Avis de fin de support : le 30 juin 2027, le support d'AMS Advanced AWS prendra fin. Après le 30 juin 2027, vous ne pourrez plus accéder à la console AMS Advanced ni aux ressources AMS Advanced. Pour plus d'informations, consultez la section Fin du support d'AMS Advanced.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolution des erreurs RFC dans AMS
De nombreuses défaillances RFC de provisionnement AMS peuvent être étudiées dans la CloudFormation documentation. Voir Résolution des problèmes liés à AWS CloudFormation : résolution des erreurs
Des suggestions de résolution des problèmes supplémentaires sont fournies dans les sections suivantes.
Erreurs RFC de « gestion » dans AMS
Les types de changement de catégorie (CT) AMS « Management » vous permettent de demander l'accès aux ressources ainsi que de gérer les ressources existantes. Cette section décrit certains problèmes courants.
Erreurs d'accès RFC
Assurez-vous que le nom d'utilisateur et le nom de domaine complet que vous avez spécifiés dans la RFC sont corrects et existent dans le domaine. Pour obtenir de l'aide pour trouver votre nom de domaine complet, consultez la section Trouver votre nom de domaine complet.
Assurez-vous que l'ID de pile que vous avez spécifié pour l'accès est une EC2-related pile. Les piles telles que ELB et Amazon Simple Storage Service (S3) ne sont pas candidates aux RFC d'accès. Utilisez plutôt votre rôle d'accès en lecture seule pour accéder à ces ressources de piles. Pour obtenir de l'aide pour trouver un identifiant de pile, consultez la section Recherche d'identifiants de pile
Assurez-vous que l'identifiant de pile que vous avez fourni est correct et qu'il appartient au compte concerné.
Pour obtenir de l'aide concernant d'autres défaillances RFC d'accès, consultez la section Gestion des accès.
YouTube Vidéo : Comment lancer correctement une demande de modification (RFC) pour éviter les rejets et
Erreurs de planification RFC (manuelle) CT
La plupart des types de modifications sont ExecutionMode = automatisés, mais certains sont ExecutionMode = manuels, ce qui affecte la façon dont vous devez les planifier pour éviter une défaillance de la RFC.
Les RFC planifiées avec ExecutionMode =Manual doivent être configurées pour s'exécuter au moins 24 heures dans le futur si vous utilisez la console AMS pour créer la RFC.
AMS a pour objectif de répondre à un scanner manuel dans les huit heures et répondra dès que possible, mais l'exécution de la RFC peut prendre beaucoup plus de temps.
Utilisation des RFC avec des CT de mise à jour manuelle
Les opérations AMS rejettent Management | Other | Other RFC pour les mises à jour des piles, lorsqu'il existe un type de modification de mise à jour pour le type de pile que vous souhaitez mettre à jour.
Erreurs de suppression de pile RFC
Défaillances de la pile de suppression RFC : si vous utilisez le CT Management | Standard Stacks | Stack | Delete, vous verrez les événements détaillés dans la CloudFormation console pour la pile portant le nom de la pile AMS. Vous pouvez identifier votre pile en la comparant au nom qu'elle porte dans la console AMS. La CloudFormation console fournit plus de détails sur les causes des défaillances.
Avant de supprimer une pile, vous devez réfléchir à la manière dont elle a été créée. Si vous avez créé la pile à l'aide d'un AMS CT et que vous n'avez ni ajouté ni modifié les ressources de la pile, vous pouvez vous attendre à la supprimer sans problème. Cependant, il est conseillé de supprimer toutes les ressources ajoutées manuellement d'une pile avant de soumettre une RFC de suppression de pile à son encontre. Par exemple, si vous créez une pile à l'aide de la pile complète CT (HA Two Tier), elle inclut un groupe de sécurité, SG1. Si vous utilisez ensuite AMS pour créer un autre groupe de sécurité, SG2, et que vous référencez le nouveau SG2 dans le SG1 créé dans le cadre de la pile complète, puis que vous utilisez la pile de suppression CT pour supprimer la pile, le SG1 ne sera pas supprimé car il est référencé par SG2.
