Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migrating AWS Glue pour que les tâches Spark soient AWS Glue version 5.0
Cette rubrique décrit les modifications apportées entre AWS Glue les versions 0.9, 1.0, 2.0, 3.0 et 4.0 pour vous permettre de migrer vos applications Spark et vos tâches ETL vers la AWS Glue version 5.0. Il décrit également les fonctionnalités de la AWS Glue version 5.0 et les avantages de son utilisation.
Pour utiliser cette fonctionnalité avec vos tâches AWS Glue ETL, 5.0 choisissez-la Glue version lors de la création de vos tâches.
Rubriques
Nouvelles fonctionnalités
Cette section décrit les nouvelles fonctionnalités et les avantages de la AWS Glue version 5.0.
-
Mise à jour d'Apache Spark de la version 3.3.0 dans la AWS Glue version 4.0 à la version 3.5.4 dans AWS Glue la version 5.0. Consultez Améliorations majeures de Spark 3.3.0 à Spark 3.5.4.
-
Spark-native contrôle d'accès détaillé (FGAC) à l'aide de Lake Formation. Cela inclut FGAC pour les tables Iceberg, Delta et Hudi. Pour plus d'informations, consultez la section Utilisation AWS Glue avec AWS Lake Formation pour un contrôle d'accès précis.
Notez les considérations ou limites suivantes pour le Spark-native FGAC :
Actuellement, les écritures de données ne sont pas prises en charge.
Pour écrire dans Iceberg via
GlueContexten utilisant Lake Formation, vous devez plutôt utiliser le contrôle d’accès IAM.
Pour une liste complète des limites et des considérations relatives à l'utilisation du Spark-native FGAC, voirConsidérations et restrictions.
-
Support des subventions d'accès Amazon S3 en tant que solution de contrôle d'accès évolutive à vos données Amazon S3 depuis AWS Glue. Pour de plus amples informations, veuillez consulter Utilisation d'Amazon S3 Access Grants avec AWS Glue.
-
Open Table Formats (OTF) mis à jour vers Hudi 0.15.0, Iceberg 1.7.1 et Delta Lake 3.3.0
-
Support d'Amazon SageMaker Unified Studio.
-
Amazon SageMaker Lakehouse et intégration de l'abstraction de données. Pour de plus amples informations, veuillez consulter Interrogation de catalogues de données de métastore à partir de AWS Glue ETL.
-
Prise en charge pour installer des bibliothèques Python supplémentaires à l’aide de
requirements.txt. Pour de plus amples informations, veuillez consulter Installation de bibliothèques Python supplémentaires dans AWS Glue 5.0 ou version ultérieure à l'aide de requirements.txt. -
AWS Glue La version 5.0 prend en charge le lignage des données sur Amazon DataZone. Vous pouvez configurer AWS Glue pour collecter automatiquement des informations de lignage lors de l'exécution des tâches Spark et envoyer les événements de lignage à visualiser sur Amazon. DataZone Pour plus d'informations, consultez la section Lignage des données sur Amazon DataZone.
Pour le configurer sur la AWS Glue console, activez Generate lineage events et saisissez votre identifiant de DataZone domaine Amazon dans l'onglet Job details.
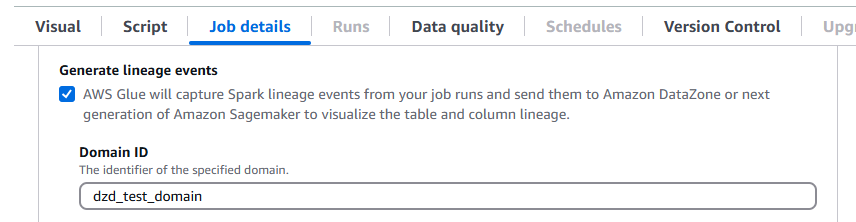
Vous pouvez également fournir le paramètre de tâche suivant (indiquez votre ID de DataZone domaine) :
Clé :
--confValeur :
extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener —conf spark.openlineage.transport.type=amazon_datazone_api -conf spark.openlineage.transport.domainId=<your-domain-ID>
-
Mises à jour du connecteur et du pilote JDBC. Pour plus d’informations, consultez Annexe B : Mises à niveau du pilote JDBC et Annexe C : Mises à niveau des connecteurs.
