Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Intégrer les données Amazon Redshift dans AWS Glue Data Catalog
Vous pouvez gérer les données analytiques dans les entrepôts de données Amazon Redshift dans AWS Glue Data Catalog le (catalogue de données) et unifier les lacs de données Amazon S3 et les entrepôts de données Amazon Redshift. Amazon Redshift est un service d'entrepôt de données entièrement géré de plusieurs pétaoctets dans le cloud. AWS Un entrepôt des données Amazon Redshift est un ensemble de ressources informatiques appelées nœuds, qui sont organisées en un groupe appelé cluster. Chaque cluster exécute un moteur Amazon Redshift et contient une ou plusieurs bases de données.
Dans Amazon Redshift, vous pouvez créer des clusters provisionnés par Amazon Redshift et des espaces de noms sans serveur, et les enregistrer dans le catalogue de données. Vous pouvez ainsi unifier les données dans le stockage géré Amazon Redshift (RMS) et les compartiments Amazon S3, et accéder aux données à partir de moteurs d'analyse compatibles avec Apache Iceberg.
En enregistrant des espaces de noms et des clusters, vous pouvez donner accès aux données sans avoir à les copier ou à les déplacer. Pour plus d'informations sur l'enregistrement de clusters et d'espaces de noms dans Amazon Redshift, consultez la section Enregistrement de clusters et d'espaces de noms Amazon Redshift auprès du. AWS Glue Data Catalog
Dans Amazon Redshift, vous pouvez partager des données via des partages de données ou en enregistrant des espaces de noms et des clusters auprès de Data Catalog. Dans le cas des partages de données, qui fonctionnent au niveau de chaque objet de base de données, vous devez activer le partage pour chaque table ou vue. En revanche, la publication d'espaces de noms fonctionne au niveau du cluster ou de l'espace de noms. Lorsque vous enregistrez un cluster ou un espace de noms dans le catalogue de données, toutes les bases de données et les tables qu'il contient sont automatiquement partagées, sans que vous ayez à configurer le partage pour des objets individuels.
Dans le catalogue de données, vous pouvez créer un catalogue fédéré pour chaque espace de noms ou cluster. Un catalogue est appelé catalogue fédéré lorsqu'il pointe vers une entité extérieure au catalogue de données. Les tables et les vues de l'espace de noms Amazon Redshift sont répertoriées sous forme de tables individuelles dans le catalogue de données. Vous pouvez partager des bases de données et des tables du catalogue fédéré avec des principaux IAM et des utilisateurs SAML sélectionnés au sein du même compte ou d'un autre compte avec Lake Formation. Vous pouvez également inclure des expressions de filtre de ligne et de colonne pour restreindre l'accès à certaines données. Pour de plus amples informations, veuillez consulter Filtrage des données et sécurité au niveau des cellules dans Lake Formation.
Le catalogue de données prend en charge une hiérarchie de métadonnées à trois niveaux comprenant des catalogues, des bases de données et des tables (et des vues). Lorsque vous enregistrez un espace de noms dans le catalogue de données, la hiérarchie de données Amazon Redshift est mappée à la hiérarchie à 3 niveaux du catalogue de données comme suit :
-
L'espace de noms Amazon Redshift devient un catalogue à plusieurs niveaux dans le catalogue de données.
La base de données Amazon Redshift associée est enregistrée en tant que catalogue dans le catalogue de données.
-
Le schéma Amazon Redshift devient une base de données dans le catalogue de données.
-
