Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Analyse de la cohésion et du couplage pour la décomposition des bases de données
Cette section vous aide à analyser les modèles de couplage et de cohésion dans votre base de données monolithique afin de guider sa décomposition. Il est essentiel de comprendre comment les composants de base de données interagissent et dépendent les uns des autres pour identifier les points de rupture naturels, évaluer la complexité et planifier une approche de migration progressive. Cette analyse révèle les dépendances cachées, met en évidence les domaines qui se prêtent à une séparation immédiate et vous aide à hiérarchiser les efforts de décomposition tout en minimisant les risques de transformation. En examinant à la fois le couplage et la cohésion, vous pouvez prendre des décisions éclairées concernant la séquence de séparation des composants afin de maintenir la stabilité du système tout au long du processus de transformation.
Cette section contient les rubriques suivantes :
À propos de la cohésion et du couplage
Le couplage mesure le degré d'interdépendance entre les composants de la base de données. Dans un système bien conçu, vous souhaitez obtenir un couplage souple, dans lequel les modifications apportées à un composant ont un impact minimal sur les autres. La cohésion mesure dans quelle mesure les éléments d'un composant de base de données fonctionnent ensemble pour atteindre un objectif unique et bien défini. Une cohésion élevée indique que les éléments d'un composant sont étroitement liés et axés sur une fonction spécifique. Lorsque vous décomposez une base de données monolithique, vous devez analyser à la fois la cohésion au sein des composants individuels et le couplage entre eux. Cette analyse vous aide à prendre des décisions éclairées sur la manière de décomposer la base de données tout en préservant l'intégrité et les performances du système.
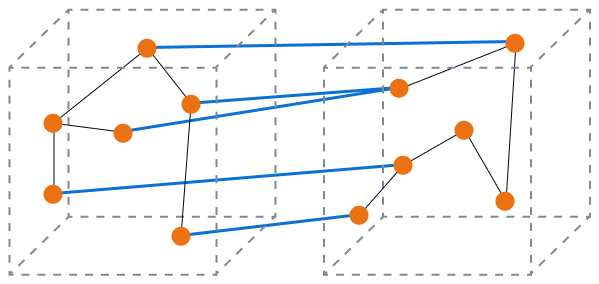
L'image suivante montre un couplage lâche avec une cohésion élevée. Les composants de la base de données fonctionnent ensemble pour exécuter une fonction spécifique, et vous minimisez l'impact des modifications sur un seul composant. C'est l'état idéal.

L'image suivante montre un couplage élevé avec une faible cohésion. Les composants de la base de données sont déconnectés et les modifications sont très susceptibles d'avoir un impact sur les autres composants.
Modèles de couplage courants dans les bases de données monolithiques
Il existe plusieurs modèles de couplage courants lors de la décomposition d'une base de données monolithique en bases de données spécifiques aux microservices. La compréhension de ces modèles est essentielle au succès des initiatives de modernisation des bases de données. Cette section décrit chaque modèle, ses défis et les meilleures pratiques pour réduire le couplage.
Modèle de couplage de mise en œuvre
Définition : Les composants sont étroitement interconnectés au niveau du code et du schéma. Par exemple, la modification de la structure d'une customer table a un impact sur order les billing services. inventory
Impact de la modernisation : chaque microservice nécessite son propre schéma de base de données et sa propre couche d'accès aux données.
Défis :
-
Les modifications apportées aux tables partagées affectent plusieurs services
-
Risque élevé d'effets secondaires imprévus
-
Complexité accrue des tests
-
Difficile de modifier des composants individuels
Bonnes pratiques pour réduire le couplage :
-
Définissez des interfaces claires entre les composants
-
Utiliser des couches d'abstraction pour masquer les détails de mise en œuvre
-
Implémenter des schémas spécifiques au domaine
Schéma de couplage temporel
Définition : Les opérations doivent s'exécuter dans un ordre spécifique. Par exemple, le traitement des commandes ne peut pas se poursuivre tant que les mises à jour de l'inventaire ne sont pas terminées.
Impact de la modernisation : chaque microservice a besoin d'un contrôle autonome des données.
Défis :
-
Rompre les dépendances synchrones entre les services
-
Les goulets d'étranglement liés aux performances
-
Difficile à optimiser
-
Traitement parallèle limité
Bonnes pratiques pour réduire le couplage :
-
Mettre en œuvre un traitement asynchrone dans la mesure du possible
-
Utiliser des architectures pilotées par les événements
-
Conception pour une cohérence éventuelle, le cas échéant
Schéma de couplage de déploiement
Définition : Les composants du système doivent être déployés en tant qu'unité unique. Par exemple, une modification mineure de la logique de traitement des paiements nécessite le redéploiement de l'ensemble de la base de données.
