Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migrer les programmes Apache Spark vers AWS Glue
Apache Spark est une plateforme open source pour les charges de travail informatiques distribuées et exécutées sur de vastes jeux de données. AWS Glue tire parti des capacités de Spark pour fournir une expérience optimisée pour l'ETL. Vous pouvez migrer des programmes Spark AWS Glue pour tirer parti de nos fonctionnalités. AWS Glue fournit les mêmes améliorations de performances que celles que vous attendez d'Apache Spark sur Amazon EMR.
Exécuter le code Spark
Le code Spark natif peut être exécuté dans un AWS Glue environnement prêt à l'emploi. Les scripts sont souvent développés en modifiant une partie de code de manière itérative, afin d’offrir un flux de travail adapté à une session interactive. Cependant, le code existant est plus adapté à une exécution dans le cadre d'une AWS Glue tâche, ce qui vous permet de planifier et d'obtenir régulièrement des journaux et des métriques pour chaque exécution de script. Vous pouvez télécharger et modifier un script existant en utilisant la console.
-
Obtenir la source de votre script. Pour besoin de cet exemple, vous utiliserez un exemple de script du référentiel Apache Spark. Exemple de binarizer
-
Dans la AWS Glue console, développez le volet de navigation de gauche et sélectionnez ETL > Jobs
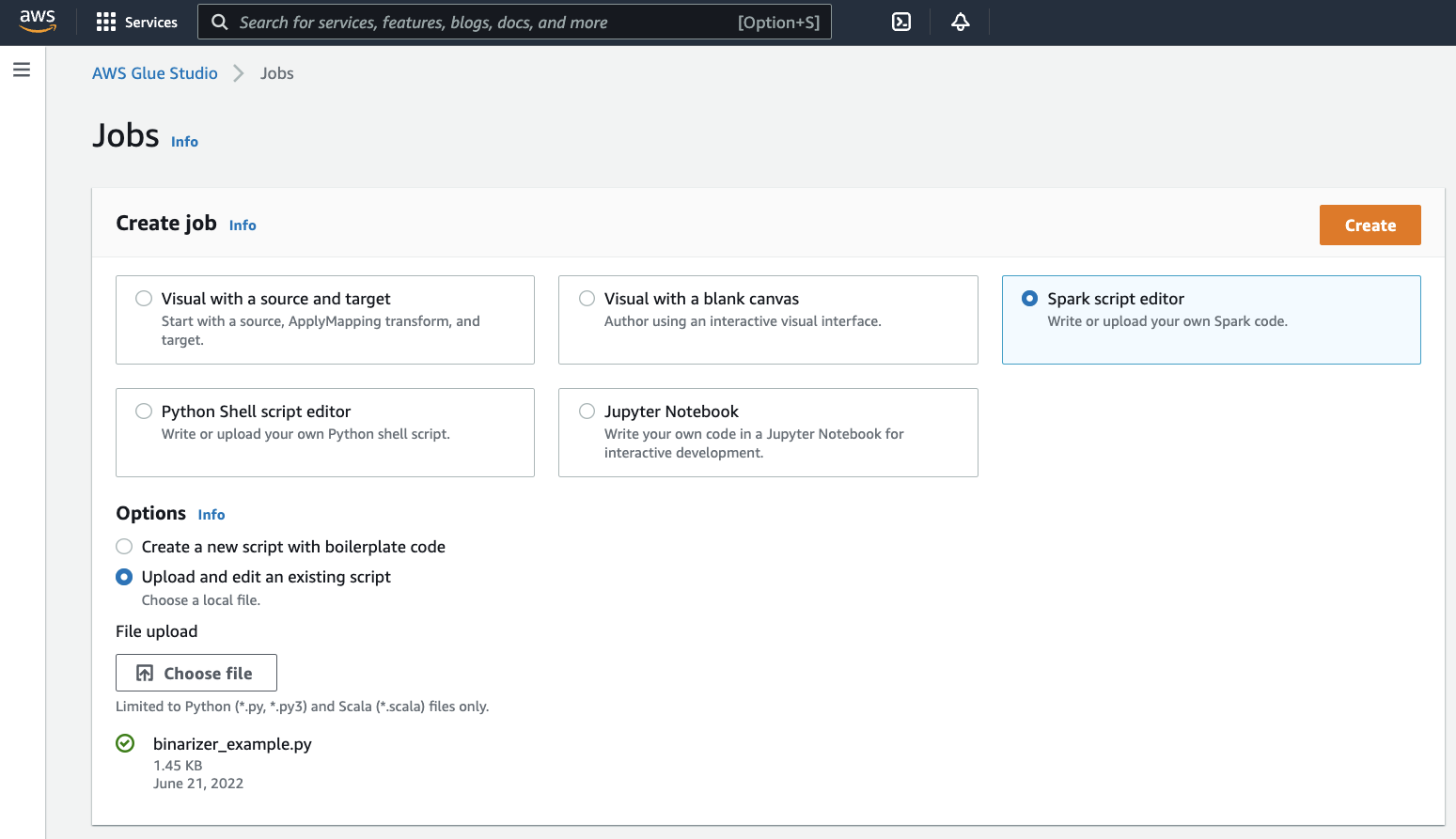
Dans le panneau Créer une tâche, sélectionnez Éditeur de script Spark. Une section Options apparaîtra. Dans cette section Options, sélectionnez Chargement et modification d'un script existant.