La table Amazon Redshift devient une table dans le catalogue de données.
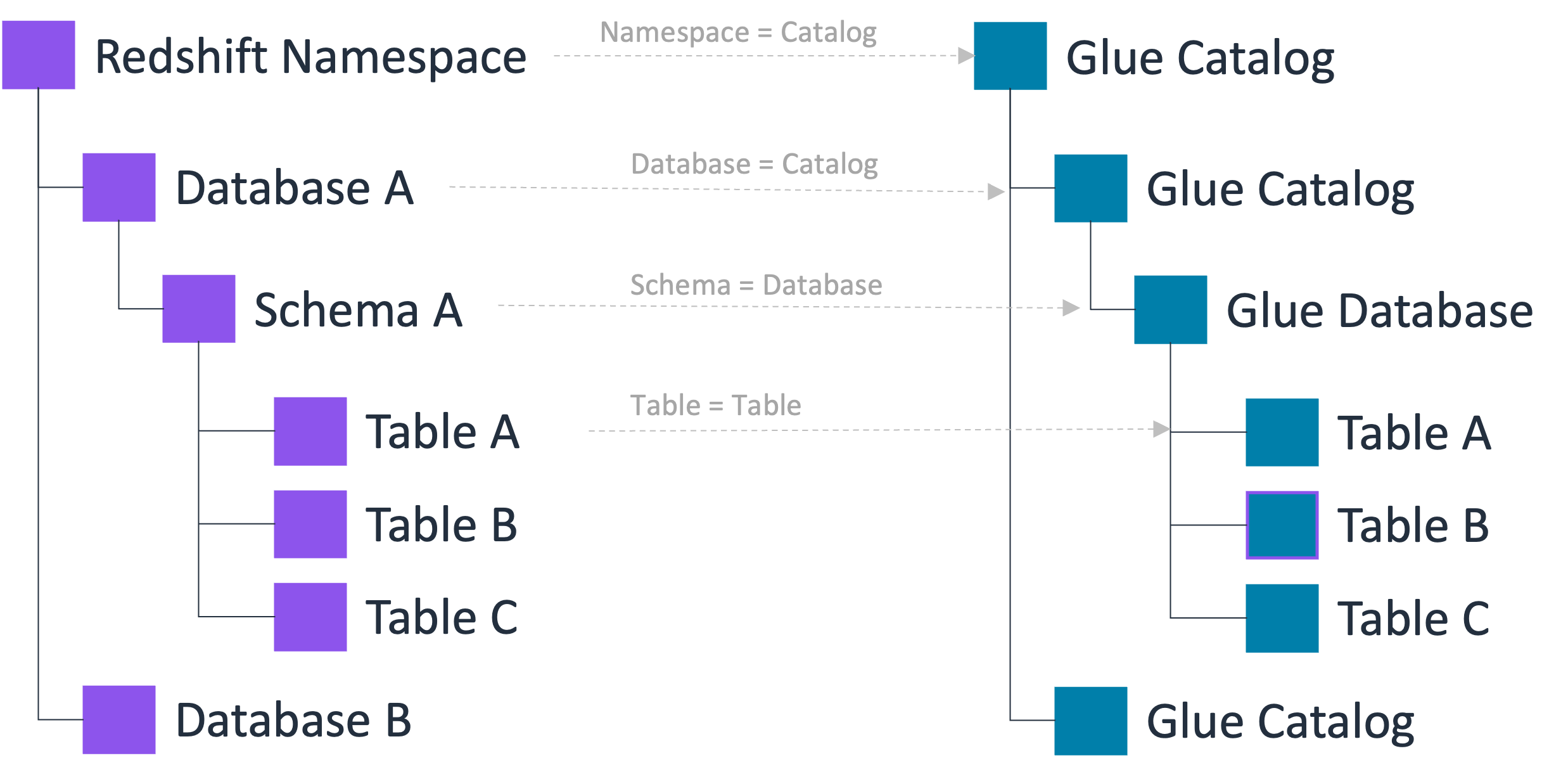
Grâce à cette hiérarchie de métadonnées à trois niveaux, vous pouvez accéder aux tables Amazon Redshift en utilisant la notation en trois parties catalog1/catalog2 « .database.table » dans le catalogue de données. Les équipes chargées des données peuvent également conserver la même organisation qu'Amazon Redshift utilise pour organiser les tables au sein du compte Data Catalog.
Dans Lake Formation, vous pouvez gérer en toute sécurité les données d'Amazon Redshift à l'aide d'un contrôle d'accès précis pour les ressources du catalogue de données. Grâce à cette intégration, vous pouvez gérer, sécuriser et interroger des données analytiques à partir d'un catalogue unique doté d'un mécanisme de contrôle d'accès commun.
Pour connaître les limitations, veuillez consulter Limites liées à l'intégration des données de l'entrepôt de données Amazon Redshift dans le AWS Glue Data Catalog.
Rubriques
Principaux avantages
L'enregistrement de clusters et d'espaces de noms Amazon Redshift dans les AWS Glue Data Catalog lacs de données Amazon S3 et les entrepôts de données Amazon Redshift et leur unification offrent les avantages suivants :
Expérience d'interrogation uniforme : interrogez vos données gérées par Amazon Redshift et les données contenues dans les compartiments Amazon S3 à l'aide de n'importe quel moteur de requête compatible avec Apache Iceberg, tel qu'Amazon EMR Serverless et Amazon Athena, sans avoir à déplacer ou à copier des données.
-
Accès aux données cohérent entre les services : vous n'avez pas besoin de mettre à jour les noms des bases de données et des tables dans vos pipelines de données lorsque vous accédez aux mêmes sources de données fédérées à partir de différents services AWS d'analyse, car les sources de données sont enregistrées dans le catalogue de données.
Fine-grained contrôle d'accès : vous pouvez appliquer les autorisations de Lake Formation pour gérer l'accès aux sources de données fédérées à l'aide d'autorisations de contrôle d'accès détaillées.
Rôles et responsabilités
| Rôle | Responsabilité |
| Administrateur du cluster de producteurs Amazon Redshift |
Enregistre le cluster ou l'espace de noms dans le catalogue de données. |
| Administrateur du lac de données de Lake Formation |
Accepte l'invitation du cluster ou de l'espace de noms, crée des catalogues fédérés et accorde l'accès aux catalogues fédérés à d'autres principaux. |
| Administrateur en lecture seule de Lake Formation | Découvre le catalogue fédéré, interroge les tables Amazon Redshift dans le catalogue fédéré. |
| Rôle de transfert de données |
Amazon Redshift se charge en votre nom de transférer les données vers et depuis le compartiment Amazon S3. |
Voici les étapes de haut niveau permettant aux utilisateurs d'accéder à un espace de noms Amazon Redshift :
-
Dans Amazon Redshift, l'administrateur du cluster de producteurs enregistre un cluster ou un espace de noms dans le catalogue de données.
-
L'administrateur du lac de données accepte l'invitation à l'espace de noms de l'administrateur du cluster de producteurs Amazon Redshift et crée un catalogue fédéré dans le catalogue de données.
Une fois cette étape terminée, vous pouvez gérer le catalogue d'espaces de noms Amazon Redshift dans le catalogue de données.
-
Accordez des autorisations aux utilisateurs sur les catalogues, les bases de données et les tables. Vous pouvez partager l'intégralité du catalogue d'espaces de noms ou un sous-ensemble de tables avec des utilisateurs du même compte ou d'un autre compte.
