Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration d'une cible pour une intégration zéro ETL
Plusieurs options sont proposées AWS Glue lors de la configuration d'une cible pour une intégration zéro ETL. La cible peut être un entrepôt de Amazon Redshift données crypté ou une architecture Lakehouse d'Amazon. SageMaker
Avant de sélectionner la cible pour l’intégration zéro ETL, vous devez configurer l’une des ressources cible suivantes. Les options de configuration pour une cible dans une intégration zéro ETL sont les suivantes :
Un compartiment Amazon S3 à usage général utilisant l'architecture Lakehouse d'Amazon. SageMaker Consultez Configuration d'une cible de compartiment S3 à usage général.
Un bucket Amazon S3 Tables utilisant l'architecture Lakehouse d'Amazon. SageMaker Consultez Configuration d'une cible de compartiment Amazon S3 Tables.
Un stockage Amazon Redshift géré utilisant l'architecture Lakehouse d'Amazon. SageMaker Consultez Configuration d'une cible de stockage Amazon Redshift géré.
Un entrepôt Amazon Redshift de données identifié par un espace de noms Redshift. Consultez Configuration d'une cible d'entrepôt de Amazon Redshift données.
Note
Vous ne pouvez pas modifier la cible d’une intégration zéro ETL après sa création.
Configuration d'une cible de compartiment S3 à usage général
Cette section décrit les conditions préalables et les étapes de configuration pour configurer un compartiment S3 à usage général comme espace de stockage pour votre cible dans le cadre d'une intégration zéro ETL, en utilisant l'architecture Lakehouse d'Amazon. SageMaker
Avant de créer une intégration zéro ETL avec l'architecture Lakehouse d'Amazon à SageMaker l'aide d'un stockage S3 à usage général, vous devez effectuer les tâches de configuration suivantes :
Configuration d'une AWS Glue base de données
Fournir une politique RBAC du catalogue
Créer un rôle IAM cible
Associer le rôle cible, le KMS (facultatif) et la connexion (facultatif) à la ressource cible
(Facultatif) Configurer les propriétés de la table cible
Configuration d'une AWS Glue base de données
Pour configurer une base de données cible dans le catalogue de données avec un emplacement de compartiment à usage général Amazon S3 :
Sur la page d'accueil de la AWS Glue console, sélectionnez Base de données sous Catalogue de données.
Choisissez Ajouter une base de données en haut à droite. Si vous avez déjà créé une base de données, assurez-vous que l’emplacement avec l’URI Amazon S3 est défini pour la base de données.
Saisissez un nom et un emplacement (URI Amazon S3). Notez que l’emplacement est requis pour l’intégration zéro ETL. Cliquez sur Créer une base de données lorsque vous avez terminé.
Note
Le compartiment Amazon S3 à usage général doit se trouver dans la même région que la AWS Glue base de données.
Pour plus d'informations sur la création d'une nouvelle base de données dans AWS Glue, voir Mise en route avec le catalogue de données.
Vous pouvez également utiliser la commande CLI create-database pour créer la base de données dans AWS Glue. Notez que le LocationUri dans --database-input est obligatoire.
Optimisation des tables Iceberg
Une fois qu'une table est créée AWS Glue dans la base de données cible, vous pouvez activer le compactage pour accélérer les requêtes dans Amazon Athena. Pour plus d’informations sur la configuration des ressources (rôle IAM) pour le compactage, consultez Conditions préalables requises pour l’optimisation des tables.
Pour plus d'informations sur la configuration du compactage sur la AWS Glue table créée par l'intégration, consultez Optimisation des tables Iceberg.
Fourniture d’une politique d’accès basée sur les ressources (RBAC) du catalogue
Pour les intégrations qui utilisent une AWS Glue base de données, ajoutez les autorisations suivantes à la politique RBAC du catalogue afin de permettre les intégrations entre la source et la cible.
Note
Pour les intégrations entre comptes, l'utilisateur qui crée la politique de rôle d'intégration et la politique de ressources du catalogue doivent autoriser l'accès à glue:CreateInboundIntegration la ressource. Pour un même compte, une politique de ressources ou une politique de rôle autorisant glue:CreateInboundIntegration sur la ressource est suffisante. Les deux scénarios doivent toujours autoriser glue.amazonaws.com pour glue:AuthorizeInboundIntegration.