Important
La suppression de piles peut avoir des conséquences indésirables et imprévues. Pour cette raison, AMS préfère *pas* supprimer des piles ou empiler des ressources pour le compte de ses clients. Notez qu'AMS supprimera uniquement les ressources en votre nom (par le biais d'un type de modification soumis par Gestion | Autre | Autre | Mettre à jour) qu'il n'est pas possible de supprimer en utilisant le type de modification automatique approprié à supprimer. Considérations supplémentaires :
Si les ressources sont activées pour la « protection contre la suppression », AMS peut vous aider à débloquer ce type de modification en soumettant une modification de type Gestion | Autre | Autre | Mise à jour et, une fois la protection contre la suppression de la protection contre la suppression, vous pouvez utiliser le CT automatique pour supprimer cette ressource.
Si une pile contient plusieurs ressources et que vous souhaitez supprimer uniquement un sous-ensemble des ressources de la pile, utilisez le type de modification CloudFormation Update (voir CloudFormation Ingest Stack : Updating). Vous pouvez également soumettre un type de modification Gestion | Autre | Autre | Mettre à jour et les ingénieurs d'AMS peuvent vous aider à élaborer l'ensemble de modifications, si nécessaire.
Si vous rencontrez des problèmes lors de l'utilisation de l' CloudFormation Update CT en raison de dérives, AMS peut vous aider en soumettant une mise à jour Management | Other | Other | pour résoudre le problème (dans la mesure où cela est pris en charge par le CloudFormation service AWS) et en fournissant une ChangeSet que vous pouvez ensuite valider et exécuter à l'aide du CT automatisé, Management/Custom Stack/Stack From CloudFormation Template/Approve Changeset et Update.
AMS applique les restrictions ci-dessus afin de garantir l'absence de suppressions de ressources inattendues ou imprévues.
Pour plus d'informations, consultez la section Résolution des problèmes liés à AWS CloudFormation : la suppression de la pile échoue.
Erreurs DNS de mise à jour RFC
Plusieurs RFC pour mettre à jour une zone hébergée DNS peuvent échouer, parfois sans raison. La création de plusieurs RFC en même temps pour mettre à jour les zones hébergées du DNS (privées ou publiques) peut entraîner l'échec de certaines RFC car elles tentent de mettre à jour la même pile en même temps. La gestion des modifications AMS rejette ou échoue les RFC qui ne sont pas en mesure de mettre à jour une pile parce que la pile est déjà mise à jour par une autre RFC. AMS vous recommande de créer une RFC à la fois et d'attendre qu'elle aboutisse avant d'en créer une nouvelle pour la même pile.
Erreurs d'entités RFC IAM
AMS fournit un certain nombre de rôles et de profils IAM par défaut dans des comptes AMS conçus pour répondre à vos besoins. Cependant, il se peut que vous deviez demander des ressources IAM supplémentaires de temps en temps.
Le processus de soumission des RFC demandant des ressources IAM personnalisées suit le flux de travail standard pour les RFC manuels, mais le processus d'approbation inclut également un examen de sécurité pour garantir que les contrôles de sécurité appropriés sont en place. Par conséquent, le processus prend généralement plus de temps que les autres RFC manuels. Pour réduire le temps de cycle de ces RFC, veuillez suivre les instructions suivantes.
Pour plus d'informations sur ce que nous entendons par révision IAM et sur la manière dont elle correspond à nos normes techniques et à notre processus d'acceptation des risques, consultezComprendre les évaluations de sécurité RFC.
