application Flask et hérite des paramètres de configuration définis dans.config.pyCeci est effectué par le code suivant :
application = Flask(__name__) application.config.from_pyfile('config.py')