-
Mise à jour de Java de la version 8 vers la version 17.
-
Stockage accru pour les
G.2Xemployés AWS GlueG.1Xet les employés, l'espace disque passant respectivement à 94 Go et 138 Go. De plus, de nouveaux types deG.12Xtravailleurs et des outils optimisés pour la mémoireR.1XR.8Xsont disponibles dans les AWS Glue versions 4.0 et ultérieures.G.16XR.2XR.4XPour de plus amples informations, consultez Tâches. Support pour les tâches AWS SDK for Java, versions 2 AWS Glue à 5.0, peuvent utiliser les versions
1.12.569 ou 2.28.8 pour Java si la tâche prend en charge la version v2. Le AWS SDK pour Java 2.x est une réécriture majeure de la base de code de la version 1.x. Il repose sur Java 8+ et ajoute plusieurs fonctionnalités fréquemment demandées. Il s'agit notamment de la prise en charge du non-blocage I/O et de la possibilité de connecter une implémentation HTTP différente lors de l'exécution. Pour plus d’informations, notamment un Guide de migration du kit SDK pour la version 1 de Java vers la version 2, consultez le guide du Kit SDK AWS pour Java, version 2.
Évolutions
Prenez note des modifications majeures suivantes :
-
Dans la AWS Glue version 5.0, lorsque vous utilisez le système de fichiers S3A et si `fs.s3a.endpoint` et `fs.s3a.endpoint.region` ne sont pas définis, la région par défaut utilisée par S3A est `us-east-2`. Cela peut entraîner des problèmes, tels que des erreurs de délai de chargement dans S3, en particulier pour les tâches VPC. Pour atténuer les problèmes causés par cette modification, définissez la configuration Spark `fs.s3a.endpoint.region` lorsque vous utilisez le système de fichiers S3A dans la version 5.0. AWS Glue
-
Contrôle d' Fine-grained accès aux formations lacustres (FGAC)
-
AWS Glue La version 5.0 ne prend en charge le nouveau Spark-native FGAC qu'avec Spark DataFrames. Il ne prend pas en charge l'utilisation AWS Glue DynamicFrames du FGAC.
-
L'utilisation de FGAC dans la version 5.0 nécessite une migration depuis Spark AWS Glue DynamicFrames DataFrames
-
Si vous n'avez pas besoin du FGAC, il n'est pas nécessaire de migrer vers Spark DataFrame et les GlueContext fonctionnalités, telles que les signets de tâches et les prédicats push down, continueront de fonctionner.
-
-
Les tâches au Spark-native sein du FGAC nécessitent un minimum de 4 travailleurs : un pilote utilisateur, un pilote système, un exécuteur système et un exécuteur utilisateur de secours.
-
Pour plus d'informations, consultez la section Utilisation AWS Glue avec AWS Lake Formation pour un contrôle d'accès précis.
-
-
Accès complet aux tables (FTA) Lake Formation
-
AWS Glue 5.0 prend en charge le FTA avec Spark-native DataFrames (nouveau) et GlueContext DynamicFrames (ancien, avec des limites)
-
Spark-native ALE
-
Si le script 4.0 l'utilise GlueContext, migrez vers Native Spark.
-
Cette fonctionnalité est limitée aux tables Hive et Iceberg.
-
Pour plus d'informations sur la configuration d'une tâche 5.0 pour utiliser le FTA natif de Spark, consultezNative Spark FTA en version 5.0 AWS Glue.
-
-
GlueContext DynamicFrame ALE
-
Aucune modification de code requise
-
Cette fonctionnalité est limitée aux tables non OTF. Elle ne fonctionnera pas avec Iceberg, Delta Lake et Hudi.
-
-
Le lecteur CSV SIMD vectorisé n’est pas pris en charge.
La journalisation continue dans le groupe de journaux de sortie n’est pas prise en charge. Utilisez plutôt un groupe de journaux
error.Le AWS Glue Job Run Insights
job-insights-rule-driverest devenu obsolète. Le flux de journauxjob-insights-rca-driverse trouve désormais dans le groupe des journaux d’erreurs.Athena-based custom/marketplace les connecteurs ne sont pas pris en charge.
