Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration sur place
La migration sur place élimine le besoin de réécrire tous vos fichiers de données. Au lieu de cela, les fichiers de métadonnées Iceberg sont générés et liés à vos fichiers de données existants. Cette méthode est généralement plus rapide et plus rentable, en particulier pour les grands ensembles de données ou les tables dont les formats de fichier sont compatibles, tels que Parquet, Avro et ORC.
Note
La migration sur place ne peut pas être utilisée lors de la migration vers Amazon S3 Tables.
Iceberg propose deux options principales pour mettre en œuvre la migration sur place :
-
Utiliser la procédure de capture instantanée
pour créer une nouvelle table Iceberg tout en conservant la table source inchangée. Pour plus d'informations, consultez Snapshot Table dans la documentation d'Iceberg. -
Utilisation de la procédure de migration
pour créer une nouvelle table Iceberg en remplacement de la table source. Pour plus d'informations, consultez la section Migrate Table dans la documentation d'Iceberg. Bien que cette procédure fonctionne avec Hive Metastore (HMS), elle n'est actuellement pas compatible avec le. AWS Glue Data Catalog La AWS Glue Data Catalog section Réplication de la procédure de migration des tables présentée plus loin dans ce guide fournit une solution permettant d'obtenir un résultat similaire avec le catalogue de données.
Une fois que vous avez effectué la migration sur place en utilisant l'une snapshot ou l'autre des optionsmigrate, certains fichiers de données risquent de ne pas être migrés. Cela se produit généralement lorsque les rédacteurs continuent d'écrire dans la table source pendant ou après la migration. Pour intégrer ces fichiers restants dans votre table Iceberg, vous pouvez utiliser la procédure add_files
Supposons que vous ayez une products table basée sur Parquet créée et renseignée dans Athena comme suit :
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
Les sections suivantes expliquent comment utiliser les migrate procédures snapshot et avec ce tableau.
Option 1 : procédure de capture instantanée
La snapshot procédure crée une nouvelle table Iceberg portant un nom différent mais qui reproduit le schéma et le partitionnement de la table source. Cette opération laisse la table source complètement inchangée pendant et après l'action. Il crée efficacement une copie allégée de la table, ce qui est particulièrement utile pour tester des scénarios ou explorer des données sans risquer de modifier la source de données d'origine. Cette approche permet une période de transition pendant laquelle le tableau original et le tableau Iceberg restent disponibles (voir les notes à la fin de cette section). Une fois les tests terminés, vous pouvez mettre votre nouvelle table Iceberg en production en transférant tous les rédacteurs et lecteurs vers la nouvelle table.
Vous pouvez exécuter la snapshot procédure en utilisant Spark dans n'importe quel modèle de déploiement Amazon EMR (par exemple, Amazon EMR sur EC2, Amazon EMR sur EKS, EMR Serverless) et. AWS Glue
Pour tester la migration sur place à l'aide de la procédure snapshot Spark, procédez comme suit :
-
Lancez une application Spark et configurez la session Spark avec les paramètres suivants :
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Exécutez la
snapshotprocédure pour créer une nouvelle table Iceberg pointant vers les fichiers de données de la table d'origine :spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)La trame de données de sortie contient le
imported_files_count(le nombre de fichiers ajoutés). -
Validez la nouvelle table en l'interrogeant :
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
Remarques
-
Après avoir exécuté la procédure, toute modification du fichier de données sur la table source désynchronisera la table générée. Les nouveaux fichiers que vous ajoutez ne seront pas visibles dans la table Iceberg, et les fichiers que vous avez supprimés affecteront les capacités de requête de la table Iceberg. Pour éviter les problèmes de synchronisation :
-
Si la nouvelle table Iceberg est destinée à une utilisation en production, arrêtez tous les processus qui écrivent dans la table d'origine et redirigez-les vers la nouvelle table.
-
Si vous avez besoin d'une période de transition ou si la nouvelle table Iceberg est destinée à des fins de test, consultez la section Maintien de la synchronisation des tables Iceberg après une migration sur place plus loin dans cette section pour obtenir des conseils sur la gestion de la synchronisation des tables.
-
-
Lorsque vous utilisez
snapshotcette procédure, lagc.enabledpropriété est définiefalsedans les propriétés de la table Iceberg créée. Ce paramètre interdit les actions telles queexpire_snapshotsremove_orphan_files, ouDROP TABLEavec l'PURGEoption, qui supprimeraient physiquement des fichiers de données. Les opérations de suppression ou de fusion d'Iceberg, qui n'ont pas d'impact direct sur les fichiers source, sont toujours autorisées. -
Pour que votre nouvelle table Iceberg soit pleinement fonctionnelle, sans aucune limite quant aux actions de suppression physique de fichiers de données, vous pouvez modifier la propriété de la
gc.enabledtable sur.trueToutefois, ce paramètre autorise les actions qui ont un impact sur les fichiers de données source, ce qui pourrait altérer l'accès à la table d'origine. Par conséquent, modifiez lagc.enabledpropriété uniquement si vous n'avez plus besoin de conserver les fonctionnalités de la table d'origine. Par exemple :spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
Option 2 : procédure de migration
La migrate procédure crée une nouvelle table Iceberg portant le même nom, le même schéma et le même partitionnement que la table source. Lorsque cette procédure s'exécute, elle verrouille la table source et la renomme en <table_name>_BACKUP_ (ou en un nom personnalisé spécifié par le paramètre de backup_table_name procédure).