Impact de la modernisation : déploiements de bases de données indépendants par service
Défis :
-
Déploiements à haut risque
-
Fréquence de déploiement limitée
-
Procédures de rétrogradation complexes
Bonnes pratiques pour réduire le couplage :
-
Décomposer en composants déployables indépendamment
-
Mettre en œuvre des stratégies de partage de base de données
-
Utiliser des modèles de déploiement bleu-vert
Schéma de couplage de domaines
Définition : Les domaines commerciaux partagent les structures et la logique des bases de données. Par exemple, les inventory domaines customerorder, et partagent des tables et des procédures stockées.
Impact de la modernisation : isolation des données spécifiques au domaine
Défis :
-
Limites de domaines complexes
-
Difficile de faire évoluer des domaines individuels
-
Des règles commerciales enchevêtrées
Bonnes pratiques pour réduire le couplage :
-
Identifiez des limites de domaine claires
-
Séparer les données par contexte de domaine
-
Mettre en œuvre des services spécifiques à un domaine
Modèles de cohésion courants dans les bases de données monolithiques
Il existe plusieurs modèles de cohésion courants lors de l'évaluation des composants de base de données en vue de leur décomposition. Il est essentiel de comprendre ces modèles pour identifier les composants de base de données bien structurés. Cette section décrit chaque modèle, ses caractéristiques et les meilleures pratiques pour renforcer la cohésion.
Schéma de cohésion fonctionnel
Définition : Tous les éléments soutiennent et contribuent directement à l'exécution d'une fonction unique et bien définie. Par exemple, toutes les procédures et tables stockées dans un module de traitement des paiements ne gèrent que les opérations liées au paiement.
Impact de la modernisation : modèle idéal pour la conception de bases de données de microservices
Défis :
-
Identifier des limites fonctionnelles claires
-
Séparer les composants à usage mixte
-
Maintien d'une responsabilité unique
Les meilleures pratiques pour renforcer la cohésion :
-
Regroupez les fonctions associées
-
Supprimer les fonctionnalités non liées
-
Définissez des limites claires pour les composants
Schéma de cohésion séquentiel
Définition : La sortie d'un élément devient l'entrée d'un autre. Par exemple, les résultats de validation d'une commande sont intégrés au traitement des commandes.
Impact de la modernisation : nécessite une analyse minutieuse des flux de travail et une cartographie des flux de données
Défis :
-
Gérer les dépendances entre les étapes
-
Gestion des scénarios de défaillance
-
Maintien de l'ordre des processus
Les meilleures pratiques pour renforcer la cohésion :
-
Documentez des flux de données clairs
-
Mettre en œuvre une gestion appropriée des erreurs
-
Concevez des interfaces claires entre les étapes
Schéma de cohésion communicationnelle
Définition : Les éléments fonctionnent sur les mêmes données. Par exemple, les fonctions de gestion des profils clients fonctionnent toutes avec les données des clients.
Impact de la modernisation : aide à identifier les limites des données pour la séparation des services afin de réduire le couplage entre les modules
Défis :
-
Déterminer la propriété des données
-
Gestion de l'accès aux données partagées
-
Maintien de la cohérence des données
Les meilleures pratiques pour renforcer la cohésion :
-
Définissez clairement la propriété des données
-
Mettre en œuvre des modèles d'accès aux données appropriés
-
Concevez un partitionnement des données efficace
Schéma de cohésion procédurale
Définition : Les éléments sont regroupés car ils doivent être exécutés dans un ordre spécifique, mais ils peuvent ne pas être liés fonctionnellement. Par exemple, dans le cadre du traitement des commandes, une procédure stockée qui gère à la fois la validation des commandes et les notifications aux utilisateurs est regroupée simplement parce qu'elles se déroulent en séquence, même si elles répondent à des objectifs différents et peuvent être gérées par des services distincts.
Impact de la modernisation : nécessite une séparation soigneuse des procédures tout en maintenant le flux des processus
Défis :
-
Maintien d'un flux de processus correct après la décomposition
-
Identifier les véritables limites fonctionnelles par rapport aux dépendances procédurales
Les meilleures pratiques pour renforcer la cohésion :
-
Procédures distinctes en fonction de leur objectif fonctionnel plutôt que de leur ordre d'exécution
-
Utiliser des modèles d'orchestration pour gérer le flux de processus
-
Mettre en œuvre des systèmes de gestion des flux de travail pour les séquences complexes
-
Concevez des architectures pilotées par les événements pour gérer les étapes du processus de manière indépendante
Schéma de cohésion temporelle
Définition : Les éléments sont liés par des exigences temporelles. Par exemple, lorsqu'une commande est passée, plusieurs opérations doivent être exécutées simultanément : la vérification de l'inventaire, le traitement des paiements, la confirmation de commande et la notification d'expédition doivent tous avoir lieu dans un intervalle de temps spécifique afin de maintenir un état de commande cohérent.