Les connecteurs Adobe Marketo Engage, Facebook Ads, Google Ads, Google Analytics 4, Google Sheets, Hubspot, Instagram Ads, Intercom, Jira Cloud, Oracle, Salesforce, Salesforce Marketing Cloud NetSuite, Salesforce Marketing Cloud Account Engagement, SAP OData, Slack, Snapchat Ads, Stripe ServiceNow, Zendesk et Zoho CRM ne sont pas pris en charge.
Les propriétés log4j personnalisées ne sont pas prises en charge dans AWS Glue la version 5.0.
Améliorations majeures de Spark 3.3.0 à Spark 3.5.4
Notez les améliorations suivantes :
-
Client Python pour Spark Connect (SPARK-39375
). -
Implémentez la prise en charge des valeurs DEFAULT pour les colonnes des tables (SPARK-38334
). -
Support « Références d'alias de colonne latérale » (SPARK-27561
). -
Renforcez l'utilisation de SQLSTATE pour les classes d'erreur (). SPARK-41994
-
Activez les jointures du filtre Bloom par défaut (SPARK-38841
). -
Amélioration de l'évolutivité de l'interface utilisateur Spark et de la stabilité des pilotes pour les applications volumineuses (SPARK-41053
). -
Suivi de la progression asynchrone dans le streaming structuré (SPARK-39591
). -
Traitement dynamique arbitraire en Python dans le streaming structuré (SPARK-40434
). -
Améliorations de la couverture de l'API Pandas (SPARK-42882
) et de la prise en charge des NumPy entrées dans PySpark (SPARK-39405 ). -
Fournissez un profileur de mémoire pour les fonctions PySpark définies par l'utilisateur () SPARK-40281
. -
PyTorch Distributeur d'outils (SPARK-41589
). -
Publiez des artefacts SBOM () SPARK-41893
. -
IPv6-only Environnement de support (SPARK-39457
). -
Planificateur K8s personnalisé (Apache YuniKorn et Volcano) GA (). SPARK-42802
-
Support client Scala et Go dans Spark Connect (SPARK-42554
) et (SPARK-43351 ). -
PyTorch-based Support ML distribué pour Spark Connect (SPARK-42471
). -
Support de streaming structuré pour Spark Connect en Python et Scala (SPARK-42938
). -
Support de l'API Pandas pour le client Python Spark Connect (SPARK-42497
). -
Introduisez Arrow Python UDFs (SPARK-40307
). -
Support des fonctions de table définies par l'utilisateur en Python (SPARK-43798
). -
Migrez PySpark les erreurs vers les classes d'erreurs (SPARK-42986
). -
PySpark framework de test (SPARK-44042
). -
Ajoutez le support pour Datasketches HllSketch () SPARK-16484
. -
Built-in Amélioration de la fonction SQL (SPARK-41231
). -
Clause IDENTIFIER (SPARK-43205
). -
Ajoutez des fonctions SQL dans Scala, Python et R API (SPARK-43907
). -
Ajoutez le support des arguments nommés pour les fonctions SQL (SPARK-43922
). -
Évitez de réexécuter une tâche inutile en cas de perte d'un exécuteur hors service en cas de migration des données shuffle (). SPARK-41469
-
ML distribué <> spark connect (SPARK-42471
). -
DeepSpeed distributeur (SPARK-44264
). -
Implémentez le point de contrôle du journal des modifications pour RockSDB state store (). SPARK-43421
-
Introduisez la propagation des filigranes entre les opérateurs (SPARK-42376
). -
Introduisez drop DuplicatesWithinWatermark (SPARK-42931
). -
Améliorations apportées à la gestion de la mémoire du fournisseur RockSDB State Store () SPARK-43311
.
Actions de migration vers AWS Glue 5.0
Pour les tâches existantes, modifiez la Glue version depuis la version précédente vers Glue 5.0 dans la configuration de la tâche.
-
Dans AWS Glue Studio, choisissez «
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3inGlue version». -
Dans l’API, choisissez
5.0dans le paramètreGlueVersionde l’opération d’APIUpdateJob.
Pour les nouvelles tâches, choisissez Glue 5.0 lorsque vous créez une tâche.
