Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Améliorations génératives de l'IA pour Apache Spark in AWS Glue
Spark Upgrades in AWS Glue permet aux ingénieurs de données et aux développeurs de mettre à niveau et de migrer leurs tâches AWS Glue Spark existantes vers les dernières versions de Spark à l'aide de l'IA générative. Les ingénieurs de données peuvent l'utiliser pour scanner leurs tâches AWS Glue Spark, générer des plans de mise à niveau, exécuter des plans et valider les résultats. Cela permet de réduire le temps et le coût des mises à niveau de Spark en automatisant le travail indifférencié d’identification et de mise à jour des scripts, des configurations, des dépendances, des méthodes et des fonctionnalités de Spark.
Comment ça marche
Lorsque vous utilisez l'analyse des mises à niveau, AWS Glue identifie les différences entre les versions et les configurations dans le code de votre tâche afin de générer un plan de mise à niveau. Le plan de mise à niveau détaille toutes les modifications du code et les étapes de migration requises. Ensuite, AWS Glue crée et exécute l'application mise à niveau dans un environnement pour valider les modifications et génère une liste de modifications de code afin que vous puissiez migrer votre travail. Vous pouvez consulter le script mis à jour, ainsi que le résumé détaillant les modifications proposées. Après avoir effectué vos propres tests, acceptez les modifications et le job AWS Glue sera automatiquement mis à jour vers la dernière version avec le nouveau script.
Le processus d’analyse de la mise à niveau peut prendre un certain temps, selon la complexité de la tâche et la charge de travail. Les résultats de l’analyse de la mise à niveau seront stockés dans le chemin Amazon S3 spécifié, qui pourra être consulté pour comprendre la mise à niveau et les éventuels problèmes de compatibilité. Après avoir examiné les résultats de l’analyse de la mise à niveau, vous pouvez décider de poursuivre la mise à niveau proprement dite ou d’apporter les modifications nécessaires à la tâche avant sa mise à niveau.
Conditions préalables
Les prérequis suivants sont requis pour utiliser l'IA générative afin de mettre à niveau les jobs dans AWS Glue :
-
AWS Tâches Glue 2 PySpark : seules les tâches AWS Glue 2 peuvent être mises à niveau vers AWS Glue 5.
-
Les autorisations IAM sont nécessaires pour démarrer l’analyse, examiner les résultats et améliorer votre tâche. Pour plus d’informations, consultez les exemples dans la section Permissions ci-dessous.
-
Si vous l'utilisez AWS KMS pour chiffrer des artefacts d'analyse, des AWS AWS KMS autorisations supplémentaires sont nécessaires. Pour plus d’informations, consultez les exemples dans la section AWS KMS politique ci-dessous.
Permissions
-
Mettez à jour la politique IAM de l’appelant avec l’autorisation suivante :
-
Mettez à jour le rôle d’exécution de la tâche que vous mettez à niveau pour inclure la politique en ligne suivante :
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }Par exemple, si vous utilisez le chemin d’accès à Amazon S3
s3://amzn-s3-demo-bucket/upgraded-result, la politique sera la suivante :{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
AWS KMS politique
Pour transmettre votre propre AWS KMS clé personnalisée lors du démarrage d'une analyse, reportez-vous à la section suivante pour configurer les autorisations appropriées sur les AWS KMS clés.
Cette politique garantit que vous disposez à la fois des autorisations de chiffrement et de déchiffrement sur la AWS KMS clé.
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
Exécution d’une analyse de la mise à niveau et application du script de mise à niveau
Vous pouvez exécuter une analyse de la mise à niveau, qui générera un plan de mise à niveau pour une tâche que vous sélectionnez dans la vue Tâches.
-
Dans Jobs, sélectionnez une tâche AWS Glue 2.0, puis choisissez Run upgrade analysis dans le menu Actions.
