Avis de fin de support : le 30 juin 2027, le support d'AMS Advanced AWS prendra fin. Après le 30 juin 2027, vous ne pourrez plus accéder à la console AMS Advanced ni aux ressources AMS Advanced. Pour plus d'informations, consultez la section Fin du support d'AMS Advanced.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Planification de la reprise après sinistre
La reprise après sinistre (DR) est un service essentiel pour la continuité des activités et la conformité des entreprises. AMS s'associe à vous pour vous aider à planifier, mettre en œuvre et maintenir votre stratégie de reprise après sinistre sur AMS.
La zone d'atterrissage AMS (LZ), multicompte et compte unique, fournit une haute disponibilité native, multi-AZ et une haute disponibilité pour les composants de l'infrastructure AMS qui répondent à la plupart des scénarios de protection contre les catastrophes. Toutefois, selon la couverture géographique de votre entreprise, vous pourriez avoir besoin d'une protection régionale. Pour la disponibilité interrégionale et la reprise après sinistre, un autre compte AMS est requis dans une région différente (c'est le cas à la fois pour la zone d'atterrissage multi-comptes et pour la zone d'atterrissage monocompte).
AMS s'aligne sur les directives AWS DR décrites dans ce blog, Rapidly restore mission-critical systems in a disaster
Multisite (ou haute disponibilité)
Veille chaude
Lampe pilote
Sauvegarde et restauration
Ces options et leur prise en charge par AMS sont décrites dans les sections suivantes.
Multi-site ou haute disponibilité (HA)
La solution HA est généralement fournie par les fonctionnalités intégrées de l'application, telles que le clustering ou la réplication synchrone. Les utilisateurs sont dirigés à la fois vers Prod et vers les HA/DR nœuds. Le DNS pointe vers les nœuds directement ou via un équilibreur de charge élastique (ELB).
Votre architecte cloud (CA) AMS travaillera avec vous dans le cadre de votre planification Well-Architected-Review et de la reprise après sinistre.
HA DR utilise des applications et des services et fonctionnalités AWS natifs, comme illustré dans le graphique suivant :
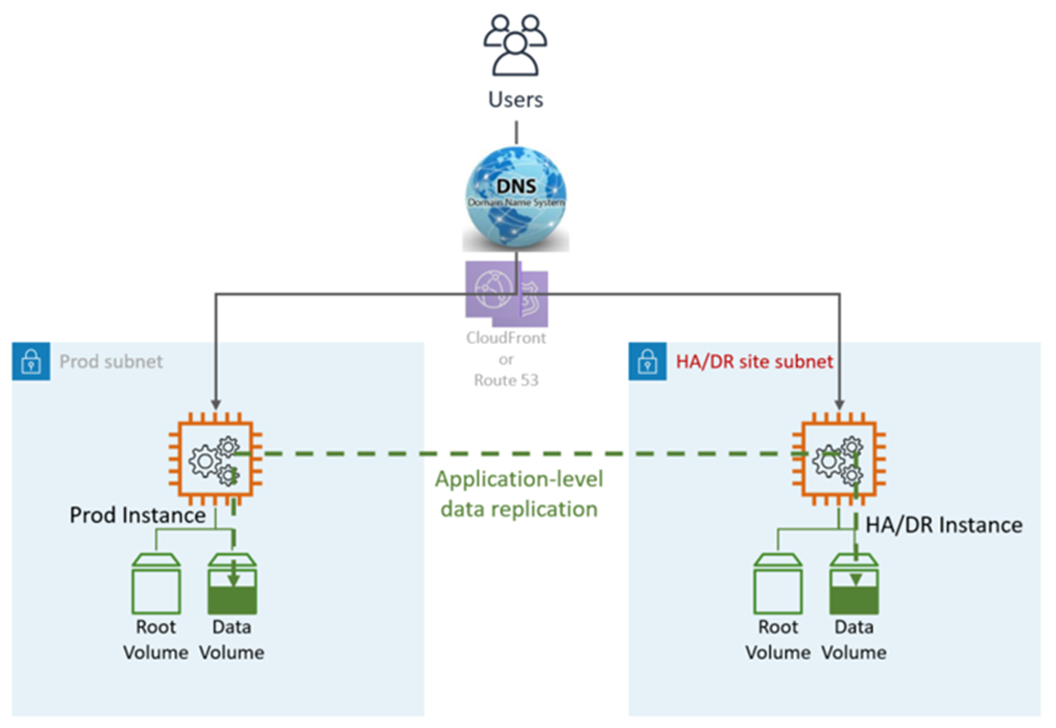
Le site DR peut être identique ou différent Région AWS.