Une section de Chargement du fichier apparaîtra. Dans cette section Chargement du fichier, cliquez sur Choisissez un fichier. Le sélecteur de fichiers de votre système s'affichera. Accédez à l'emplacement où vous avez enregistré
binarizer_example.py, sélectionnez-le et confirmez votre choix.Une touche Créer apparaîtra dans l'en-tête du panneau Créer une tâche. Cliquez sur cette touche.
-
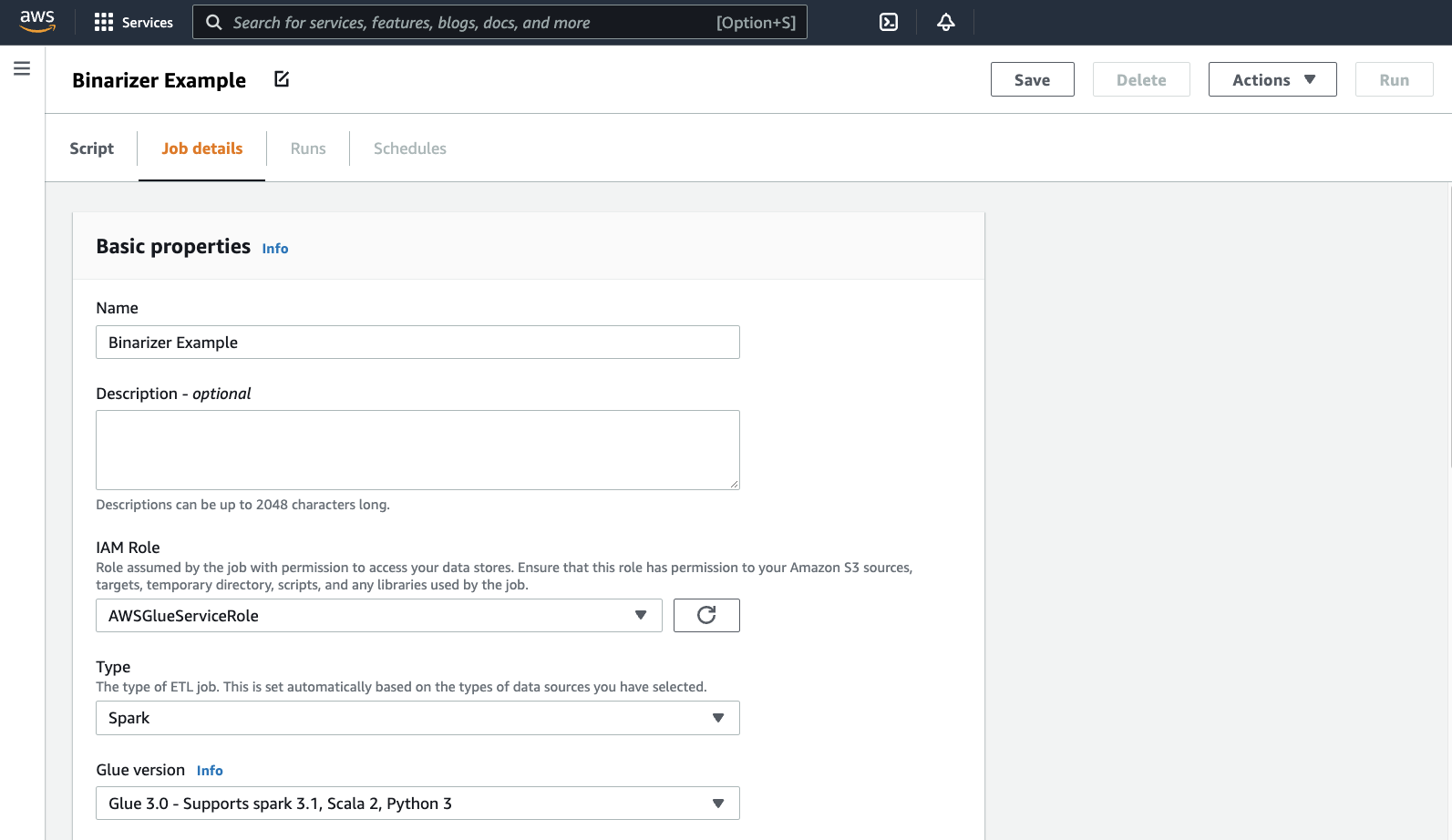
Votre navigateur accèdera à l'éditeur de script. Dans l'en-tête, cliquez sur l’onglet Détails de la tâche. Définissez le Nom et le Rôle IAM. Pour obtenir des conseils sur les rôles AWS Glue IAM, consultezConfiguration des autorisations IAM pour AWS Glue.