Demandes de ressources IAM courantes :
Si vous demandez une politique concernant une application majeure compatible avec le cloud, par exemple CloudEndure, consultez le fichier d'exemple de CloudEndure politique IAM préapprouvée par AMS : décompressez le fichier d'exemple de zone d'atterrissage WiGS Cloud Endure et ouvrez le
customer_cloud_endure_policy.jsonNote
Si vous souhaitez une politique plus permissive, discutez de vos besoins avec vous CloudArchitect/CSDM et obtenez, si nécessaire, un examen de sécurité AMS et une approbation avant de soumettre une RFC mettant en œuvre la politique.
Si vous souhaitez modifier une ressource déployée par AMS dans votre compte par défaut, nous vous recommandons de demander une copie modifiée de cette ressource plutôt que de modifier la ressource existante.
Si vous demandez des autorisations pour un utilisateur humain (au lieu de les associer à l'utilisateur), associez les autorisations à un rôle, puis accordez à l'utilisateur l'autorisation d'assumer ce rôle. Pour plus de détails sur cette procédure, consultez la section Accès temporaire à la console AMS Advanced.
Si vous avez besoin d'autorisations exceptionnelles pour une migration ou un flux de travail temporaire, indiquez une date de fin pour ces autorisations dans votre demande.
Si vous avez déjà discuté de l'objet de votre demande avec votre équipe de sécurité, fournissez la preuve de son approbation à votre CSDM avec le plus de détails possible.
Si AMS rejette une RFC IAM, nous fournissons une raison claire pour le rejet. Par exemple, nous pouvons rejeter une demande de création d'une politique IAM et expliquer en quoi cette politique est inappropriée. Dans ce cas, vous pouvez apporter les modifications identifiées et soumettre à nouveau la demande. Si des précisions supplémentaires sur le statut d'une demande sont nécessaires, soumettez une demande de service ou contactez votre CSDM.
La liste suivante décrit les risques typiques qu'AMS essaie d'atténuer lorsque nous examinons vos RFC IAM. Si votre RFC IAM présente l'un de ces risques, cela peut entraîner le rejet du RFC. Dans les cas où vous avez besoin d'une exception, AMS demande l'approbation de votre équipe de sécurité. Pour obtenir une telle exception, coordonnez-vous avec votre CSDM.
Note
AMS peut, pour quelque raison que ce soit, refuser toute modification des ressources IAM au sein d'un compte. Pour toute question concernant le rejet d'une RFC, contactez AMS Operations via une demande de service ou contactez votre CSDM.
Augmentation des privilèges, telle que les autorisations qui vous permettent de modifier vos propres autorisations ou de modifier les autorisations d'autres ressources du compte. Exemples :
L'utilisation
iam:PassRoleavec un autre rôle plus privilégié.Autorisation d'accéder aux politiques attach/detach IAM à partir d'un rôle ou d'un utilisateur.
Modification des politiques IAM dans le compte.
Possibilité d'effectuer des appels d'API dans le contexte de l'infrastructure de gestion.
Autorisations permettant de modifier les ressources ou les applications requises pour vous fournir les services AMS. Exemples :
Modification de l'infrastructure AMS telle que les bastions, l'hôte de gestion ou l'infrastructure EPS.
Suppression des fonctions de gestion des journaux AWS Lambda, ou des flux de journaux.
Suppression ou modification de l'application de CloudTrail surveillance par défaut.
Modification de l'Active Directory (AD) des services d'annuaire.
Désactivation des CloudWatch alarmes (CW).
Modification des principes, des politiques et des espaces de noms déployés dans le compte dans le cadre de la zone de landing zone.
Déploiement d'une infrastructure en dehors des meilleures pratiques, telles que les autorisations qui permettent la création d'une infrastructure dans un état mettant en danger la sécurité de vos informations. Exemples :
Création de compartiments S3 publics ou non chiffrés ou partage public de volumes EBS.
Le provisionnement d'adresses IP publiques.
Modification des groupes de sécurité pour permettre un accès étendu.