Note
Une région différente (Cross-Region) aura un environnement Active Directory différent.
Étapes DR (failover) : basculement automatique, aucune étape manuelle n'est requise. En cas de défaillance de la LZ principale, les utilisateurs seront automatiquement redirigés vers le nœud. DR/HA Ceci est réalisé à la fois par le DNS et par la configuration de l'application.
Métriques HA DR :
Objectif du point de récupération (RPO) : <5 min
Objectif de temps de récupération et (RTO) : <5 min
Maintenance : élevée (des modifications synchrones sont requises dans les deux environnements, telles que la configuration des applications, les correctifs, les SG ou ALB, les certificats, etc.).
Coût : élevé
Secours semi-automatique
Le terme « veille chaude » est utilisé pour décrire un scénario de reprise après sinistre (DR) dans lequel une version réduite de l'environnement s'exécute dans le cloud.
La réplication des données est gérée par la couche application, généralement de manière asynchrone, vers une instance en ligne, tandis que les autres instances (par exemple, au niveau Application et au niveau Web) peuvent être désactivées pour réduire les coûts. Les utilisateurs sont uniquement dirigés vers le site de production. D'autres AWS ressources, comme Elastic Load Balancer (ELB), peuvent également être préprovisionnées sur le site de reprise après sinistre.
Votre AMS Cloud Architect (CA) travaillera avec vous dans le cadre de votre planification Well-Architected-Review et de la reprise après sinistre.
Warm Standby DR utilise des applications et des services et fonctionnalités AWS natifs, comme illustré dans le graphique suivant :
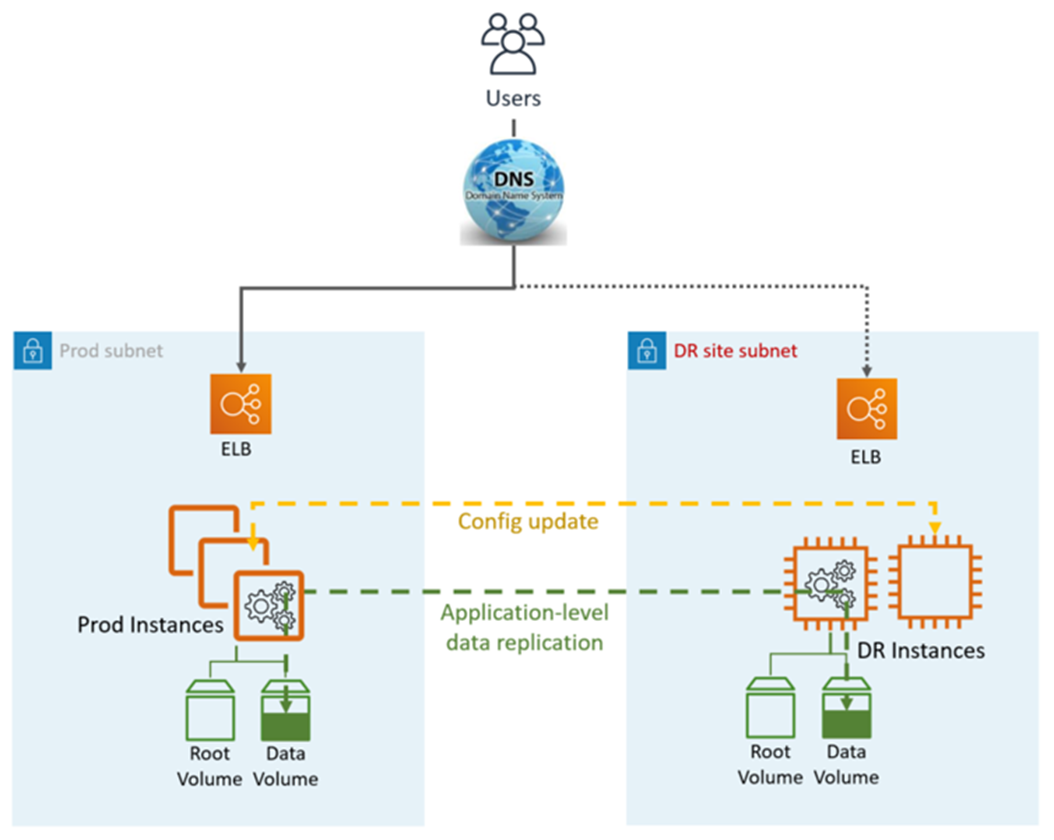
Le site DR peut être identique ou différent Région AWS.