Note
Si vous définissez le paramètre de drop_backup procédure surtrue, la table d'origine ne sera pas conservée en tant que sauvegarde.
Par conséquent, la procédure de migrate table exige que toutes les modifications affectant la table source soient arrêtées avant que l'action ne soit exécutée. Avant d'exécuter la migrate procédure :
-
Arrêtez tous les rédacteurs qui interagissent avec la table source.
-
Modifiez les lecteurs et les rédacteurs qui ne supportent pas Iceberg de manière native pour activer le support Iceberg.
Par exemple :
-
Athéna continue de travailler sans modification.
-
Spark nécessite :
-
Fichiers Iceberg Java Archive (JAR) à inclure dans le chemin de classe (voir les sections Travailler avec Iceberg dans Amazon EMR et Travailler avec Iceberg AWS Glue dans les sections précédentes de ce guide).
-
Les configurations de catalogue de session Spark suivantes (
SparkSessionCatalogà utiliser pour ajouter la prise en charge d'Iceberg tout en conservant les fonctionnalités de catalogue intégrées pour les tables autres qu'Iceberg) :-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Après avoir exécuté la procédure, vous pouvez redémarrer vos rédacteurs avec leur nouvelle configuration Iceberg.
Actuellement, la migrate procédure n'est pas compatible avec le AWS Glue Data Catalog, car le catalogue de données ne prend pas en charge l'RENAMEopération. Par conséquent, nous vous recommandons d'utiliser cette procédure uniquement lorsque vous travaillez avec Hive Metastore. Si vous utilisez le catalogue de données, consultez la section suivante pour une autre approche.
Vous pouvez exécuter la migrate procédure sur tous les modèles de déploiement Amazon EMR (Amazon EMR sur EC2, Amazon EMR sur EKS, EMR sans serveur), mais elle nécessite une connexion configurée à Hive Metastore AWS Glue. Amazon EMR sur EC2 est le choix recommandé car il fournit une configuration Hive Metastore intégrée, ce qui minimise la complexité de l'installation.
Pour tester la migration sur place à l'aide de la procédure migrate Spark à partir d'un cluster Amazon EMR sur EC2 configuré avec Hive Metastore, procédez comme suit :
-
Lancez une application Spark et configurez la session Spark pour utiliser l'implémentation du catalogue Iceberg Hive. Par exemple, si vous utilisez la
pysparkCLI :pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Créez une
productstable dans Hive Metastore. Il s'agit de la table source, qui existe déjà dans une migration classique.-
Créez la table Hive
productsexterne dans Hive Metastore pour pointer vers les données existantes dans Amazon S3 :spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
Ajoutez les partitions existantes à l'aide de la
MSCK REPAIR TABLEcommande :spark.sql(f""" MSCK REPAIR TABLE products """ ) -
Vérifiez que la table contient des données en exécutant une
SELECTrequête :spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)Exemple de sortie :

-
-
Utilisez la
migrateprocédure Iceberg :df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()La trame de données de sortie contient
migrated_files_count(le nombre de fichiers ajoutés à la table Iceberg) :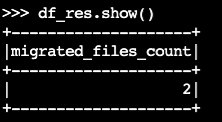
-
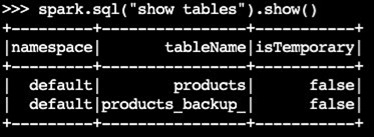
Vérifiez que la table de sauvegarde a été créée :
spark.sql("show tables").show()Exemple de sortie :
-
Validez l'opération en interrogeant la table Iceberg :
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
Remarques
-
Une fois la procédure exécutée, tous les processus actuels qui interrogent ou écrivent dans la table source seront affectés s'ils ne sont pas correctement configurés avec le support d'Iceberg. Nous vous recommandons donc de suivre les étapes suivantes :
-
Arrêtez tous les processus en utilisant la table source avant la migration.
-
Effectuez la migration.
-
Réactivez les processus en utilisant les paramètres Iceberg appropriés.
-
-
Si des modifications de fichiers de données se produisent pendant le processus de migration (de nouveaux fichiers sont ajoutés ou des fichiers sont supprimés), la table générée sera désynchronisée. Pour les options de synchronisation, voir Maintien de la synchronisation des tables Iceberg après une migration sur place plus loin dans cette section.