Vous pouvez accéder aux paramètres du catalogue sous Catalogue de données. Indiquez ensuite les autorisations suivantes et complétez les informations manquantes.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Création d’un rôle IAM cible
Créez un rôle IAM cible avec les autorisations et les relations d’approbation suivantes :
{ "Version": "2012-10-17", "Statement": [ { "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::amzn-s3-bucket", "Effect": "Allow" }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/*", "Effect": "Allow" }, { "Action": [ "glue:GetDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Effect": "Allow" }, { "Action": [ "glue:CreateTable", "glue:GetTable", "glue:GetTables", "glue:DeleteTable", "glue:UpdateTable", "glue:GetTableVersion", "glue:GetTableVersions", "glue:GetResourcePolicy" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name", "arn:aws:glue:us-east-1:111122223333:table/database-name/*" ], "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Ajoutez la politique de confiance suivante pour permettre au AWS Glue service d'assumer le rôle :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Associer le rôle cible, le KMS (facultatif) et la connexion (facultatif) à la ressource cible
Associez le rôle cible ci-dessus à la ressource cible, c'est-à-dire à la AWS Glue base de données. En option, le KMS pour chiffrer les données avant de les stocker dans la table iceberg cible et l'ARN de connexion pour accéder au compartiment S3 peuvent être configurés pour la base de données cible AWS Glue . Cela permettra d'accéder AWS Glue aux données sur l'emplacement S3 cible à l'aide du rôle fourni et éventuellement de les chiffrer à l'aide de la clé KMS fournie. Si le compartiment S3 cible est configuré pour être accessible via un certain VPC, l'ARN de connexion peut être associé pour permettre l'exécution du traitement AWS Glue au sein de ce VPC. Pour plus d'informations sur la configuration d'un VPC, consultez la section Créer un VPC.
Ou en utilisant la AWS Glue CLI/API :
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --target-processing-properties '{"RoleArn": "arn:aws:iam::123456789012:role/gmi_target_role"}' \ --region us-east-1
(Facultatif) Configurer les propriétés de la table cible
Facultativement, les propriétés des tables cibles peuvent être configurées pour les tables cibles qui vont être synchronisées avec la cible.
Vous pouvez configurer ces paramètres dans la section Paramètres de sortie du flux de travail de création d'intégration dans la AWS Glue console :

Lorsque vous sélectionnez Spécifier des clés de partition personnalisées, vous pouvez configurer les clés de partition ainsi que leurs caractéristiques de fonction et de conversion :

Si la source et la cible se trouvent dans le même compte, cette configuration peut être effectuée dans le cadre du flux de travail de création d'intégration à partir de l'interface utilisateur de la AWS Glue console. Mais si la cible se trouve dans un autre compte, cette configuration doit être terminée avant de créer l'intégration. Lorsque vous utilisez la CLI ou l'API, cela doit être fait avant d'appeler l'API Create-Integration, même lorsque la source et la cible se trouvent dans le même compte. AWS Glue L'interface utilisateur de la console encapsule simplement cet appel d'API pour le même scénario de compte.
Si cela n'est pas configuré, les valeurs par défaut seront utilisées lors de la synchronisation de la table. Cette configuration peut également être modifiée à tout moment après la création de l'intégration.
Note
Si cette propriété est mise à jour après la création de l'intégration, elle peut déclencher une resynchronisation complète de la table lorsque la configuration mise à jour entre en conflit avec la configuration existante. Par exemple, mettre à jour la table « unnesting » de « No-Unnest » à « Full-Unnest », ou modifier la colonne de partition.
À l'aide de la CLI ou de l'API :
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --table-nametable-name\ --target-table-config '{ "UnnestSpec":"TOPLEVEL"|"FULL"|"NOUNNEST", "PartitionSpec": [ { "FieldName":"string", "FunctionSpec":"string", "ConversionSpec":"string"} ... ], "TargetTableName":"string" }' \ --region us-east-1
Après avoir configuré l'architecture Lakehouse d'Amazon SageMaker avec un stockage par compartiment Amazon S3 à usage général, vous pouvez terminer la configuration Configuration de l’intégration avec votre cible de l'intégration.
