Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Générez des informations sur z/OS les données DB2 en utilisant AWS Mainframe Modernization et Amazon Q dans Quick Sight
Shubham Roy, Roshna Razack et Santosh Kumar Singh, Amazon Web Services
Résumé
Remarque : le AWS Mainframe Modernization service (expérience de l'environnement d'exécution géré) n'est plus ouvert aux nouveaux clients. Pour des fonctionnalités similaires à AWS Mainframe Modernization Service (expérience de l'environnement d'exécution géré), explorez AWS Mainframe Modernization Service (Self-Managed Expérience). Les clients existants peuvent continuer à utiliser le service normalement. Pour plus d'informations, consultez AWS Mainframe Modernization la section Modification de la disponibilité.
Si votre entreprise héberge des données critiques dans un environnement mainframe IBM Db2, il est essentiel d'obtenir des informations à partir de ces données pour stimuler la croissance et l'innovation. En débloquant les données du mainframe, vous pouvez créer des informations commerciales plus rapides, sécurisées et évolutives afin d'accélérer la prise de décision, la croissance et l'innovation basées sur les données dans le cloud Amazon Web Services ()AWS.
Ce modèle présente une solution pour générer des informations commerciales et créer des récits partageables à partir de données du mainframe dans IBM Db2 for tables. z/OS Les modifications des données du mainframe sont transmises à la AWS Mainframe Modernization rubrique Amazon Managed Streaming for Apache Kafka (Amazon MSK) à l'aide de la réplication de données avec Precisely. Grâce à l'ingestion en streaming d'Amazon Redshift, les données thématiques Amazon MSK sont stockées dans des tables d'entrepôt de données Amazon Redshift Serverless à des fins d'analyse dans Amazon Quick Sight.
Une fois les données disponibles dans Quick Sight, vous pouvez utiliser des instructions en langage naturel avec Amazon Q dans Quick Sight pour créer des résumés des données, poser des questions et générer des récits de données. Vous n'avez pas besoin d'écrire de requêtes SQL ou de vous familiariser avec un outil de business intelligence (BI).
Contexte commercial
Ce modèle présente une solution pour les cas d'utilisation de l'analyse des données sur le mainframe et de l'analyse des données. À l'aide de ce modèle, vous créez un tableau de bord visuel pour les données de votre entreprise. Pour démontrer la solution, ce modèle fait appel à une entreprise de soins de santé qui fournit des plans médicaux, dentaires et ophtalmologiques à ses membres aux États-Unis. Dans cet exemple, les données démographiques des membres et les informations relatives au plan sont stockées dans les tables de z/OS données IBM Db2 for. Le tableau de bord visuel présente les éléments suivants :
Répartition des membres par région
Répartition des membres par sexe
Répartition des membres par âge
Répartition des membres par type de plan
Membres qui n'ont pas terminé leur vaccination préventive
Pour des exemples de répartition des membres par région et de membres n'ayant pas terminé la vaccination préventive, consultez la section Informations supplémentaires.
Après avoir créé le tableau de bord, vous générez un récit de données qui explique les informations issues de l'analyse précédente. L'histoire des données fournit des recommandations pour augmenter le nombre de membres ayant effectué des vaccinations préventives.
Conditions préalables et limitations
Conditions préalables
Un actif Compte AWS. Cette solution a été développée et testée sur Amazon Linux 2 sur Amazon Elastic Compute Cloud (Amazon EC2).
Un cloud privé virtuel (VPC) doté d'un sous-réseau accessible par votre système mainframe.
Une base de données mainframe contenant des données commerciales. Pour les exemples de données utilisés pour créer et tester cette solution, consultez la section Pièces jointes.
La capture des données de modification (CDC) est activée sur les z/OS tables Db2. Pour activer le CDC sur DB2 z/OS, consultez la documentation IBM
. Precisely Connect CDC est z/OS installé sur le z/OS système hébergeant les bases de données sources. L' z/OS image Precisely Connect CDC for est fournie sous forme de fichier zip dans le dossier AWS Mainframe Modernization - Data Replication for IBM z/OS
Amazon Machine Image (AMI). Pour installer Precisely Connect CDC for z/OS sur le mainframe, consultez la documentation d'installation de Precisely .
