Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Interprétabilité locale
Les méthodes les plus populaires pour l'interprétabilité locale de modèles complexes sont basées soit sur les explications additives de Shapley (SHAP) [8], soit sur des dégradés intégrés [11]. Chaque méthode comporte un certain nombre de variantes spécifiques à un type de modèle.
Pour les modèles d'ensembles d'arbres, utilisez tree SHAP
Dans le cas des modèles basés sur des arbres, la programmation dynamique permet un calcul rapide et exact des valeurs de Shapley
Pour les réseaux neuronaux et les modèles différenciables, utilisez des gradients et une conductance intégrés
Les gradients intégrés fournissent un moyen simple de calculer les attributions de caractéristiques dans les réseaux neuronaux. La conductance s'appuie sur des gradients intégrés pour vous aider à interpréter les attributions provenant de parties de réseaux neuronaux telles que les couches et les neurones individuels. (Voir [3,11], la mise en œuvre se trouve sur https://captum.ai/
Dans tous les autres cas, utilisez Kernel SHAP
Vous pouvez utiliser Kernel SHAP pour calculer les attributions de fonctionnalités pour n'importe quel modèle, mais il s'agit d'une approximation du calcul des valeurs complètes de Shapley et cela reste coûteux en termes de calcul (voir [8]). Les ressources informatiques requises pour Kernel SHAP augmentent rapidement avec le nombre de fonctionnalités. Cela nécessite des méthodes d'approximation qui peuvent réduire la fidélité, la répétabilité et la robustesse des explications. Amazon SageMaker AI Clarify propose des méthodes pratiques qui déploient des conteneurs prédéfinis pour calculer les valeurs Kernal SHAP dans des instances distinctes. (Pour un exemple, consultez le GitHub référentiel Fairness and Explainability with SageMaker AI Clarify
Pour les modèles à arbre unique, les variables fractionnées et les valeurs foliaires fournissent un modèle immédiatement explicable, et les méthodes décrites précédemment ne fournissent pas d'informations supplémentaires. De même, pour les modèles linéaires, les coefficients fournissent une explication claire du comportement du modèle. (Le SHAP et les méthodes de gradient intégré renvoient toutes deux des contributions déterminées par les coefficients.)
Le SHAP et les méthodes intégrées basées sur les dégradés présentent des faiblesses. SHAP exige que les attributions soient dérivées d'une moyenne pondérée de toutes les combinaisons de fonctionnalités. Les attributions obtenues de cette manière peuvent être trompeuses lors de l'estimation de l'importance des caractéristiques s'il existe une forte interaction entre les caractéristiques. Les méthodes basées sur des gradients intégrés peuvent être difficiles à interpréter en raison du grand nombre de dimensions présentes dans les grands réseaux neuronaux, et ces méthodes sont sensibles au choix d'un point de base. Plus généralement, les modèles peuvent utiliser les fonctionnalités de manière inattendue pour atteindre un certain niveau de performance, lequel peut varier en fonction du modèle. L'importance des fonctionnalités dépend toujours du modèle.
Visualisations recommandées
Le tableau suivant présente plusieurs méthodes recommandées pour visualiser les interprétations locales abordées dans les sections précédentes. Pour les données tabulaires, nous conseillons un graphique à barres simple qui montre les attributions, afin qu'elles puissent être facilement comparées et utilisées pour déduire comment le modèle fait des prédictions.
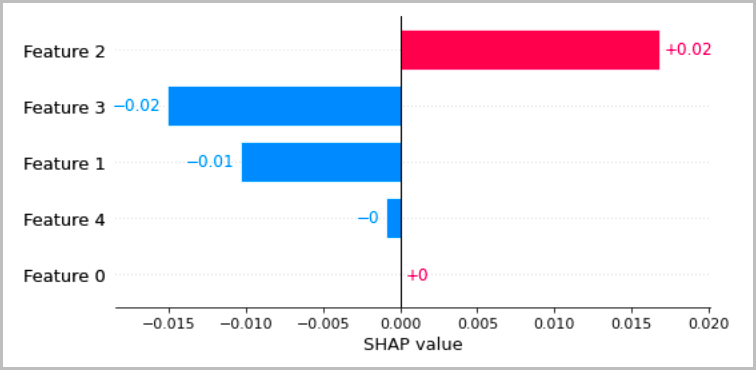
Pour les données texte, l'intégration de jetons entraîne un grand nombre d'entrées scalaires. Les méthodes recommandées dans les sections précédentes produisent une attribution pour chaque dimension de l'intégration et pour chaque sortie. Afin de synthétiser ces informations dans une visualisation, les attributions d'un jeton donné peuvent être additionnées. L'exemple suivant montre la somme des attributions du modèle de réponse aux questions basé sur Bert qui a été entraîné sur le jeu de données SQUAD. Dans ce cas, l'étiquette prévue et vraie est le symbole du mot « france ».