Des autorisations trop larges susceptibles d'avoir un impact sur les applications, telles que des autorisations susceptibles d'entraîner une perte de données, une perte d'intégrité, une configuration inappropriée ou des interruptions de service pour votre infrastructure et les applications du compte. Exemples :
Désactiver ou rediriger le trafic réseau via des API telles que
ModifyNetworkInterfaceAttributeou.UpdateRouteTableDésactivation de l'infrastructure gérée en détachant les volumes des hôtes gérés.
Les autorisations pour les services ne font pas partie de la description du service AMS et ne sont pas prises en charge par AMS.
Les services non répertoriés dans la description du service AMS ne peuvent pas être utilisés dans les comptes AMS. Pour demander de l'aide pour une fonctionnalité ou un service, veuillez contacter votre CSDM.
Autorisations qui ne répondent pas à l'objectif que vous vous êtes fixé, soit parce qu'elles sont trop généreuses, soit trop conservatrices, soit parce qu'elles ne sont pas appliquées aux bonnes ressources. Exemples :
Demande d'
s3:PutObjectautorisation d'accès à un compartiment S3 doté d'un chiffrement KMS obligatoire, sansKMS:Encryptautorisation d'accès à la clé correspondante.Autorisations relatives à des ressources qui n'existent pas dans le compte.
RFC IAM où la description de la RFC ne semble pas correspondre à la demande.
Erreurs RFC « Déploiement »
Les types de changement de catégorie (CT) AMS « Deployment » vous permettent de demander que diverses AMS-supported ressources soient ajoutées à votre compte.
La plupart des CTS AMS qui créent une ressource sont basés sur CloudFormation des modèles. En tant que client, vous avez un accès en lecture seule à tous les services AWS. Vous pouvez notamment CloudFormation identifier rapidement la CloudFormation pile qui représente votre pile en fonction de la description de la pile à l'aide de la CloudFormation console. La pile défaillante sera probablement dans l'état DELETE_COMPLETE. Une fois que vous avez identifié la CloudFormation pile, les événements vous indiqueront la ressource spécifique qui n'a pas pu être créée et pourquoi.
Utilisation de CloudFormation la documentation pour résoudre les problèmes
La plupart des RFC de provisionnement AMS utilisent un CloudFormation modèle et cette documentation peut être utile pour le dépannage. Consultez la documentation de ce CloudFormation modèle :
Défaillance de l'équilibreur de charge de l'application : AWS::ElasticLoadBalancingV2 : : LoadBalancer (Application Load Balancer)
Créer un groupe Auto Scaling AWS::AutoScaling: : AutoScalingGroup (Auto Scaling Group)
Créer un cache memcached : AWS::ElastiCache: CacheCluster (cluster de cache)
Créer un cache Redis : : AWS::ElastiCache: CacheCluster (cluster de cache)
Créer une zone hébergée DNS (utilisée avec Create DNS private/public) : AWS::Route53 : : HostedZone (zone hébergée R53)
Créer un ensemble d'enregistrements DNS (utilisé avec Create DNS private/public) : AWS::Route53 : : RecordSet (ensembles d'enregistrements de ressources)
Créez une pile EC2 : AWS : :EC2 : :Instance (Elastic Compute Cloud)
Créer un système de fichiers élastique (EFS) : AWS : :EFS : : FileSystem (système de fichiers élastique)
Créer un équilibreur de charge : AWS::ElasticLoadBalancing: : LoadBalancer (Elastic Load Balancer)
Créez une base de données RDS : AWS : :RDS : :DBInstance (base de données relationnelle)
Créez Amazon S3 : AWS : :S3 : :Bucket (service de stockage simple)
Créer une file d'attente : AWS : :SQS : :Queue (service de file d'attente simple)
RFC créant des erreurs d'AMI
Une Amazon Machine Image (AMI) est un modèle qui contient une configuration logicielle (par exemple, un système d’exploitation, un serveur d’applications et des applications). À partir d’une AMI, vous lancez une instance qui est une copie de l’AMI s’exécutant en tant que serveur virtuel dans le cloud. Les AMI sont très utiles et nécessaires pour créer des instances EC2 ou des groupes Auto Scaling ; vous devez toutefois respecter certaines exigences :
L'instance que vous spécifiez
Ec2InstanceIddoit être dans un état arrêté pour que la RFC réussisse. N'utilisez pas d'instances du groupe Auto Scaling (ASG) pour ce paramètre car l'ASG mettra fin à une instance arrêtée.Pour créer une Amazon Machine Image (AMI) AMS, vous devez commencer par une instance AMS. Avant de pouvoir utiliser l'instance pour créer l'AMI, vous devez la préparer en vous assurant qu'elle est arrêtée et dissociée de son domaine. Pour plus de détails, consultez Créer une image de machine Amazon standard à l'aide de Sysprep
Le nom que vous spécifiez pour la nouvelle AMI doit être unique dans le compte, sinon la RFC échoue. La procédure à suivre est décrite dans AMI | Create, et pour plus de détails, consultez AWS AMI Design
.
