Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de l'agent de mise à niveau
Modes de déploiement pris en charge
L'agent de mise à niveau Apache Spark pour Amazon EMR prend en charge les deux modes de déploiement suivants pour l'expérience de mise à niveau de l'application end-to-end Spark, notamment la mise à niveau du fichier de build, script/dependency le test local et la validation avec le cluster EMR cible ou l'application EMR Serverless, et la validation de la qualité des données.
-
EMR sur EC2
-
EMR sans serveur
Veuillez vous référer Caractéristiques et capacités à cette section pour comprendre les caractéristiques détaillées, les capacités et les limites.
Interfaces prises en charge
Intégration avec Amazon SageMaker Unified Studio VS Code Editor Spaces
Sur Amazon SageMaker Unified Studio VS Code Editor Spaces, vous pouvez configurer le profil IAM et la configuration MCP comme décrit dans la section Configuration de l'agent de mise à niveau en suivant simplement la capture d'écran ci-dessous :
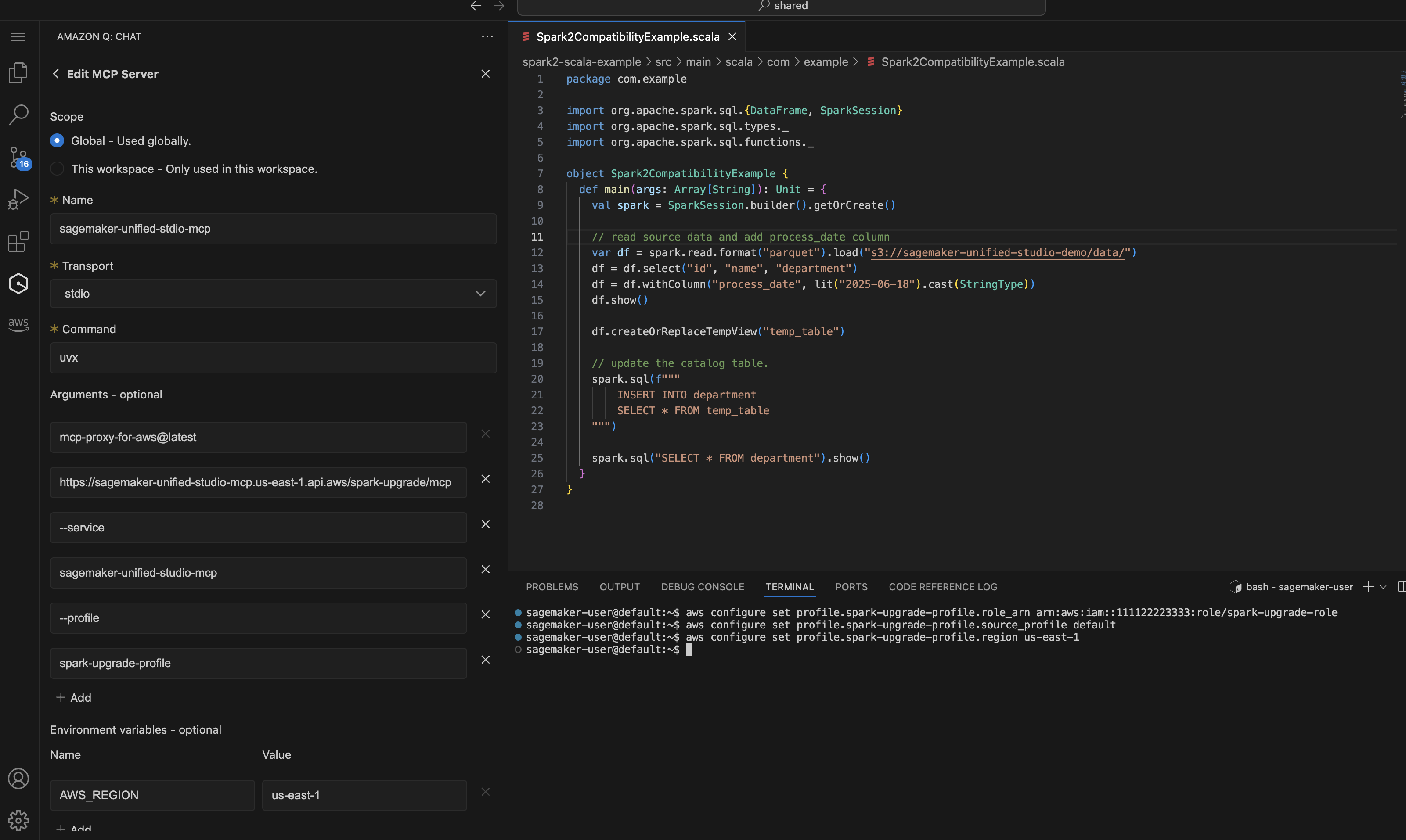
Démonstration de l'expérience de mise à niveau de l'EMR sur EC2 avec l'éditeur de code SMUS VS. Cela commence par une simple invite à demander à l'agent de démarrer le processus de mise à niveau de Spark.