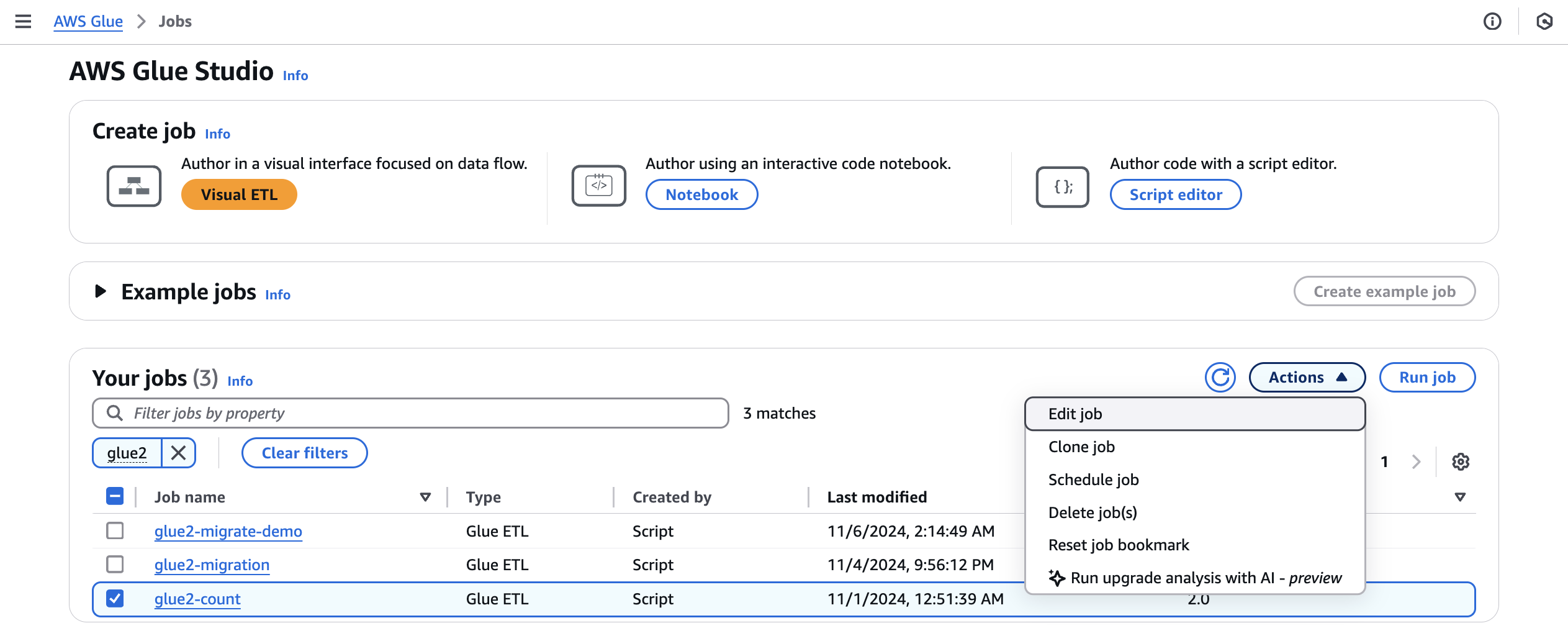
-
Dans la fenêtre modale, sélectionnez un chemin d’accès pour stocker votre plan de mise à niveau généré dans le chemin d’accès aux résultats. Il doit s’agir d’un compartiment Amazon S3 auquel vous pouvez accéder et sur lequel vous pouvez écrire.