Limites
Les données Db2 de votre mainframe doivent être dans un type de données pris en charge par Precisely Connect CDC. Pour obtenir la liste des types de données pris en charge, consultez la documentation Precisely Connect CDC
. Vos données chez Amazon MSK doivent être dans un type de données pris en charge par Amazon Redshift. Pour obtenir la liste des types de données pris en charge, consultez la documentation Amazon Redshift.
Amazon Redshift a des comportements et des limites de taille différents selon les types de données. Pour plus d'informations, consultez la documentation Amazon Redshift.
Les données en temps quasi réel dans Quick Sight dépendent de l'intervalle d'actualisation défini pour la base de données Amazon Redshift.
Certains Services AWS ne sont pas disponibles du tout Régions AWS. Pour connaître la disponibilité par région, voir Services AWS par région
. Amazon Q in Quick Sight n'est actuellement pas disponible dans toutes les régions compatibles avec Quick Sight. Pour des points de terminaison spécifiques, consultez la page Points de terminaison et quotas du service, puis choisissez le lien vers le service.
Versions du produit
AWS Mainframe Modernization Réplication des données avec Precisely version 4.1.44
Python version 3.6 ou ultérieure
Apache Kafka version 3.5.1
Architecture
Architecture cible
Le schéma suivant montre une architecture permettant de générer des informations commerciales à partir des données du mainframe en utilisant la réplication AWS Mainframe Modernization des données avec Precisely
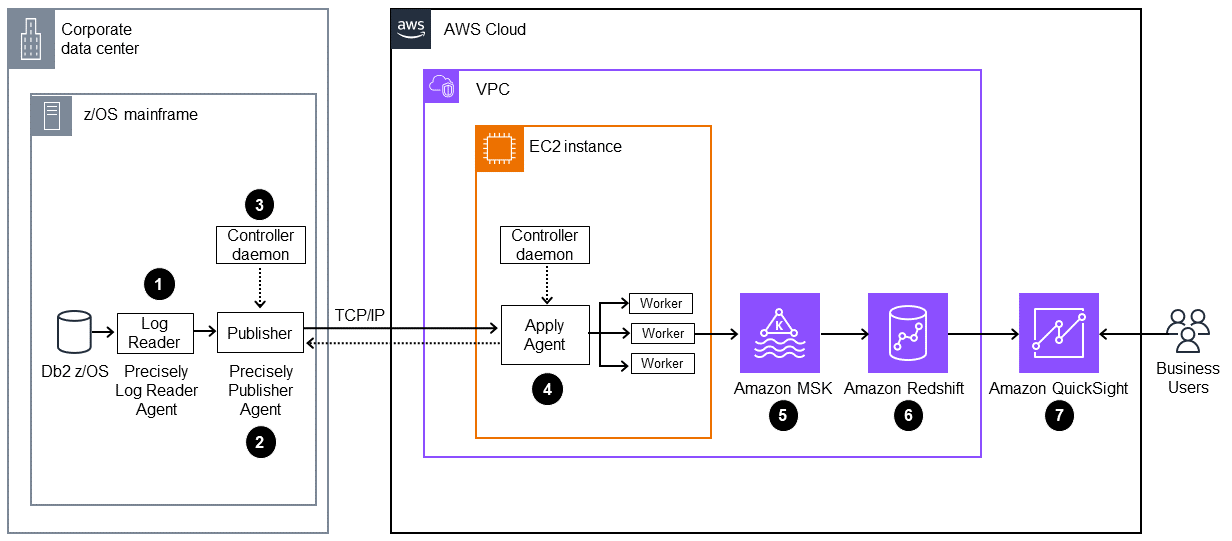
Le schéma suivant illustre le flux de travail suivant :
L'agent Precisely Log Reader lit les données des journaux DB2 et les écrit dans un stockage transitoire sur un système de fichiers OMVS sur le mainframe.
L'agent Publisher lit les journaux Db2 bruts depuis le stockage transitoire.
Le démon du contrôleur local authentifie, autorise, surveille et gère les opérations.
L'agent Apply est déployé sur Amazon EC2 à l'aide de l'AMI préconfigurée. Il se connecte à l'agent de publication via le démon du contrôleur en utilisant TCP/IP. L'agent Apply envoie les données vers Amazon MSK en faisant appel à plusieurs opérateurs pour un débit élevé.