Configuration d'une cible de compartiment Amazon S3 Tables
Cette section décrit les conditions préalables et les étapes de configuration pour configurer les tables Amazon S3 en tant que cible pour votre intégration zéro ETL, en utilisant l'architecture Lakehouse d'Amazon. SageMaker
Avant de créer une intégration zéro ETL avec des tableaux Amazon S3 comme cibles, vous devez effectuer les tâches de configuration suivantes :
Configuration du compartiment de tables Amazon S3 (et intégration des services d'analyse)
Fournir une politique RBAC du catalogue
Créer un rôle IAM cible
Associer le rôle cible, le KMS (facultatif) et la connexion (facultatif) à la ressource cible
(Facultatif) Configurer les propriétés de la table cible
Configuration du compartiment de tables Amazon S3 (avec intégration des services d'analyse)
Créez un compartiment de tableaux S3 dans votre compte en suivant les instructions de la section Getting started with Amazon S3 Tables.
Activez les intégrations Analytics avec votre bucket S3-Table en suivant ces instructions : Intégration des AWS services avec Amazon S3 Tables.
Cela créera un nouveau catalogue S3-Table dans. AWS Lake Formation
Fourniture d’une politique RBAC du catalogue
Les autorisations suivantes doivent être ajoutées à la politique RBAC du catalogue pour permettre les intégrations entre la source et la cible du catalogue des tableaux Amazon S3.
La politique de ressources du AWS Glue catalogue cible doit inclure les autorisations AWS Glue de service pourAuthorizeInboundIntegration. En outre, une CreateInboundIntegration autorisation est requise soit sur le principal source qui crée l'intégration, soit dans la politique de AWS Glue ressource cible.
Note
Dans le cas d'un scénario entre comptes, la politique de ressources du AWS Glue catalogue principal et celle du catalogue cible doivent inclure glue:CreateInboundIntegration des autorisations sur la ressource.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Note
s3tablescatalogs3tablescatalog
Création d’un rôle IAM cible
Créez un rôle IAM cible avec les autorisations et les relations d’approbation suivantes :
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3tables:ListTableBuckets", "s3tables:GetTableBucket", "s3tables:GetTableBucketEncryption", "s3tables:GetNamespace", "s3tables:CreateNamespace", "s3tables:ListNamespaces", "s3tables:CreateTable", "s3tables:DeleteTable", "s3tables:GetTable", "s3tables:GetTableEncryption", "s3tables:ListTables", "s3tables:GetTableMetadataLocation", "s3tables:UpdateTableMetadataLocation", "s3tables:GetTableData", "s3tables:PutTableData" ], "Resource": "arn:aws:s3tables:us-east-1:111122223333:bucket/s3-table-bucket", "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Ajoutez la politique de confiance suivante dans le rôle IAM cible pour permettre au AWS Glue Service de l'assumer :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Note
Assurez-vous qu’il n’existe aucune instruction DENY explicite pour ce rôle IAM cible dans la politique de ressources du compartiment des tableaux S3. Une instruction DENY explicite remplacerait toutes les autorisations ALLOW et empêcherait l’intégration de fonctionner correctement.
Associer le rôle cible, le KMS (facultatif) et la connexion (facultatif) à la ressource cible
Associez le rôle cible ci-dessus à la ressource cible. En option, le KMS pour chiffrer les données avant de les stocker dans la table Iceberg cible et l'ARN de connexion pour accéder au compartiment S3 cible peuvent être configurés. Si le compartiment S3 cible est configuré pour être accessible via un certain VPC, l'ARN de connexion peut être associé pour permettre l'exécution du traitement AWS Glue au sein de ce VPC. Pour plus d'informations sur la configuration d'un VPC, consultez la section Créer un VPC.
À l'aide de la AWS Glue CLI/API :
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --target-processing-properties '{ "RoleArn": "arn:aws:iam::123456789012:role/target_role" }' \ --region us-east-1
(Facultatif) Configurer les propriétés de la table cible
Facultativement, les propriétés des tables cibles peuvent être configurées pour les tables cibles qui vont être synchronisées avec la cible. Les mêmes règles s'appliquent, comme décrit dans la section cible S3 à usage général.