Note
Pour plus d'informations sur la préparation à la création d'AMI, voir AMI | Create.
RFC créant des erreurs EC2 ou ASG
En cas de défaillance d'EC2 ou d'ASG avec délais d'expiration, AMS vous recommande de vérifier si l'AMI utilisée est personnalisée. Si tel est le cas, reportez-vous aux étapes de création d'AMI incluses dans ce guide (voir AMI | Créer) pour vous assurer que l'AMI a été créée correctement. Une erreur courante lors de la création d'une AMI personnalisée est de ne pas suivre les étapes du guide pour renommer ou invoquer Sysprep.
RFC créant des erreurs RDS
Les défaillances d'Amazon Relational Database Service (RDS) peuvent survenir pour de nombreuses raisons, car vous pouvez utiliser de nombreux moteurs différents lorsque vous créez le RDS, et chaque moteur a ses propres exigences et limites. Avant de tenter de créer une pile AMS RDS, examinez attentivement les valeurs des paramètres AWS RDS, voir CreateDBInstance.
Pour en savoir plus sur Amazon RDS en général, y compris les recommandations relatives à la taille, consultez la documentation Amazon Relational Database Service
Les RFC créent des erreurs Amazon S3
L'une des erreurs les plus courantes lors de la création d'un compartiment de stockage S3 est le fait de ne pas utiliser un nom unique pour le compartiment. Si vous soumettez un compartiment S3 Create CT portant le même nom qu'un compartiment précédemment soumis, il échouera car un compartiment S3 portant ce nom existerait déjà BucketName. Cela sera détaillé dans la CloudFormation console, où vous verrez que l'événement stack indique que le nom du bucket est déjà utilisé.
Validation RFC et erreurs d'exécution
Les échecs RFC et les messages associés diffèrent dans les messages de sortie sur la page de détails RFC de la console AMS pour une RFC sélectionnée :
Les raisons des échecs de validation ne sont disponibles que dans le champ État
Les raisons des échecs d'exécution sont disponibles dans les champs de sortie et de statut de l'exécution.
