Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'un flux de travail de correspondance basé sur des règles avec le type de règle avancée
Conditions préalables
Avant de créer un flux de travail de correspondance basé sur des règles, vous devez :
-
Créez un mappage de schéma. Pour de plus amples informations, veuillez consulter Création d'un mappage de schéma.
-
Si vous utilisez Connect Customer Customer Customer Profiles comme destination de sortie, assurez-vous que les autorisations appropriées sont configurées.
La procédure suivante explique comment créer un flux de travail de correspondance basé sur des règles avec le type de règle avancée à l'aide de la Résolution des entités AWS console ou de l'CreateMatchingWorkflowAPI.
- Console
-
Pour créer un flux de travail de correspondance basé sur des règles avec le Advanced (Avancé) type de règle à l'aide de la console
-
Connectez-vous à la Résolution des entités AWS console AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/entityresolution/
. -
Dans le volet de navigation de gauche, sous Workflows, choisissez Matching.
-
Sur la page des flux de travail correspondants, dans le coin supérieur droit, choisissez Créer un flux de travail correspondant.
-
Pour l'étape 1 : Spécifier les détails du flux de travail correspondants, procédez comme suit :
-
Entrez un nom de flux de travail correspondant et une description facultative.
-
Pour la saisie de données, choisissez une Région AWSAWS Glue base de données, la AWS Glue table, puis le mappage de schéma correspondant.
Vous pouvez ajouter jusqu'à 19 entrées de données.
Note
Pour utiliser les règles avancées, vos mappages de schéma doivent répondre aux exigences suivantes :
-
Chaque champ de saisie doit être mappé à une clé de correspondance unique, sauf si les champs sont regroupés.
-
Si les champs de saisie sont regroupés, ils peuvent partager la même clé de correspondance.
Par exemple, le mappage de schéma suivant serait valide pour les règles avancées :
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }Dans ce cas, les
lastNamechampsfirstNameet sont regroupés et partagent la même clé de correspondance de nom, ce qui est autorisé.Passez en revue vos mappages de schéma et mettez-les à jour afin de suivre cette règle de correspondance individuelle, sauf si les champs sont correctement groupés, afin d'utiliser les règles avancées.
-
Si votre table de données comporte une colonne DELETE, le type du mappage du schéma doit être
Stringet vous ne pouvez pas avoir de «matchKeyetgroupName».
-
-
L'option Normaliser les données est sélectionnée par défaut, afin que les entrées de données soient normalisées avant la mise en correspondance. Si vous ne souhaitez pas normaliser les données, désélectionnez l'option Normaliser les données.
Note
La normalisation n'est prise en charge que pour les scénarios suivants dans Créer un mappage de schéma :
-
Si les sous-types de nom suivants sont regroupés : prénom, deuxième prénom, nom de famille.
-
Si les sous-types d'adresse suivants sont regroupés : adresse 1, adresse 2, adresse 3, ville, État, pays, code postal.
-
Si les sous-types de téléphone suivants sont regroupés : numéro de téléphone, code du pays du téléphone.
-
-
Pour spécifier les autorisations d'accès au service, choisissez une option et prenez les mesures recommandées.
Option Action recommandée Création et utilisation d'un nouveau rôle de service -
Résolution des entités AWS crée un rôle de service avec la politique requise pour cette table.
-
Le nom du rôle de service par défaut est
entityresolution-matching-workflow-<timestamp>. -
Vous devez disposer des autorisations nécessaires pour créer des rôles et associer des politiques.
-
Si vos données d'entrée sont cryptées, vous pouvez choisir l'option Ces données sont cryptées avec une clé KMS, puis saisir une AWS KMS clé qui sera utilisée pour déchiffrer vos données saisies.
Utiliser un rôle de service existant -
Choisissez le nom d'un rôle de service existant dans la liste déroulante.
La liste des rôles s'affiche si vous êtes autorisé à répertorier les rôles.
Si vous n'êtes pas autorisé à répertorier les rôles, vous pouvez saisir le nom de ressource Amazon (ARN) du rôle que vous souhaitez utiliser.
S'il n'existe aucun rôle de service existant, l'option Utiliser un rôle de service existant n'est pas disponible.
-
Affichez le rôle de service en choisissant le lien externe Afficher dans IAM.
