Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Techniques d’invite de compréhension visuelle
Note
Cette documentation concerne la version 1 d'Amazon Nova. Pour plus d'informations sur la manière de favoriser la compréhension multimodale dans Amazon Nova 2, consultez Proposer des entrées multimodales.
Les techniques d’invite visuelle suivantes vous aideront à créer de meilleures invites pour Amazon Nova.
Rubriques
L’emplacement est important
Nous vous recommandons de placer les fichiers multimédias (tels que les images ou les vidéos) avant d’ajouter des documents, puis votre texte d’instructions ou vos invites pour guider le modèle. Bien que les images placées après le texte ou intercalées avec le texte fonctionnent toujours correctement, si le cas d’utilisation le permet, la structure {media_file}-then-{text} est l’approche préférée.
Le modèle suivant peut être utilisé pour placer les fichiers multimédias avant le texte lors de la compréhension visuelle.
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
Pas de structure suivie |
Invite optimisée |
|
|---|---|---|
Utilisateur |
Expliquez ce qui se passe dans l’image [Image1.png] |
[Image1.png] Expliquez ce qui se passe dans l’image ? |
Plusieurs fichiers multimédias avec des composants visuels
Dans les situations où vous fournissez plusieurs fichiers multimédias au fil des tours, présentez chaque image avec une étiquette numérotée. Par exemple, si vous utilisez deux images, étiquetez-les Image
1: et Image 2:. Si vous utilisez trois vidéos, étiquetez-les Video
1:, Video 2: et Video 3:. Vous n’avez pas besoin d’ajouter de sauts de ligne entre les images ou entre les images et l’invite.
Le modèle suivant peut être utilisé pour placer plusieurs fichiers multimédias :
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
Invite non optimisée |
Invite optimisée |
|---|---|
|
Décrivez ce que vous voyez dans la deuxième image. [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] Décrivez ce que vous voyez dans la deuxième image. |
|
La deuxième image est-elle décrite dans le document joint ? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] La deuxième image est-elle décrite dans le document joint ? |
En raison de la longueur des jetons de contexte des types de fichiers multimédias, l’invite système indiquée au début de l’invite peut ne pas être respectée dans certains cas. Dans ce cas, nous vous recommandons de déplacer toutes les instructions système vers les tours de l’utilisateur et de suivre les conseils généraux de {media_file}-then-{text}. Cela n’a aucune incidence sur les invites système avec RAG, les agents ou l’utilisation des outils.
Utilisez les instructions utilisateur pour améliorer le suivi des instructions pour les tâches de compréhension visuelle
Pour la compréhension vidéo, le nombre de jetons dans le contexte rend les recommandations dans L’emplacement est important très importantes. Utilisez l’invite système pour des éléments plus généraux tels que le ton et le style. Nous vous recommandons de conserver les instructions relatives à la vidéo dans l’invite utilisateur pour de meilleures performances.
Le modèle suivant peut être utilisé pour améliorer les instructions :
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
Tout comme pour le texte, nous vous recommandons d' chain-of-thoughtutiliser des images et des vidéos pour améliorer les performances. Nous vous recommandons également de placer les chain-of-thought directives dans l'invite du système, tout en conservant les autres instructions dans l'invite de l'utilisateur.
Important
Le modèle Amazon Nova Premier est un modèle d’intelligence supérieure de la famille Amazon Nova, capable de traiter des tâches plus complexes. Si vos tâches nécessitent une chain-of-thought réflexion approfondie, nous vous recommandons d'utiliser le modèle d'invite fourni dans Give Amazon Nova time to think (chain-of-thought). Cette approche peut contribuer à améliorer les capacités d’analyse et de résolution de problèmes du modèle.