-
Dans la console, choisissez
Spark 3.5.4, Python 3 (Glue Version 5.0) or Spark 3.5.4, Scala 2 (Glue Version 5.0)dansGlue version. -
Dans AWS Glue Studio, choisissez «
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3inGlue version». -
Dans l’API, choisissez
5.0dans le paramètreGlueVersionde l’opération d’APICreateJob.
Pour consulter les journaux d'événements Spark de la AWS Glue version 5.0 à partir de la version AWS Glue 2.0 ou d'une version antérieure, lancez un serveur d'historique Spark mis à niveau pour la AWS Glue version 5.0 à l'aide CloudFormation de Docker.
Liste de contrôle de migration
Consultez cette liste de contrôle pour la migration :
-
Mises à jour de Java 17
-
[Scala] Mettre à niveau les appels du AWS SDK de la v1 à la v2
-
Migration de Python 3.10 vers Python 3.11
-
[Python] Mise à jour des références boto de la version 1.26 vers la version 1.34
AWS Glue Caractéristiques de la version 5.0
Cette section décrit les AWS Glue fonctionnalités de manière plus détaillée.
Interrogation de catalogues de données de métastore à partir de AWS Glue ETL
Vous pouvez enregistrer votre AWS Glue travail pour accéder au AWS Glue Data Catalog, qui met les tables et autres ressources de métastore à la disposition de clients disparates. Le catalogue de données prend en charge une hiérarchie de catalogues multiples, qui unifie toutes vos données dans les lacs de données Amazon S3. Il fournit également une API de métastore Hive et une API Apache Iceberg open source pour accéder aux données. Ces fonctionnalités sont disponibles pour AWS Glue d'autres services axés sur les données tels qu'Amazon EMR, Amazon Athena et Amazon Redshift.
Lorsque vous créez des ressources dans le catalogue de données, vous pouvez y accéder à partir de n'importe quel moteur SQL prenant en charge l'API REST Apache Iceberg. AWS Lake Formation gère les autorisations. Après la configuration, vous pouvez tirer parti des capacités AWS Glue de l'application pour interroger des données disparates en interrogeant ces ressources de métastore avec des applications familières. Il s’agit notamment d’Apache Spark et de Trino.
Organisation des ressources de métadonnées
Les données sont organisées selon une hiérarchie logique de catalogues, de bases de données et de tables, à l' AWS Glue Data Catalog aide des éléments suivants :
Catalogue : conteneur logique qui contient des objets provenant d’un entrepôt de données, tels que des schémas ou des tables.
Base de données : organise les objets de données tels que les tables et les vues dans un catalogue.
Tables et vues : objets de données d’une base de données qui fournissent une couche d’abstraction avec un schéma compréhensible. Ils facilitent l’accès aux données sous-jacentes, qui peuvent être dans différents formats et à différents emplacements.
Migration à partir de AWS Glue 4,0 à AWS Glue 5.0
Tous les paramètres de travail existants et les principales fonctionnalités qui existent dans la AWS Glue version 4.0 existeront dans la AWS Glue version 5.0, à l'exception des transformations liées à l'apprentissage automatique.
Les nouveaux paramètres suivants ont été ajoutés :
-
--enable-lakeformation-fine-grained-access: Active la fonctionnalité de contrôle d'accès détaillé (FGAC) dans les tables de AWS Lake Formation.
Reportez-vous à la documentation sur la migration de Spark :
Migration à partir de AWS Glue 3,0 à AWS Glue 5.0
Note
Pour les étapes de migration liées à la AWS Glue version 4.0, voirMigration de la AWS Glue version 3.0 à AWS Glue la version 4.0.
Tous les paramètres de travail existants et les fonctionnalités principales qui existent dans la AWS Glue version 3.0 existeront dans la AWS Glue version 5.0, à l'exception des transformations de machine learning.
Migration à partir de AWS Glue 2,0 à AWS Glue 5.0
Note
Pour les étapes de migration liées à la version AWS Glue 4.0 et la liste des différences de migration entre les AWS Glue versions 3.0 et 4.0, voirMigration de la AWS Glue version 3.0 à AWS Glue la version 4.0.