Sinon, la norme vectorielle des attributions de jetons peut être attribuée sous forme de valeur d'attribution totale, comme indiqué dans l'exemple suivant.

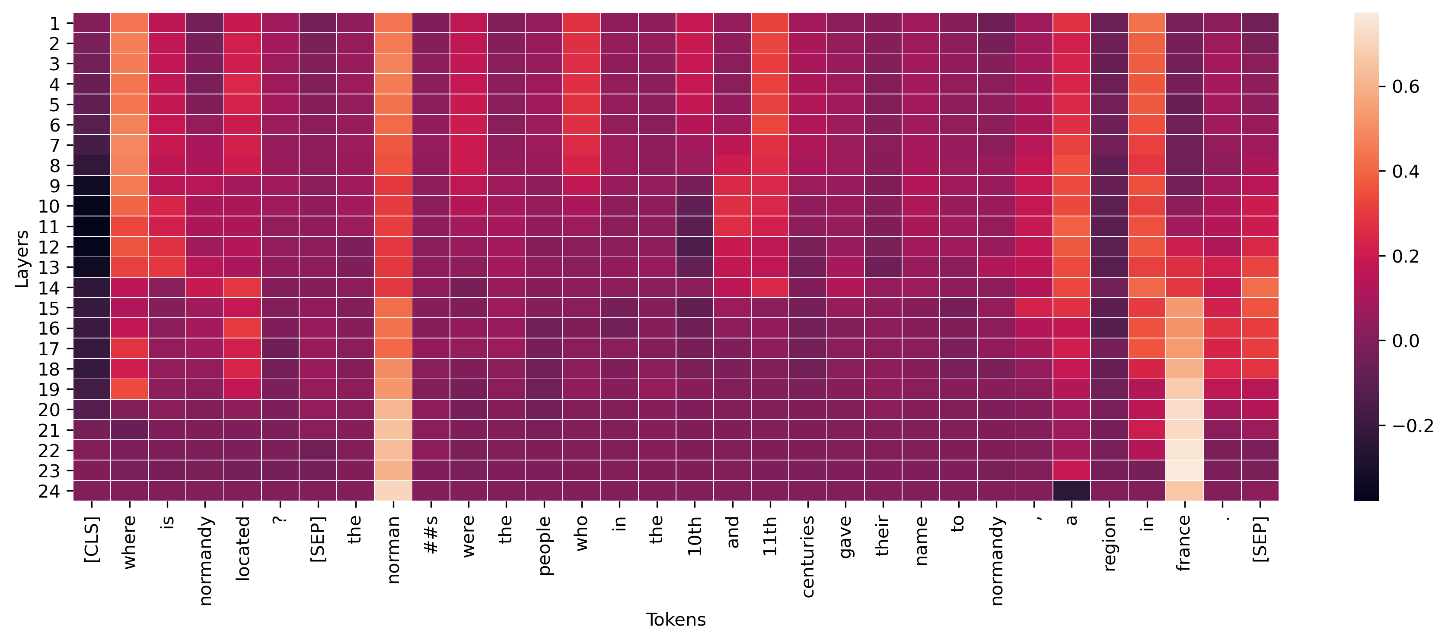
Pour les couches intermédiaires des modèles d'apprentissage profond, des agrégations similaires peuvent être appliquées aux conductances à des fins de visualisation, comme indiqué dans l'exemple suivant. Cette norme vectorielle de la conductance des jetons pour les couches de transformateurs montre l'activation éventuelle de la prédiction des jetons finaux (« france »).
Les vecteurs d'activation conceptuelle fournissent une méthode pour étudier plus en détail les réseaux de neurones profonds [6]. Cette méthode extrait les entités d'une couche d'un réseau déjà entraîné et entraîne un classificateur linéaire sur ces entités afin de tirer des conclusions sur les informations contenues dans la couche. Par exemple, vous souhaiterez peut-être déterminer quelle couche d'un modèle de langage basé sur Bert contient le plus d'informations sur les parties du discours. Dans ce cas, vous pouvez entraîner un part-of-speech modèle linéaire sur chaque sortie de couche et estimer grossièrement que le classificateur le plus performant est associé à la couche contenant le plus part-of-speech d'informations. Bien que nous ne recommandions pas cette méthode comme méthode principale d'interprétation des réseaux neuronaux, elle peut être une option pour une étude plus détaillée et une aide à la conception de l'architecture du réseau.
