Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
# Machines d'état Aurora et Step Functions
Cette section couvre les processus et les machines d'état spécifiques au basculement et au retour en panne des clusters Amazon Aurora. Les clusters sont configurés en tant que base de données globale.
**Note**
À des fins de démonstration, cet exemple utilise Aurora MySQL Compatible Edition. Vous pouvez suivre des étapes similaires pour Aurora PostgreSQL Compatible Edition.
## État stable
À l'état stable, une base de données globale compatible avec Amazon Aurora MySQL (`dr-globaldb-cluster-mysql`) a été créée avec deux clusters de bases de données. Le premier cluster de base de données (`db-cluster-01`) a été créé dans le cluster principal Région AWS (`us-east-1`) pour répondre à la charge de travail de lecture/écriture. Le deuxième cluster de base de données (`db-cluster-02`)**** a été créé dans la région secondaire (`us-west-2`) pour servir la charge de travail en lecture seule.
En plus de fournir la solution DR, vous pouvez réduire la charge sur votre cluster de base de données principal en acheminant les requêtes de lecture de vos applications vers le cluster de base de données secondaire. Chacun de ces clusters contient une instance de base de données appelée `dbcluster-01-use1-instance-1` et`dbcluster-02-usw2-instance-2`, respectivement.
## État de l'événement
À l'aide d'une base de données mondiale Amazon Aurora, vous pouvez planifier et reprendre vos activités en cas de sinistre assez rapidement. La reprise après sinistre est généralement mesurée à l'aide des valeurs de l'objectif de temps de restauration (RTO) et de l'objectif du point de reprise (RPO). Pour plus d'informations, consultez [Utilisation du basculement ou du basculement dans une base de données globale Amazon Aurora](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-disaster-recovery.html).
Avec une base de données globale Aurora, il existe deux approches différentes pour le basculement :
+ Basculement (basculement planifié géré)
+ Basculement (basculement manuel non planifié, ou *détachement* et promotion)
### Basculement
Le passage au numérique est destiné aux environnements contrôlés, tels que la maintenance opérationnelle et les autres procédures opérationnelles planifiées. En utilisant un basculement planifié géré, vous pouvez déplacer le cluster de base de données principal de votre base de données globale Aurora vers l'une des régions secondaires. Comme le basculement attend que les clusters de base de données secondaires soient synchronisés avec la base de données principale, le RPO est égal à 0 (aucune perte de données). Pour en savoir plus, consultez la section [Effectuer des commutations pour les bases de données mondiales Amazon Aurora](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-disaster-recovery.html#aurora-global-database-disaster-recovery.managed-failover).
La machine `dr-orchestrator-stepfunction-FAILOVER` d'état est invoquée pendant l'*état de l'événement* pour faire basculer votre cluster principal vers la région secondaire que vous avez choisie (`us-west-2`).
Pour effectuer le basculement, procédez comme suit :
1. Connectez-vous au AWS Management Console.
1. Remplacez la région par la région DR (`us-west-2`).
1. Accédez à **Services**, puis sélectionnez **Step Functions**.
1. Accédez à la machine à `dr-orchestrator-stepfunction-FAILOVER` états.
1. Choisissez **Démarrer l'exécution**, puis entrez le code JSON suivant dans la `Input - optional` section :
```
{
"StatePayload": [
{
"layer": 1,
"resources": [
{
"resourceType": "PlannedFailoverAurora",
"resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)",
"parameters": {
"GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier",
"DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier"
}
}
]
}
]
}
```
1. La machine `dr-orchestrator-stepfunction-FAILOVER` d'état lit le type de ressource `PlannedFailoverAuroraMySQ` L et appelle la machine d'`dr-orchestrator-stepfunction-planned-Aurora-failover`état pour qu'elle bascule sur la base de données globale Aurora.
