Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utiliser AWS Glue with AWS Lake Formation pour un contrôle d'accès précis
Présentation de
Avec AWS la version 5.0 et les versions ultérieures de Glue, vous pouvez AWS Lake Formation appliquer des contrôles d'accès précis aux tables du catalogue de données soutenues par S3. Cette fonctionnalité vous permet de configurer des contrôles d’accès au niveau des tables, des lignes, des colonnes et des cellules pour les requêtes read contenues dans vos tâches AWS Glue pour Apache Spark. Consultez les sections suivantes pour en savoir plus sur Lake Formation et sur son utilisation avec AWS Glue.
GlueContextle contrôle d'accès basé sur une table avec des AWS Lake Formation autorisations prises en charge dans Glue 4.0 ou antérieur n'est pas pris en charge dans Glue 5.0. Utilisez le nouveau contrôle précis des accès (FGAC) natif Spark de Glue 5.0. Prenez note des détails suivants :
Si vous avez besoin d'un contrôle d'accès détaillé (FGAC) pour le contrôle row/column/cell d'accès, vous devez migrer depuis
GlueContextDynamicFrame /Glue dans Glue 4.0 et avant le dataframe Spark dans Glue 5.0. Pour obtenir des exemples, consultez Migration de Spark GlueContext/Glue DynamicFrame vers Spark DataFrameSi vous avez besoin d'un contrôle d'accès complet aux tables (FTA), vous pouvez tirer parti du FTA dans DynamicFrames AWS Glue 5.0. Vous pouvez également migrer vers l'approche native de Spark pour bénéficier de fonctionnalités supplémentaires telles que les ensembles de données distribués résilients (RDDs), les bibliothèques personnalisées et les fonctions définies par l'utilisateur (UDFs) avec des AWS Lake Formation tables. Pour des exemples, voir Migration de AWS Glue 4.0 vers AWS Glue 5.0.
Si vous n’avez pas besoin de FGAC, aucune migration vers le dataframe Spark n’est nécessaire et les fonctionnalités
GlueContexttelles que les signets de tâches et le déploiement des prédicats continueront de fonctionner.Les tâches avec FGAC nécessitent un minimum de quatre travailleurs : un pilote utilisateur, un pilote système, un exécuteur système et un exécuteur utilisateur de secours.
L'utilisation AWS de Glue with AWS Lake Formation entraîne des frais supplémentaires.
Comment fonctionne AWS Glue avec AWS Lake Formation