À l'aide de la CLI ou de l'API :
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --table-nametable-name\ --target-table-config '' \ --region us-east-1
Après avoir configuré le stockage Amazon S3-Tables à l'aide de l'architecture Lakehouse d'Amazon SageMaker, vous pouvez terminer la configuration Configuration de l’intégration avec votre cible de l'intégration.
Configuration d'une cible de stockage Amazon Redshift géré
Cette section décrit les conditions préalables et les étapes de configuration pour configurer un stockage Amazon Redshift géré (RMS) comme cible pour votre intégration zéro ETL, en utilisant l'architecture Lakehouse d'Amazon. SageMaker
Avant de créer une intégration zéro ETL avec une architecture Lakehouse d'Amazon utilisant le stockage géré SageMaker Redshift, vous devez effectuer les tâches de configuration suivantes :
Configuration d'un Amazon Redshift cluster ou d'un groupe de travail sans serveur
Enregistrez l' Amazon Redshift intégration avec Lake Formation
Créer un catalogue géré dans Lake Formation
Configuration des autorisations IAM
Configuration du stockage Amazon Redshift géré
Pour configurer le stockage Amazon Redshift géré pour votre intégration Zero-ETL :
Créez ou utilisez un Amazon Redshift cluster ou un groupe de travail sans serveur existant. Assurez-vous que le
enable_case_sensitive_identifierparamètre est activé dans le Amazon Redshift groupe de travail ou le cluster cible pour que l'intégration soit réussie. Pour plus d'informations sur l'activation de la distinction majuscules/minuscules, voir Activer la distinction majuscules/minuscules pour votre entrepôt de données dans le guide Amazon Redshift de gestion.Enregistrez une intégration de Redshift dans le catalogue dans AWS Lake Formation. Consultez la section Enregistrement de Amazon Redshift clusters et d'espaces de noms dans le catalogue de données.
Créez un catalogue fédéré ou géré dans. AWS Lake Formation Pour en savoir plus, consultez :
Configurez les autorisations IAM pour le rôle cible. Le rôle a besoin d’autorisations pour accéder aux ressources Redshift et Lake Formation. Au minimum, le rôle doit disposer des éléments suivants :
Autorisations d’accès au cluster Redshift ou au groupe de travail
Autorisations d’accès au catalogue Lake Formation
Autorisations de création et de gestion de tableaux dans le catalogue
CloudWatch et CloudWatch enregistre les autorisations à des fins de surveillance
Après avoir configuré le catalogue Amazon SageMaker Lakehouse avec le stockage Amazon Redshift géré, vous pouvez terminer la configuration Configuration de l’intégration avec votre cible de l'intégration.
Configuration d'une cible d'entrepôt de Amazon Redshift données
Cette section décrit les conditions préalables et les étapes de configuration pour configurer un entrepôt de Amazon Redshift données en tant que cible pour votre intégration zéro ETL.
Avant de créer une intégration zéro ETL avec une cible d'entrepôt de Amazon Redshift données, vous devez effectuer les tâches de configuration suivantes :
Configuration d'un Amazon Redshift cluster ou d'un groupe de travail sans serveur
Configurer la sensibilité à la casse
Configuration des autorisations IAM
Configuration de l'entrepôt Amazon Redshift de données
Pour configurer un entrepôt de Amazon Redshift données pour votre intégration Zero-ETL :
Accédez à la console Amazon Redshift
et cliquez sur Créer un cluster ou utilisez un cluster existant. Pour créer un Amazon Redshift cluster, reportez-vous à la section Création d'un cluster. Pour Amazon Redshift sans serveur, cliquez sur Créer un groupe de travail. Pour créer un groupe de travail Amazon Redshift sans serveur, voir Création d’un groupe de travail avec un espace de noms. Si vous créez un cluster, choisissez une taille de cluster appropriée et assurez-vous que votre cluster est chiffré. Pour le sans serveur, configurez les paramètres de groupe de travail en fonction de vos besoins.
