Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Validation de la cohérence des données lors d'une migration en ligne
La prochaine étape du processus de migration en ligne est la validation des données. Les écritures doubles ajoutent de nouvelles données à votre base de données Amazon Keyspaces et vous avez terminé la migration des données historiques par téléchargement groupé ou par expiration des données avec TTL.
Vous pouvez maintenant utiliser la phase de validation pour confirmer que les deux magasins de données contiennent en fait les mêmes données et renvoient les mêmes résultats de lecture. Vous pouvez choisir l'une des deux options suivantes pour vérifier que vos deux bases de données contiennent des données identiques.
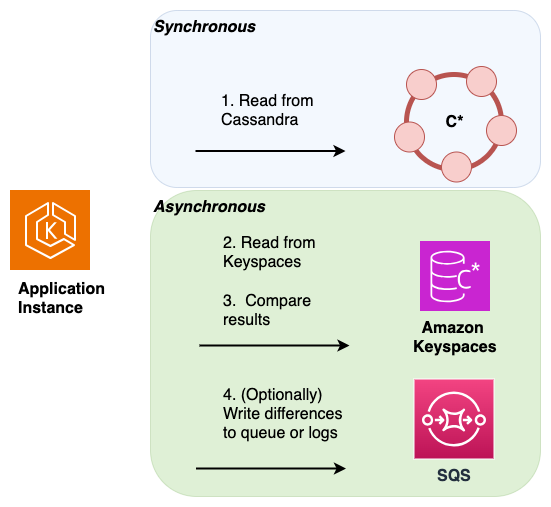
Lectures doubles : pour vérifier que la base de données source et la base de données de destination contiennent le même ensemble de données nouvellement écrites et historiques, vous pouvez implémenter des lectures doubles. Pour ce faire, vous pouvez lire à la fois dans votre base de données Cassandra principale et dans votre base de données Amazon Keyspaces secondaire de la même manière que la méthode à double écriture et vous comparez les résultats de manière asynchrone.
Les résultats de la base de données principale sont renvoyés au client, et les résultats de la base de données secondaire sont utilisés pour être validés par rapport au jeu de résultats principal. Les différences détectées peuvent être enregistrées ou envoyées dans une file d'attente de lettres mortes (DLQ) pour un rapprochement ultérieur.
Dans le schéma suivant, l'application effectue une lecture synchrone depuis Cassandra (qui est le magasin de données principal) et une lecture asynchrone depuis Amazon Keyspaces, qui est le magasin de données secondaire.
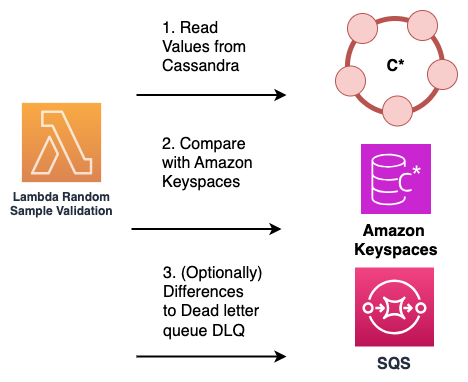
Exemples de lectures — Une solution alternative qui ne nécessite pas de modification du code de l'application consiste à utiliser des AWS Lambda fonctions pour échantillonner périodiquement et aléatoirement les données du cluster Cassandra source et de la base de données Amazon Keyspaces de destination.
Ces fonctions Lambda peuvent être configurées pour s'exécuter à intervalles réguliers. La fonction Lambda extrait un sous-ensemble aléatoire de données à la fois des systèmes source et de destination, puis effectue une comparaison des données échantillonnées. Toute divergence ou inadéquation entre les deux ensembles de données peut être enregistrée et envoyée à une file d'attente dédiée (DLQ) pour un rapprochement ultérieur.
Ce processus est illustré dans le diagramme suivant.