Par défaut, Résolution des entités AWS ne tente pas de mettre à jour la politique de rôle existante pour ajouter les autorisations nécessaires.
-
-
(Facultatif) Pour activer les balises pour la ressource, choisissez Ajouter une nouvelle balise, puis entrez la paire clé/valeur.
-
Choisissez Suivant.
-
-
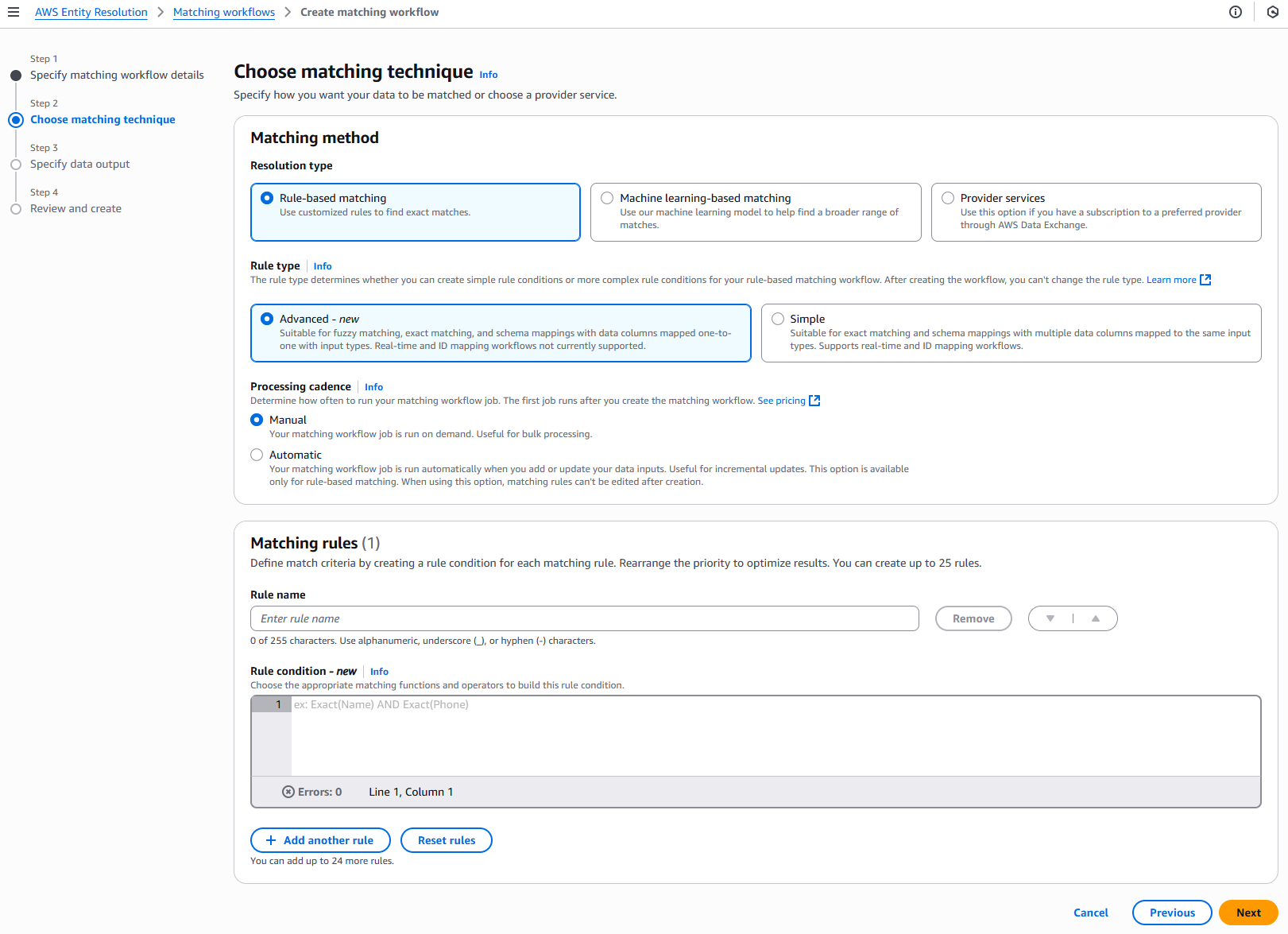
Pour l'étape 2 : Choisissez la technique de correspondance :
-
Pour Méthode de correspondance, choisissez la Rule-basedcorrespondance.