Facultativement, définissez le Nombre de travailleurs à
2etle Nombre de nouvelles tentatives à1. Ces options sont utiles lors de l'exécution de tâches de production. Cependant, leur désactivation simplifiera votre expérience lors du test d'une fonctionnalité.Dans la barre de titre, cliquez surEnregistrer, puis sur Exécuter
-
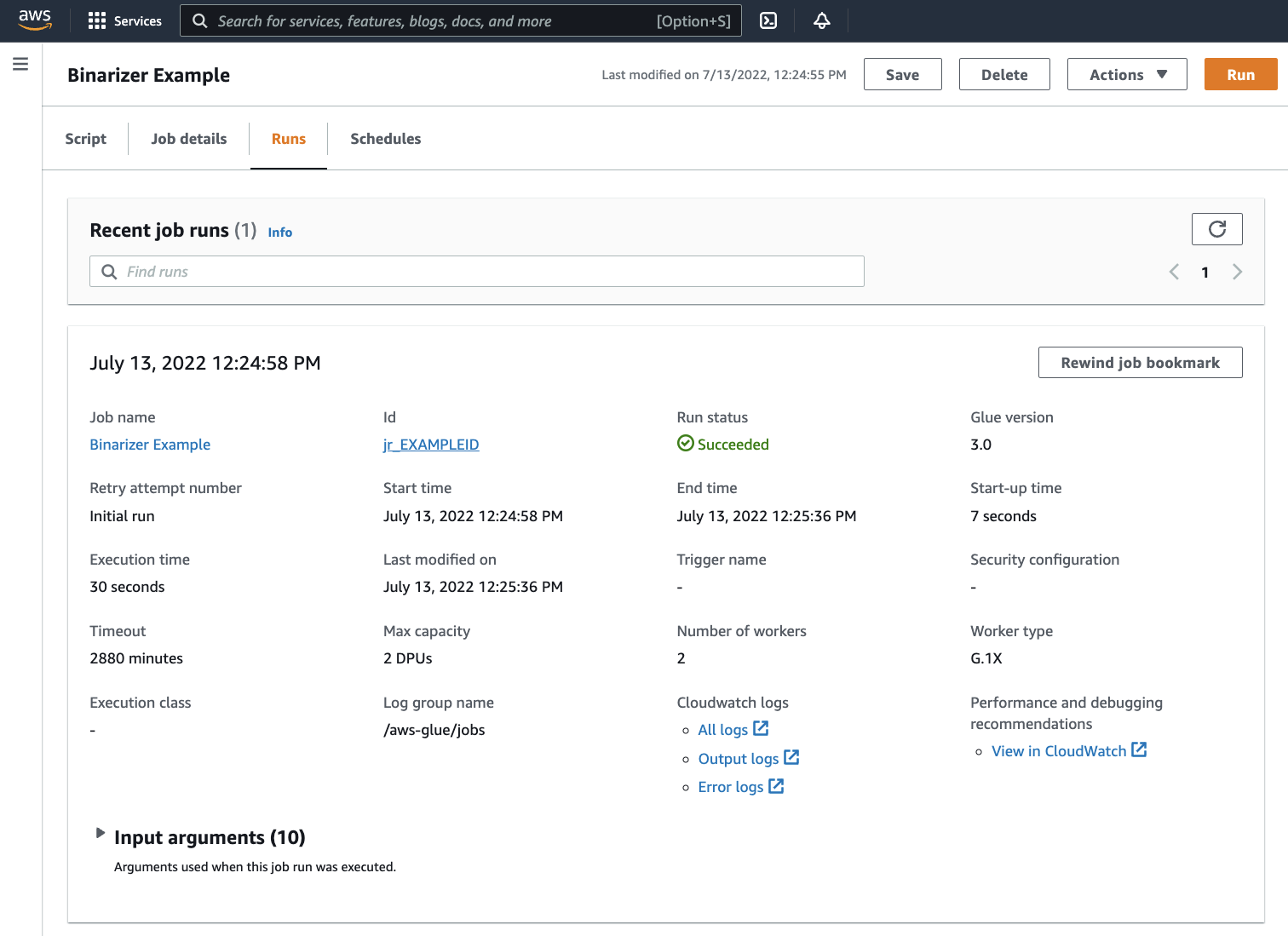
Accédez à l’onglet Exécutions. Vous verrez un panneau correspondant à l’exécution de votre tâche. Patientez quelques minutes, la page devrait s'actualiser automatiquement pour afficher Réussie comme Statut de l'exécution.
