Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d'EMR Serverless avecAWS Lake Formationpour un contrôle d'accès précis
Présentation de
Avec les versions 7.2.0 et supérieures d'Amazon EMR, vous pouvez AWS Lake Formation appliquer des contrôles d'accès précis aux tables du catalogue de données soutenues par S3. Cette fonctionnalité vous permet de configurer des contrôles d'accès au niveau des tables, des lignes, des colonnes et des cellules pour les read requêtes dans vos tâches Amazon EMR Serverless Spark. Pour configurer un contrôle d'accès précis pour les tâches par lots et les sessions interactives d'Apache Spark, utilisez EMR Studio. Consultez les sections suivantes pour en savoir plus sur Lake Formation et sur son utilisation avec EMR Serverless.
L'utilisation d'Amazon EMR Serverless AWS Lake Formation entraîne des frais supplémentaires. Pour plus d'informations, consultez la tarification d'Amazon EMR.
Comment fonctionne EMR Serverless avecAWS Lake Formation
L'utilisation d'EMR Serverless avec Lake Formation vous permet d'appliquer une couche d'autorisations à chaque tâche Spark afin d'appliquer le contrôle des autorisations de Lake Formation lorsque EMR Serverless exécute des tâches. EMR Serverless utilise les profils de ressources Spark pour créer deux profils
Lorsque vous utilisez une capacité préinitialisée avec Lake Formation, nous vous conseillons de disposer d'au moins deux pilotes Spark. Chaque Formation-enabled tâche Lake utilise deux pilotes Spark, l'un pour le profil utilisateur et l'autre pour le profil système. Pour de meilleures performances, utilisez deux fois plus de facteurs pour les Formation-enabled tâches Lake que si vous n'utilisez pas Lake Formation.
Lorsque vous exécutez des tâches Spark sur EMR Serverless, tenez également compte de l'impact de l'allocation dynamique sur la gestion des ressources et les performances du cluster. La configuration spark.dynamicAllocation.maxExecutors du nombre maximum d'exécuteurs par profil de ressource s'applique aux exécuteurs utilisateur et système. Si vous configurez ce nombre pour qu'il soit égal au nombre maximum autorisé d'exécuteurs, l'exécution de votre tâche risque de se bloquer car un type d'exécuteur utilise toutes les ressources disponibles, ce qui empêche l'autre exécuteur d'exécuter des tâches.
Pour ne pas manquer de ressources, EMR Serverless définit le nombre maximum d'exécuteurs par défaut par profil de ressource à 90 % de la valeur. spark.dynamicAllocation.maxExecutors Vous pouvez remplacer cette configuration lorsque vous spécifiez spark.dynamicAllocation.maxExecutorsRatio une valeur comprise entre 0 et 1. Configurez également les propriétés suivantes pour optimiser l'allocation des ressources et les performances globales :
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
Voici un aperçu général de la manière dont EMR Serverless accède aux données protégées par les politiques de sécurité de Lake Formation.
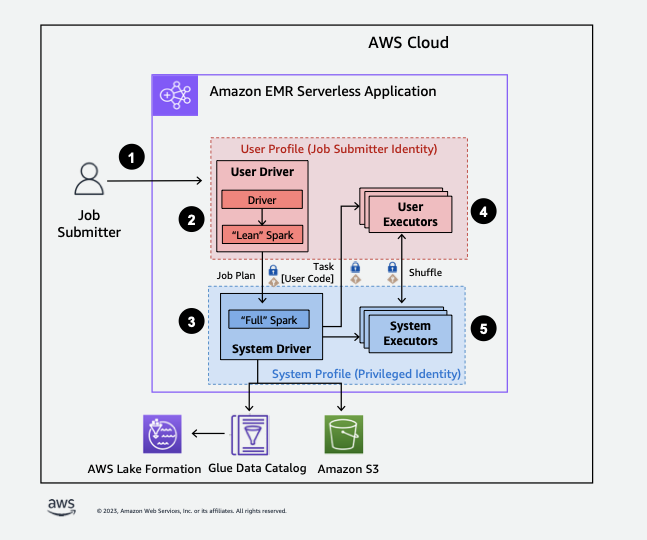
-
Un utilisateur soumet une tâche Spark à une application EMR sans serveur AWS Lake Formation compatible.
-
EMR Serverless envoie la tâche à un pilote utilisateur et l'exécute dans le profil utilisateur. Le pilote utilisateur exécute une version allégée de Spark qui n’est pas en mesure de lancer des tâches, de demander des exécuteurs, d’accéder à S3 ni au catalogue Glue. Il crée un plan de tâche.
-
EMR Serverless configure un deuxième pilote appelé pilote système et l'exécute dans le profil système (avec une identité privilégiée). EMR Serverless configure un canal TLS crypté entre les deux pilotes pour la communication. Le pilote utilisateur utilise le canal pour envoyer les plans de tâche au pilote système. Le pilote système n’exécute pas le code soumis par l’utilisateur. Il exécute Spark dans son intégralité et communique avec S3 et le catalogue de données pour l’accès aux données. Il demande des exécuteurs et compile le plan de tâche en une séquence d’étapes d’exécution.
-
EMR Serverless exécute ensuite les étapes sur les exécuteurs à l'aide du pilote utilisateur ou du pilote système. À n’importe quelle étape, le code utilisateur est exécuté exclusivement sur les exécuteurs de profil utilisateur.
-
Les étapes qui lisent les données des tables du catalogue de données protégées par des filtres de sécurité AWS Lake Formation ou qui appliquent des filtres de sécurité sont déléguées aux exécuteurs du système.