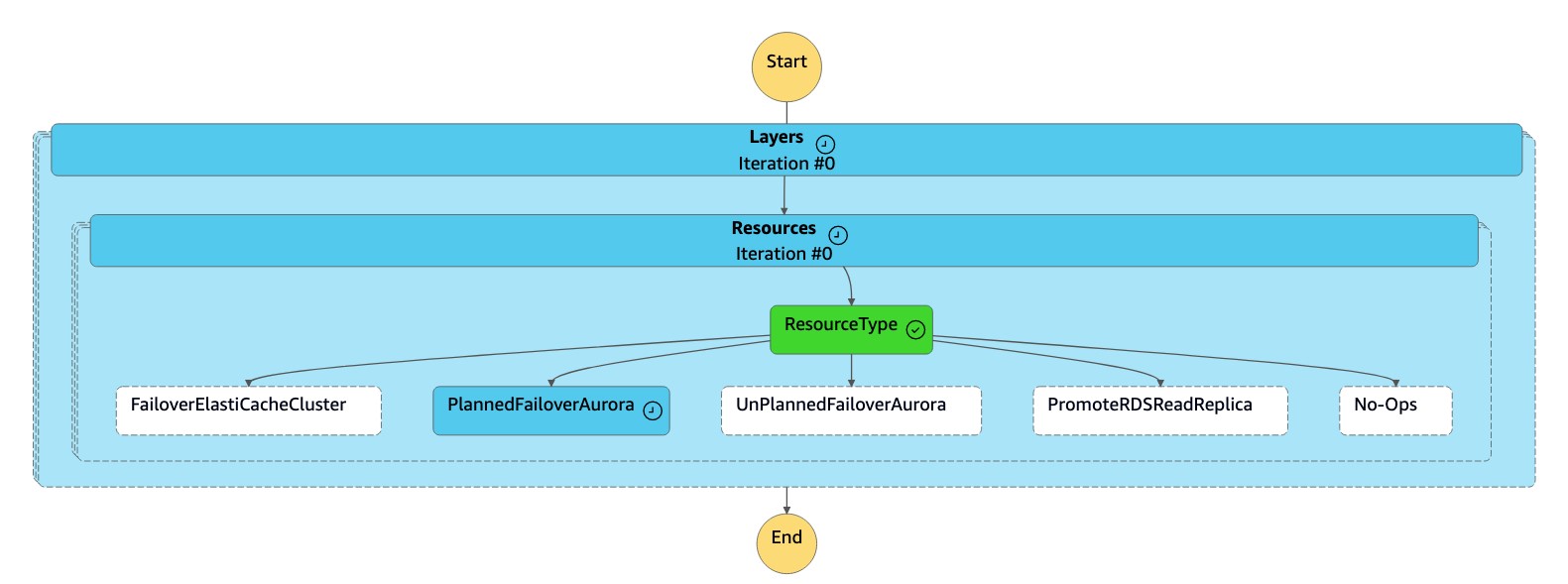
1. La machine `dr-orchestrator-stepfunction-planned-Aurora-failover` d'état exécute les étapes suivantes pour passer du rôle de base de données globale compatible Aurora MySQL.
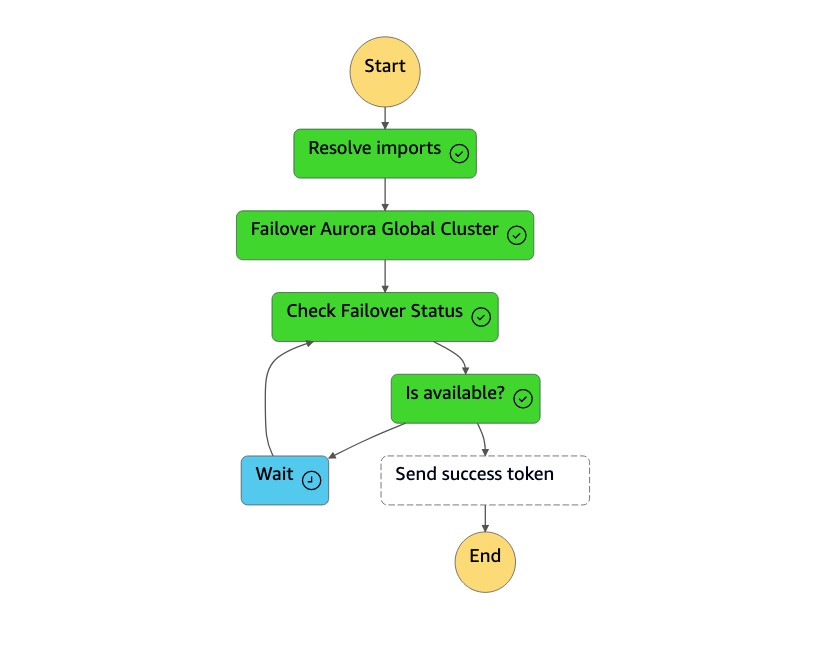
[See the AWS documentation website for more details](http://docs.aws.amazon.com/fr_fr/prescriptive-guidance/latest/automate-dr-solution-relational-database/aurora-state-machines.html)
1. Accédez à la console Amazon RDS. Sous **Status**, les valeurs de la base de données globale Aurora passeront de **Disponible** à **Switching over** ou **Modifying**.
1. Une fois que la machine `dr-orchestrator-stepfunction-planned-Aurora-failover` d'état est terminée, elle renvoie un jeton de réussite à la machine `dr-orchestrator-stepfunction-FAILOVER` d'état.