Quelques exemples de plans
Tout comme pour les modèles de texte, nous vous recommandons de fournir des exemples d'images pour améliorer les performances de compréhension des images (les exemples de vidéos ne peuvent pas être fournis en raison des single-video-per-inference limites). Nous vous recommandons de placer les exemples dans l’invite utilisateur, après le fichier multimédia, plutôt que de les fournir dans l’invite système.
| 0-Shot | 2 coups | |
|---|---|---|
| Utilisateur | [Image 1] | |
| Assistant | Description de l'image 1 | |
| Utilisateur | [Image 2] | |
| Assistant | Description de l'image 2 | |
| Utilisateur | [Image 3] Expliquez ce qui se passe dans l’image |
[Image 3] Expliquez ce qui se passe dans l’image |
Détection des cadres
Si vous devez identifier les coordonnées du cadre de sélection d’un objet, vous pouvez utiliser le modèle Amazon Nova pour générer des cadres de sélection à l’échelle [0, 1000). Une fois ces coordonnées obtenues, vous pouvez les redimensionner en fonction des dimensions de l’image dans le cadre d’une étape de post-traitement. Pour plus d’informations sur la manière de réaliser cette étape de post-traitement, veuillez vous reporter au bloc-notes Amazon Nova Image Grounding
Voici un exemple d’invite pour la détection de cadres de sélection :
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
Sorties ou style plus riches
La sortie de compréhension vidéo peut être très courte. Si vous voulez des résultats plus longs, nous vous recommandons de créer un persona pour le modèle. Vous pouvez demander à ce persona de répondre de la manière souhaitée, comme si vous utilisiez le rôle système.
D’autres modifications des réponses peuvent être apportées à l’aide des techniques one-shot et few-shot. Fournissez des exemples de ce que devrait être une bonne réponse et le modèle pourra en imiter certains aspects lors de la génération des réponses.
Extraire le contenu d’un document dans Markdown
Amazon Nova Premier démontre des capacités améliorées pour comprendre les graphiques intégrés dans les documents et la capacité de lire et de comprendre le contenu de domaines complexes tels que les articles scientifiques. De plus, Amazon Nova Premier affiche des performances améliorées lors de l’extraction du contenu des documents et peut produire ces informations aux formats Markdown Table et Latex.