Les travailleurs écrivent les données dans la rubrique Amazon MSK au format JSON. En tant que cible intermédiaire pour les messages répliqués, Amazon MSK fournit des fonctionnalités de basculement automatisées et hautement disponibles.
L'ingestion de streaming Amazon Redshift permet une ingestion de données à faible latence et à haut débit depuis Amazon MSK vers une base de données Amazon Redshift Serverless. Une procédure stockée dans Amazon Redshift effectue la réconciliation des données de modification du mainframe (insert/update/deletes) dans les tables Amazon Redshift. Ces tables Amazon Redshift constituent la source d'analyse des données pour Quick Sight.
Les utilisateurs accèdent aux données dans Quick Sight pour obtenir des analyses et des informations. Vous pouvez utiliser Amazon Q dans Quick Sight pour interagir avec les données à l'aide d'instructions en langage naturel.
Outils
Services AWS
Amazon Elastic Compute Cloud (Amazon EC2) offre une capacité de calcul évolutive dans l' AWS Cloud. Vous pouvez lancer autant de serveurs virtuels que vous le souhaitez et les étendre ou les intégrer rapidement.
AWS Key Management Service (AWS KMS) vous aide à créer et à contrôler des clés cryptographiques afin de protéger vos données.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) est un service entièrement géré qui vous permet de créer et d'exécuter des applications utilisant Apache Kafka pour traiter les données de streaming.
Amazon Quick Sight est un service de business intelligence (BI) à l'échelle du cloud qui vous permet de visualiser, d'analyser et de rapporter vos données dans un tableau de bord unique. Ce modèle utilise les fonctionnalités de BI générative d'Amazon Q dans Quick Sight.
Amazon Redshift Serverless
est une option sans serveur d'Amazon Redshift qui permet d'exécuter et de faire évoluer les analyses de manière plus efficace en quelques secondes, sans qu'il soit nécessaire de configurer et de gérer une infrastructure d'entrepôt de données. AWS Secrets Manager vous aide à remplacer les informations d'identification codées en dur dans votre code, y compris les mots de passe, par un appel d'API à Secrets Manager pour récupérer le secret par programmation.
Autres outils
Precisely Connect CDC
collecte et intègre les données des systèmes existants dans le cloud et les plateformes de données.
Référentiel de code
Le code de ce modèle est disponible dans le GitHub Mainframe_DataInsights_change_data_reconciliation
Bonnes pratiques
Suivez les meilleures pratiques lors de la configuration de votre cluster Amazon MSK.
Suivez les meilleures pratiques d'analyse des données Amazon Redshift pour améliorer les performances.
Lorsque vous créez les rôles Gestion des identités et des accès AWS (IAM) pour la configuration de Precisely, suivez le principe du moindre privilège et accordez les autorisations minimales requises pour effectuer une tâche. Pour plus d'informations, consultez les sections Accorder le moindre privilège et Bonnes pratiques en matière de sécurité dans la documentation IAM.
Épopées
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez un groupe de sécurité. | Pour vous connecter au démon du contrôleur et au cluster Amazon MSK, créez un groupe de sécurité pour l'instance EC2. Ajoutez les règles d'entrée et de sortie suivantes :
Notez le nom du groupe de sécurité. Vous devrez faire référence au nom lorsque vous lancerez l'instance EC2 et que vous configurerez le cluster Amazon MSK. | DevOps ingénieur, AWS DevOps |
Créez une politique IAM et un rôle IAM. |
| DevOps ingénieur, administrateur système AWS |
Provisionnez une instance EC2. | Pour configurer une instance EC2 afin d'exécuter Precisely CDC et de se connecter à Amazon MSK, procédez comme suit :
| Administrateur AWS, DevOps ingénieur |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Créez le cluster Amazon MSK. | Pour créer un cluster Amazon MSK, procédez comme suit :
La création d'un cluster provisionné typique prend jusqu'à 15 minutes. Une fois le cluster créé, son statut passe de Création à Actif. | AWS DevOps, administrateur du cloud |
