Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Découplage des relations entre les tables lors de la décomposition de la base de données
Cette section fournit des conseils sur la décomposition des relations complexes entre les tables et les opérations JOIN lors de la décomposition d'une base de données monolithique. Une jointure de table combine les lignes de deux tables ou plus en fonction d'une colonne associée entre elles. L'objectif de la séparation de ces relations est de réduire le couplage élevé entre les tables tout en préservant l'intégrité des données dans les microservices.
Cette section contient les rubriques suivantes :
Stratégie de dénormalisation
La dénormalisation est une stratégie de conception de base de données qui consiste à introduire intentionnellement de la redondance en combinant ou en dupliquant des données entre des tables. Lorsque vous divisez une grande base de données en petites bases de données, il peut être judicieux de dupliquer certaines données entre les services. Par exemple, le stockage des informations de base sur les clients, telles que le nom et les adresses e-mail, à la fois dans un service marketing et dans un service de commande élimine le besoin de recherches interservices constantes. Le service marketing peut avoir besoin des préférences et des coordonnées des clients pour le ciblage des campagnes, tandis que le service des commandes a besoin des mêmes données pour le traitement des commandes et les notifications. Bien que cela crée une certaine redondance des données, cela peut améliorer considérablement les performances et l'indépendance du service, permettant à l'équipe marketing de gérer ses campagnes sans dépendre des recherches en temps réel du service client.
Lorsque vous mettez en œuvre la dénormalisation, concentrez-vous sur les champs fréquemment consultés que vous identifiez grâce à une analyse minutieuse des modèles d'accès aux données. Vous pouvez utiliser des outils, tels que Oracle AWR des rapports ou des rapportspg_stat_statements, pour comprendre quelles données sont généralement extraites ensemble. Les experts du domaine peuvent également fournir des informations précieuses sur les groupements de données naturelles. N'oubliez pas que la dénormalisation n'est pas une all-or-nothing approche, mais uniquement des données dupliquées qui améliorent de manière démontrable les performances du système ou réduisent les dépendances complexes.
Reference-by-key stratégie
Une reference-by-key stratégie est un modèle de conception de base de données dans lequel les relations entre les entités sont maintenues par le biais de clés uniques plutôt que de stocker les données associées réelles. Au lieu des relations traditionnelles à clé étrangère, les microservices modernes stockent souvent uniquement les identifiants uniques des données associées. Par exemple, plutôt que de conserver toutes les informations du client dans le tableau des commandes, le service des commandes enregistre uniquement l'identifiant du client et récupère des informations supplémentaires sur le client via un appel d'API en cas de besoin. Cette approche préserve l'indépendance des services tout en garantissant l'accès aux données associées.
Motif CQRS
Le modèle CQRS (Command Query Responsibility Segrégation) sépare les opérations de lecture et d'écriture d'un magasin de données. Ce modèle est particulièrement utile dans les systèmes complexes nécessitant de hautes performances, en particulier ceux soumis à des read/write charges asymétriques. Si votre application a fréquemment besoin de combiner des données provenant de plusieurs sources, vous pouvez créer un modèle CQRS dédié au lieu de jointures complexes. Par exemple, plutôt que de joindre Product des Inventory tables à chaque demande, maintenez une Product Catalog table consolidée contenant les données nécessaires. Pricing Les avantages de cette approche peuvent l'emporter sur les coûts de la table supplémentaire.
Envisagez un scénario dans lequel ProductPrice, et les Inventory services ont fréquemment besoin d'informations sur les produits. Au lieu de configurer ces services pour accéder directement aux tables partagées, créez un Product Catalog service dédié. Ce service gère sa propre base de données qui contient les informations consolidées sur les produits. Il agit comme une source unique de vérité pour les requêtes relatives aux produits. Lorsque les détails du produit, les prix ou les niveaux de stock changent, les services concernés peuvent publier des événements pour mettre à jour le Product Catalog service. Cela garantit la cohérence des données tout en préservant l'indépendance des services. L'image suivante montre cette configuration, où Amazon EventBridge
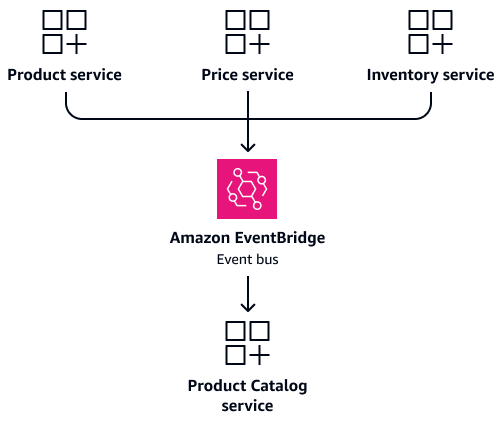
Comme indiqué dans la section suivanteSynchronisation des données basée sur les événements, maintenez le modèle CQRS à jour au fil des événements. Lorsque les détails des produits, les prix ou les niveaux de stock changent, les services concernés publient des événements. Le Product Catalog service s'abonne à ces événements et met à jour sa vue consolidée. Cela permet des lectures rapides sans jointure complexe et préserve l'indépendance du service.
Synchronisation des données basée sur les événements
La synchronisation des données basée sur les événements est un modèle dans lequel les modifications apportées aux données sont capturées et propagées sous forme d'événements, ce qui permet à différents systèmes ou composants de maintenir des états de données synchronisés. Lorsque les données changent, au lieu de mettre à jour immédiatement toutes les bases de données associées, publiez un événement pour informer les services abonnés. Par exemple, lorsqu'un client change d'adresse de livraison dans le Customer service, un CustomerUpdated événement déclenche des mises à jour du Order service et du Delivery service selon le calendrier de chaque service. Cette approche remplace les jointures de table rigides par des mises à jour flexibles et évolutives basées sur les événements. Certains services peuvent brièvement contenir des données périmées, mais le compromis réside dans l'amélioration de l'évolutivité du système et de l'indépendance des services.
