Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur DynamoDB avec prise en charge de Spark DataFrame
Le connecteur DynamoDB compatible avec DataFrame Spark vous permet de lire et d'écrire dans des tables de DynamoDB à l'aide des API Spark. DataFrame Les étapes de configuration du connecteur sont les mêmes que pour le DynamicFrame-based connecteur et peuvent être consultées ici.
Pour charger dans la bibliothèque de DataFrame-based connecteurs, veillez à associer une connexion DynamoDB à la tâche Glue.
Note
L'interface utilisateur de la console Glue ne prend actuellement pas en charge la création d'une connexion DynamoDB. Vous pouvez utiliser Glue CLI (CreateConnection) pour créer une connexion DynamoDB :
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
Lors de la création de la connexion DynamoDB, vous pouvez l'associer à votre tâche Glue via CLI CreateJob(UpdateJob,) ou directement sur la page « Détails de la tâche » :
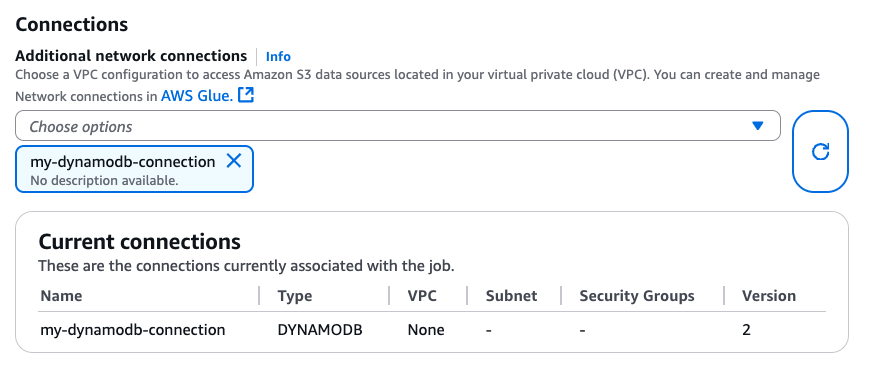
Après avoir vérifié qu'une connexion avec DYNAMODB Type est attachée à votre tâche Glue, vous pouvez utiliser les opérations de lecture, d'écriture et d'exportation suivantes à partir du DataFrame-based connecteur.
Lecture et écriture dans DynamoDB à l'aide du connecteur DataFrame-based
Les exemples de code suivants montrent comment lire et écrire dans des tables DynamoDB via le connecteur. DataFrame-based Ils montrent la lecture d'une table et l'écriture dans une autre table.
Utilisation de l'exportation DynamoDB via le connecteur DataFrame-based
L'opération d'exportation est préférable à l'opération de lecture pour les tables DynamoDB de plus de 80 Go. Les exemples de code suivants montrent comment lire depuis une table, exporter vers S3 et imprimer le nombre de partitions via le DataFrame-based connecteur.