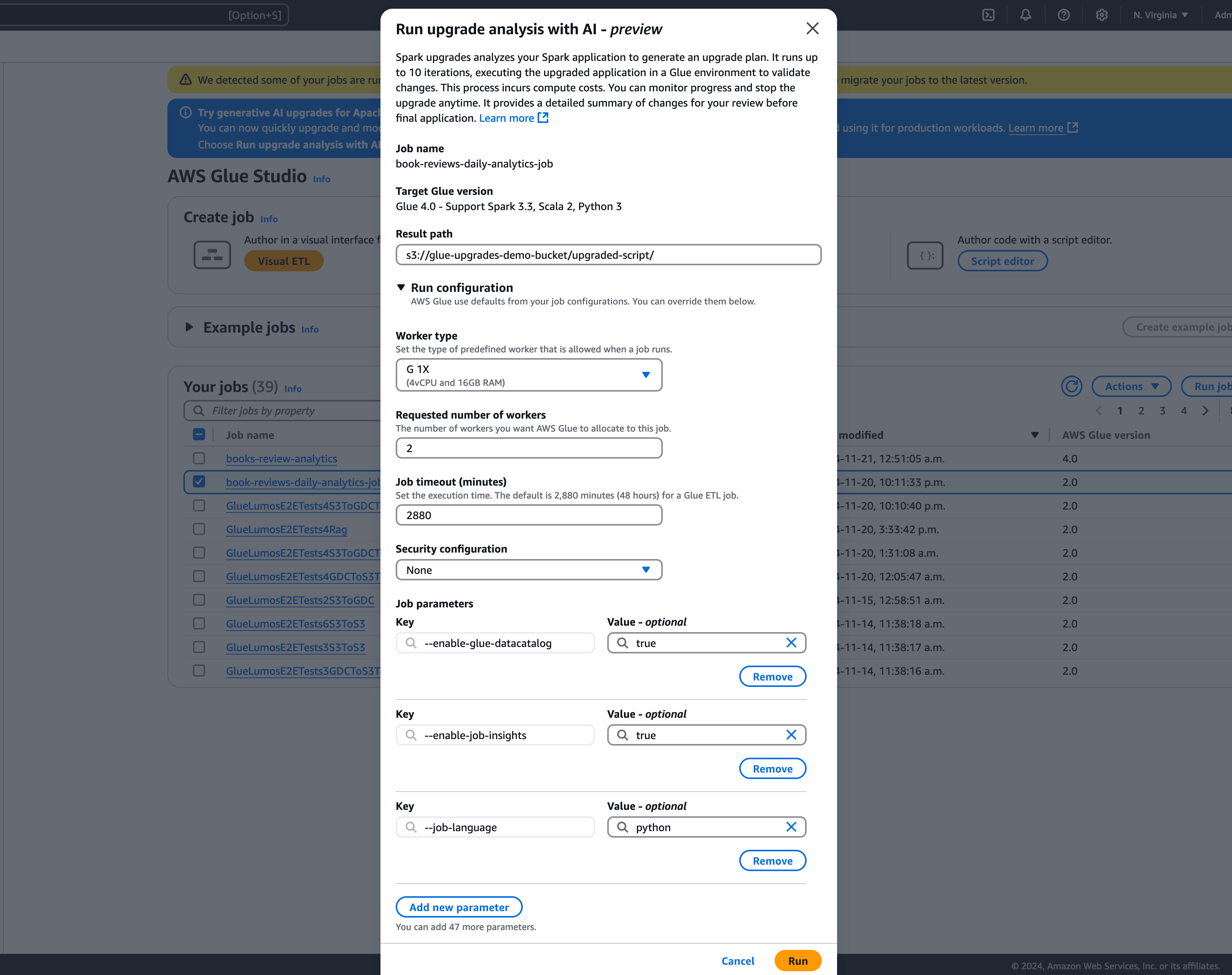
-
Configurez les options supplémentaires au besoin :
-
Configuration d’exécution (facultative) : la configuration d’exécution est un paramètre facultatif qui vous permet de personnaliser divers aspects des cycles de validation effectués lors de l’analyse de la mise à niveau. Cette configuration est utilisée pour exécuter le script mis à niveau et vous permet de sélectionner les propriétés de l’environnement de calcul (type de travailleur, nombre de travailleurs, etc.). Notez que vous devez utiliser vos comptes de développeur hors production pour exécuter les validations sur des exemples de jeux de données avant de vérifier, d’accepter les modifications et de les appliquer aux environnements de production. La configuration d’exécution comprend les paramètres personnalisables suivants :
-
Type de travailleur : vous pouvez spécifier le type de travailleur à utiliser pour les cycles de validation, ce qui vous permet de choisir les ressources de calcul appropriées en fonction de vos besoins.
