Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Conception d'architectures d'IA sans serveur
La traduction des principes de l'IA sans serveur dans des systèmes réels nécessite une architecture réfléchie. L'objectif est de les intégrer de manière souple Services AWS dans des pipelines modulaires et intelligents qui évoluent de manière élastique et répondent en temps réel.
Cette section fournit des conseils prescriptifs sur la manière d'assembler des systèmes d'IA natifs du cloud à l'aide de services AWS sans serveur, notamment l'orchestration générative de l'IA, l'inférence en temps réel et l'informatique de pointe. Chaque modèle architectural correspond à un cas d'utilisation courant dans l'entreprise, garantissant ainsi pertinence et applicabilité.
Dans cette section :
Modèles d'architecture fondamentaux
Dans une architecture d'application traditionnelle axée sur les événements, le système est structuré en quatre couches logiques qui dissocient les préoccupations tout en garantissant évolutivité et réactivité. Au sommet, la couche d'application gère les interactions des utilisateurs et les événements de l'interface utilisateur, déclenchant souvent des événements spécifiques au domaine dans le système. APIs En dessous, la couche d'orchestration gère les flux de travail, les règles métier et le séquençage des événements à l'aide d'outils tels que des machines à états ou des flux de travail sans serveur. La couche de service contient des fonctions ou des microservices modulaires et réutilisables qui répondent aux événements et exécutent la logique de base. À la base, la couche de données est responsable de la persistance, du streaming et de l'approvisionnement en événements. La couche de données utilise des services tels que les bases de données, les magasins d'objets ou les journaux d'événements pour émettre et consommer des événements de changement. Ensemble, ces couches soutiennent une architecture faiblement couplée, évolutive et maintenable dans laquelle les événements orientent le flux dans l'ensemble de la pile.
Les systèmes d'IA sans serveur sont également composés de services faiblement couplés et pilotés par des événements qui peuvent évoluer, évoluer et récupérer indépendamment. Pour concevoir ces systèmes de manière cohérente et évolutive, il est essentiel de considérer l'architecture comme cinq couches distinctes. Chaque couche remplit une fonction spécifique et correspond directement à une couche spécialement conçue Services AWS. Le schéma suivant montre chaque couche.
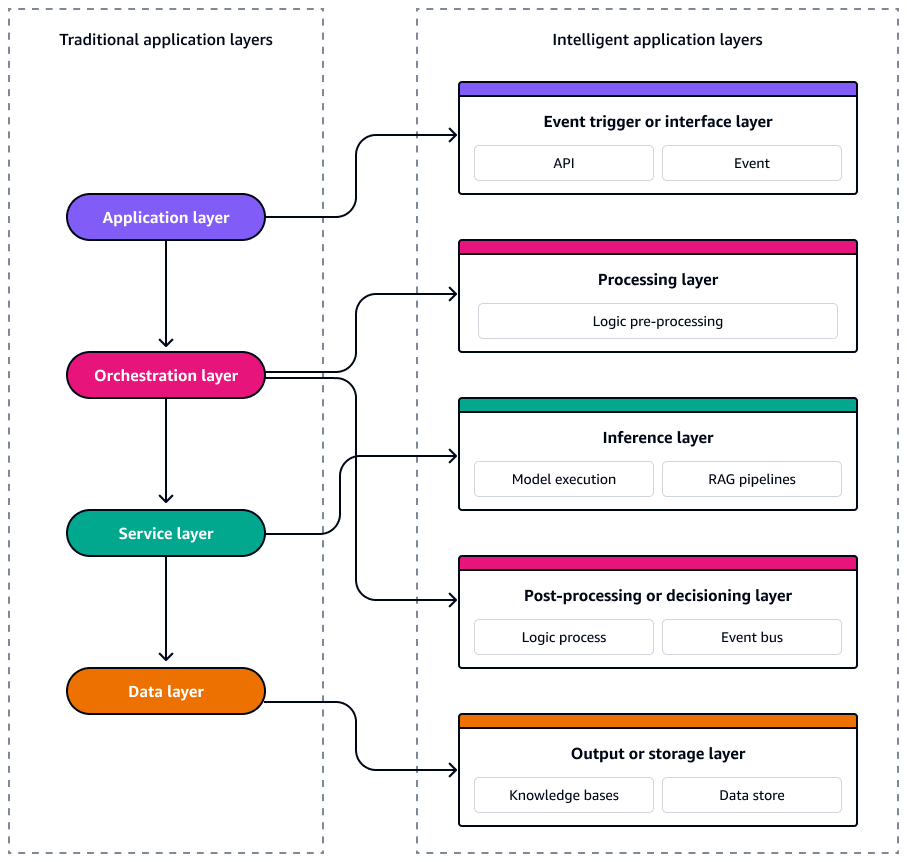
Ces cinq couches constituent le modèle pour créer des applications intelligentes, axées sur les événements, résilientes, observables et optimisées en termes de coûts et de performances.