Assurez-vous que le
enable_case_sensitive_identifierparamètre est activé dans le Amazon Redshift groupe de travail ou le cluster cible pour que l'intégration soit réussie. Pour plus d’informations sur l’activation de la sensibilité à la casse, consultez Activation de la sensibilité à la casse pour votre entrepôt de données dans le Guide de la gestion Amazon Redshift.Configurez les autorisations IAM pour permettre à l'intégration Zero-ETL d'accéder à votre entrepôt de Amazon Redshift données. Vous devrez créer un rôle IAM avec les autorisations suivantes :
Autorisations d'accès au Amazon Redshift cluster ou au groupe de travail
Autorisations permettant de créer et de gérer des bases de données et des tables dans Amazon Redshift
CloudWatch et CloudWatch enregistre les autorisations à des fins de surveillance
Une fois la configuration du Amazon Redshift groupe de travail ou du cluster terminée, vous devez configurer votre entrepôt de données pour les intégrations sans ETL. Pour plus d’informations, reportez-vous à Démarrer avec les intégrations zéro ETL dans le Guide de gestion Amazon Redshift.
Note
Lorsque vous utilisez un entrepôt de Amazon Redshift données comme cible, l'intégration crée un schéma dans la base de données spécifiée pour stocker les données répliquées. Le nom du schéma provient du nom de l’intégration.
Note
Le enable_case_sensitive_identifier paramètre doit être activé dans le Amazon Redshift groupe de travail ou le cluster cible pour que l'intégration soit réussie.
Après avoir configuré l'entrepôt de Amazon Redshift données, vous pouvez Configuration de l’intégration avec votre cible terminer la configuration de l'intégration.
Configuration de l’intégration avec votre cible
Après avoir configuré les ressources source et cible, procédez comme suit pour terminer la configuration de l'intégration :
Accédez à la page « Intégrations zéro ETL » et lancez le flux de travail de création des intégrations.
Sélectionnez la ressource source configurée dans les étapes précédentes.
Sélectionnez ou spécifiez la ressource cible (même compte ou compte croisé) configurée lors des étapes précédentes.
Sélectionnez le rôle IAM cible configuré précédemment.
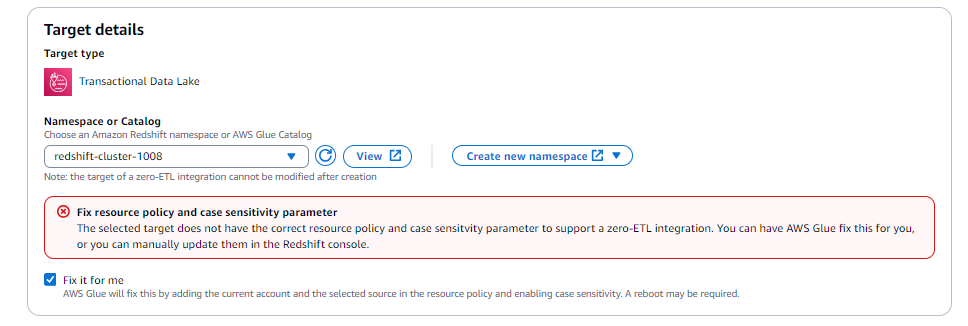
Sélectionnez l'option Corriger le problème pour moi (disponible uniquement lorsque la cible possède le même compte).
Pour les cibles Amazon S3 (AWS Glue base de données) et S3-Table (catalogue) classiques, cela permettra de :
Appliquez un principal de service autorisé à la politique de ressources du catalogue cible.
Appliquez un ARN principal AWS Glue source autorisé à la politique de ressources du catalogue cible.
Pour la Amazon Redshift cible, cela permettra de :
Appliquez un principal de service autorisé sur le Amazon Redshift cluster ou le groupe de travail sans serveur.
Appliquez un ARN AWS Glue source autorisé au Amazon Redshift cluster ou au groupe de travail sans serveur.
Associer un nouveau groupe de paramètres à
enable_case_sensitive_identifier = true.
Utilisez ce qui suit pour créer l'intégration via une API ou une CLI : CreateIntegration API.