-
Nombre de travailleurs : vous pouvez définir le nombre de travailleurs à affecter pour les cycles de validation, ce qui vous permet de mettre à l’échelle les ressources en fonction de vos besoins en matière de charge de travail.
-
Délai d’expiration des tâches (en minutes) : ce paramètre vous permet de définir une limite de temps pour les cycles de validation, en veillant à ce que les tâches se terminent après une durée spécifiée afin d’éviter une consommation excessive de ressources.
-
Configuration de la sécurité : vous pouvez configurer les paramètres de sécurité, tels que le chiffrement et le contrôle d’accès, pour garantir la protection de vos données et de vos ressources pendant les cycles de validation.
-
Paramètres de tâche supplémentaires : si nécessaire, vous pouvez ajouter de nouveaux paramètres de tâche afin de personnaliser davantage l’environnement d’exécution pour les cycles de validation.
En tirant parti de la configuration d’exécution, vous pouvez adapter les cycles de validation à vos besoins spécifiques. Par exemple, vous pouvez configurer les cycles de validation pour qu’ils utilisent un jeu de données plus petit, ce qui permet d’effectuer l’analyse plus rapidement et d’optimiser les coûts. Cette approche garantit que l’analyse de la mise à niveau est effectuée efficacement tout en minimisant l’utilisation des ressources et les coûts associés pendant la phase de validation.
-
-
Configuration du chiffrement (facultatif) :
-
Activer le chiffrement des artefacts de mise à niveau : activez le chiffrement au repos lorsque vous écrivez des données dans le chemin des résultats. Si vous ne souhaitez pas chiffrer vos artefacts de mise à niveau, laissez cette option désactivée.
