Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Etape 2 : Création d'une source de données de formation
Après avoir chargé le banking.csv jeu de données sur votre site Amazon Simple Storage Service (Amazon S3), vous l'utilisez pour créer une source de données de formation. Une source de données est un objet Amazon Machine Learning (Amazon ML) qui contient l'emplacement de vos données d'entrée et des métadonnées importantes relatives à ces données d'entrée. Amazon ML utilise la source de données pour des opérations telles que la formation et l'évaluation des modèles ML.
Pour créer une source de données, fournissez les éléments suivants :
-
L'emplacement de vos données sur Amazon S3 et l'autorisation d'accès aux données
-
Le schéma, qui comprend les noms des attributs dans les données et le type de chaque attribut (numérique, texte, catégorie ou binaire)
-
Le nom de l'attribut qui contient la réponse que vous souhaitez qu'Amazon ML apprenne à prédire, l'attribut cible
Note
La source de données ne stocke pas réellement vos données, mais les référence uniquement. Évitez de déplacer ou de modifier les fichiers stockés dans Amazon S3. Si vous les déplacez ou les modifiez, Amazon ML ne pourra pas y accéder pour créer un modèle de machine learning, générer des évaluations ou générer des prédictions.
Pour créer la source de données de formation
Ouvrez la console Amazon Machine Learning à l'adresse https://console.aws.amazon.com/machinelearning/
. -
Choisissez Démarrer.
Note
Ce didacticiel part du principe que c'est la première fois que vous utilisez Amazon ML. Si vous avez déjà utilisé Amazon ML, vous pouvez utiliser le bouton Create new... liste déroulante sur le tableau de bord Amazon ML pour créer une nouvelle source de données.
-
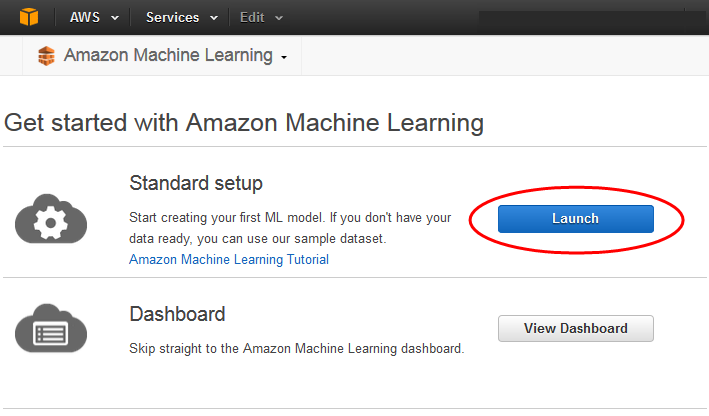
Sur la page Commencer avec Amazon Machine Learning, sélectionnez Launch.
-
Dans la page Input Data, pour Where is your data located?, assurez-vous que S3 est sélectionné.

-
Pour Emplacement S3, tapez l'emplacement complet du fichier
banking.csvde l'étape 1 : Préparation de vos données. Par exemple :your-bucket/banking.csv. Amazon ML ajoute s3 ://au nom de votre compartiment pour vous. -
Pour Datasource name, tapez
Banking Data 1.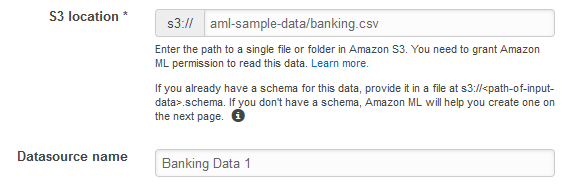
-
Choisissez Vérifier.
-
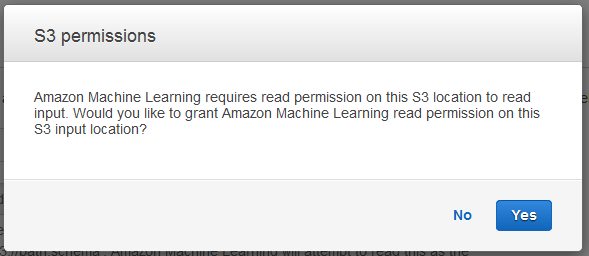
Dans la boîte de dialogue S3 permissions, choisissez Oui.
-
Si Amazon ML peut accéder au fichier de données et le lire à l'emplacement S3, vous verrez une page similaire à la suivante. Passez en revue les propriétés, puis choisissez Continuer.