Note
Une région différente (Cross-Region) aura un environnement Active Directory différent.
Étapes DR (failover) :
Freiner la réplication des données et faire de l'instance de données du site DR le maître
Mettez à jour la configuration de l'application selon les besoins (nouvelle adresse IP, nom du serveur, etc.)
Rediriger le DNS vers le site DR (ELB)
Dépendances AD si nécessaire (comptes de service, SPN, GPO, etc.)
Métriques HA DR :
Objectif du point de reprise (RPO) : <1 heure
Objectif de temps de restauration et (RTO) : <1 heure (dépend du nombre d'instances et de l'orchestration)
Maintenance : élevée (des modifications synchrones sont requises dans les deux environnements, telles que la configuration des applications, les correctifs, les groupes de sécurité (SG) ou l'équilibreur de charge des applications (ALB), les certificats, etc.).
Coût : moyen
Veilleuse
Dans cette approche de reprise après sinistre (DR), vous répliquez une partie de votre environnement Prod pour un ensemble limité de services de base. Une petite partie de votre infrastructure fonctionne en permanence, synchronisant simultanément les données modifiables (telles que les bases de données ou les documents), tandis que d'autres parties de votre infrastructure sont désactivées et utilisées uniquement pendant les tests. Contrairement à une approche de sauvegarde et de restauration, vous devez vous assurer que les éléments essentiels les plus critiques sont déjà configurés et fonctionnent dans la zone d'atterrissage de la DR (la veilleuse).
Votre architecte du cloud AMS travaillera avec vous dans le cadre de votre planification Well-Architected-Review et de celle de la reprise après sinistre.
Pilot Light DR utilise des applications et des services et fonctionnalités AWS natifs, comme illustré dans le graphique suivant :
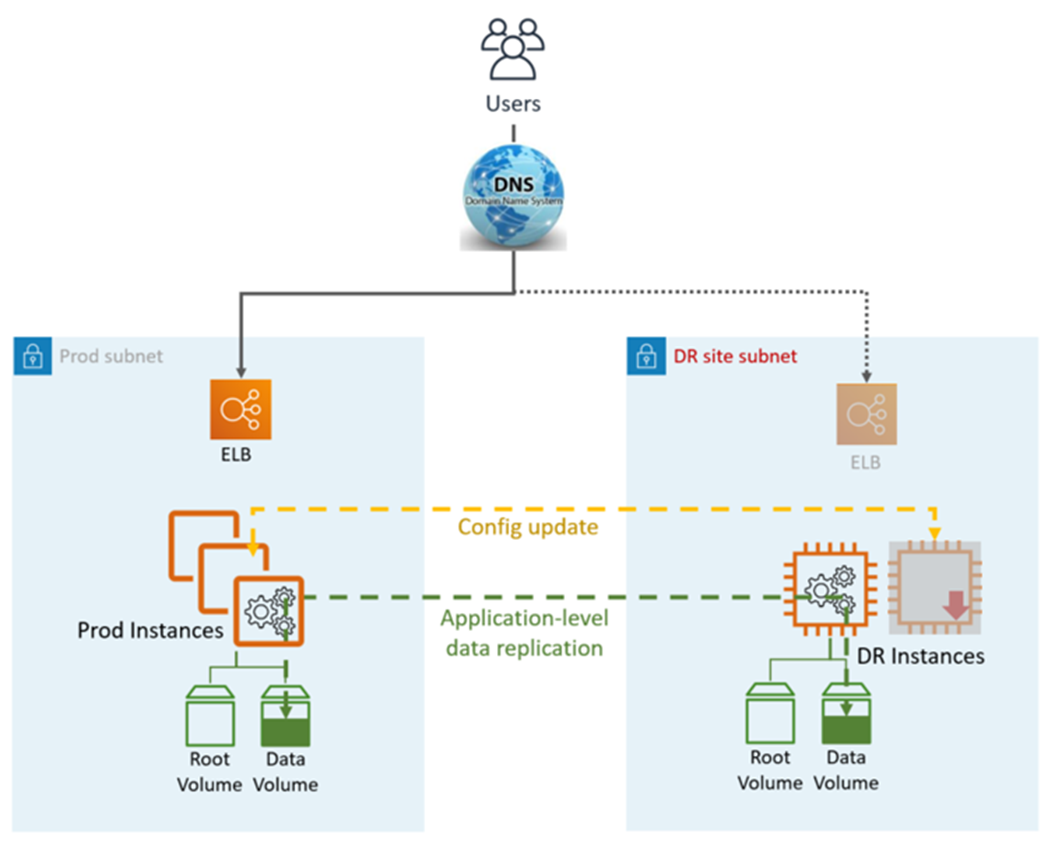
Le site DR peut être identique ou différent Région AWS.