-
-
-
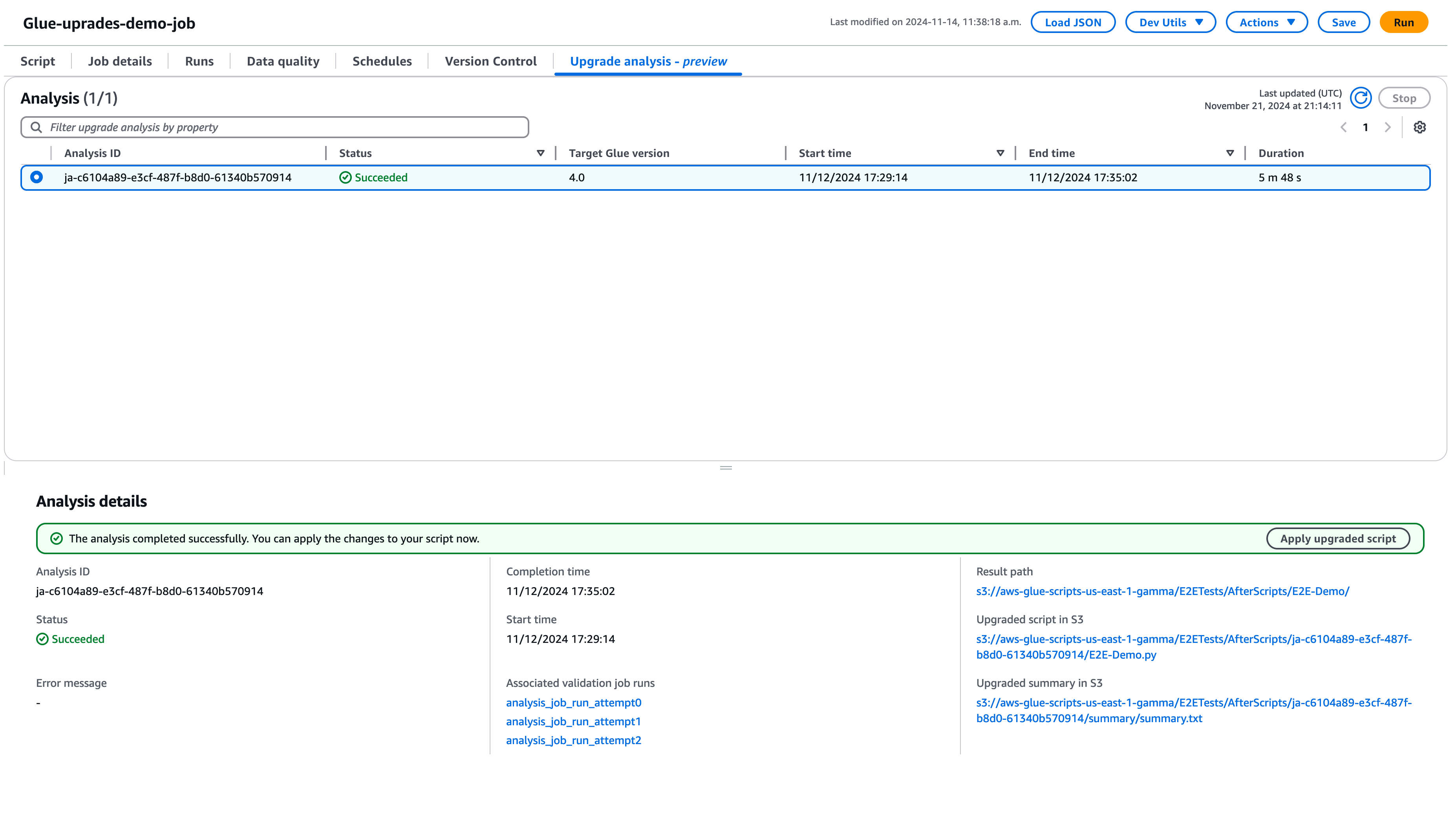
Choisissez Exécuter pour démarrer l’analyse de la mise à niveau. Pendant que l’analyse est en cours, vous pouvez consulter les résultats dans l’onglet Analyse de la mise à niveau. La fenêtre des détails de l’analyse affiche des informations sur l’analyse, ainsi que des liens vers les artefacts de mise à niveau.
-
Chemin d’accès au résultat : c’est à cet endroit que le résumé des résultats et le script de mise à niveau sont stockés.
-
Script mis à niveau dans Amazon S3 : emplacement du script de mise à niveau dans Amazon S3. Vous pouvez afficher le script avant d’appliquer la mise à niveau.
-
Résumé de la mise à niveau dans Amazon S3 : l’emplacement du résumé de la mise à niveau dans Amazon S3. Vous pouvez consulter le résumé de la mise à niveau avant d’appliquer cette dernière.
-
-
Lorsque l’analyse de la mise à niveau se termine correctement, vous pouvez appliquer le script de mise à niveau pour mettre automatiquement à niveau votre tâche en choisissant Appliquer le script mis à niveau.
Une fois appliquée, la version AWS Glue sera mise à jour vers la version 4.0. Vous pouvez consulter le nouveau script dans l’onglet Script.
Comprendre le résumé de votre mise à niveau
Cet exemple illustre le processus de mise à niveau d'une tâche AWS Glue de la version 2.0 à la version 4.0. L’exemple de tâche lit les données du produit depuis un compartiment Amazon S3, applique plusieurs transformations aux données à l’aide de Spark SQL, puis enregistre les résultats transformés dans un compartiment Amazon S3.