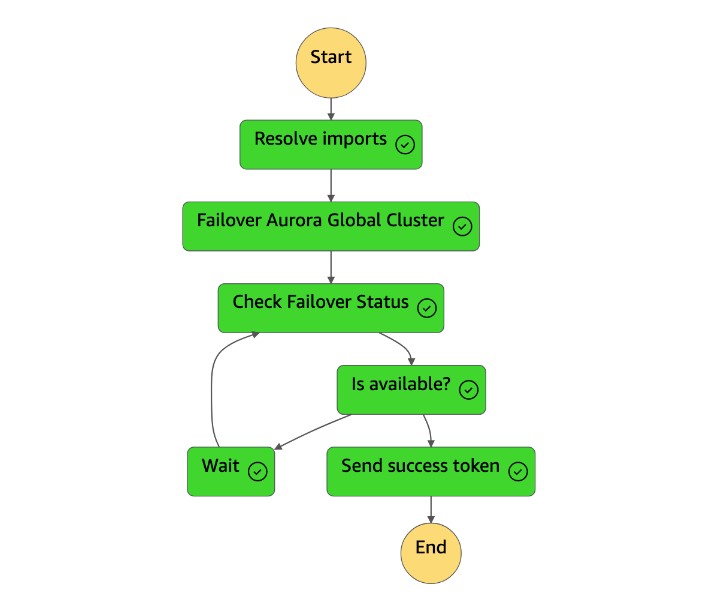
1. La machine à `dr-orchestrator-stepfunction-FAILOVER` états est terminée.
Sur la console, le rôle du **cluster secondaire (`dbcluster-02`) est désormais le cluster** **principal, et le cluster** est prêt à traiter des charges de travail en lecture/écriture. Le rôle du cluster principal d'origine (`dbcluster-01`) est désormais répertorié comme **cluster secondaire**.
### Basculement manuel non planifié
Dans de rares cas, votre base de données globale Aurora peut rencontrer une panne inattendue dans sa base de données principale Région AWS. Si cela se produit, votre cluster de base de données Aurora principal et son nœud de scripteur ne sont pas disponibles, et la réplication entre le cluster principal et les clusters secondaires s'interrompt. Pour minimiser à la fois les temps d'arrêt (RTO) et les pertes de données (RPO), effectuez rapidement un basculement entre régions et reconstruisez votre base de données globale Aurora. Pour plus d'informations, consultez [Restaurer une base de données globale Amazon Aurora suite à une panne imprévue](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-disaster-recovery.html#aurora-global-database-failover).
Pour effectuer un basculement imprévu, vous devez détacher votre cluster secondaire de la base de données globale Aurora. Avant d'effectuer le basculement imprévu, arrêtez les écritures d'applications sur votre cluster de base de données Aurora principal. Une fois le basculement effectué avec succès, reconfigurez l'application pour écrire sur le nouveau cluster de base de données principal. Cette approche permet d'éviter les pertes de données. Cela permet également d'éviter les incohérences dans les données si le nœud d'écriture principal revient en ligne pendant le processus de basculement.
Pour effectuer le basculement imprévu, appelez la machine d'`dr-orchestrator-stepfunction-FAILOVER`état. Pour cet exemple, le **cluster secondaire** (`db-cluster-02`*)***** se trouve dans la région DR (`us-west-2`) à l'état stable.
Pour effectuer le basculement, procédez comme suit :
1. Connectez-vous à la console.
1. Remplacez la région par la région DR (`us-west-2`).
1. Accédez à **Services**, puis sélectionnez **Step Functions**.
1. Accédez à la machine à `dr-orchestrator-stepfunction-FAILOVER` états.
1. Choisissez **Démarrer l'exécution**, puis entrez le code JSON suivant dans la `Input - optional` section, en utilisant `UnPlannedFailoverAurora` comme suit `resourceType` *:*
```
{
"StatePayload": [
{
"layer": 1,
"resources": [
{
"resourceType": "UnPlannedFailoverAurora",
"resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)",
"parameters": {
"GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier",
"DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier",
"ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region"
}
}
]
}
]
}
```
1. La machine `dr-orchestrator-stepfunction-FAILOVER` d'état lit le type de ressource `UnPlannedFailoverAuroraMySQL` et appelle la tâche `Detach Cluster from Global Database` depuis la machine `dr-orchestrator-stepfunction-unplanned-Aurora-failover` d'état.