Note
Une région différente (Cross-Region) aura un environnement Active Directory différent.
Étapes DR (failover) :
Freiner la réplication des données et faire de l'instance de données du site DR le maître
Démarrez les instances et l'infrastructure désactivées
Mettez à jour la configuration de l'application selon les besoins (nouvelle adresse IP, nom du serveur, etc.)
Ajoutez les instances à l'ELB selon les besoins
Rediriger le DNS vers le site DR (ELB)
Dépendances AD, si nécessaire (comptes de service, SPN, GPO, etc.)
Indicateurs de Pilot Light DR :
Objectif du point de reprise (RPO) : <1 heure
Objectif de temps de restauration et (RTO) : environ 1 heure (dépend du nombre d'instances et de l'orchestration)
Entretien : moyen
Coût : moyen
Sauvegarde et restauration
Cette approche de reprise après sinistre (DR) simple et peu coûteuse sauvegarde vos données et applications depuis n'importe où vers la zone d'atterrissage de la reprise après sinistre pour les utiliser lors de la reprise après sinistre.
Votre AMS Cloud Architect travaille avec vous dans le cadre de votre planification de Backup et de DR.
Backup and Restore DR utilise les outils et processus automatisés AMS, comme illustré dans le graphique suivant :
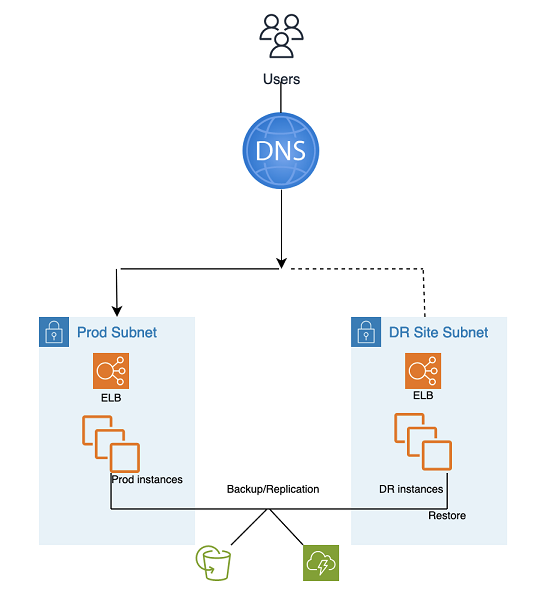
Deux méthodes de sauvegarde et de réplication peuvent être utilisées :
Instantané EBS (Recovery Point Objective (RPO) > 1 heure), connu sous le nom d' « EBS »
Reprise après sinistre AWS Elastic (Objectif de point de récupération (RPO) ~ 0,25 heure), connu sous le nom de « DRS »
Le site DR peut être identique ou différent Région AWS.
Note
Une autre région (Cross-Region) possède un environnement Active Directory différent.
Étapes DR (failover) :
Restaurez les instances à partir de snapshots (processus en deux étapes avec d'abord une instance de remplacement)
Mettre à jour la configuration de l'application (nouvelle adresse IP, nom du serveur, etc.)
Configurez d'autres infrastructures selon les besoins (SG, ELB, etc.)