L'utilisation de AWS Glue with Lake Formation vous permet d'appliquer une couche d'autorisations à chaque tâche Spark afin d'appliquer le contrôle des autorisations de Lake Formation lorsque AWS Glue exécute des tâches. AWS Glue utilise les profils de ressources Spark
Voici un aperçu général de la manière dont AWS Glue accède aux données protégées par les politiques de sécurité de Lake Formation.
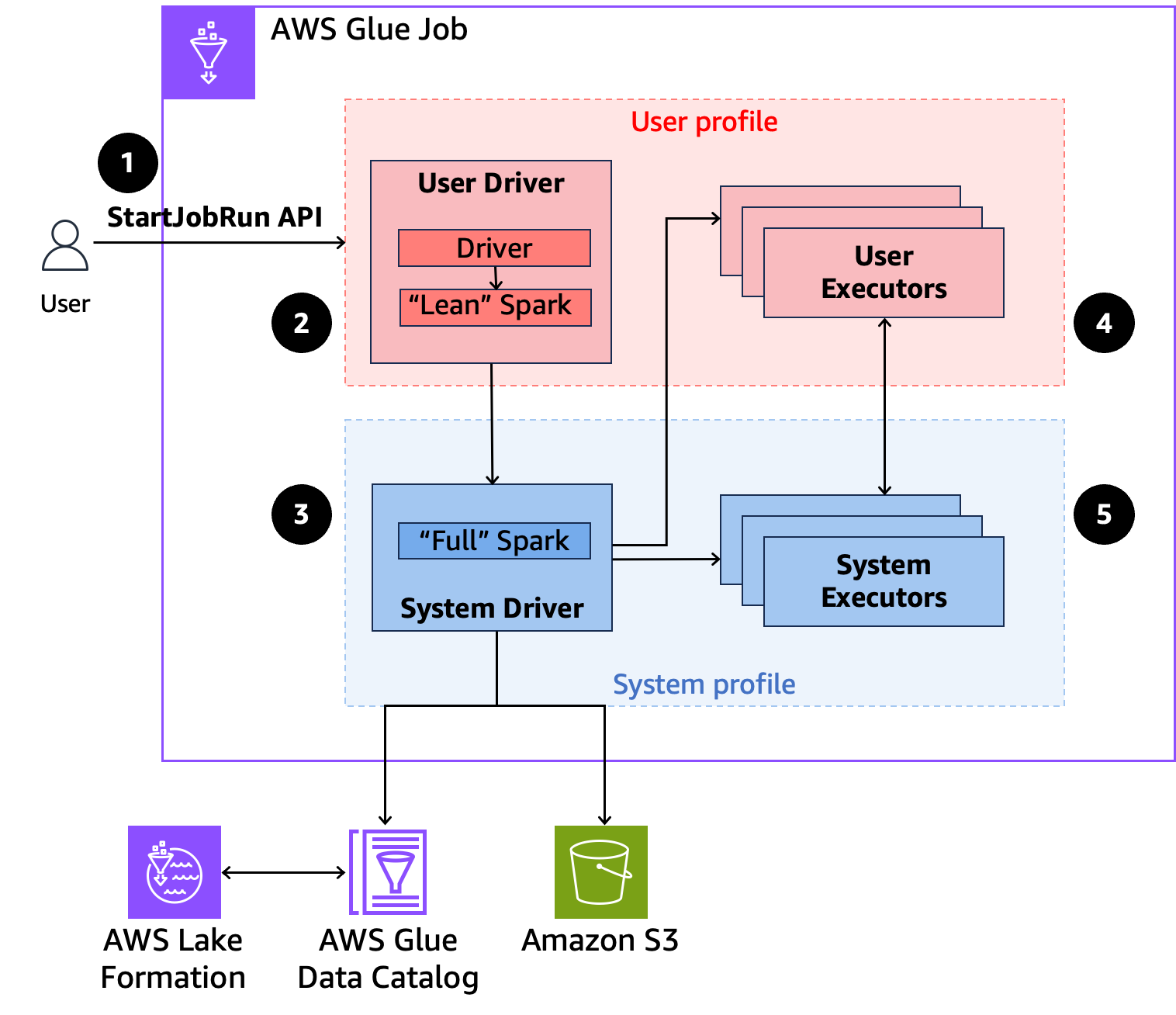
-
Un utilisateur appelle l'
StartJobRunAPI sur une tâche AWS Glue compatible avec AWS Lake Formation. -
AWS Glue envoie la tâche à un pilote utilisateur et l'exécute dans le profil utilisateur. Le pilote utilisateur exécute une version allégée de Spark qui n’est pas en mesure de lancer des tâches, de demander des exécuteurs, d’accéder à S3 ni au catalogue Glue. Il crée un plan de tâche.
-
AWS Glue configure un deuxième pilote appelé pilote système et l'exécute dans le profil système (avec une identité privilégiée). AWS Glue met en place un canal TLS crypté entre les deux pilotes pour la communication. Le pilote utilisateur utilise le canal pour envoyer les plans de tâche au pilote système. Le pilote système n’exécute pas le code soumis par l’utilisateur. Il exécute Spark dans son intégralité et communique avec S3 et le catalogue de données pour l’accès aux données. Il demande des exécuteurs et compile le plan de tâche en une séquence d’étapes d’exécution.
-
AWS Glue exécute ensuite les étapes sur les exécuteurs avec le pilote utilisateur ou le pilote système. À n’importe quelle étape, le code utilisateur est exécuté exclusivement sur les exécuteurs de profil utilisateur.
-
Les étapes qui lisent les données des tables du catalogue de données protégées par des filtres de sécurité AWS Lake Formation ou qui appliquent des filtres de sécurité sont déléguées aux exécuteurs du système.
Exigences de minimum de travailleurs
Une tâche compatible avec Lake Formation dans AWS Glue nécessite un minimum de 4 travailleurs : un pilote utilisateur, un pilote système, un exécuteur système et un exécuteur utilisateur de secours. Cela représente une augmentation par rapport au minimum de 2 travailleurs requis pour les travaux standard de AWS Glue.
Une tâche compatible avec Lake Formation dans AWS Glue utilise deux pilotes Spark, l'un pour le profil système et l'autre pour le profil utilisateur. De même, les exécuteurs sont également divisés en deux profils :
Exécuteurs système : gèrent les tâches auxquelles les filtres de données de Lake Formation sont appliqués.