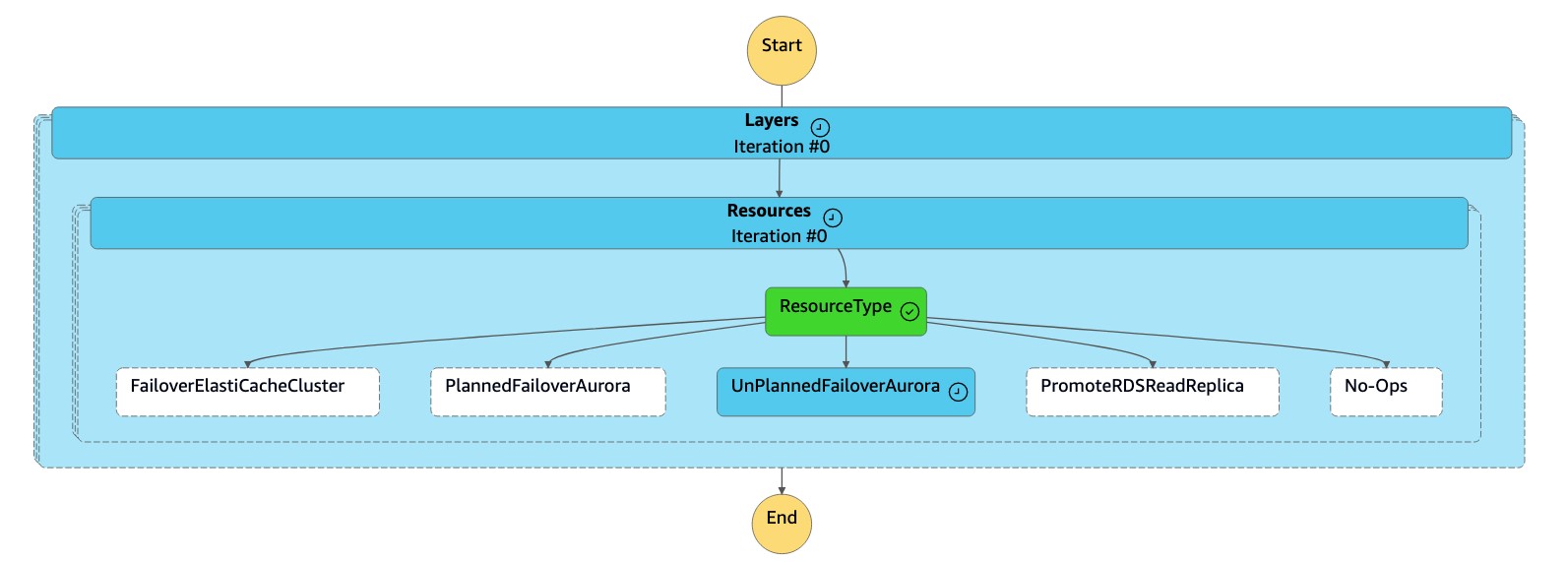
1. La `Detach Cluster from Global Database` tâche détache (supprime) le cluster secondaire de la base de données globale.
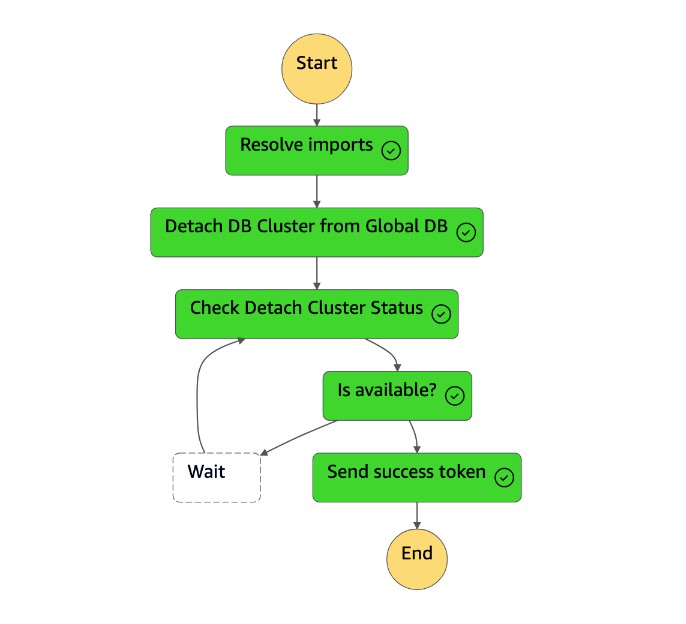
1. Le cluster secondaire (`dbcluster-02`) est promu au rang de cluster autonome, et il peut prendre en charge des charges de travail en lecture/écriture.