Déclencheur d'événements ou couche d'interface
Le déclencheur d'événements ou la couche d'interface est le point d'entrée de votre système d'IA sans serveur. Il capture les interactions des utilisateurs, les événements système ou les modifications des données et les émet sous forme d'événements structurés dans l'architecture. Il permet une orchestration asynchrone et dissocie les entrées en amont de la logique de traitement en aval.
Les responsabilités de la couche de déclenchement d'événements sont les suivantes :
-
Capturez les actions des utilisateurs telles que les clics, les messages et les téléchargements
-
Émettre des événements de domaine ou des notifications de modification
-
Normaliser les données entrantes pour une consommation en aval
Services AWS qui sont couramment utilisés avec cette couche sont les suivants :
-
Amazon API Gateway accepte les entrées utilisateur via REST ou WebSocket APIs.
-
Amazon EventBridge achemine les événements internes ou externes à l'aide d'un registre de schémas.
-
Amazon Simple Storage Service (Amazon S3) se déclenche lors de la création d'objets tels que le téléchargement de documents et de fichiers multimédia.
-
Amazon Kinesis et Amazon Managed Streaming for Apache Kafka (Amazon MSK) ingèrent des événements de streaming à grande échelle.
Exemple : une demande d'assistance client soumise via un formulaire Web déclenche une EventBridge règle, initiant un flux de travail d'agent Amazon Bedrock en aval.
Couche de traitement
La couche de traitement transforme ou enrichit les données avant de les transmettre au modèle d'IA. Il gère les tâches de prétraitement telles que la validation des entrées, le formatage, le balisage des métadonnées, la détection de la langue et l'enrichissement des données à l'aide de tables de recherche ou externes. APIs
Les responsabilités de la couche de traitement sont les suivantes :
-
Validez et normalisez les entrées brutes.
-
Extrayez ou injectez des métadonnées telles que la langue et l'identifiant client.
-
Logique de routage ou de branche basée sur les attributs des données.
Services AWS qui sont couramment utilisés avec cette couche sont les suivants :
-
AWS Lambdaest un calcul sans état piloté par les événements pour la logique de transformation.
-
AWS Step Functionsorchestrer des tâches de prétraitement en plusieurs étapes.
-
Amazon Comprehend propose la détection du langage, la reconnaissance d'entités ou l'analyse des sentiments dans le cadre du prétraitement.
Exemple : les demandes d'assurance téléchargées sont scannées pour détecter les informations personnelles identifiables (PII) et le type de document à l'aide de Lambda et Amazon Comprehend avant d'être résumées par l'IA.
Couche d'inférence
En tant que cœur du système d'IA, la couche d'inférence exécute l'inférence de l'apprentissage automatique (ML) ou du modèle de base (FM). Il peut inclure un ou plusieurs modèles (génératif, prédictif ou de classification) selon le cas d'utilisation.
Les responsabilités de la couche d'inférence sont les suivantes :
-
Exécutez l'inférence du modèle ML ou FM.
-
Générez des prédictions, des classifications ou du contenu généré.
-
Intégrez le contexte de génération augmentée de récupération (RAG) le cas échéant.
Services AWS qui sont couramment utilisés avec cette couche sont les suivants :
-
Amazon Bedrock fournit une inférence de modèles de base (texte, image, multimodal) provenant de fournisseurs tels qu'Anthropic, Amazon (pour Amazon Nova) Meta et. Mistral
-
Amazon SageMaker Serverless Inference exécute des modèles de machine learning personnalisés à grande échelle.
-
Amazon Bedrock Agents propose un raisonnement basé sur de grands modèles linguistiques (LLM) et une orchestration basée sur les objectifs.
Exemple : un agent Amazon Bedrock utilise Amazon Nova Pro pour générer une réponse à une demande d'assistance complexe, basée sur les connaissances de l'entreprise à l'aide de RAG.
Couche de post-traitement ou de prise de décision
La couche de post-traitement ou de prise de décision affine ou agit sur les résultats d'inférence. Il peut formater la réponse, enregistrer les résultats, invoquer des actions en aval ou prendre des décisions en fonction de la confiance du modèle, des classifications ou des règles commerciales externes.
Les responsabilités de la couche de post-traitement ou de prise de décision sont les suivantes :
-
Formatez la sortie AI pour les systèmes ou les écrans en aval.
-
Déclenchez une logique ou un appel conditionnel APIs.