Configurez SASL/SCRAM l'authentification. | Pour configurer SASL/SCRAM l'authentification pour un cluster Amazon MSK, procédez comme suit :
| Architecte du cloud |
Créez la rubrique Amazon MSK. | Pour créer la rubrique Amazon MSK, procédez comme suit :
| Administrateur du cloud |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez les scripts Precisely pour répliquer les modifications apportées aux données. | Pour configurer les scripts Precisely Connect CDC afin de répliquer les données modifiées depuis le mainframe vers la rubrique Amazon MSK, procédez comme suit :
Par exemple, les fichiers .ddl, consultez la section Informations supplémentaires. | Développeur d'applications, architecte cloud |
Générez la clé ACL du réseau. | Pour générer la clé de liste de contrôle d'accès réseau (ACL réseau), procédez comme suit :
| Architecte du cloud, AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez les valeurs par défaut dans l'écran ISPF. | Pour configurer les paramètres par défaut dans l'Interactive System Productivity Facility (ISPF), suivez les instructions de la documentation Precisely | Administrateur système mainframe |
Configurez le démon du contrôleur. | Pour configurer le démon du contrôleur, procédez comme suit :
| Administrateur système mainframe |
Configuration du diffuseur de publication. | Pour configurer l'éditeur, procédez comme suit :
| Administrateur système mainframe |
Mettez à jour le fichier de configuration du démon. | Pour mettre à jour les informations relatives à l'éditeur dans le fichier de configuration du démon du contrôleur, procédez comme suit :
| Administrateur système mainframe |
Créez la tâche pour démarrer le démon du contrôleur. | Pour créer la tâche, procédez comme suit :
| Administrateur système mainframe |
Générez le fichier JCL de l'éditeur de capture. | Pour générer le fichier JCL de l'éditeur de capture, procédez comme suit :
| Administrateur système mainframe |
Vérifiez et mettez à jour le CDC. |
| Administrateur système mainframe |
Soumettez les fichiers JCL. | Soumettez les fichiers JCL suivants que vous avez configurés lors des étapes précédentes :
Après avoir soumis les fichiers JCL, vous pouvez démarrer le moteur d'application dans Precisely sur l'instance EC2. | Administrateur système mainframe |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Démarrez le moteur d'application et validez le CDC. | Pour démarrer le moteur d'application sur l'instance EC2 et valider le CDC, procédez comme suit :
| Architecte cloud, développeur d'applications |
Validez les enregistrements relatifs à la rubrique Amazon MSK. | Pour lire le message du sujet Kafka, procédez comme suit :
| Développeur d'applications, architecte cloud |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez Amazon Redshift Serverless. | Sur le tableau de bord Amazon Redshift Serverless, vérifiez que l'espace de noms et le groupe de travail ont été créés et sont disponibles. Pour cet exemple de modèle, le processus peut prendre de 2 à 5 minutes. | Ingénieur de données |
Configurez le rôle IAM et la politique de confiance requis pour l'ingestion du streaming. | Pour configurer l'ingestion du streaming sans serveur Amazon Redshift depuis Amazon MSK, procédez comme suit :
| Ingénieur de données |
Connectez Amazon Redshift Serverless à Amazon MSK. | Pour vous connecter à la rubrique Amazon MSK, créez un schéma externe dans Amazon Redshift Serverless. Dans l'éditeur de requêtes Amazon Redshift v2, exécutez la commande SQL suivante, en la
| Ingénieur en migration |
Créez une vue matérialisée. | Pour utiliser les données de la rubrique Amazon MSK dans Amazon Redshift Serverless, créez une vue matérialisée. Dans l'éditeur de requêtes Amazon Redshift v2, exécutez les commandes SQL suivantes, en les
| Ingénieur en migration |
Créez des tables cibles dans Amazon Redshift. | Les tables Amazon Redshift fournissent les données d'entrée pour Quick Sight. Ce modèle utilise les tables Pour créer les deux tables dans Amazon Redshift, exécutez les commandes SQL suivantes dans l'éditeur de requêtes Amazon Redshift v2 :
| Ingénieur en migration |