Ensuite, vous devez établir un schéma. Un schéma est l'information dont Amazon ML a besoin pour interpréter les données d'entrée d'un modèle ML, y compris les noms des attributs et les types de données qui leur sont attribués, ainsi que les noms des attributs spéciaux. Il existe deux manières de fournir un schéma à Amazon ML :
-
Fournissez un fichier de schéma distinct lorsque vous chargez vos données Amazon S3.
-
Autorisez Amazon ML à déduire les types d'attributs et à créer un schéma pour vous.
Dans ce didacticiel, nous demanderons à Amazon ML de déduire le schéma.
Pour obtenir des informations sur la création d'un fichier de schéma distinct, consultez Création d'un schéma de données pour Amazon ML.
Pour autoriser Amazon ML à déduire le schéma
-
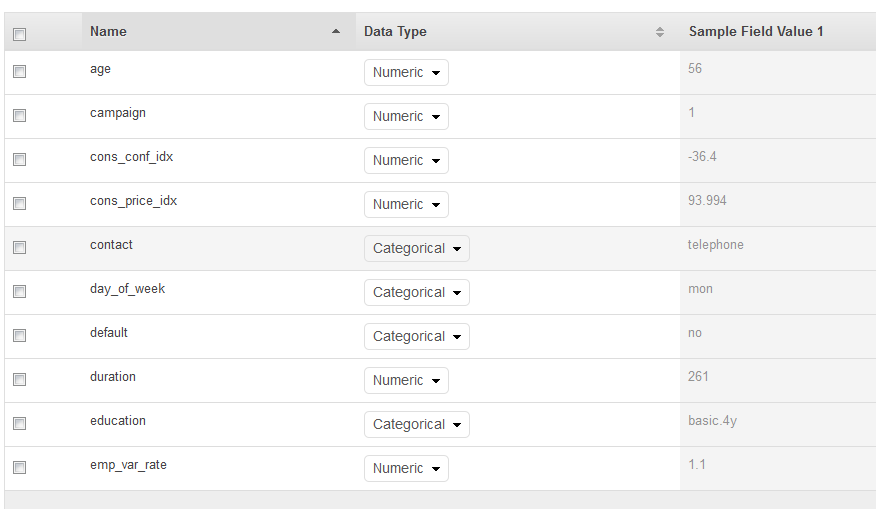
Sur la page Schéma, Amazon ML vous montre le schéma qu'il a déduit. Passez en revue les types de données déduits par Amazon ML pour les attributs. Il est important que le type de données approprié soit attribué aux attributs pour permettre à Amazon ML d'ingérer correctement les données et de permettre le traitement correct des fonctionnalités sur les attributs.
-
Les attributs qui ont seulement deux états possibles, tels que oui ou non, doivent être marqués comme Binary (binaire).
-
Les attributs correspondant à des chaînes ou des nombres utilisés pour indiquer une catégorie doivent être marqués comme Categorical (catégorie).
-
Les attributs correspondant à des quantités numériques dont l'ordre est important doivent être marqués comme Numeric (numérique).
-
Les attributs correspondant à des chaînes que vous souhaitez traiter comme des mots délimités par des espaces doivent être marqués comme Text (texte).
-
-
Dans ce didacticiel, Amazon ML a correctement identifié les types de données pour tous les attributs. Choisissez donc Continuer.
Ensuite, sélectionnez un attribut cible.
Souvenez-vous que la cible est l'attribut que le modèle d'apprentissage-machine doit apprendre à prédire. L'attribut y indique si une personne a déjà souscrit à une campagne dans le passé : 1 (oui) ou 0 (non).
Note
Choisissez un attribut cible seulement si vous avez l'intention d'utiliser la source de données pour la formation et l'évaluation des modèles d'apprentissage-machine.
Pour sélectionner y comme attribut cible
-
Dans la partie inférieure droite du tableau, choisissez la flèche simple pour passer à la dernière page du tableau, où figure l'attribut nommé
y.
-
Dans la colonne Target, sélectionnez
y.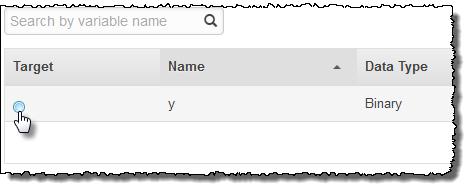
Amazon ML confirme que y est sélectionné comme cible.
-
Sélectionnez Continuer.
-
Dans la page Row ID, pour Does your data contain an identifier ? , veillez à ce que la valeur No (valeur par défaut) soit sélectionnée.
-
Choisissez Vérification, puis Continuer.
Maintenant que vous avez une source de données de formation, vous êtes prêt à créer votre modèle.