Notez également les différences de migration suivantes entre AWS Glue les versions 3.0 et 2.0 :
Tous les paramètres de travail existants et les fonctionnalités principales qui existent dans la AWS Glue version 2.0 existeront dans la AWS Glue version 5.0, à l'exception des transformations de machine learning.
Plusieurs modifications Spark peuvent à elles seules nécessiter une révision de vos scripts pour s’assurer que les fonctions supprimées ne sont pas référencées. Par exemple, Spark 3.1.1 et versions ultérieures n'active pas les Scala-untyped UDF, mais Spark 2.4 les autorise.
Python 2.7 n’est pas pris en charge.
Tout fichier jar supplémentaire fourni dans les tâches AWS Glue 2.0 existantes peut entraîner des dépendances conflictuelles, car plusieurs dépendances ont été mises à niveau. Vous pouvez éviter les conflits de chemin de classe avec le paramètre de tâche
--user-jars-first.Modifications du comportement des fichiers loading/saving de from/to parquet horodatés. Pour plus de détails, veuillez consulter Mise à niveau de Spark SQL 3.0 vers 3.1.
Parallélisme différent des tâches Spark pour driver/executor la configuration. Vous pouvez ajuster le parallélisme des tâches en transmettant l’argument de la tâche
--executor-cores.
Le comportement de journalisation change dans AWS Glue 5.0
Les modifications apportées au comportement de journalisation dans la AWS Glue version 5.0 sont les suivantes. Pour plus d'informations, consultez la section Journalisation des AWS Glue tâches.
-
Tous les journaux (journaux du système, journaux de démon Spark, journaux des utilisateurs et journaux Glue Logger) sont désormais écrits dans le groupe de journaux
/aws-glue/jobs/errorpar défaut. -
Le groupe de journaux
/aws-glue/jobs/logs-v2utilisé pour la journalisation continue dans les versions précédentes n’est plus utilisé. -
Vous ne pouvez plus renommer ou personnaliser les noms des groupes de journaux ou des flux de journaux à l’aide des arguments de journalisation continue supprimés. Consultez plutôt les nouveaux arguments de tâche dans la AWS Glue version 5.0.
Deux nouveaux arguments relatifs à l'emploi sont introduits dans AWS Glue 5.0
-
––custom-logGroup-prefix: vous permet de spécifier un préfixe personnalisé pour les groupes de journaux/aws-glue/jobs/erroret/aws-glue/jobs/output. -
––custom-logStream-prefix: vous permet de spécifier un préfixe personnalisé pour les noms des flux de journaux au sein des groupes de journaux.Les règles de validation et les restrictions relatives aux préfixes personnalisés sont les suivantes :
-
Le nom complet du flux de journaux doit comporter entre 1 et 512 caractères.
-
Le préfixe personnalisé pour les noms des flux de journaux est limité à 400 caractères.
-
Les caractères autorisés dans les préfixes incluent les caractères alphanumériques, les traits de soulignement (« _ »), les traits d’union (« - ») et les barres obliques (« / »).
-
Arguments de journalisation continue obsolètes dans AWS Glue 5.0
Les arguments de tâche suivants pour la journalisation continue ont été déconseillés dans la version 5.0 AWS Glue
-
––enable-continuous-cloudwatch-log -
––continuous-log-logGroup -
––continuous-log-logStreamPrefix -
––continuous-log-conversionPattern -
––enable-continuous-log-filter
Migration du connecteur et du pilote JDBC pour AWS Glue 5.0
Pour en savoir plus sur les versions des connecteurs JDBC et de lac de données qui ont été mises à niveau, consultez :
Les modifications suivantes s’appliquent aux versions du connecteur ou du pilote identifiées dans les annexes de Glue 5.0.
Amazon Redshift
Notez les modifications suivantes :
Ajoute la prise en charge des noms de table en trois parties pour permettre au connecteur d’interroger les tables de partage de données Redshift.
Corrige le mappage de Spark
ShortTypepour utiliser RedshiftSMALLINTplutôt queINTEGER, afin de mieux correspondre à la taille de données attendue.Ajout de la prise en charge des noms de cluster personnalisés (CNAME) pour Amazon Redshift sans serveur.
Apache Hudi
Notez les modifications suivantes :
Prise en charge des indices au niveau des enregistrements.