Créez une procédure stockée dans Amazon Redshift. | Ce modèle utilise une procédure stockée pour synchroniser les données de modification ( Pour créer la procédure stockée dans Amazon Redshift, utilisez l'éditeur de requêtes v2 pour exécuter le code de procédure stockée qui se trouve dans le GitHub référentiel. | Ingénieur en migration |
Lisez à partir de la vue matérialisée en streaming et chargez vers les tables cibles. | La procédure stockée lit les modifications de données depuis la vue matérialisée en continu et charge les modifications de données dans les tables cibles. Pour exécuter la procédure stockée, utilisez la commande suivante :
Vous pouvez utiliser Amazon EventBridge Une autre option consiste à utiliser l'éditeur de requêtes Amazon Redshift v2 pour planifier l'actualisation. Pour plus d'informations, consultez la section Planification d'une requête avec l'éditeur de requêtes v2. | Ingénieur en migration |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez Quick Sight. | Pour configurer Quick Sight, suivez les instructions de la AWS documentation. | Ingénieur en migration |
Configurez une connexion sécurisée entre Quick Sight et Amazon Redshift. | Pour configurer une connexion sécurisée entre Quick Sight et Amazon Redshift, procédez comme suit
| Ingénieur en migration |
Créez un jeu de données pour Quick Sight. | Pour créer un ensemble de données pour Quick Sight à partir d'Amazon Redshift, procédez comme suit :
| Ingénieur en migration |
Joignez-vous à l'ensemble de données. | Pour créer des analyses dans Quick Sight, joignez les deux tables en suivant les instructions de la AWS documentation. Dans le volet Configuration de la jointure, choisissez Left pour le type de jointure. Sous Clauses d'adhésion, utilisez | Ingénieur en migration |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez Amazon Q dans Quick Sight. | Pour configurer Amazon Q dans la fonctionnalité de BI générative de Quick Sight, suivez les instructions de la AWS documentation. | Ingénieur en migration |
Analysez les données du mainframe et créez un tableau de bord visuel. | Pour analyser et visualiser vos données dans Quick Sight, procédez comme suit :
Lorsque vous avez terminé, vous pouvez publier votre tableau de bord afin de le partager avec les autres membres de votre organisation. Pour des exemples, consultez le tableau de bord visuel du mainframe dans la section Informations supplémentaires. | Ingénieur en migration |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Créez une histoire de données. | Créez une histoire de données pour expliquer les conclusions de l'analyse précédente et générer une recommandation visant à accroître la vaccination préventive des membres :
| Ingénieur en migration |
Consultez l'histoire des données générées. | Pour afficher le récit de données généré, choisissez-le sur la page Récits de données. | Ingénieur en migration |
Modifiez un récit de données généré. | Pour modifier le formatage, la mise en page ou les éléments visuels d'un data story, suivez les instructions de la AWS documentation. | Ingénieur en migration |
Partagez une histoire de données. | Pour partager une histoire de données, suivez les instructions de la AWS documentation. | Ingénieur en migration |
Résolution des problèmes
| Problème | Solution |
|---|---|
Pour Quick Sight to Amazon Redshift, la création du jeu de données |
|
La tentative de démarrage du moteur Apply sur l'instance EC2 renvoie l'erreur suivante :
| Exportez le chemin
|
La tentative de démarrage du moteur d'application renvoie l'une des erreurs de connexion suivantes :
| Vérifiez le spool du mainframe pour vous assurer que les tâches du démon du contrôleur sont en cours d'exécution. |
Ressources connexes
Informations supplémentaires
Exemples de fichiers .ddl
members_details.ddl
CREATE TABLE MEMBER_DTLS ( memberid INTEGER NOT NULL, member_name VARCHAR(50), member_type VARCHAR(20), age INTEGER, gender CHAR(1), email VARCHAR(100), region VARCHAR(20) );
member_plans.ddl
CREATE TABLE MEMBER_PLANS ( memberid INTEGER NOT NULL, medical_plan CHAR(1), dental_plan CHAR(1), vision_plan CHAR(1), preventive_immunization VARCHAR(20) );
Exemple de fichier .sqd
<kafka topic name>Remplacez-le par le nom de votre rubrique Amazon MSK.