Implémentation d'alternatives aux jointures de tables
Commencez la décomposition de votre base de données par des opérations de lecture, car elles sont généralement plus simples à migrer et à valider. Une fois les chemins de lecture stables, abordez les opérations d'écriture les plus complexes. Pour les exigences critiques et de haute performance, envisagez d'implémenter le modèle CQRS. Utilisez une base de données distincte et optimisée pour les lectures tout en conservant une autre pour les écritures.
Créez des systèmes résilients en ajoutant une logique de nouvelle tentative pour les appels interservices et en implémentant les couches de mise en cache appropriées. Surveillez de près les interactions entre les services et configurez des alertes pour les problèmes de cohérence des données. L'objectif final n'est pas la cohérence parfaite partout, mais la création de services indépendants performants tout en maintenant une précision des données acceptable pour les besoins de votre entreprise.
La nature découplée des microservices introduit les nouvelles complexités suivantes en matière de gestion des données :
-
Les données sont distribuées. Les données se trouvent désormais dans des bases de données distinctes, gérées par des services indépendants.
-
La synchronisation en temps réel entre les services est souvent peu pratique, ce qui nécessite un éventuel modèle de cohérence.
-
Les opérations qui se produisaient auparavant dans le cadre d'une seule transaction de base de données concernent désormais plusieurs services.
Pour relever ces défis, procédez comme suit :
-
Mettez en œuvre une architecture axée sur les événements : utilisez les files d'attente de messages et la publication d'événements pour propager les modifications de données entre les services. Pour plus d'informations, voir Création d'architectures pilotées par les événements
sur un terrain sans serveur. -
Adoptez le modèle d'orchestration Saga : ce modèle vous aide à gérer les transactions distribuées et à préserver l'intégrité des données sur l'ensemble des services. Pour plus d'informations, voir Création d'une application distribuée sans serveur à l'aide d'un modèle d'orchestration Saga sur AWS Blogs
. -
Conception en cas d'échec : intégrez des mécanismes de nouvelle tentative, des disjoncteurs et des transactions de compensation pour gérer les problèmes de réseau ou les pannes de service.
-
Utiliser l'estampillage de version : suivez les versions des données pour gérer les conflits et vous assurer que les mises à jour les plus récentes sont appliquées.
-
Réconciliation régulière — Mettez en œuvre des processus de synchronisation des données périodiques pour détecter et corriger les éventuelles incohérences.
Exemple basé sur un scénario
L'exemple de schéma suivant comporte deux tables, une Customer table et une Order table :
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
Voici un exemple de la façon dont vous pourriez utiliser une approche dénormalisée :
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
Le nom du client et les adresses e-mail du nouveau Order tableau sont dénormalisés. Le customer_id est référencé et il n'existe aucune contrainte de clé étrangère avec la Customer table. Les avantages de cette approche dénormalisée sont les suivants :
-
Le
Orderservice peut afficher l'historique des commandes avec les détails du client, et il ne nécessite pas d'appels d'API auCustomermicroservice. -
Si le
Customerservice est en panne, il reste pleinement fonctionnel.Order -
Les requêtes relatives au traitement des commandes et à la création de rapports sont plus rapides.
Le schéma suivant montre une application monolithique qui récupère les données de commande à l'aide degetOrder(customer_id), getOrder(order_id)getCustomerOders(customer_id), et d'appels createOrder(Order
order) d'API au Order microservice.
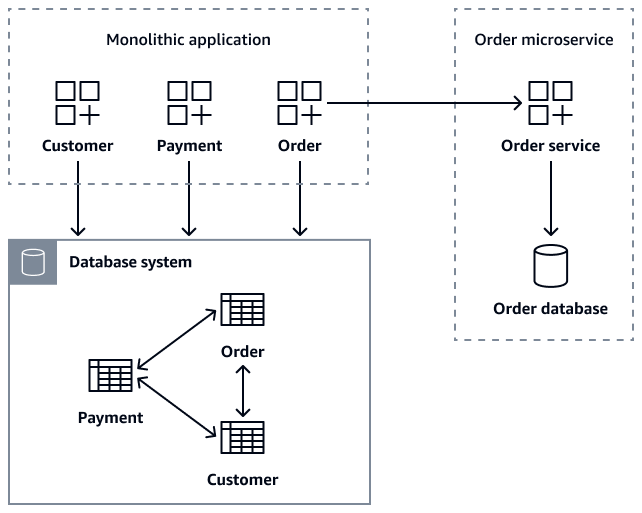
Pendant la migration des microservices, vous pouvez conserver la Order table dans la base de données monolithique à titre de mesure de sécurité transitoire, afin de garantir que l'ancienne application reste fonctionnelle. Cependant, il est essentiel que toutes les nouvelles opérations liées aux commandes soient acheminées via l'API de Order microservice, qui gère sa propre base de données tout en écrivant simultanément dans l'ancienne base de données en tant que sauvegarde. Ce modèle à double écriture constitue un filet de sécurité. Il permet une migration progressive tout en préservant la stabilité du système. Une fois que tous les clients ont migré avec succès vers le nouveau microservice, vous pouvez désactiver l'ancienne Order table dans la base de données monolithique. Après avoir décomposé l'application monolithique et sa base de données en Order microservices distinctsCustomer, le principal défi consiste à maintenir la cohérence des données.