Rediriger le DNS vers le site DR (ELB)
Mettez à jour ou restaurez les dépendances AD si nécessaire (comptes de service, noms principaux de service (SPN), objets de stratégie de groupe (GPO), etc.)
Mesures de sauvegarde et de restauration après sinistre :
Objectif du point de reprise (RPO) : > 1 heure ou environ 0,25 heure (dépend de la solution sélectionnée - EBS ou DRE)
Objectif de temps de restauration et (RTO) : environ 1 heure (dépend du nombre d'instances et de l'orchestration)
Maintenance : des modifications importantes (synchrones) sont nécessaires dans les deux environnements, telles que la configuration des applications, les correctifs, les groupes de sécurité ou les équilibreurs de charge des applications, les certificats, etc.
Coût : moyen
Protection contre les sinistres pour EC2 avec des instantanés EBS sur AMS
Prérequis :
Zone d'atterrissage d'AMS Prod (source)
Zone d'atterrissage AMS DR (cible DR)
Les instantanés EBS sont activés pour les instances EC2 ()AWS Backup
Solution de réplication de snapshots :
Cross AZ : Non applicable - Les instantanés EBS sont hautement disponibles dans la région dès leur conception
Cross-Region: AWS Backup
Le schéma suivant représente le processus de restauration EC2 à partir de snapshots EBS sur AMS :
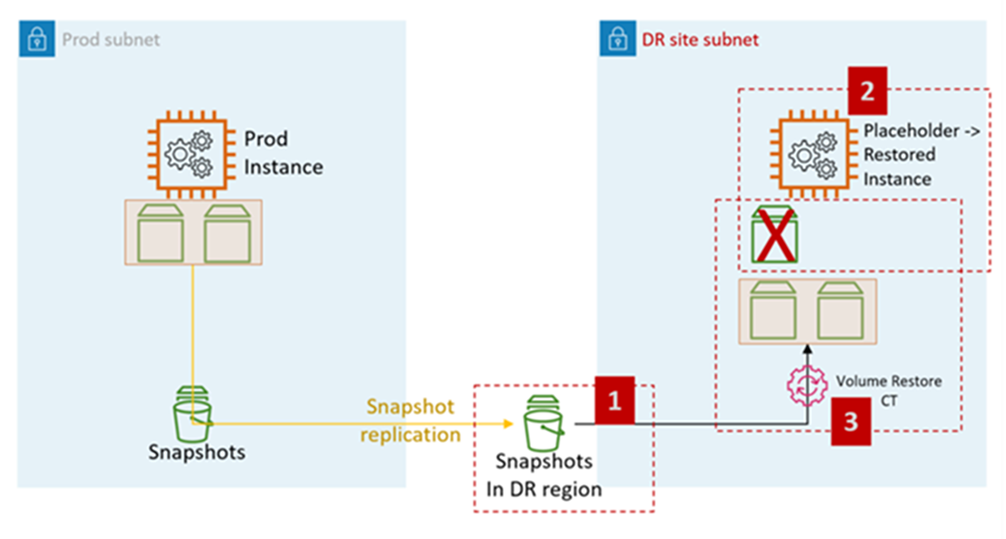
Étapes de l'EC2 DR sur AMS :
Déclenchez une RFC pour partager les instantanés EBS avec le compte cible (obligatoire pour Cross-Region la DR).
: Gestion, composants de pile avancés, EBS Snapshot, partage
Créez une pile AMS EC2 de remplacement dans le sous-réseau de destination (sous-réseau du site DR). Il est recommandé d'utiliser l'ingestion de CFN pour créer la pile, car le client peut combiner les étapes d'attribution de groupes de sécurité et d'autres étapes (comme l'ajout de l'instance à un ELB) dans la même pile.
Type de modification : déploiement, ingestion, empilage à partir d' CloudFormation un modèle, création
Déclenchez une RFC pour effectuer la restauration du volume de pile EC2.
Type de modification : gestion, composants de pile avancés, pile d'instances EC2, volumes de restauration.
Le CT restaure les volumes à partir des instantanés partagés à l'étape 1 et les attache à l'instance d'espace réservé créée à l'étape 2.