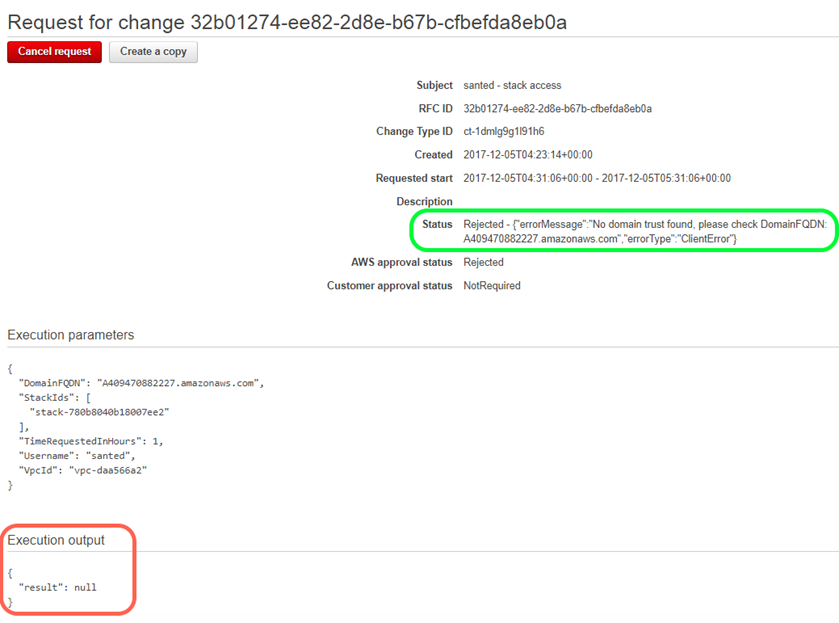
Messages d'erreur RFC
Lorsque vous rencontrez l'erreur suivante pour les types de modifications (CT) répertoriés, vous pouvez utiliser ces solutions pour vous aider à trouver la source des problèmes et à les résoudre.
{"errorMessage":"An error has occurred during RFC execution. We are investigating the issue.","errorType":"InternalError"}
Si vous avez besoin d'une assistance supplémentaire après avoir consulté les options de dépannage suivantes, contactez AMS par correspondance RFC. Pour plus d'informations, consultez Correspondance et pièce jointe RFC (console).
Erreurs d'ingestion de charge de travail (WIGS)
Note
Les outils de validation pour Windows et Linux peuvent être téléchargés et exécutés directement sur vos serveurs locaux, ainsi que sur les instances EC2 d'AWS. Vous pouvez les trouver dans le guide du développeur d'applications avancées d'AMS intitulé Migrating workloads : Linux pre-ingestion validation et Migrating workloads : Windows pre-ingestion validation.
Assurez-vous que l'instance EC2 existe dans le compte AMS cible. Par exemple, si vous avez partagé votre AMI d'un compte non-AMS vers un compte AMS, vous devrez créer une instance EC2 dans votre compte AMS avec l'AMI partagée avant de pouvoir soumettre une RFC d'ingestion de charge de travail.
Vérifiez si le trafic de sortie est autorisé pour les groupes de sécurité attachés à l'instance. L'agent SSM doit être en mesure de se connecter à son point de terminaison public.
Vérifiez si l'instance dispose des autorisations nécessaires pour se connecter à l'agent SSM. Ces autorisations sont fournies avec le
customer-mc-ec2-instance-profile, vous pouvez vérifier cela dans la console EC2 :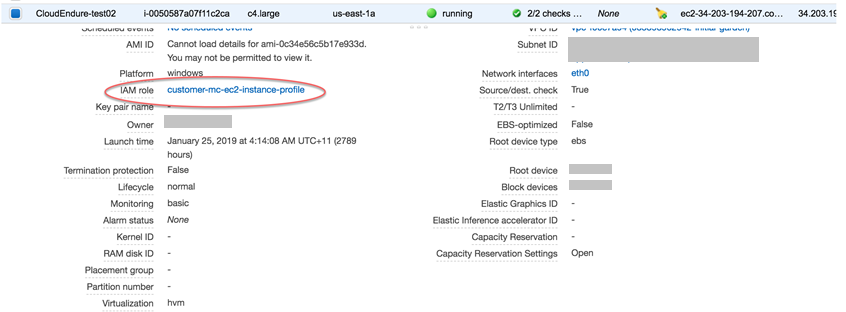
Erreurs d'arrêt de la pile d'instances EC2
Vérifiez si l'instance est déjà dans un état arrêté ou terminé.