Impact de la modernisation : peut nécessiter un traitement spécial dans les systèmes distribués
Défis :
-
Coordination des dépendances temporelles entre les services distribués
-
Gestion des transactions distribuées
-
Confirmation de l'achèvement du processus sur plusieurs composants
Les meilleures pratiques pour renforcer la cohésion :
-
Mettre en œuvre des mécanismes de planification et des délais d'attente appropriés
-
Utilisez des architectures axées sur les événements avec une gestion claire des séquences
-
Conception pour une cohérence éventuelle avec les modèles de rémunération
-
Implémenter des modèles de saga pour les transactions distribuées
Schéma de cohésion logique ou fortuit
Définition : Les éléments sont classés logiquement pour faire les mêmes choses, même s'ils ont des relations faibles ou insignifiantes. Par exemple, vous pouvez stocker les données relatives aux commandes des clients, les inventaires des entrepôts et les modèles d'e-mails marketing dans le même schéma de base de données, car ils concernent tous les opérations de vente, malgré des modèles d'accès, une gestion du cycle de vie et des exigences de mise à l'échelle différents. Un autre exemple consiste à combiner le traitement des paiements des commandes et la gestion du catalogue de produits au sein d'un même composant de base de données, car ils font tous deux partie du système de commerce électronique, même s'ils répondent à des fonctions commerciales distinctes ayant des besoins opérationnels différents.
Impact de la modernisation : devrait être refactorisé ou réorganisé
Défis :
-
Identifier de meilleurs modèles d'organisation
-
Briser les dépendances inutiles
-
Composantes de restructuration qui ont été regroupées de manière arbitraire
Les meilleures pratiques pour renforcer la cohésion :
-
Réorganisez en fonction des véritables limites fonctionnelles et des domaines d'activité
-
Supprimer les groupements arbitraires basés sur des relations superficielles
-
Mettre en œuvre une séparation appropriée des éléments en fonction des capacités de l'entreprise
-
Aligner les composants de base de données sur leurs exigences opérationnelles spécifiques
Mise en œuvre d'un faible couplage et d'une haute cohésion
Bonnes pratiques
Les meilleures pratiques suivantes peuvent vous aider à réduire le couplage :
-
Réduisez les dépendances entre les composants de base de données
-
Utiliser des interfaces bien définies pour l'interaction entre les composants
-
Évitez les états partagés et les structures de données globales
Les meilleures pratiques suivantes peuvent vous aider à atteindre une cohésion élevée :
-
Regroupez les données et les opérations associées
-
Assurez-vous que chaque composant a une responsabilité unique et claire
-
Maintenir des limites claires entre les différents domaines d'activité
Phase 1 : Cartographier les dépendances des données
Cartographiez les relations entre les données et identifiez les limites naturelles. Vous pouvez utiliser des outils, tels que SchemaSpy
Vous pouvez également exporter les schémas de votre base de données dans une base de données de graphes ou dans un Jupiter bloc-notes. Vous pouvez ensuite appliquer des algorithmes de clustering ou de composants interconnectés pour identifier les limites naturelles et les dépendances. D'autres AWS Partner outils, tels que CAST Imaging
Phase 2 : Analyser les limites des transactions et les modèles d'accès
Analysez les modèles de transaction pour maintenir les propriétés ACID (atomicité, cohérence, isolation, durabilité) et comprendre comment les données sont consultées et modifiées. Vous pouvez utiliser des outils d'analyse de base de données et de diagnostic, tels que Oracle Automatic Workload Repository (AWR)
Les outils d'IA, tels que vFunction
Phase 3 : Identifier les tables autonomes
Recherchez les tableaux qui présentent deux caractéristiques principales :
-
Cohésion élevée — Les contenus de la table sont étroitement liés les uns aux autres
-
Couplage faible : leur dépendance par rapport aux autres tables est minimale.
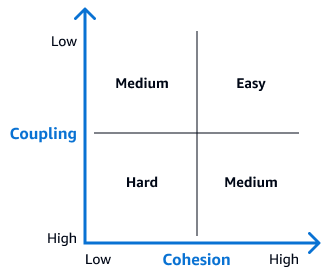
La matrice de couplage-cohésion suivante peut vous aider à identifier la difficulté de découpler chaque table. Les tableaux qui apparaissent dans le quadrant supérieur droit de cette matrice sont des candidats idéaux pour les premiers efforts de découplage, car ils sont les plus faciles à séparer. Dans un diagramme ER, ces tables présentent peu de relations de clé étrangère ou d'autres dépendances. Après avoir découplé ces tables, progressez vers des tables présentant des relations plus complexes.
Note
La structure de la base de données reflète souvent l'architecture de l'application. Les tables plus faciles à découpler au niveau de la base de données correspondent généralement à des composants plus faciles à convertir en microservices au niveau de l'application.