-
Pour Type de règle, choisissez Avancé.
-
Pour Cadence de traitement, sélectionnez l'une des options suivantes.
-
Choisissez Manuel pour exécuter un flux de travail à la demande pour une mise à jour groupée
-
Choisissez Automatique pour exécuter un flux de travail dès que de nouvelles données se trouvent dans votre compartiment S3
Note
Si vous choisissez Automatique, assurez-vous que EventBridge les notifications Amazon sont activées pour votre compartiment S3. Pour obtenir des instructions sur l'activation EventBridge d'Amazon à l'aide de la console S3, consultez la section Activation d'Amazon EventBridge dans le guide de l'utilisateur Amazon S3.
-
-
Pour les règles de correspondance, entrez un nom de règle, puis créez la condition de règle en choisissant les fonctions et les opérateurs de correspondance appropriés dans la liste déroulante en fonction de votre objectif.
Vous pouvez créer jusqu'à 25 règles.
Note
Résolution des entités AWS prend également en charge l'appariement transitif, qui traite les enregistrements à tous les niveaux de règles pour connecter les groupes de correspondance de manière transitive. La correspondance transitive est disponible en tant que API-only fonctionnalité. Lorsque la correspondance transitive est activée, le modificateur EmptyValues=Ignore n'est pas pris en charge. Pour de plus amples informations, veuillez consulter Utilisation de la correspondance transitive.
Vous devez combiner une fonction de correspondance floue (Cosine, Levenshtein ou Soundex) avec une fonction de correspondance exacte (Exact,) à l'aide de l'opérateur AND. ExactManyToMany
Vous pouvez utiliser le tableau suivant pour déterminer le type de fonction ou d'opérateur que vous souhaitez utiliser, en fonction de votre objectif.
Votre objectif Fonction ou opérateur recommandé Modificateur optionnel recommandé Avantages Faites correspondre des chaînes identiques sur des données précises, mais pas sur des valeurs vides. Exact EmptyValues=Processus Associez des chaînes identiques à des données précises et ignorez les valeurs vides. Exactement ( matchKey)EmptyValues=Ignorer Associez plusieurs enregistrements sur des clés de correspondance. Convient aux couples flexibles. Limite : 15 touches de correspondance ExactManyToMany( matchKey,matchKey, ...)n/a Mesurez la similitude entre les représentations numériques des données, mais ne faites pas correspondre les valeurs vides. Convient au texte, aux chiffres ou à un mélange des deux. Cosinus EmptyValues=Processus Simple et efficace.
Fonctionne bien avec un texte long lorsqu'il est associé à une TF-IDF pondération.
Idéal pour une correspondance exacte basée sur des mots.
Mesurez la similitude entre les représentations numériques des données et ignorez les valeurs vides. Cosinus ( matchKey,threshold,...)EmptyValues=Ignorer Gère bien les fautes de frappe, les fautes d'orthographe et les transpositions.
Efficace sur un large éventail de types d'informations personnelles.
Idéal pour les chaînes courtes (par exemple, les noms ou les numéros de téléphone).
Comptez le nombre minimum de modifications nécessaires pour transformer un mot en un autre, mais ne faites pas correspondre les valeurs vides. Convient aux textes présentant de légères différences d'orthographe. Levenshtein EmptyValues=Processus Comptez le nombre minimum de modifications nécessaires pour transformer un mot en un autre et ignorez les valeurs vides. Levenstein ( matchKey,,threshold...)EmptyValues=Ignorer Comparez et associez des chaînes de texte en fonction de leur similitude, mais ne correspondez pas à des valeurs vides. Convient aux textes présentant des variations d'orthographe ou de prononciation. Soundex EmptyValues=Processus Efficace pour la correspondance phonétique, l'identification de mots à consonance similaire.
Rapide et peu coûteux en termes de calcul.
Idéal pour associer des noms ayant des prononciations similaires mais des orthographes différentes.