Si l'instance EC2 est en ligne et que le
InternalErrormessage d'erreur s'affiche, soumettez une demande de service pour qu'AMS examine la situation.Notez que vous ne pouvez pas utiliser le type de changement Management | Advanced stack components | EC2 instance stack | Stop ct-3mvvt2zkyveqj pour arrêter une instance de groupe Auto Scaling (ASG). Si vous devez arrêter une instance ASG, soumettez une demande de service.
La pile d'instances EC2 crée des erreurs
Le InternalError message provient de CloudFormation ; une raison de statut CREATION_FAILED. Vous pouvez obtenir des informations détaillées sur la défaillance d'une CloudWatch pile dans les événements de pile en suivant ces étapes :
Dans la console de gestion AWS, vous pouvez consulter la liste des événements de la pile lors de la création, de la mise à jour ou de la suppression de votre pile. Recherchez dans cette liste l'événement qui a échoué, puis consultez la raison du statut correspondant.
La raison du statut peut contenir un message d'erreur provenant d'AWS CloudFormation ou d'un service spécifique qui peut vous aider à comprendre le problème.
Pour plus d'informations sur l'affichage des événements de stack, consultez la section Visualisation des données et des ressources AWS CloudFormation Stack sur l'AWS Management Console.
Erreurs de restauration du volume d'instance EC2
AMS crée une RFC de dépannage interne en cas d'échec de la restauration du volume d'instance EC2. Cela est dû au fait que la restauration du volume d'instance EC2 est un élément important de la reprise après sinistre (DR) et AMS crée automatiquement cette RFC de dépannage interne pour vous.
Lorsque le RFC de dépannage interne est créé, une bannière s'affiche vous fournissant des liens vers le RFC. Cette RFC de dépannage interne vous donne une meilleure visibilité sur les échecs RFC et, au lieu de soumettre des RFC de nouvelle tentative entraînant les mêmes erreurs, ou de vous obliger à contacter AMS manuellement en cas d'échec, vous pouvez suivre vos modifications et savoir qu'AMS est en train de remédier à l'échec. Cela réduit également le délai de restauration (TTR) nécessaire à leur modification, car les opérateurs AMS travaillent de manière proactive sur la défaillance de la RFC au lieu d'attendre votre demande.
Comment obtenir de l'aide concernant un RFC
Vous pouvez contacter AMS pour identifier la cause première de votre échec. Les heures d'ouverture d'AMS sont 24 heures par jour, 7 jours par semaine, 365 jours par an.
AMS vous propose plusieurs moyens de demander de l'aide.
Si vous avez besoin d'assistance pour une RFC ouverte ou une RFC terminée mais incorrecte, contactez AMS via une correspondance bidirectionnelle RFC. Pour plus d'informations, consultez Correspondance et pièce jointe RFC (console).
Pour signaler un problème de performance des services AWS ou AMS ayant une incidence sur votre environnement géré, utilisez la console AMS et soumettez un rapport d'incident. Pour plus de détails, consultez la section Signaler un incident. Pour des informations générales sur la gestion des incidents AMS, consultez la section Réponse aux incidents.
Pour des questions spécifiques sur la façon dont vous ou vos ressources ou applications travaillez avec AMS, ou pour aggraver un incident, envoyez un e-mail à l'une ou plusieurs des adresses suivantes :
Tout d'abord, si vous n'êtes pas satisfait de la demande de service ou de la réponse au rapport d'incident, envoyez un e-mail à votre CSDM : ams-csdm@amazon.com
Ensuite, si l'escalade est requise, vous pouvez envoyer un e-mail au responsable des opérations AMS (mais votre CSDM le fera probablement) : ams-opsmanager@amazon.com
Pour toute autre escalade, adressez-vous au directeur de l'AMS : ams-director@amazon.com
Enfin, vous pouvez toujours joindre le vice-président de l'AMS : ams-vp@amazon.com