-
Si vous souhaitez examiner votre sortie pour vérifier que le script Spark s'est exécuté comme prévu. Cet échantillon de script Apache Spark doit écrire une chaîne dans le flux de sortie. Vous pouvez le trouver en accédant aux Journaux sous Cloudwatch logs dans le panneau, pour l'exécution de tâche réussie. Notez l'ID d'exécution de la tâche, un identifiant généré sous le modèle Id commençant par
jr_.Cela ouvrira la CloudWatch console, configurée pour visualiser le contenu du groupe de AWS Glue journaux par défaut
/aws-glue/jobs/output, filtré en fonction du contenu des flux de journaux pour l'identifiant d'exécution de la tâche. Chaque programme de travail aura généré un flux de journaux, affiché sous forme de lignes sous Flux de journaux. Un programme de travail aurait dû exécuter le code demandé. Vous devrez ouvrir tous les flux de journaux pour identifier le bon programme de travail. Une fois que vous avez trouvé le bon programme de travail, vous devriez voir la sortie du script, comme dans l'image suivante :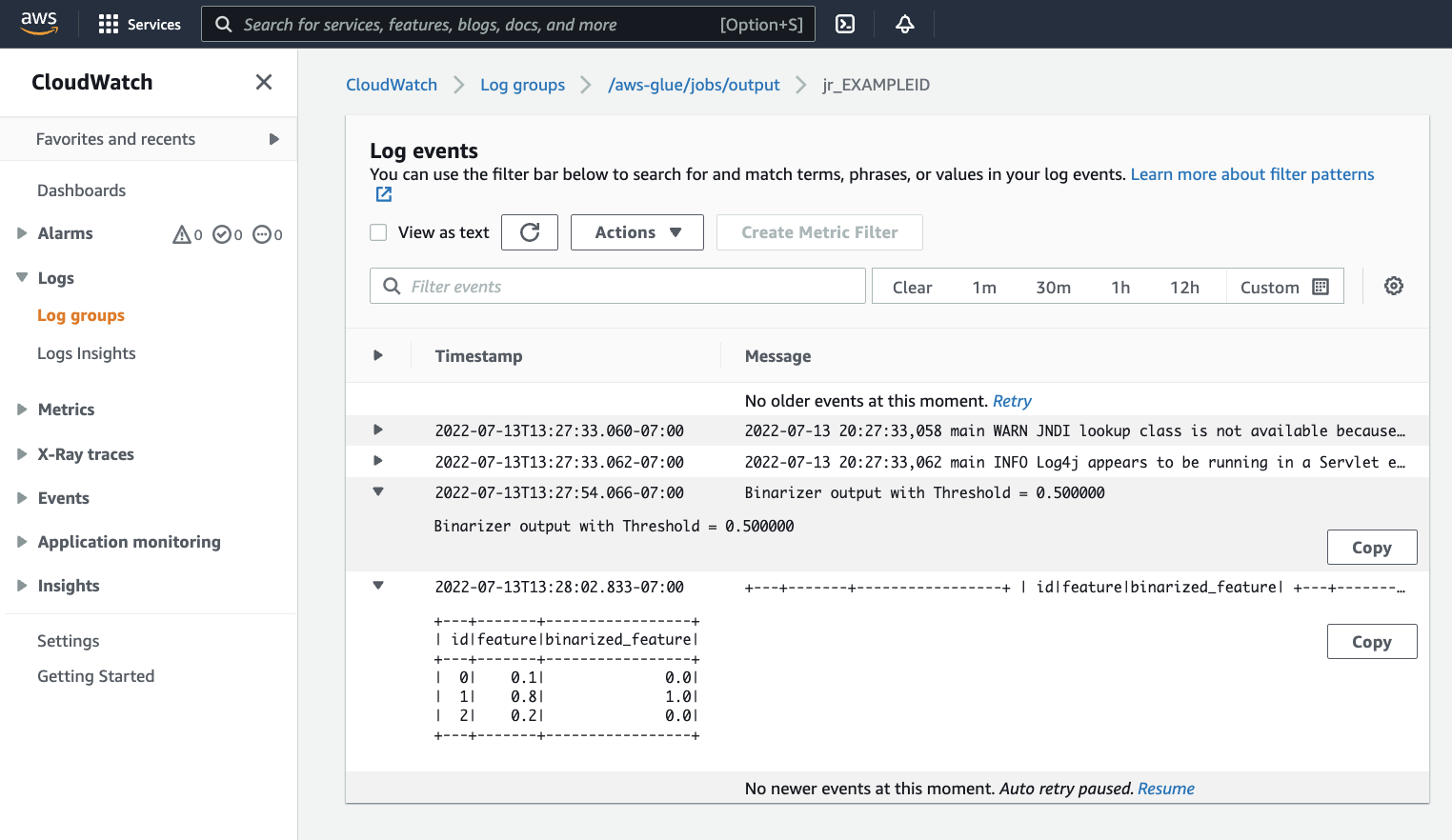
Procédures communes requises pour la migration des programmes Spark
Évaluation de la prise en charge de la version de Spark
AWS Glue les versions de version définissent la version d'Apache Spark et de Python disponible pour la AWS Glue tâche. Vous pouvez trouver nos AWS Glue versions et ce qu'elles prennent en charge à l'adresse suivanteAWS Glue versions. Vous devrez peut-être mettre à jour votre programme Spark pour qu'il soit compatible avec une version plus récente de Spark afin d'accéder à certaines fonctionnalités AWS Glue .
Intégration des bibliothèques tierces
De nombreux programmes Spark existants dépendront à la fois d'artefacts privés et publics. AWS Glue prend en charge les dépendances de style JAR pour les tâches Scala, ainsi que les dépendances Wheel et source Pure-Python pour les tâches Python.