1. La machine à `dr-orchestrator-stepfunction-FAILOVER` états est terminée.
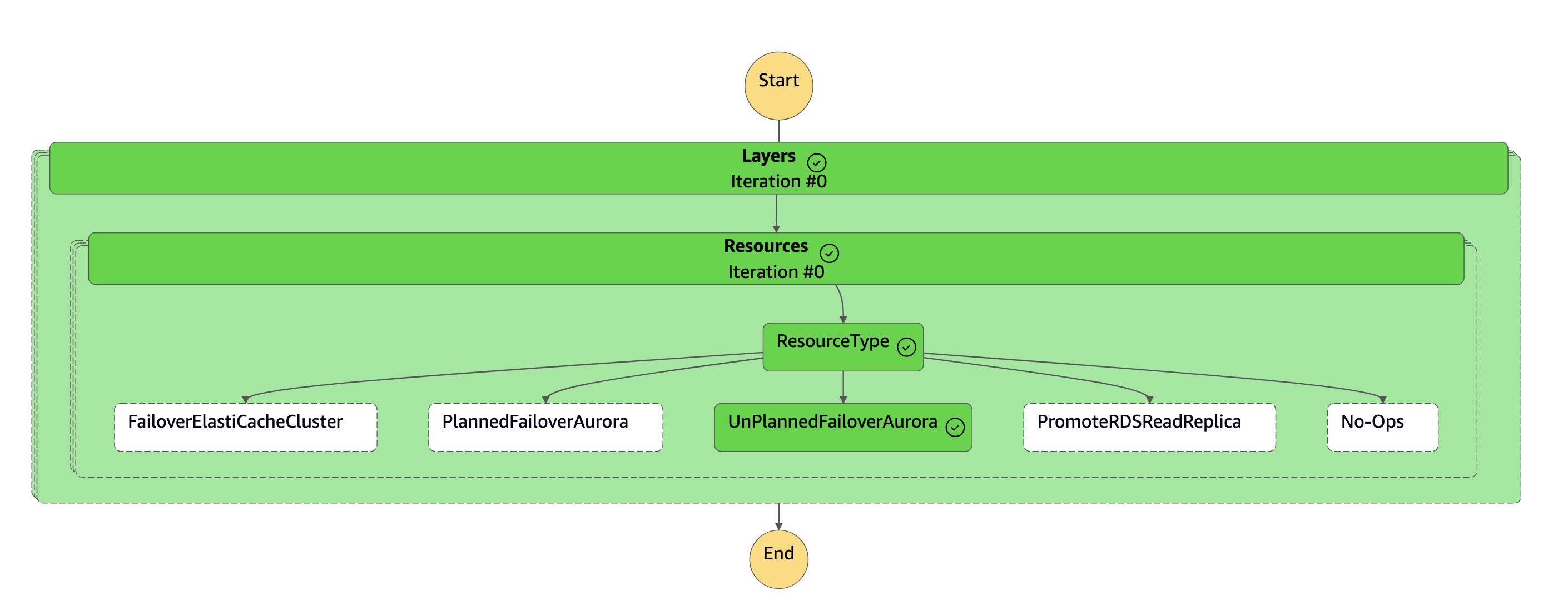
1. Le cluster secondaire (`dbcluster-02`) est détaché de la base de données globale Aurora et devient un cluster autonome pour répondre à la charge de travail de lecture/écriture.
1. Reconfigurez votre application pour envoyer toutes les opérations d'écriture à ce nouveau cluster de base de données Aurora autonome à l'aide de son nouveau point de terminaison de cluster.
## Failback
Un retour de secours ramène votre base de données à son emplacement principal d'origine (ou à son nouvel emplacement) après la résolution d'un sinistre (ou d'un événement planifié). Lorsque la panne imprévue aura été résolue, vous souhaiterez peut-être ajouter à nouveau votre ancienne région principale à la base de données mondiale Aurora. Vous devez d'abord supprimer le cluster de base de données existant de l'ancienne région principale, créer un nouveau cluster de base de données à partir de la nouvelle région principale, puis utiliser le processus de basculement planifié géré pour changer le rôle du nouveau cluster.
Cela peut être considéré comme une activité planifiée que vous pouvez effectuer en dehors des heures de pointe ou le week-end.
Vous devez [modifier manuellement le cluster de base de données Amazon Aurora](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Modifying.html) et le désactiver `DeletionProtection`**** avant d'exécuter la machine d'`DR Orchestrator FAILBACK`état depuis l'ancienne région principale (`us-east-1`), car elle a été créée avec`DeletionProtection`.
DR Orchestrator Framework utilise la machine à `dr-orchestrator-stepfunction-FAILBACK` états pour automatiser les étapes de suppression du cluster existant et de création d'un nouveau cluster dans l'ancienne région principale.
Pour le désactiver`DeletionProtection`, procédez comme suit :
1. Connectez-vous à la console.
1. Remplacez la région par l'ancienne région principale (`us-east-1`).
1. Accédez à la console Amazon RDS, sélectionnez le nom du cluster (`dbcluster-01`), puis choisissez **Modifier**.
1. Sous **Protection contre la suppression**, décochez la case **Activer la protection contre la suppression**, puis choisissez **Continuer**.
1. Choisissez **Appliquer immédiatement**, puis **Modifier le cluster**.
La machine `DR Orchestrator FAILBACK` d'état est invoquée pendant le processus de repli depuis l'ancienne région principale (`us-east-1`).
Pour effectuer le retour en arrière, procédez comme suit :
1. Connectez-vous à la console.
1. Remplacez la région par l'ancienne région principale (`us-east-1`).
1. Accédez à **Services**, puis sélectionnez **Step Functions**.
1. Accédez à la machine à `DR Orchestrator FAILBACK` états.
1. Choisissez **Démarrer l'exécution**, puis entrez le code JSON suivant dans la `Input - optional` section :
```
{
"StatePayload": [
{
"layer": 1,
"resources": [
{
"resourceType": "CreateAuroraSecondaryDBCluster",
"resourceName": "To create secondary Aurora MySQL Global Database Cluster",
"parameters": {
"GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier",
"DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier",
"DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name",
"SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier",
"DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier",
"Port": "!Import dr-globaldb-cluster-mysql-port",
"DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class",
"DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name",
"VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids",
"Engine": "!Import dr-globaldb-cluster-mysql-engine",
"EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version",
"KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId",
"SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region",
"ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region",
"BackupRetentionPeriod": "7",
"MonitoringInterval": "60",
"StorageEncrypted": "True",
"EnableIAMDatabaseAuthentication": "True",
"DeletionProtection": "True",
"CopyTagsToSnapshot": "True",
"AutoMinorVersionUpgrade": "True",
"MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole"
}
}
]
}
]
}
```
1. La machine `DR Orchestrator FAILBACK` d'état lit le type de ressource comme`CreateAuroraSecondaryDBCluster`, et elle appelle la machine `dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster` d'état.
