Avis de fin de support : le 15 décembre 2025, AWS le support de AWS IoT Analytics. Après le 15 décembre 2025, vous ne pourrez plus accéder à la AWS IoT Analytics console ni aux AWS IoT Analytics ressources. Pour plus d'informations, voir AWS IoT Analytics fin du support.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Étape 1 : Rediriger l'ingestion de données en cours
La première étape de votre migration consiste à rediriger votre ingestion de données en cours vers un nouveau service. Nous recommandons deux modèles en fonction de votre cas d'utilisation spécifique :
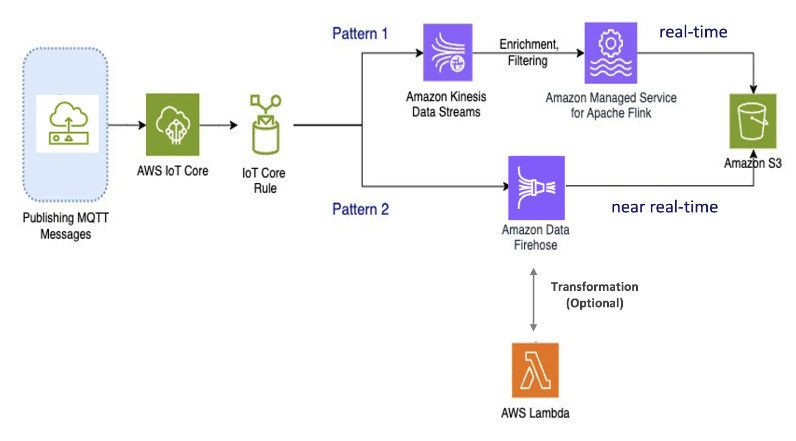
Modèle 1 : Amazon Kinesis Data Streams avec Amazon Managed Service pour Apache Flink
Dans ce modèle, vous commencez par publier des données AWS IoT Core qui s'intègrent à Amazon Kinesis Data Streams, ce qui vous permet de collecter, de traiter et d'analyser une large bande passante de données en temps réel.
Métriques et analyses
-
Ingestion de données : AWS IoT les données sont ingérées dans un Amazon Kinesis Data Streams en temps réel. Amazon Kinesis Data Streams peut gérer un débit élevé de données provenant de millions d'appareils, ce qui permet d'effectuer AWS IoT des analyses en temps réel et de détecter les anomalies.
-
Traitement des données : utilisez Amazon Managed Service pour Apache Flink pour traiter, enrichir et filtrer les données issues d'Amazon Kinesis Data Streams. Flink fournit des fonctionnalités robustes pour le traitement d'événements complexes, tels que les agrégations, les jointures et les opérations temporelles.
-
Données du magasin : Flink envoie les données traitées à Amazon S3 pour le stockage et une analyse plus approfondie. Ces données peuvent ensuite être consultées à l'aide d'Amazon Athena ou intégrées à d'autres services d' AWS analyse.
Utilisez ce modèle si votre application implique le streaming de données à bande passante élevée et nécessite un traitement avancé, tel que la correspondance de modèles ou le fenêtrage, ce modèle est le mieux adapté.
Modèle 2 : utiliser Amazon Data Firehose
Dans ce modèle, les données sont publiées sur Amazon Data Firehose AWS IoT Core, qui s'intègre, ce qui vous permet de stocker des données directement dans Amazon S3. Ce modèle prend également en charge les transformations de base à l'aide de AWS Lambda.
Métriques et analyses
-
Ingestion de données : AWS IoT les données sont ingérées directement depuis vos appareils ou dans AWS IoT Core Amazon Data Firehose.
-
Données de traitement : Amazon Data Firehose effectue des transformations et des traitements de base sur les données, tels que la conversion de format et l'enrichissement. Vous pouvez activer la transformation des données Firehose en la configurant pour appeler des AWS Lambda fonctions permettant de transformer les données sources entrantes avant de les transmettre aux destinations.
-
Données du magasin : les données traitées sont transmises à Amazon S3 en temps quasi réel. Amazon Data Firehose s'adapte automatiquement au débit des données entrantes, garantissant ainsi une diffusion fiable et efficace des données.
Utilisez ce modèle pour les charges de travail qui nécessitent des transformations et un traitement de base. En outre, Amazon Data Firehose simplifie le processus en proposant des fonctionnalités de mise en mémoire tampon et de partitionnement dynamique pour les données stockées dans Amazon S3.