Exécuteurs utilisateur : sont demandés par le pilote système selon les besoins.
Comme les jobs de Spark sont par nature paresseux, AWS Glue réserve 10 % du nombre total de travailleurs (minimum 1), après déduction des deux facteurs, aux exécuteurs utilisateurs.
L’autoscaling est activé pour toutes les tâches compatibles avec Lake Formation, ce qui signifie que les exécuteurs utilisateur ne démarrent qu’en cas de besoin.
Pour un exemple de configuration, consultez Considerations and limitations.
Autorisations IAM du rôle d’exécution des tâches
Les autorisations de Lake Formation contrôlent l'accès aux ressources du catalogue de données AWS Glue, aux sites Amazon S3 et aux données sous-jacentes de ces sites. Les autorisations IAM contrôlent l'accès à la Lake Formation and AWS Glue APIs et aux ressources. Bien que vous ayez l’autorisation Lake Formation d’accéder à une table du catalogue de données (SELECT), votre opération échoue si vous ne disposez pas de l’autorisation IAM sur l’opération d’API glue:Get*.
Voici un exemple de politique expliquant comment fournir les autorisations IAM pour accéder à un script dans Amazon S3, le chargement de journaux sur S3, les autorisations d’API AWS Glue et les autorisations d’accès à Lake Formation.
Configuration des autorisations de Lake Formation pour le rôle d’exécution des tâches
Tout d’abord, enregistrez l’emplacement de votre table Hive avec Lake Formation. Créez ensuite des autorisations pour votre rôle d’exécution des tâches dans la table de votre choix. Pour plus de détails sur Lake Formation, voir Qu'est-ce que c'est AWS Lake Formation ? dans le Guide AWS Lake Formation du développeur.
Après avoir configuré les autorisations de Lake Formation, vous pouvez soumettre des tâches Spark sur AWS Glue.
Soumission d’une exécution de tâche
Une fois que vous aurez fini de configurer les subventions Lake Formation, vous pourrez soumettre des jobs Spark sur AWS Glue. Pour exécuter des tâches Iceberg, vous devez fournir les configurations Spark suivantes. Pour configurer via les paramètres de tâche Glue, entrez le paramètre suivant :
Clé :
--confValeur :
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
Utilisation d’une session interactive
Une fois que vous avez fini de configurer les AWS Lake Formation subventions, vous pouvez utiliser Interactive Sessions on AWS Glue. Vous devez fournir les configurations Spark suivantes via la commande magique %%configure avant d’exécuter le code.
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
FGAC for AWS Glue 5.0 Notebook ou sessions interactives
Pour activer le contrôle d'accès fin (FGAC) dans AWS Glue, vous devez spécifier les configurations Spark requises pour Lake Formation dans le cadre de la magie de %%configure avant de créer la première cellule.
Une spécification ultérieure à l’aide des appels SparkSession.builder().conf("").get() ou ne SparkSession.builder().conf("").create() suffira pas. Il s'agit d'une modification par rapport au comportement de AWS Glue 4.0.
Prise en charge du format de tableau ouvert
AWS La version 5.0 ou ultérieure de Glue inclut la prise en charge d'un contrôle d'accès précis basé sur Lake Formation. AWS Glue est compatible avec les tables Hive et Iceberg. Le tableau suivant décrit toutes les options prises en charge.
| Opérations | Hive | Iceberg |
|---|---|---|
| Commandes DDL | Avec des autorisations de rôle IAM uniquement | Avec des autorisations de rôle IAM uniquement |
| Requêtes progressives | Non applicable | Entièrement pris en charge |
| Requêtes Time Travel | Non applicable à ce format de table | Entièrement pris en charge |
| Tables de métadonnées | Non applicable à ce format de table | Pris en charge, mais certaines tables sont masquées Pour plus d’informations, consultez Considerations and limitations. |
DML INSERT |
Avec des autorisations IAM uniquement | Avec des autorisations IAM uniquement |
| DML UPDATE | Non applicable à ce format de table | Avec des autorisations IAM uniquement |
DML DELETE |
Non applicable à ce format de table | Avec des autorisations IAM uniquement |
| Opérations de lecture | Entièrement pris en charge | Entièrement pris en charge |
| Procédures stockées | Non applicable | Pris en charge à l’exception de register_table et de migrate Pour plus d’informations, consultez Considerations and limitations. |