Prise en charge de la génération automatique de clés d’enregistrement. Vous n’avez plus besoin de spécifier le champ de clé d’enregistrement.
Apache Iceberg
Notez les modifications suivantes :
Support d'un contrôle d'accès précis avec. AWS Lake Formation
Prise en charge du branchement et du balisage, qui sont des références nommées à des instantanés dotés de leur propre cycle de vie indépendant.
Ajout d’une procédure d’affichage du journal des modifications qui génère une vue contenant les modifications apportées à une table au cours d’une période spécifiée ou entre des instantanés spécifiques.
Delta Lake
Notez les modifications suivantes :
Support du format Delta Universal (UniForm) qui permet un accès fluide via Apache Iceberg et Apache Hudi.
Support des vecteurs de suppression qui implémentent un Merge-on-Read paradigme.
AzureCosmos
Notez les modifications suivantes :
Ajout de la prise en charge des clés de partition hiérarchiques.
Ajout d'une option permettant d'utiliser un schéma personnalisé avec StringType (json brut) pour une propriété imbriquée.
Ajout d'une option
spark.cosmos.auth.aad.clientCertPemBase64de configuration pour permettre d'utiliser l'authentification SPN (ServicePrincipal nom) avec un certificat au lieu du secret client.
Pour plus d’informations, consultez Azure Cosmos DB Spark connector change log
Microsoft SQL Server
Notez les modifications suivantes :
Le chiffrement TLS est activé par défaut.
Lorsque encrypt = false, mais que le serveur exige le chiffrement, le certificat est validé en fonction du paramètre de connexion
trustServerCertificate.aadSecurePrincipalIdetaadSecurePrincipalSecretsont obsolètes.API
getAADSecretPrincipalIdsupprimée.Résolution CNAME ajoutée lorsque le domaine est spécifié.
MongoDB
Notez les modifications suivantes :
Prise en charge du mode microlots avec Spark Structured Streaming.
Prise en charge des types de données BSON.
Ajout de la prise en charge de la lecture de plusieurs collections lors de l’utilisation des modes microlots ou de streaming continu.
Si le nom d’une collection utilisée dans votre option de configuration
collectioncontient une virgule, le connecteur Spark la traite comme deux collections différentes. Pour éviter ceci, échappez la virgule en la faisant précéder d’une barre oblique inverse (\).Si le nom d’une collection utilisée dans votre option de configuration
collectionest « * », le connecteur Spark l’interprète comme une spécification pour analyser toutes les collections. Pour éviter ceci, échappez l’astérisque en le faisant précéder d’une barre oblique inverse (\).Si le nom d’une collection utilisée dans votre option de configuration
collectioncontient une barre oblique inverse (\), le connecteur Spark traite la barre oblique inverse comme un caractère d’échappement, ce qui peut modifier la façon dont il interprète la valeur. Pour éviter cela, vous devez échapper la barre oblique inverse en la faisant précéder d’une autre barre oblique inverse.
Pour plus d’informations, consultez MongoDB connector for Spark release notes
Snowflake
Notez les modifications suivantes :
Ajout d’un nouveau paramètre
trim_spaceque vous pouvez utiliser pour réduire automatiquement les valeurs des colonnesStringTypelors de l’enregistrement dans une table Snowflake. Valeur par défaut :false.Le paramètre
abort_detached_querya été désactivé par défaut au niveau de la session.Suppression de l’exigence du paramètre
SFUSERlors de l’utilisation d’OAUTH.Suppression de la fonctionnalité Advanced Query Pushdown. Des alternatives à cette fonctionnalité sont disponibles. Par exemple, au lieu de charger des données à partir de tables Snowflake, les utilisateurs peuvent charger directement des données à partir de requêtes SQL Snowflake.