Réplication de la procédure de migration des tables dans AWS Glue Data Catalog
Vous pouvez reproduire le résultat de la procédure de migration dans AWS Glue Data Catalog (en sauvegardant la table d'origine et en la remplaçant par une table Iceberg) en procédant comme suit :
-
Utilisez la procédure de capture instantanée pour créer une nouvelle table Iceberg pointant vers les fichiers de données de la table d'origine.
-
Sauvegardez les métadonnées de la table d'origine dans le catalogue de données :
-
Utilisez l'GetTableAPI pour récupérer la définition de la table source.
-
Utilisez l'GetPartitionsAPI pour récupérer la définition de la partition de table source.
-
Utilisez l'CreateTableAPI pour créer une table de sauvegarde dans le catalogue de données.
-
Utilisez l'BatchCreatePartitionAPI CreatePartitionor pour enregistrer des partitions dans la table de sauvegarde du catalogue de données.
-
-
Modifiez la propriété de la table
gc.enabledIcebergfalsepour activer les opérations complètes de la table. -
Supprimez la table d’origine.
-
Localisez le fichier JSON des métadonnées de la table Iceberg dans le dossier de métadonnées situé à la racine de la table.
-
Enregistrez la nouvelle table dans le catalogue de données en utilisant la procédure register_table
avec le nom de table d'origine et l'emplacement du metadata.jsonfichier créé par la procédure :snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
Maintien de la synchronisation des tables Iceberg après la migration sur place
La add_files procédure fournit un moyen flexible d'intégrer les données existantes dans les tables Iceberg. Plus précisément, il enregistre les fichiers de données existants (tels que les fichiers Parquet) en référençant leurs chemins absolus dans la couche de métadonnées d'Iceberg. Par défaut, la procédure ajoute des fichiers provenant de toutes les partitions de table à une table Iceberg, mais vous pouvez ajouter des fichiers provenant de partitions spécifiques de manière sélective. Cette approche sélective est particulièrement utile dans plusieurs scénarios :
-
Lorsque de nouvelles partitions sont ajoutées à la table source après la migration initiale.
-
Lorsque des fichiers de données sont ajoutés ou supprimés de partitions existantes après la migration initiale. Toutefois, pour ajouter à nouveau des partitions modifiées, il faut d'abord les supprimer. De plus amples informations à ce sujet sont fournies plus loin dans cette section.
Voici quelques considérations relatives à l'utilisation de la add_file procédure une fois la migration sur place (snapshotoumigrate) effectuée, afin de maintenir la synchronisation de la nouvelle table Iceberg avec les fichiers de données sources :
-
Lorsque de nouvelles données sont ajoutées à de nouvelles partitions de la table source, utilisez la
add_filesprocédure avec lapartition_filterpossibilité d'intégrer de manière sélective ces ajouts dans la table Iceberg :spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)ou :
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
La
add_filesprocédure recherche les fichiers dans l'ensemble de la table source ou dans des partitions spécifiques lorsque vous spécifiez l'partition_filteroption, et tente d'ajouter tous les fichiers trouvés dans la table Iceberg. Par défaut, la propriété decheck_duplicate_filesprocédure est définie surtrue, ce qui empêche l'exécution de la procédure si des fichiers existent déjà dans la table Iceberg. Ceci est important car il n'existe aucune option intégrée permettant d'ignorer les fichiers ajoutés précédemment, et la désactivationcheck_duplicate_filesentraînera l'ajout de deux fichiers, ce qui créera des doublons. Lorsque de nouveaux fichiers sont ajoutés à la table source, procédez comme suit :-
Pour les nouvelles partitions, utilisez
add_fileswith apartition_filterpour importer uniquement les fichiers de la nouvelle partition. -
Pour les partitions existantes, supprimez d'abord la partition de la table Iceberg, puis exécutez-la
add_filesà nouveau en spécifiant le.partition_filterPar exemple :# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
Note
Chaque add_files opération génère un nouvel instantané de la table Iceberg avec des données ajoutées.
Choisir la bonne stratégie de migration sur place
Pour choisir la meilleure stratégie de migration sur place, prenez en compte les questions du tableau suivant.
Question |
Recommendation |
Explication |
|---|---|---|
Voulez-vous migrer rapidement sans réécrire les données tout en gardant les tables Hive et Iceberg accessibles à des fins de test ou de transition progressive ? |
|
Utilisez |
Utilisez-vous Hive Metastore et souhaitez-vous remplacer immédiatement votre table Hive par une table Iceberg, sans réécrire les données ? |
|
Utilisez la Remarque : Cette option est compatible avec Hive Metastore mais pas avec. AWS Glue Data Catalog Utilisez la |
Utilisez-vous AWS Glue Data Catalog et souhaitez-vous remplacer immédiatement votre table Hive par une table Iceberg, sans réécrire les données ? |
Adaptation de la |
Comportement de
Remarque : Cette option nécessite la gestion manuelle des appels d' AWS Glue API pour la sauvegarde des métadonnées. Utilisez la |