Favoriser la formation de Lake dans Amazon EMR
Pour activer Lake Formation, définissez le paramètre de configuration spark.emr-serverless.lakeformation.enabled d'exécution sur « true spark-defaults sous-classification » lors de la création d'une application EMR Serverless.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
Vous pouvez également activer Lake Formation lorsque vous créez une nouvelle application dans EMR Studio. Choisissez Utiliser Lake Formation pour un contrôle d'accès précis, disponible dans la section Configurations supplémentaires.
Inter-worker le chiffrement est activé par défaut lorsque vous utilisez Lake Formation avec EMR Serverless. Il n'est donc pas nécessaire de réactiver explicitement le chiffrement entre les opérateurs.
Activer Lake Formation pour les emplois de Spark
Pour activer Lake Formation pour des tâches Spark individuelles, définissez ce paramètre spark.emr-serverless.lakeformation.enabled sur true lors de l'utilisationspark-submit.
--conf spark.emr-serverless.lakeformation.enabled=true
Autorisations IAM du rôle d’exécution des tâches
Les autorisations de Lake Formation contrôlent l'accès aux ressources du catalogue de données AWS Glue, aux sites Amazon S3 et aux données sous-jacentes de ces sites. Les autorisations IAM contrôlent l'accès aux API et aux ressources de Lake Formation et AWS Glue. Bien que vous ayez l’autorisation Lake Formation d’accéder à une table du catalogue de données (SELECT), votre opération échoue si vous ne disposez pas de l’autorisation IAM sur l’opération d’API glue:Get*.
Voici un exemple de politique expliquant comment fournir les autorisations IAM pour accéder à un script dans Amazon S3, le chargement de journaux sur S3, les autorisations d’API AWS Glue et les autorisations d’accès à Lake Formation.
Configuration des autorisations de Lake Formation pour le rôle d’exécution des tâches
Tout d’abord, enregistrez l’emplacement de votre table Hive avec Lake Formation. Créez ensuite des autorisations pour votre rôle d’exécution des tâches dans la table de votre choix. Pour plus de détails sur la Lake Formation, reportez-vous à Qu'est-ce que c'est AWS Lake Formation ? dans le Guide AWS Lake Formation du développeur.
Après avoir configuré les autorisations de Lake Formation, soumettez des tâches Spark sur Amazon EMR Serverless. Pour plus d'informations sur les tâches Spark, reportez-vous aux exemples de Spark.
Soumission d’une exécution de tâche
Une fois que vous aurez terminé de configurer les subventions Lake Formation, vous pourrez soumettre des tâches Spark sur EMR Serverless. La section qui suit présente des exemples de configuration et de soumission des propriétés d'exécution des tâches.
Conditions d'autorisation
Tables non enregistrées dansAWS Lake Formation
Pour les tables non enregistrées auprès de Amazon S3AWS Lake Formation, le rôle d'exécution des tâches accède à la fois au catalogue de données AWS Glue et aux données des tables sous-jacentes. Cela nécessite que le rôle d'exécution des tâches dispose des autorisations IAM appropriées pour les opérations AWS Glue et Amazon S3.
Tables enregistrées dansAWS Lake Formation
Pour les tables enregistrées auprès deAWS Lake Formation, le rôle d'exécution du job accède aux métadonnées du catalogue de données AWS Glue, tandis que les informations d'identification temporaires fournies par Lake Formation accèdent aux données des tables sous-jacentes dans Amazon S3. Les autorisations de Lake Formation requises pour exécuter une opération dépendent du catalogue de données AWS Glue et des appels d'API Amazon S3 lancés par la tâche Spark et peuvent être résumées comme suit :
-
L'autorisation DESCRIBE permet au rôle d'exécution de lire les métadonnées d'une table ou d'une base de données dans le catalogue de données
-
L'autorisation ALTER permet au rôle d'exécution de modifier les métadonnées de table ou de base de données dans le catalogue de données
-
L'autorisation DROP permet au rôle d'exécution de supprimer les métadonnées de table ou de base de données du catalogue de données
-
L'autorisation SELECT permet au rôle d'exécution de lire les données des tables depuis Amazon S3
-
L'autorisation INSERT permet au rôle d'exécution d'écrire des données de table sur Amazon S3
-
L'autorisation DELETE permet au rôle d'exécution de supprimer les données de table d'Amazon S3
Note
Lake Formation évalue les autorisations de manière paresseuse lorsqu'une tâche Spark appelle AWS Glue pour récupérer les métadonnées des tables et Amazon S3 pour récupérer les données des tables. Les tâches qui utilisent un rôle d'exécution avec des autorisations insuffisantes n'échoueront pas tant que Spark n'aura pas AWS passé un appel à Glue ou Amazon S3 nécessitant l'autorisation manquante.
Note
Dans la matrice de tableau prise en charge suivante :
-
Les opérations marquées comme Supported utilisent exclusivement les informations d'identification de Lake Formation pour accéder aux données des tables enregistrées auprès de Lake Formation. Si les autorisations de Lake Formation sont insuffisantes, l'opération ne se basera pas sur les informations d'identification du rôle d'exécution. Pour les tables non enregistrées auprès de Lake Formation, les informations d'identification du rôle d'exécution du travail accèdent aux données de la table.
-
Les opérations marquées comme étant prises en charge par des autorisations IAM sur le site Amazon S3 n'utilisent pas les informations d'identification de Lake Formation pour accéder aux données des tables sous-jacentes dans Amazon S3. Pour exécuter ces opérations, le rôle d'exécution des tâches doit disposer des autorisations Amazon S3 IAM nécessaires pour accéder aux données de la table, que la table soit enregistrée ou non auprès de Lake Formation.