script.sqd
-- Name: DB2ZTOMSK: DB2z To MSK JOBNAME DB2ZTOMSK;REPORT EVERY 1;OPTIONS CDCOP('I','U','D');-- Source Descriptions JOBNAME DB2ZTOMSK; REPORT EVERY 1; OPTIONS CDCOP('I','U','D'); -- Source Descriptions BEGIN GROUP DB2_SOURCE; DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_details.ddl AS MEMBER_DTLS; DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_plans.ddl AS MEMBER_PLANS; END GROUP; -- Source Datastore DATASTORE cdc://<zos_host_name>/DB2ZTOMSK/DB2ZTOMSK OF UTSCDC AS CDCIN DESCRIBED BY GROUP DB2_SOURCE ; -- Target Datastore(s) DATASTORE 'kafka:///<kafka topic name>/key' OF JSON AS TARGET DESCRIBED BY GROUP DB2_SOURCE; PROCESS INTO TARGET SELECT { REPLICATE(TARGET) } FROM CDCIN;
Tableau de bord visuel du mainframe
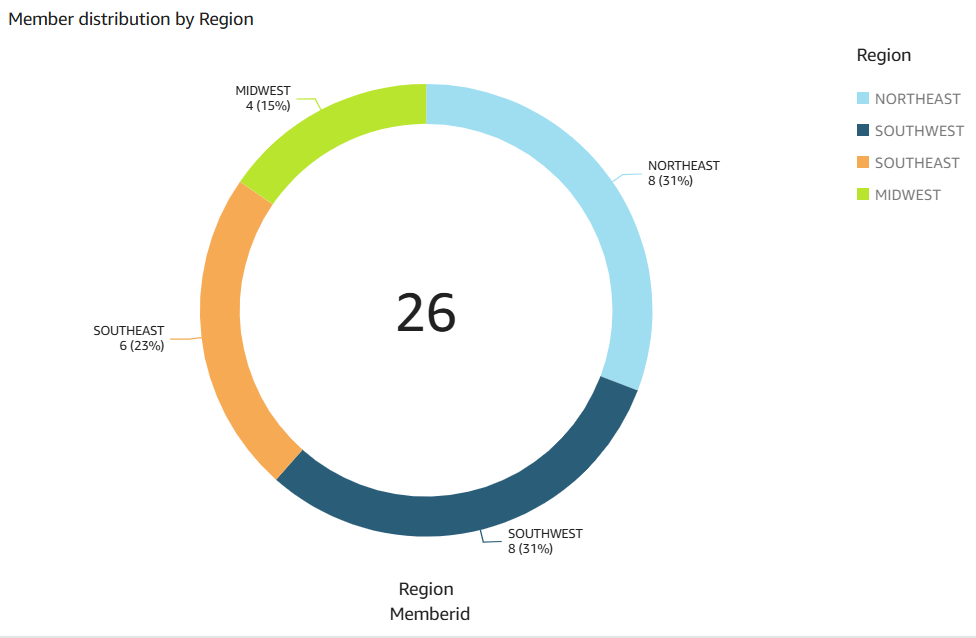
Le visuel de données suivant a été créé par Amazon Q dans Quick Sight pour la question d'analyse show member distribution by region.
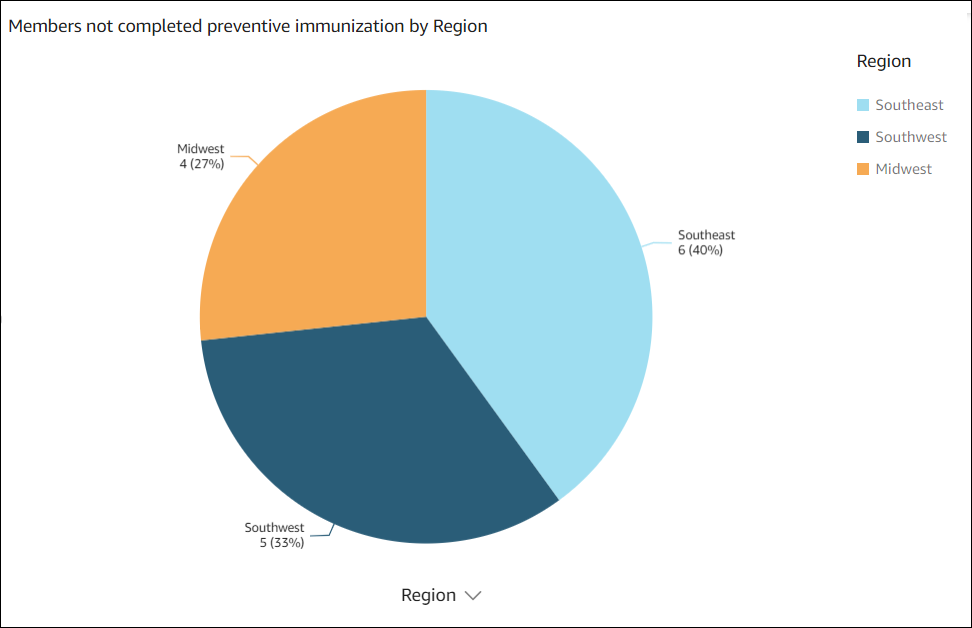
Le visuel de données suivant a été créé par Amazon Q dans Quick Sight pour cette questionshow member distribution by Region who have not completed preventive immunization, in pie chart.