L’exemple suivant fournit un tableau dans une image, ainsi qu’une invite pour qu’Amazon Nova Premier convertisse le contenu de l’image en un tableau Markdown. Une fois le Markdown (ou la représentation Latex) créé, vous pouvez utiliser des outils pour convertir le contenu en JSON ou en une autre sortie structurée.
Make a table representation in Markdown of the image provided.
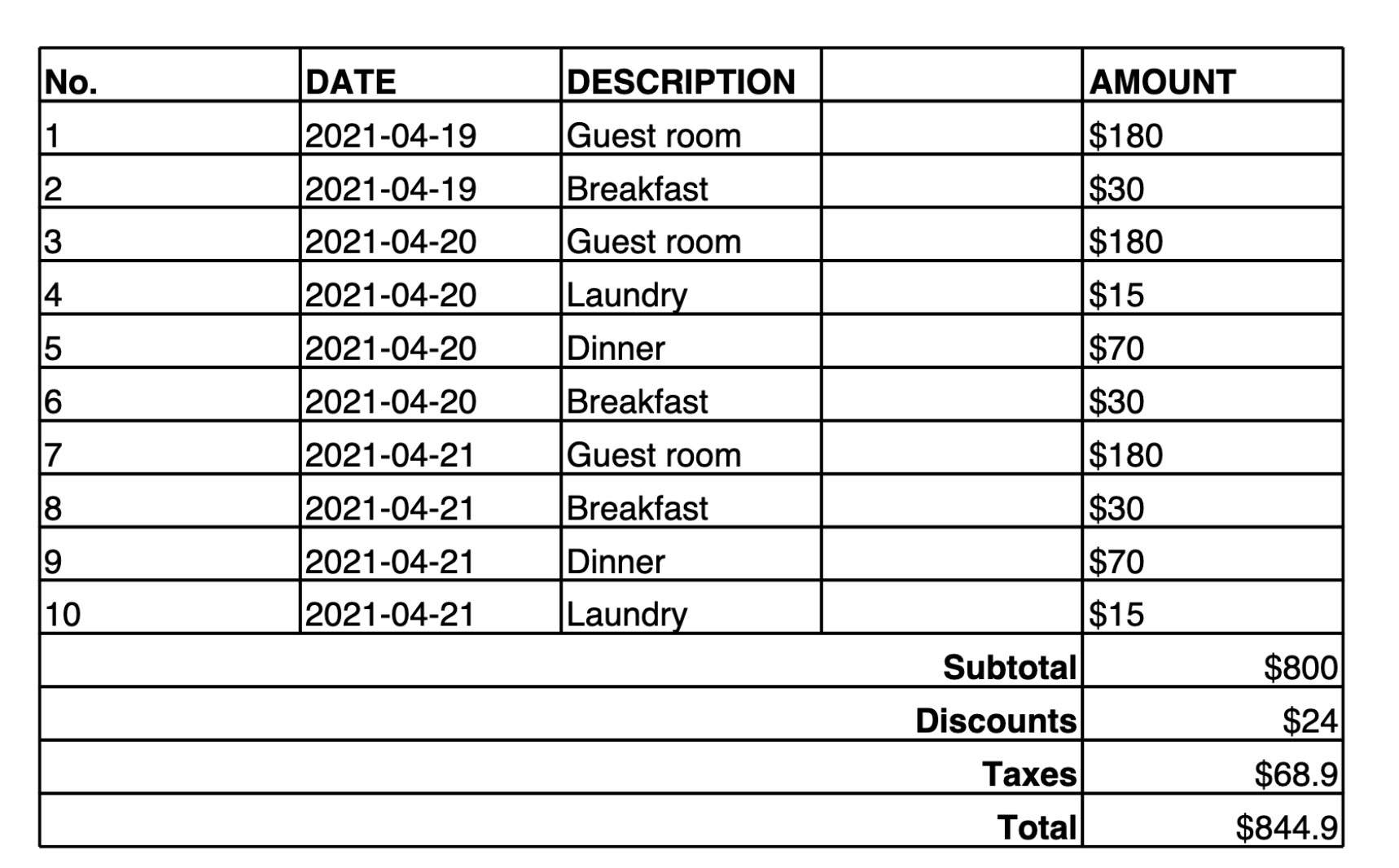
Voici la sortie fournie par le modèle :
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
Cette sortie utilise une notation de tableau personnalisée où || est utilisé comme séparateur de colonnes et && comme séparateur de lignes.
Paramètres d’inférence pour la compréhension visuelle
Pour les cas d’utilisation liés à la compréhension visuelle, nous vous recommandons de commencer avec les paramètres d’inférence temperature définis sur 0 et topK définis sur 1. Après avoir observé la sortie du modèle, vous pouvez ajuster les paramètres d’inférence en fonction du cas d’utilisation. Ces valeurs dépendent généralement de la tâche et de la variance requise. Augmentez le paramètre de température pour induire davantage de variations dans les réponses.
Classification des vidéos
Pour trier efficacement le contenu vidéo dans les catégories appropriées, fournissez des catégories que le modèle peut utiliser pour la classification. Veuillez considérer l’exemple d’invite suivant :
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
Balisage des vidéos
Amazon Nova Premier présente des fonctionnalités améliorées pour la création de balises vidéo. Pour obtenir les meilleurs résultats, veuillez utiliser l’instruction suivante demandant des balises séparées par des virgules : « Utilisez des virgules pour séparer chaque balise ». Voici un exemple d’invite :
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
Sous-titrage dense des vidéos
Amazon Nova Premier présente des capacités améliorées pour fournir des sous-titres denses, c’est-à-dire des descriptions textuelles détaillées générées pour plusieurs segments de la vidéo. Voici un exemple d’invite :
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