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

Sur la base du résumé, quatre modifications ont été proposées par AWS Glue afin de réussir la mise à niveau du script de AWS Glue 2.0 vers AWS Glue 4.0 :
-
Configuration de Spark SQL (spark.sql.adaptive.enabled) : cette modification vise à restaurer le comportement de l’application, car une nouvelle fonctionnalité d’exécution de requêtes adaptatives Spark SQL est introduite à partir de Spark 3.2. Vous pouvez inspecter cette modification de configuration et l’activer ou la désactiver selon les préférences.
-
DataFrame Modification de l'API : l'option path ne peut pas coexister avec d'autres DataFrameReader opérations telles que
load(). Pour conserver le comportement précédent, AWS Glue a mis à jour le script pour ajouter une nouvelle configuration SQL (spark.sql.legacy). pathOptionBehavior.activé). -
Modification de l’API Spark SQL : le comportement de
strfmtdansformat_string(strfmt, obj, ...)a été mis à jour pour interdire0$comme premier argument. Pour garantir la compatibilité, AWS Glue a modifié le script pour l'utiliser1$comme premier argument à la place. -
Modification de l’API Spark SQL : la fonction
unbase64n’autorise pas les entrées de chaîne mal formées. Pour conserver le comportement précédent, AWS Glue a mis à jour le script afin d'utiliser latry_to_binaryfonction.
Arrêt d’une analyse de la mise à niveau en cours
Vous pouvez annuler une analyse de la mise à niveau en cours ou simplement arrêter l’analyse.
-
Choisissez l’onglet Analyse de la mise à niveau.
-
Sélectionnez la tâche en cours d’exécution, puis choisissez Arrêter. Cela arrêtera l’analyse. Vous pouvez ensuite exécuter une autre analyse de la mise à niveau sur la même tâche.

Considérations
Lorsque vous commencez à utiliser Spark Upgrades, vous devez prendre en compte plusieurs aspects importants pour une utilisation optimale du service.
-
Étendue et limites du service : La version actuelle se concentre sur les mises à niveau du PySpark code depuis les versions 2.0 de AWS Glue vers la version 5.0. À l'heure actuelle, le service gère le PySpark code qui ne repose pas sur des dépendances de bibliothèque supplémentaires. Vous pouvez exécuter des mises à niveau automatisées pour un maximum de 10 tâches simultanément dans un AWS compte, ce qui vous permet de mettre à niveau efficacement plusieurs tâches tout en préservant la stabilité du système.
-
Seuls les PySpark emplois sont pris en charge.
-
L’analyse de la mise à niveau expirera au bout de 24 heures.
-
Une seule analyse de la mise à niveau active peut être exécutée à la fois pour une tâche. Au niveau du compte, vous pouvez exécuter jusqu’à 10 analyses de la mise à niveau en même temps.
-
-
Optimisation des coûts pendant le processus de mise à niveau : étant donné que Spark Upgrades utilise l'IA générative pour valider le plan de mise à niveau par le biais de plusieurs itérations, chaque itération étant exécutée sous forme de tâche AWS Glue dans votre compte, il est essentiel d'optimiser les configurations d'exécution des tâches de validation pour des raisons de rentabilité. Pour ce faire, nous vous recommandons de spécifier une configuration d’exécution lors du lancement d’une analyse de la mise à niveau, comme suit :
-
Utilisez des comptes de développeur hors production et sélectionnez des exemples de jeux de données fictifs qui représentent vos données de production, mais dont la taille est réduite pour la validation avec Spark Upgrades.
-
Utilisez des ressources de calcul correctement dimensionnées, telles que des travailleurs G1X, et sélectionnez un nombre approprié de travailleurs pour traiter vos échantillons de données.
-
Activation de l'auto-scaling des tâches AWS Glue, le cas échéant, pour ajuster automatiquement les ressources en fonction de la charge de travail.