Note
La fonctionnalité d'exportation DynamoDB est disponible via l'objet Scala. DynamoDBExport Les utilisateurs de Python peuvent y accéder via l'interopérabilité JVM de Spark ou utiliser le SDK AWS pour Python (boto3) avec l'API DynamoDB. ExportTableToPointInTime
Options de configuration
Options de lecture
| Option | Description | Par défaut |
|---|---|---|
dynamodb.input.tableName |
Nom de la table DynamoDB (obligatoire) | - |
dynamodb.throughput.read |
Les unités de capacité de lecture (RCU) à utiliser. S'il n'est pas spécifié, dynamodb.throughput.read.ratio il est utilisé pour le calcul. |
- |
dynamodb.throughput.read.ratio |
Le ratio d'unités de capacité de lecture (RCU) à utiliser | 0.5 |
dynamodb.table.read.capacity |
Capacité de lecture de la table à la demande utilisée pour calculer le débit. Ce paramètre n'est efficace que dans les tables de capacité à la demande. Par défaut, ce sont les unités de lecture à débit chaud. | - |
dynamodb.splits |
Définit le nombre de segments utilisés dans les opérations de scan en parallèle. S'il n'est pas fourni, le connecteur calculera une valeur par défaut raisonnable. | - |
dynamodb.consistentRead |
S'il faut utiliser des lectures très cohérentes | FALSE |
dynamodb.input.retry |
Définit le nombre de tentatives que nous effectuons en cas d'exception réessayable. | 10 |
Options d'écriture
| Option | Description | Par défaut |
|---|---|---|
dynamodb.output.tableName |
Nom de la table DynamoDB (obligatoire) | - |
dynamodb.throughput.write |
Les unités de capacité d'écriture (WCU) à utiliser. S'il n'est pas spécifié, dynamodb.throughput.write.ratio il est utilisé pour le calcul. |
- |
dynamodb.throughput.write.ratio |
Le ratio d'unités de capacité d'écriture (WCU) à utiliser | 0.5 |
dynamodb.table.write.capacity |
Capacité d'écriture de la table à la demande utilisée pour calculer le débit. Ce paramètre n'est efficace que dans les tables de capacité à la demande. Par défaut, ce sont les unités d'écriture à débit chaud. | - |
dynamodb.item.size.check.enabled |
Si c'est vrai, le connecteur calcule la taille de l'élément et abandonne si la taille dépasse la taille maximale, avant d'écrire dans la table DynamoDB. | TRUE |
dynamodb.output.retry |
Définit le nombre de tentatives que nous effectuons en cas d'exception réessayable. | 10 |
Options d'exportation
| Option | Description | Par défaut |
|---|---|---|
dynamodb.export |
S'il est défini sur, ddb active le connecteur d'exportation AWS Glue DynamoDB dans lequel un ExportTableToPointInTimeRequet nouveau connecteur sera invoqué pendant la AWS tâche Glue. Une nouvelle exportation sera générée avec l'emplacement transmis depuis dynamodb.s3.bucket et dynamodb.s3.prefix. S'il est défini sur, s3 active le connecteur d'exportation AWS Glue DynamoDB mais ignore la création d'une nouvelle exportation DynamoDB et utilise à la place le et dynamodb.s3.bucket comme emplacement Amazon S3 de dynamodb.s3.prefix l'ancienne exportation de cette table. |
ddb |
dynamodb.tableArn |
La table DynamoDB à partir de laquelle lire. Obligatoire si dynamodb.export est défini sur ddb. |
|
dynamodb.simplifyDDBJson |
S'il est défini surtrue, exécute une transformation pour simplifier le schéma de la structure JSON DynamoDB présente dans les exportations. |
FALSE |
dynamodb.s3.bucket |
Le compartiment S3 pour stocker les données temporaires lors de l'exportation DynamoDB (obligatoire) | |
dynamodb.s3.prefix |
Le préfixe S3 pour stocker les données temporaires lors de l'exportation DynamoDB | |
dynamodb.s3.bucketOwner |
Indiquez le propriétaire du compartiment requis pour l'accès entre comptes Amazon S3 | |
dynamodb.s3.sse.algorithm |
Type de chiffrement utilisé sur le compartiment dans lequel les données temporaires seront stockées. Les valeurs valides sont AES256 et KMS. |
|
dynamodb.s3.sse.kmsKeyId |
ID de la clé AWS KMS gérée utilisée pour chiffrer le compartiment S3 dans lequel les données temporaires seront stockées (le cas échéant). | |
dynamodb.exportTime |
Moment où l’exportation doit être effectuée. Valeurs valides : chaînes représentant des ISO-8601 instants. |
Options générales
| Option | Description | Par défaut |
|---|---|---|
dynamodb.sts.roleArn |
L'ARN du rôle IAM à assumer pour l'accès entre comptes | - |
dynamodb.sts.roleSessionName |
Nom de session STS | glue-dynamodb-sts-session |
dynamodb.sts.region |
Région pour le client STS (pour l'hypothèse d'un rôle interrégional) | Identique à l'regionoption |