Pour plus d’informations, consultez Snowflake Connector for Spark release notes
Annexe A : Mises à niveau notables des dépendances
Voici les mises à niveau des dépendances :
| Dépendance | Version en AWS Glue 5.0 | Version en AWS Glue 4.0 | Version en AWS Glue 3.0 | Version en AWS Glue 2.0 | Version en AWS Glue 1.0 |
|---|---|---|---|---|---|
| Java | 17 | 8 | 8 | 8 | 8 |
| Spark | 3.5.4 | 3.3.0-amzn-1 | 3.1.1-amzn-0 | 2.4.3 | 2.4.3 |
| Hadoop | 3.4.1 | 3.3.3-amzn-0 | 3.2.1-amzn-3 | 2.8.5-amzn-5 | 2.8.5-amzn-1 |
| Scala | 2,1,18 | 2,12 | 2,12 | 2.11 | 2.11 |
| Jackson | 2.15.2 | 2,12 | 2,12 | 2.11 | 2.11 |
| Hive | 2.3.9-amzn-4. | 2.3.9-amzn-2 | 2.3.7-amzn-4 | 1.2 | 1.2 |
| EMRFS | 2,69,0 | 2,54,0 | 2,46,0 | 2.38.0 | 2.30.0 |
| Json4s | 3.7.0-M11 | 3.7.0-M11 | 3.6.6 | 3.5.x | 3.5.x |
| Flèche | 12,0.1 | 7.0.0 | 2.0.0 | 0.10.0 | 0.10.0 |
| AWS Glue Client de catalogue de données | 4.5.0 | 3.7.0 | 3.0.0 | 1.10.0 | N/A |
| AWS SDK pour Java | 2,29,52 | 1.12 | 1.12 | ||
| Python | 3,11 | 3,10 | 3.7 | 2.7 et 3.6 | 2.7 et 3.6 |
| Boto | 1,34,131 | 1,26 | 1,18 | 1.12 | N/A |
| Connecteur EMR DynamoDB | 5.6.0 | 4,16,0 |
Annexe B : Mises à niveau du pilote JDBC
Voici les mises à niveau du pilote JDBC :
| Pilote | Version du pilote JDBC en 5.0 AWS Glue | Version du pilote JDBC en 4.0 AWS Glue | Version du pilote JDBC en 3.0 AWS Glue | Version du pilote JDBC dans les versions précédentes AWS Glue |
|---|---|---|---|---|
| MySQL | 8,0,33 | 8.0.23 | 8.0.23 | 5.1 |
| Microsoft SQL Server | 10.2.0 | 9.4.0 | 7.0.0 | 6.1.0 |
| Oracle Databases | 23,3.0,23,09 | 21,7 | 21,1 | 11.2 |
| PostgreSQL | 42.7.3 | 42,3.6 | 42,2,18 | 42,10 |
| Amazon Redshift |
redshift-jdbc42-2.1.0.29 |
redshift-jdbc42-2.1.0.16 |
redshift-jdbc41-1.2.12.1017 |
redshift-jdbc41-1.2.12.1017 |
| SAP Hana | 2,20,17 | 2,17,12 | ||
| Teradata | 20,00.00.33 | 20,00.00.06 |
Annexe C : Mises à niveau des connecteurs
Les mises à niveau des connecteurs sont les suivantes :
| Pilote | Version du connecteur en AWS Glue 5.0 | Version du connecteur en AWS Glue 4.0 | Version du connecteur en AWS Glue 3.0 |
|---|---|---|---|
| Connecteur EMR DynamoDB | 5.6.0 | 4,16,0 | |
| Amazon Redshift | 6.4.0 | 6.1.3 | |
| OpenSearch | 1.2.0 | 1.0.1 | |
| MongoDB | 10.3.0 | 10,0.4 | 3.0.0 |
| Snowflake | 3.0.0 | 2.12.0 | |
| Google BigQuery | 0,32,2 | 0,32,2 | |
| AzureCosmos | 4,33,0 | 4,22,0 | |
| AzureSQL | 1.3.0 | 1.3.0 | |
| Vertica | 3.3.5 | 3.3.5 |
Annexe D : Mises à niveau du format de table ouverte
Les mises à niveau du format de table ouverte sont les suivantes :
| OTF | Version du connecteur en AWS Glue 5.0 | Version du connecteur en AWS Glue 4.0 | Version du connecteur en AWS Glue 3.0 |
|---|---|---|---|
| Hudi | 0,15,0 | 0.12.1 | 0,1,1 |
| Delta Lake | 3.3.0 | 2.1.0 | 1.0.0 |
| Iceberg | 1.7.1 | 1.0.0 | 0.13.1 |