Python - Pour plus d'informations sur les dépendances Python, consultez Utiliser les bibliothèques Python avec AWS Glue
Les dépendances Python courantes sont fournies dans l' AWS Glue environnement, y compris la bibliothèque Pandas--additional-python-modules. Pour plus d'informations sur ces arguments, consultez Utilisation des paramètres des tâches dans les tâches AWS Glue.
Vous pouvez fournir des dépendances Python supplémentaires avec l’argument de tâche --extra-py-files. Si vous migrez une tâche depuis un programme Spark, ce paramètre est une bonne option car il est fonctionnellement équivalent au --py-files flag in PySpark, et il est soumis aux mêmes limites. Pour plus d'informations sur le paramètre --extra-py-files, consultez Y compris des fichiers Python dotés de fonctionnalités PySpark natives
Pour les nouvelles tâches, vous pouvez gérer les dépendances Python avec l’argument de tâche --additional-python-modules. L'utilisation de cet argument offre une expérience plus profonde de la gestion des dépendances. Ce paramètre prend en charge les dépendances de style Wheel, y compris celles comprenant des liaisons de codes natifs compatibles avec Amazon Linux 2.
Scala
Vous pouvez fournir des dépendances Scala supplémentaires avec l’Argument de tâche --extra-jars. Les dépendances doivent être hébergées dans Amazon S3, et la valeur de l'argument doit être une liste de chemins non-espacés Amazon S3 délimités par des virgules. Vous trouverez peut-être plus facile de gérer votre configuration en regroupant vos dépendances avant de les héberger et de les configurer. AWS Glue Les dépendances JAR contiennent du bytecode Java, qui peut être généré à partir de n'importe quel langage JVM. Il vous est possible d’utiliser d'autres langages JVM, tels que Java, pour écrire des dépendances personnalisées.