Comparez et associez des chaînes de texte en fonction de leur similitude sonore et ignorez les valeurs vides. Indice sonore () matchKeyEmptyValues=Ignorer Combinez les fonctions. ET n/a Fonctions distinctes. OU n/a Regroupez les conditions pour créer des conditions imbriquées. (…) n/a Exemple Condition de règle qui correspond aux numéros de téléphone et aux e-mails
Voici un exemple de condition de règle qui fait correspondre les enregistrements relatifs aux numéros de téléphone (clé de correspondance du téléphone) et aux adresses e-mail (clé de correspondance de l'adresse e-mail) :
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)
La touche Phone Match utilise la fonction Exact matching pour faire correspondre des chaînes identiques. La touche Phone Match traite les valeurs vides lors de la correspondance à l'aide du modificateur EmptyValues=Process.
La clé de correspondance de l'adresse e-mail utilise la fonction de correspondance de Levenshtein pour faire correspondre les données aux fautes d'orthographe en utilisant le seuil de 2 par défaut de l'algorithme de distance de Levenshtein. La clé Email match n'utilise aucun modificateur facultatif.
L'opérateur AND combine la fonction de correspondance exacte et la fonction de correspondance Levenshtein.
Exemple Condition de règle utilisée ExactManyToMany pour effectuer une correspondance par clé de correspondance
Voici un exemple de condition de règle qui fait correspondre les enregistrements de trois champs d'adresse (clé de HomeAddresscorrespondance, clé de BillingAddresscorrespondance et clé de ShippingAddresscorrespondance) pour trouver des correspondances potentielles en vérifiant si certains d'entre eux ont des valeurs identiques.
L'
ExactManyToManyopérateur évalue toutes les combinaisons possibles des champs d'adresse spécifiés pour identifier les correspondances exactes entre deux adresses ou plus. Par exemple, il détecterait si les adressesHomeAddresscorrespondent à ou si les trois adresses correspondent exactement.BillingAddressShippingAddressExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)Exemple Condition de règle utilisant le clustering
Dans le cadre de la mise en correspondance avancée basée sur des règles avec conditions floues, le système regroupe d'abord les enregistrements en clusters en fonction de correspondances exactes. Une fois ces groupes initiaux formés, le système applique des filtres de correspondance floue pour identifier des correspondances supplémentaires au sein de chaque groupe. Pour des performances optimales, vous devez sélectionner des conditions de correspondance exactes en fonction de vos modèles de données afin de créer des clusters initiaux bien définis.
Voici un exemple de condition de règle qui combine plusieurs correspondances exactes avec une exigence de correspondance floue. Il utilise des
ANDopérateurs pour vérifier que les trois champs —FullName, Date de naissance (DOB) etAddress— correspondent exactement entre les enregistrements. Il permet également des variations mineures dans leInternalIDchamp en utilisant une distance de Levenshtein de.1La distance de Levenshtein mesure le nombre minimum de modifications à caractère unique requises pour transformer une chaîne en une autre. Une distance de 1 signifie qu'il y aura une correspondanceInternalIDsqui ne diffère que d'un caractère (par exemple, une faute de frappe, une suppression ou une insertion). Cette combinaison de conditions permet d'identifier les enregistrements qui sont très susceptibles de représenter la même entité, même si l'identifiant présente de légères différences.Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
Choisissez Suivant.
-
-
Pour l'étape 3 : Spécifier la sortie et le format des données :
-
Pour la destination et le format de sortie des données, choisissez l'emplacement Amazon S3 pour la sortie des données et indiquez si le format des données sera des données normalisées ou des données d'origine.
-
Pour le chiffrement, si vous choisissez de personnaliser les paramètres de chiffrement, entrez l'ARN de la AWS KMS clé.
-
Affichez la sortie générée par le système.
-
Pour la sortie de données, choisissez les champs que vous souhaitez inclure, masquer ou masquer, puis prenez les mesures recommandées en fonction de vos objectifs.
Votre objectif Action recommandée Inclure les champs Conservez l'état de sortie sur Inclus. Masquer les champs (exclure de la sortie) Choisissez le champ de sortie, puis choisissez Masquer. Champs de masque Choisissez le champ Sortie, puis choisissez Hash output. Réinitialisez les paramètres précédents Choisissez Réinitialiser. -
Choisissez Suivant.