Sortie d'une histoire de données
Les captures d'écran suivantes montrent des sections de l'histoire de données créée par Amazon Q dans Quick Sight pour l'inviteBuild a data story about Region with most numbers of members. Also show the member distribution by age, member distribution by gender. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern.
Dans l'introduction, l'histoire des données recommande de choisir la région comptant le plus grand nombre de membres afin de tirer le meilleur parti des efforts de vaccination.

L'histoire des données fournit une analyse du nombre de membres pour les quatre régions. Les régions du nord-est, du sud-ouest et du sud-est comptent le plus grand nombre de membres.

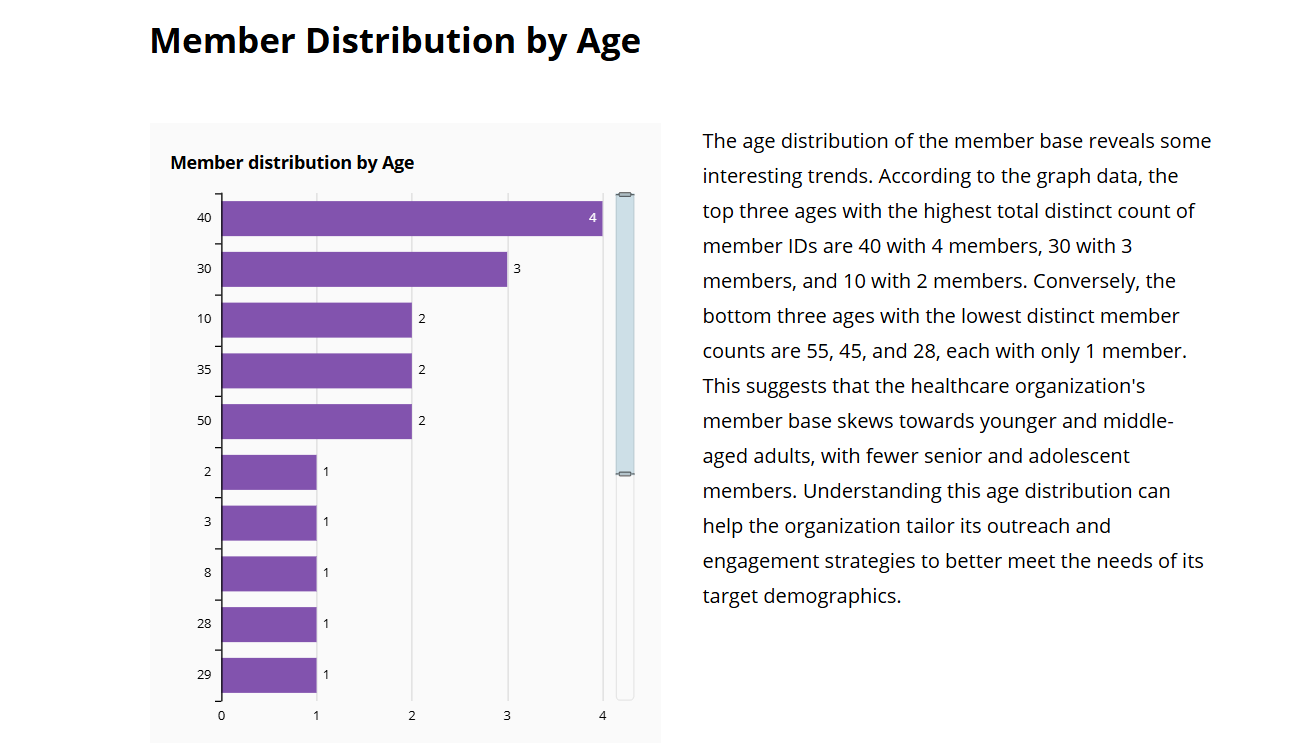
L'histoire des données présente une analyse des membres par âge.
L'histoire des données met l'accent sur les efforts de vaccination dans le Midwest.


Pièces jointes