Fonctionnalité Volume Restore CT :
Arrêtez l'instance d'espace réservé
Restaurer des volumes à partir des instantanés
Échangez les volumes
Démarrez l'instance
Quitter l'ancien domaine
Modifier le nom d’hôte
Redémarrer. Les scripts d'amorçage AMS relient l'instance au domaine cible (DR) au démarrage
Entrée CT de restauration du volume :
InstanceId (identifiant d'instance substituable)
RootDeviceSnapshotId, le snapshot EBS du volume racine restauré
KMSKeyId, l'identifiant de clé KMS, ou ARN, pour chiffrer tous les volumes restaurés sur l'instance EC2
DeviceNames, jusqu'à 25 (facultatif)
SnapshotIds, jusqu'à 25 (facultatif). Liste des instantanés des volumes à restaurer
Protection contre les sinistres pour EC2 avec Elastic Disaster Recovery sur AMS
Prérequis :
Zone d'atterrissage d'AMS Prod (source)
Zone d'atterrissage AMS DR (cible DR)
Vous devez d'abord initialiser le service Elastic Disaster Recovery pour toutes les Régions AWS applications dans lesquelles vous comptez l'utiliser.
Créez un rôle IAM dans votre zone de landing zone de reprise après sinistre (LZ) pour accéder à la console Elastic Disaster Recovery.
Important : un document SSM est créé en tant qu'action post-lancement dans DRS. Cette action doit être activée sur tous vos serveurs dans les PostLaunch paramètres.
l'instance de destination (espace réservé) doit avoir une clé de balise : « AWSDRS », une valeur : "». AllowLaunchingIntoThisInstance L'instance Placeholder doit être à l'état arrêté. Sinon, AMS ne pourra pas sélectionner l'instance d'espace réservé dans les paramètres de lancement et Elastic Disaster Recovery ne pourra pas effectuer de restauration au-dessus de l'instance d'espace réservé.
Pour un schéma du processus de configuration et de restauration d'Elastic Disaster Recovery pour EC2 sur AMS, voir Architecture générale Reprise après sinistre AWS Elastic (AWS DRS).
Étapes de reprise après sinistre d'EC2 avec Elastic Disaster Recovery sur AMS :
Créez une pile AMS EC2 de remplacement dans le sous-réseau de destination (sous-réseau du site DR) avec les balises appropriées. Pour plus d'informations, consultez la section précédente. Nous vous recommandons d'utiliser l'ingestion CFN pour créer la pile, car vous pouvez combiner les étapes consistant à attribuer des groupes de sécurité et à étiqueter l'instance, le volume EBS et d'autres (comme l'ajout de l'instance à un ELB) dans la même pile.
Type de modification : déploiement, ingestion, empilage à partir d' CloudFormation un modèle, création
Arrêtez l'instance d'espace réservé.
Type de modification : gestion, composants de pile avancés, instance EC2, arrêt
Si ce n'est pas le cas à l'étape 1, balisez l'instance d'espace réservé et son volume EBS avec la clé : « AWSDRS », valeur : "». AllowLaunchingIntoThisInstance
Type de modification : gestion, composants de pile avancés, étiquette, mise à jour.
Utilisez l'instance fictive de l'étape 1 comme cible sous Launch into instance ID, DRS Launch Settings pour le serveur source. Lancez un exercice de restauration d'instance depuis la console Elastic Disaster Recovery pour le serveur source.
Note
Les volumes d'instance réservés sont conservés dans le compte. Pour supprimer ces volumes, soumettez un type de modification Management | Advanced stack components | EBS Volume | Delete (ct-3e3h8u0sp5z80) à la fin de l'opération de reprise après sinistre.
Flux de travail de restauration d'Elastic Disaster Recovery :
L'instance cible (espace réservé) doit être à l'état arrêté
Échangez les volumes et supprimez le volume racine source (espace réservé)
Démarrez l'instance
Exécutez les actions après le lancement pour terminer les tâches suivantes :
Activez l'agent SSM.
Échangez les volumes et supprimez le volume racine source (espace réservé).
Démarrez l'instance
Exécutez le document PostLaunchScript SSM. Ce document effectue les opérations suivantes :
Quitte l'ancien domaine.
Modifie le nom d'hôte.
Redémarrer. Les scripts d'amorçage AMS relient l'instance au domaine cible (DR) lors du démarrage.