-
-
Pour l'étape 4 : révision et création :
-
Passez en revue les sélections que vous avez effectuées lors des étapes précédentes et modifiez-les si nécessaire.
-
Choisissez Créer et exécuter.
Un message apparaît, indiquant que le flux de travail correspondant a été créé et que le travail a commencé.
-
-
Sur la page des détails du flux de travail correspondant, sous l'onglet Mesures, consultez les informations suivantes sous Dernières mesures de travail :
-
Le Job ID.
-
État de la tâche de flux de travail correspondante : En file d'attente, en cours, terminée, échouée
-
Durée d'exécution de la tâche de flux de travail.
-
Le nombre d'enregistrements traités.
-
Le nombre d'enregistrements non traités.
-
Les identifiants de correspondance uniques générés.
-
Le nombre d'enregistrements en entrée.
Vous pouvez également consulter les statistiques des tâches correspondant aux tâches de flux de travail précédemment exécutées dans l'historique des tâches.
-
-
Une fois la tâche de flux de travail correspondante terminée (le statut est terminé), vous pouvez accéder à l'onglet Sortie de données, puis sélectionner votre site Amazon S3 pour afficher les résultats.
-
(Type de traitement manuel uniquement) Si vous avez créé un flux de travail Rule-based correspondant avec le type de traitement manuel, vous pouvez exécuter le flux de travail correspondant à tout moment en choisissant Exécuter le flux de travail sur la page des détails du flux de travail correspondant.
-
(Type de traitement automatique uniquement) Si votre table de données comporte une colonne DELETE, alors :
-
Les enregistrements définis sur
truela colonne DELETE sont supprimés. -
Les enregistrements définis sur
falsela colonne DELETE sont ingérés dans S3.
Pour de plus amples informations, veuillez consulter Étape 1 : préparer des tableaux de données de première partie.
-
-
- API
-
Pour créer un flux de travail de correspondance basé sur des règles avec le Advanced (Avancé) type de règle à l'aide de l'API
Note
Par défaut, le flux de travail utilise un traitement standard (par lots). Pour utiliser le traitement incrémentiel (automatique), vous devez le configurer de manière explicite.
-
Ouvrez un terminal ou une invite de commande pour effectuer la demande d'API.
-
Créez une requête POST pour le point de terminaison suivant :
/matchingworkflows -
Dans l'en-tête de la demande, définissez la Content-type valeur sur application/json.
Note
Pour obtenir la liste complète des langages de programmation pris en charge, consultez la référence des Résolution des entités AWS API.
-
Pour le corps de la demande, fournissez les paramètres JSON obligatoires suivants :
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "stringOù :
-
workflowName(obligatoire) — Doit être unique et correspondre au modèle entre 1 et 255 caractères [a-z A-Z _0-9-] * -
inputSourceConfig(obligatoire) — Liste des configurations de 1 à 20 sources d'entrée -
outputSourceConfig(obligatoire) — Exactement une configuration de source de sortie -
resolutionTechniques(obligatoire) — Défini sur « RULE_MATCHING » comme type de résolution pour la correspondance basée sur des règles -
roleArn(obligatoire) — ARN du rôle IAM pour l'exécution du flux de travail -
ruleConditionProperties(obligatoire) — Liste des conditions de règle et nom de la règle correspondante.
Les paramètres facultatifs incluent :
-
description— Jusqu'à 255 caractères -
incrementalRunConfig— Configuration du type d'exécution incrémentielle -
tags— Jusqu'à 200 paires clé-valeur
-
-
(Facultatif) Pour utiliser le traitement incrémentiel au lieu du traitement standard (par lots) par défaut, ajoutez le paramètre suivant au corps de la demande :
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
Envoyez la demande .
-
En cas de succès, vous recevrez une réponse avec le code d'état 200 et un corps JSON contenant :
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
Si l'appel échoue, l'un des messages d'erreur suivants peut s'afficher :
-
400 — ConflictException si le nom du flux de travail existe déjà
-
400 — ValidationException si l'entrée échoue à la validation
-
402 — ExceedsLimitException si les limites du compte sont dépassées
-
403 — AccessDeniedException si vous ne disposez pas d'un accès suffisant
-
429 — ThrottlingException si la demande a été limitée
-
500 — en InternalServerException cas de panne du service interne
-
-