Upgrade my Spark application <local-project-path> from EMR version 6.0.0 to 7.12.0. Use EMR-EC2 Cluster <cluster-id> to run the validation and s3 paths s3://<please fill in your staging bucket path> to store updated application artifacts. Use spark-upgrade-profile for AWS CLI operations.
Intégration avec Kiro CLI (QCLI)
Démarrez Kiro CLI ou votre assistant AI et vérifiez les outils chargés pour l'agent de mise à niveau.
... spark-upgrade (MCP): - check_and_update_build_environment * not trusted - check_and_update_python_environment * not trusted - check_job_status * not trusted - compile_and_build_project * not trusted ...
Une démonstration de l'expérience de mise à niveau EMR sans serveur avec Kiro CLI. Vous pouvez simplement démarrer le processus de mise à niveau en suivant le message suivant :
Upgrade my Spark application <local-project-path> from EMR version 6.0.0 to 7.12.0. Use EMR-Serverless Applicaion <application-id> and execution role <your EMR Serverless job execution role> to run the validation and s3 paths s3://<please fill in your staging bucket path> to store updated application artifacts.
Intégration avec d'autres IDEs
La configuration peut également être utilisée dans d'autres applications IDEs pour se connecter au serveur Managed MCP :
-
Intégration avec Cline - Pour utiliser le serveur MCP avec Cline, modifiez
cline_mcp_settings.jsonet ajoutez la configuration ci-dessus. Consultez la documentation de Clinepour plus d'informations sur la gestion de la configuration MCP. -
Intégration avec Claude Code Pour utiliser le serveur MCP avec Claude Code, modifiez le fichier de configuration pour inclure la configuration MCP. Le chemin du fichier varie en fonction de votre système d'exploitation. Reportez-vous à https://code.claude.com/docs/en/mcp
pour une configuration détaillée. -
Intégration avec GitHub Copilot - Pour utiliser le serveur MCP avec GitHub Copilot, suivez les instructions indiquées dans https://docs.github.com/en/copilot/how-tos/provide-context/use-mcp/extend- copilot-chat-with-mcp
pour modifier le fichier de configuration correspondant et suivez les instructions de chaque IDE pour activer l'installation.
Configuration du cluster EMR ou de l'application EMR sans serveur pour la version cible
Créez le cluster EMR ou l'application EMR Serverless avec la version Spark attendue que vous prévoyez d'utiliser pour l'application mise à niveau. Le cluster EMR ou l'application EMR-S cible seront utilisés pour soumettre les tâches de validation après la mise à niveau des artefacts de l'application Spark afin de vérifier la réussite de la mise à niveau ou de corriger les erreurs supplémentaires rencontrées lors de la validation. Si vous possédez déjà un cluster EMR cible ou une application EMR Serverless, vous pouvez vous référer au cluster EMR existant et ignorer cette étape. Utilisez des comptes de développeur hors production et sélectionnez des exemples de jeux de données fictifs qui représentent vos données de production, mais dont la taille est réduite pour la validation avec Spark Upgrades. Reportez-vous à cette page pour obtenir des conseils sur la création d'un cluster EMR cible ou d'une application EMR Serverless à partir de clusters EMR existants :. Création d'un cluster EMR cible/d'une application EMR-S à partir de clusters EMR existants