Gestion des informations d'identification de la source de données
Les programmes Spark existants peuvent être fournis avec une configuration complexe ou personnalisée pour l’extraction des données de leurs sources de données. Les flux d'authentification des sources de données courants sont pris en charge par AWS Glue les connexions. Pour plus d’informations sur les connexions AWS Glue , consultez Connexion aux données.
AWS Glue les connexions facilitent la connexion de votre Job à divers types de magasins de données de deux manières principales : via des appels de méthode vers nos bibliothèques et en configurant la connexion réseau supplémentaire dans la AWS console. Vous pouvez également appeler le AWS SDK depuis votre tâche pour récupérer des informations à partir d'une connexion.
Appels de méthode : les AWS Glue connexions sont étroitement intégrées au catalogue de AWS Glue
données, un service qui vous permet de gérer les informations relatives à vos ensembles de données, et les méthodes disponibles pour interagir avec AWS Glue les connexions en tiennent compte. Si vous avez une configuration d'authentification existante que vous souhaitez réutiliser, pour les connexions JDBC, vous pouvez accéder à votre configuration de AWS Glue connexion via la extract_jdbc_conf méthode indiquée sur le. GlueContext Pour de plus amples informations, consultez extract_jdbc_conf.
Configuration de la console : les AWS Glue tâches utilisent AWS Glue les connexions associées pour configurer les connexions aux sous-réseaux Amazon VPC. Si vous gérez directement votre matériel de sécurité, vous devrez peut-être fournir un NETWORK type de connexion réseau supplémentaire dans la AWS console pour configurer le routage. Pour plus d'informations sur la connexion API AWS Glue
, consultez API de connexions
Si vos programmes Spark disposent d'un flux d'authentification personnalisé ou peu commun, vous devrez peut-être gérer vos supports de sécurité manuellement. Si AWS Glue les connexions ne vous semblent pas adaptées, vous pouvez héberger en toute sécurité les documents de sécurité dans Secrets Manager et y accéder via le boto3 ou le AWS SDK, fournis dans le cadre de la tâche.
Configuration d'Apache Spark
Les migrations complexes modifient souvent la configuration de Spark pour s'adapter à leurs charges de travail. Les versions modernes d'Apache Spark permettent de définir la configuration d'exécution à l'aide duSparkSession. AWS Glue Les jobs 3.0 et versions ultérieures sont fournisSparkSession, qui peuvent être modifiés pour définir la configuration d'exécution. Configuration d'Apache Spark
Définition de la configuration
Les programmes Spark migrés peuvent être conçus pour adopter une configuration personnalisée. AWS Glue permet de définir la configuration au niveau de la tâche et de son exécution, via les arguments de la tâche. Pour plus d'informations sur ces arguments, consultez Utilisation des paramètres des tâches dans les tâches AWS Glue. Vous pouvez accéder aux arguments de tâche dans le contexte d'une tâche par le biais de nos bibliothèques. AWS Glue fournit une fonction utilitaire fournissant une vue cohérente entre les arguments définis lors de la tâche et ceux définis lors de l'exécution de la tâche. Voir Accès aux paramètres à l'aide de getResolvedOptions dans Python et AWS GlueScala GlueArgParser APIs dans Scala.
Migration du code Java
Comme expliqué dans Intégration des bibliothèques tierces, vos dépendances peuvent contenir des classes générées par les langages JVM, tels que Java ou Scala. Vos dépendances peuvent inclure une Méthodemain. Vous pouvez utiliser une main méthode dans une dépendance comme point d'entrée pour une tâche AWS Glue Scala. Cela vous permet de rédiger votre méthode main en langage Java, ou réutilisez une méthode main empaquetée selon les normes de votre propre bibliothèque.
Pour utiliser une méthode main à partir d'une dépendance, effectuez les opérations suivantes : Effacez le contenu du volet d'édition en fournissant la valeur par défaut de l’objet GlueApp. Fournissez le nom complet d'une classe dans une dépendance en tant qu'argument de travail avec la clé --class. Vous devez ensuite être en mesure de déclencher une exécution de la tâche.
Vous ne pouvez pas configurer l'ordre ou la structure des AWS Glue arguments transmis à la main méthode. Si votre code existant doit lire la configuration définie AWS Glue, cela entraînera probablement une incompatibilité avec le code précédent. Si vous utilisez getResolvedOptions, vous ne disposerez pas d’un espace approprié pour appeler cette méthode. Envisagez d'invoquer votre dépendance directement, à partir d'une méthode principale générée par AWS Glue. Le script AWS Glue ETL suivant en montre un exemple.
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
