Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Nommer les compartiments Amazon S3 dans vos couches de données
Les sections suivantes fournissent des structures de dénomination pour les compartiments Amazon Simple Storage Service (Amazon S3) dans vos couches de lacs de données. Cependant, vous pouvez personnaliser les noms de compartiment et de chemin Amazon S3 en fonction des besoins de votre organisation. Nous vous recommandons de créer des compartiments distincts pour chaque couche individuelle, car les exigences en matière d'archivage, de versionnement, d'accès et de chiffrement peuvent varier d'une couche à l'autre.
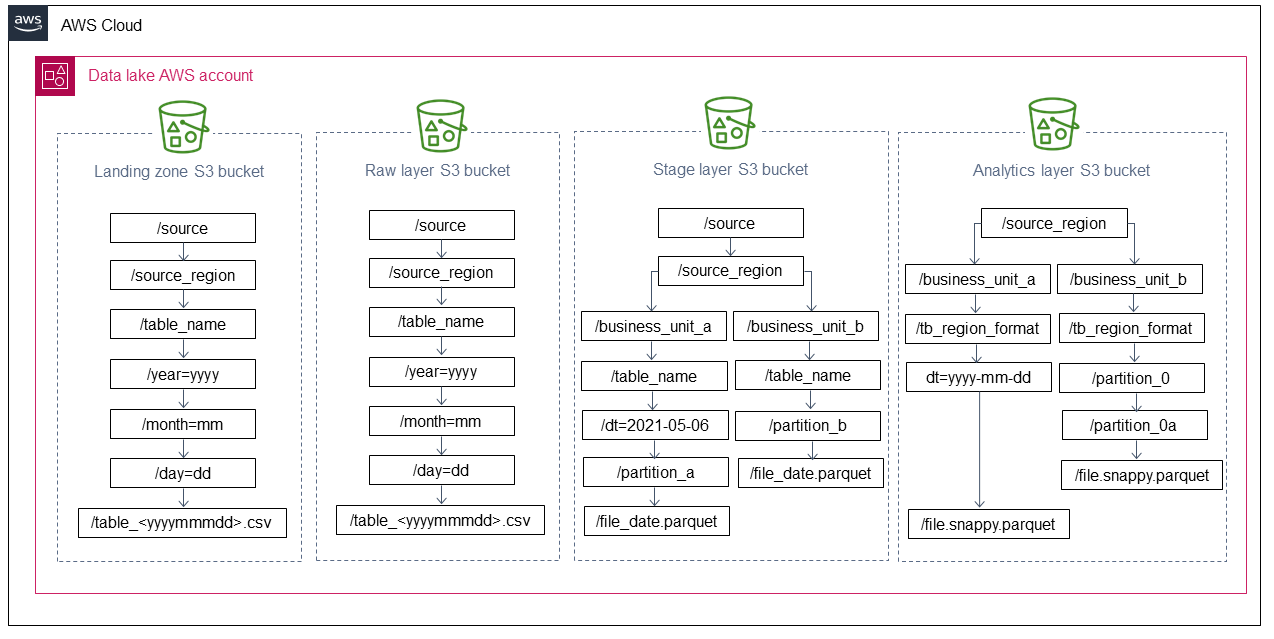
Le schéma suivant montre la structure de dénomination recommandée pour les compartiments Amazon S3 dans les couches de lac de données recommandées. La structure de dénomination sépare plusieurs unités commerciales, formats de fichiers et partitions.
Important
Les compartiments Amazon S3 doivent suivre les directives de dénomination énoncées dans les règles de dénomination des compartiments de la documentation Amazon S3.
Vous pouvez adapter les partitions de données en fonction des besoins de votre organisation. Cependant, vous devez utiliser des paires minuscules et clé-valeur (par exemple, year=yyyy au lieu deyyyy) afin de pouvoir mettre à jour le catalogue à l'aide de la commande. MSCK REPAIR
TABLE
La définition d'une stratégie de partition dépend de la nature de vos données et, surtout, de la nature des requêtes de vos utilisateurs. Nous vous recommandons d'analyser les modèles de consommation et de traitement des données afin de trouver la stratégie la plus adaptée à votre organisation. En général, il est judicieux de fournir des niveaux hiérarchiques supérieurs, tels queyear=yyyy, et month=mmday=dd, sur la couche de données brutes et des niveaux hiérarchiques inférieurs sur les couches de données de consommation, telles que la couche d'étape et la couche d'analyse. Cela est dû au fait que les couches de données brutes ne présentent généralement pas les modèles de consommation complexes des pipelines de traitement de données.
Zone d'atterrissage (compartiment Amazon S3)
Vous avez besoin d'un compartiment Amazon S3 pour votre zone de landing zone si les ensembles de données sensibles contiennent des éléments qui doivent être masqués avant que les données ne soient déplacées vers le compartiment brut.
Le tableau suivant fournit la structure de dénomination, une description de la structure de dénomination et un exemple de nom pour le compartiment Amazon S3 dans votre couche de zone de landing zone.
| Format de dénomination | Exemple |
|---|---|
|
|
Compartiment Amazon S3 à couche brute
La couche de données brutes contient des données ingérées qui n'ont pas été transformées et sont dans leur format de fichier d'origine, tel que JSON ou CSV. Ces données sont généralement organisées par source de données et par date à laquelle elles ont été ingérées dans le compartiment Amazon S3 de la couche de données brutes.
Le tableau suivant fournit la structure de dénomination, une description de la structure de dénomination et un exemple de nom pour le compartiment Amazon S3 dans votre couche de données brutes.
| Format de dénomination | Exemple |
|---|---|
|
|
Compartiment Amazon S3 Stage Layer
Les données de la couche d'étape sont lues et transformées à partir de la couche brute (par exemple, à l'aide d'une tâche AWS Glue ou d'Amazon EMR). Ce processus valide les données (par exemple, en vérifiant les types de données et les en-têtes), puis les stocke dans un format de fichier prêt à être consommé, tel qu'Apache Parquet. Les métadonnées sont stockées dans une table du AWS Glue Data Catalog.
Le tableau suivant fournit la structure de dénomination, une description de la structure de dénomination et un exemple de nom pour le compartiment Amazon S3 dans votre couche de données de stage.
| Format de dénomination | Exemple |
|---|---|
|
|
Couche d'analyse (compartiment Amazon S3)
La couche d'analyse est similaire à la couche d'étape car les données sont dans un format de fichier traité, mais elles sont ensuite agrégées conformément aux exigences de votre organisation.
Le tableau suivant fournit la structure de dénomination, une description de la structure de dénomination et un exemple de nom pour le compartiment Amazon S3 dans votre couche de données d'analyse.
| Format de dénomination | Exemple |
|---|---|
|
|