-
Transférez les données enrichies à des fins de stockage ou d'analyse.
Services AWS qui sont couramment utilisés avec cette couche sont les suivants :
-
Lambda peut formater les résultats, appliquer des transformations ou appeler. APIs
-
Amazon Simple Notification Service (Amazon SNS) et EventBridge émet d'autres événements en fonction des résultats du modèle.
-
Step Functions applique une logique de chaîne, par exemple en intensifiant le dossier d'assistance si le sentiment est synonyme de « colère ».
Exemple : une recommandation de produit issue d'un LLM est validée par rapport à un inventaire en temps réel à l'aide d'une fonction Lambda avant que la recommandation ne soit envoyée à l'utilisateur.
Couche de sortie ou de stockage
Enfin, la couche de sortie ou de stockage gère la transmission des résultats aux utilisateurs ou aux systèmes et conserve les sorties structurées pour les audits, les analyses ou les boucles de rétroaction.
Les responsabilités de la couche de sortie ou de stockage sont les suivantes :
-
Renvoyez les résultats de l'IA aux utilisateurs finaux via APIs ou UIs.
-
Conservez les sorties structurées et les journaux.
-
Alimentez les lacs de données ou les pipelines de reconversion.
Services AWS qui sont couramment utilisés avec cette couche sont les suivants :
-
Amazon S3 stocke les journaux d'inférence, les résumés ou le contenu généré.
-
Amazon DynamoDB fournit un stockage clé-valeur à faible latence pour les sorties d'IA spécifiques à une session.
-
Amazon OpenSearch Service fournit des résultats structurés par index pour la recherche et l'analyse.
-
API Gateway et WebSocket APIs fournit des réponses de retour aux clients frontaux ou mobiles.
Exemple : le résumé d'un document juridique, généré par Amazon Bedrock, est stocké dans Amazon S3 et indexé dans OpenSearch Service pour permettre une recherche sémantique dans les entreprises.
Considérations relatives à la conception selon les couches
Les principales considérations et modèles de conception suivants s'appliquent à toutes les couches architecturales :
-
Résilience — Chaque couche doit échouer et réessayer indépendamment (par exemple, files d'attente contenant des lettres mortes () DLQs sur Lambda).
-
Observabilité : envoyez des journaux, des traces et des métriques structurés à Amazon CloudWatch pour chaque étape afin de détecter les dérives comportementales.
-
Sécurité — Utilisez la séparation des rôles Gestion des identités et des accès AWS(IAM) et AWS Key Management Service(AWS KMS) pour le chiffrement des données entre les couches.
-
Optimisation des coûts : utilisez l'exécution asynchrone dans la mesure du possible et choisissez des modèles de taille adaptée.
-
Extensibilité — La conception modulaire permet de remplacer ou de mettre à niveau les services indépendamment.
Ces cinq couches forment une architecture de référence modulaire, évolutive et sans serveur pour les charges de travail basées sur l'IA. AWS Chaque couche peut être développée, déployée et optimisée indépendamment, ce qui permet une itération rapide, l'excellence opérationnelle et une séparation claire des préoccupations entre les domaines d'activité.
En utilisant ce modèle en couches comme échafaudage de conception, les entreprises peuvent standardiser leur approche de l'IA sans serveur et accélérer le passage du prototype à la production en toute confiance.
Considérations relatives à la conception architecturale
L'architecture d'IA sans serveur activée vous AWS permet de créer des applications intelligentes modulaires, évolutives et adaptées à la production. Que vous déployiez des modèles à la périphérie, que vous orchestriez des pipelines d'inférence en plusieurs étapes ou que vous créiez des assistants d'IA génératifs, Services AWS vous pouvez alimenter la prochaine génération d'applications natives de l'IA.
Lorsque vous concevez une architecture d'IA sans serveur, gardez à l'esprit les principaux objectifs de conception et les meilleures pratiques suivants :
-
Sécurité : utilisez des rôles IAM précis, chiffrez les invites et les sorties, et limitez l'accès aux API.
-
Observabilité — Intégrez CloudWatch et AWS X-Ray personnalisez les journaux pour chaque étape du pipeline.
-
Évolutivité : utilisez uniquement des composants sans serveur, tels que Lambda, Amazon Bedrock et Serverless Inference. SageMaker
-
Latence — Tirez parti de Lambda @Edge, de la simultanéité provisionnée ou de l'inférence asynchrone.
-
Modularité — Concevez des pipelines à l'aide de déclencheurs d'événements et de fonctions isolées pour chaque tâche.
-
Réutilisabilité — Paramétrez les invites, utilisez des couches Lambda partagées et découplez la logique à l'aide de Step Functions.