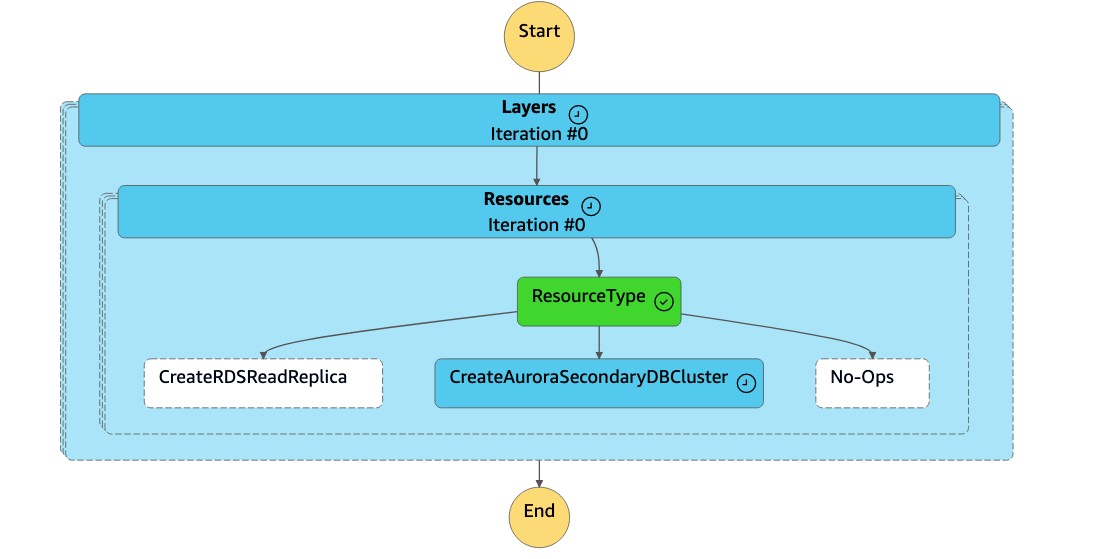
1. La machine `dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster` d'état supprime le cluster existant (`dbcluster-01`) de l'ancienne région principale (`us-east-1`).
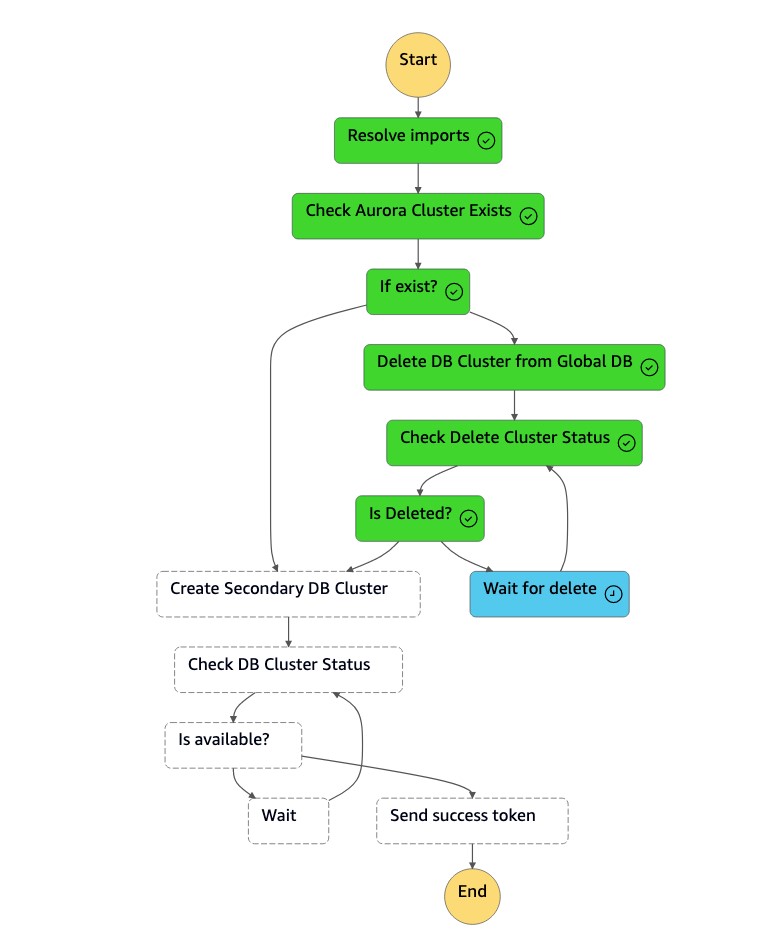
1. Une fois le cluster (`dbcluster-01`) supprimé, la machine d'état crée un nouveau cluster (`dbcluster-01`) avec l'instance de base de données, et il rejoint la base de données globale Aurora en tant que cluster secondaire pour traiter les charges de travail en lecture seule.