Par exemple, si votre tâche de production traite des téraoctets de données avec 20 travailleurs G.2X, vous pouvez configurer la tâche de mise à niveau pour traiter quelques gigaoctets de données représentatives avec 2 travailleurs G.2X et l’autoscaling activé pour la validation.
-
-
Bonnes pratiques : nous vous recommandons vivement de commencer votre processus de mise à niveau par des tâches non liées à la production. Cette approche vous permet de vous familiariser avec le flux de travail de mise à niveau et de comprendre comment le service gère les différents types de modèles de code Spark.
-
Alarmes et notifications : lorsque vous utilisez la fonction de mise à niveau de l'IA générative sur une tâche, assurez-vous qu' alarms/notifications elle est désactivée en cas d'échec des tâches. Au cours du processus de mise à niveau, il se peut que jusqu’à 10 tâches aient échoué dans votre compte avant que les artefacts mis à niveau ne soient fournis.
-
Règles de détection des anomalies : désactivez également les règles de détection des anomalies sur la tâche en cours de mise à niveau, car les données écrites dans les dossiers de sortie lors des exécutions de tâches intermédiaires risquent de ne pas être au format attendu pendant la validation de la mise à niveau.
-
Utiliser l’analyse de la mise à niveau avec les tâches idempotentes : utilisez l’analyse de la mise à niveau avec les tâches idempotentes pour vous assurer que chaque tentative d’exécution de tâche de validation suivante est similaire à la précédente et ne présente aucun problème. Les tâches idempotentes sont des tâches qui peuvent être exécutées plusieurs fois avec les mêmes données d’entrée et qui produiront à chaque fois le même résultat. Lorsque vous utilisez les mises à niveau de Generative AI pour Apache Spark in AWS Glue, le service exécutera plusieurs itérations de votre tâche dans le cadre du processus de validation. Au cours de chaque itération, il apportera des modifications à votre code et à vos configurations Spark afin de valider le plan de mise à niveau. Si votre tâche Spark n’est pas idempotente, l’exécuter plusieurs fois avec les mêmes données d’entrée peut entraîner des problèmes.
Régions prises en charge
Les mises à niveau génératives de l'IA pour Apache Spark sont disponibles dans les régions suivantes :
-
Asie-Pacifique : Tokyo (ap-northeast-1), Séoul (ap-northeast-2), Mumbai (ap-southeast-1), Singapour (ap-southeast-1) et Sydney (ap-southeast-2)
-
Amérique du Nord : Canada (ca-central-1)
-
Europe : Francfort (eu-central-1), Stockholm (eu-nord-1), Irlande (eu-west-1), Londres (eu-west-2) et Paris (eu-west-3)
-
Amérique du Sud : São Paulo (sa-east-1)
-
États-Unis : Virginie du Nord (us-east-1), Ohio (us-east-2) et Oregon (us-west-2)
Inférence entre régions dans Spark Upgrades
Spark Upgrades est alimenté par Amazon Bedrock et exploite l'inférence interrégionale (CRIS). Grâce à l’inférence entre régions, Spark Upgrades sélectionne automatiquement la région optimale au sein de votre zone géographique (comme décrit plus en détail ici) pour traiter votre demande d’inférence, optimisant ainsi les ressources de calcul disponibles et la disponibilité des modèles, et offrant la meilleure expérience client. L’utilisation de l’inférence entre régions n’entraîne aucun coût supplémentaire.
Les demandes d'inférence interrégionales sont conservées dans les AWS régions qui font partie de la zone géographique dans laquelle les données se trouvent à l'origine. Par exemple, une demande faite aux États-Unis est conservée dans les AWS régions des États-Unis. Bien que les données restent stockées uniquement dans la région principale, lorsque vous utilisez l’inférence entre régions, vos invites de saisie et les résultats de sortie peuvent être déplacés en dehors de votre région principale. Toutes les données seront transmises chiffrées sur le réseau sécurisé d’Amazon.