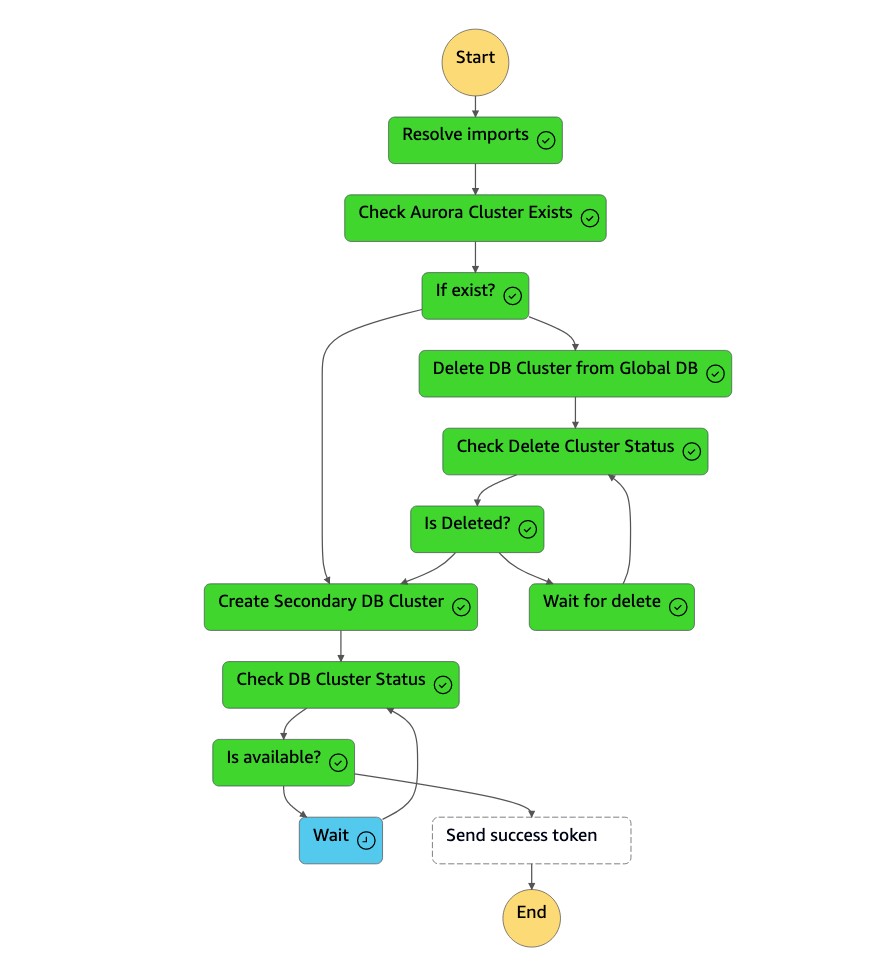
1. Une fois que le cluster secondaire est disponible, la machine d'`dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster`état est terminée et renvoie un jeton de réussite à la machine `DR Orchestrator Failback` d'état.
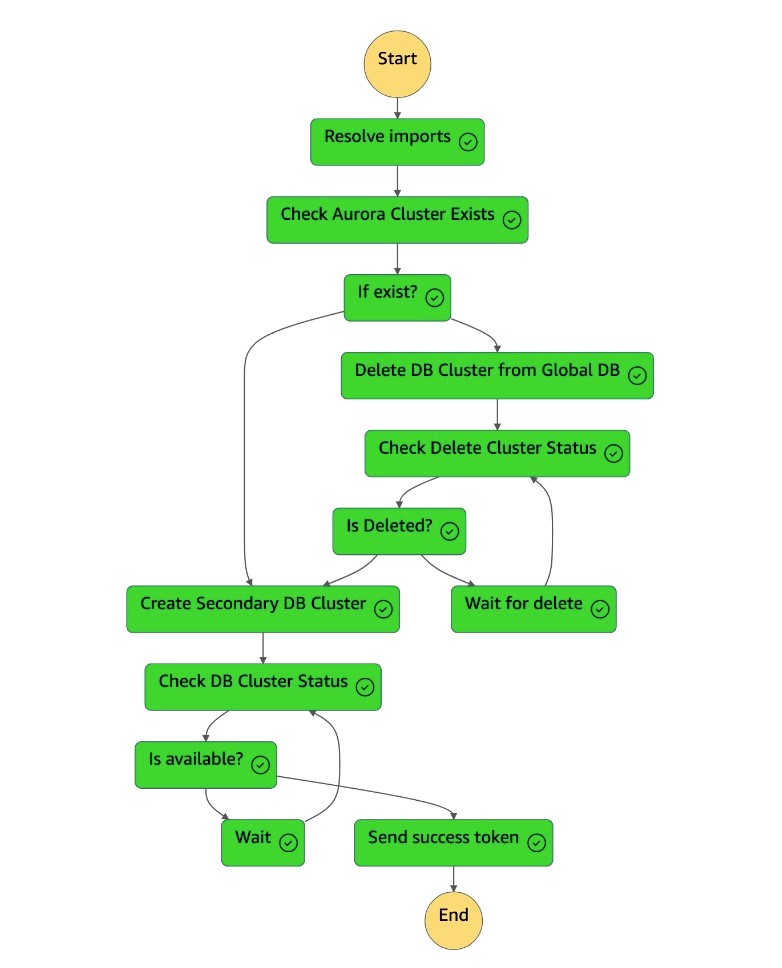
1. La machine à `dr-orchestrator-stepfunction-FAILBACK` états est terminée.
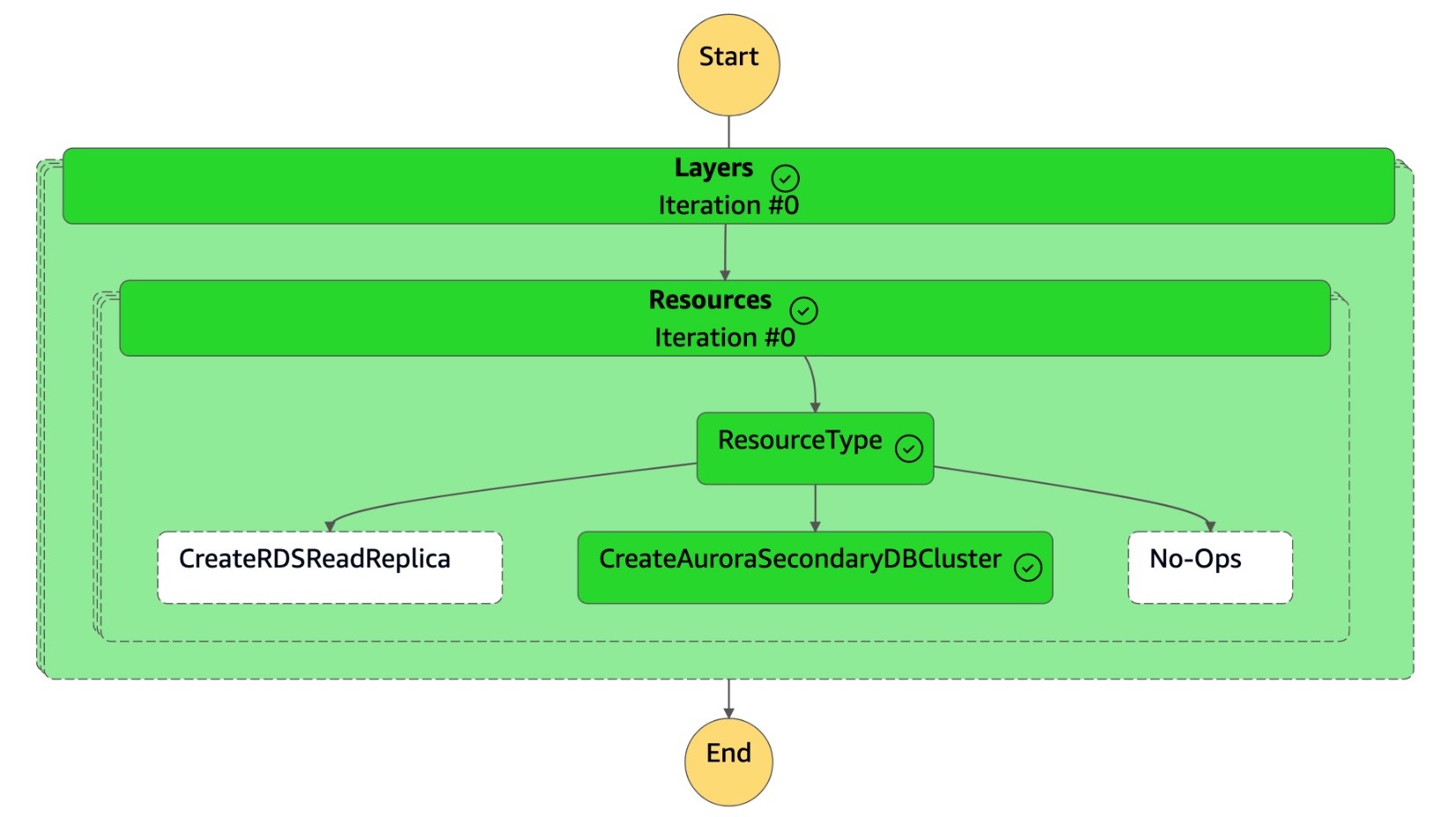
1. Vous pouvez vérifier la base de données globale Aurora sur la console Amazon RDS.
[Si vous souhaitez déplacer le cluster de base de données principal vers us-east-1, vous pouvez suivre les étapes mentionnées dans la section Switchover.](#switchover)