Aidez à améliorer cette page
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Pour contribuer à ce guide de l'utilisateur, cliquez sur le GitHub lien Modifier cette page sur qui se trouve dans le volet droit de chaque page.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillez le trafic de charge de travail de Kubernetes avec Container Network Observability
Amazon EKS fournit des fonctionnalités d'observabilité réseau améliorées qui fournissent des informations plus approfondies sur votre environnement réseau de conteneurs. Ces fonctionnalités vous aident à mieux comprendre, surveiller et dépanner votre environnement réseau Kubernetes dans. AWS Grâce à l'observabilité améliorée du réseau de conteneurs, vous pouvez tirer parti de mesures granulaires liées au réseau pour une meilleure détection proactive des anomalies dans le trafic des clusters, les flux inter-AZ et les services. AWS À l'aide de ces indicateurs, vous pouvez mesurer les performances du système et visualiser les indicateurs sous-jacents à l'aide de votre stack d'observabilité préféré.
En outre, Amazon EKS fournit désormais des visualisations de surveillance du réseau dans la AWS console qui accélèrent et améliorent le dépannage précis pour une analyse plus rapide des causes premières. Vous pouvez également tirer parti de ces fonctionnalités visuelles pour identifier les principaux intervenants et les flux réseau à l'origine des retransmissions et des délais de retransmission, éliminant ainsi les angles morts lors d'incidents.
Ces fonctionnalités sont activées par Amazon CloudWatch Network Flow Monitor.
Cas d’utilisation
Mesurez les performances du réseau pour détecter les anomalies
Plusieurs équipes s'appuient sur une pile d'observabilité qui leur permet de mesurer les performances de leur système, de visualiser les indicateurs du système et de s'alarmer en cas de dépassement d'un seuil spécifique. L'observabilité du réseau de conteneurs dans EKS va dans ce sens en exposant les indicateurs clés du système que vous pouvez extraire pour élargir l'observabilité des performances du réseau de votre système au niveau du pod et du nœud de travail.
Tirez parti des visualisations de console pour un dépannage plus précis
En cas d'alarme provenant de votre système de surveillance, vous souhaiterez peut-être vous concentrer sur le cluster et la charge de travail à l'origine du problème. À cette fin, vous pouvez tirer parti des visualisations de la console EKS qui réduisent le champ d'investigation au niveau du cluster et accélèrent la divulgation des flux réseau responsables du plus grand nombre de retransmissions, des délais de retransmission et du volume de données transférées.
Suivez les personnes qui parlent le plus dans votre environnement Amazon EKS
De nombreuses équipes utilisent EKS comme base de leurs plateformes, ce qui en fait le point central de l'activité réseau d'un environnement applicatif. À l'aide des fonctionnalités de surveillance du réseau de cette fonctionnalité, vous pouvez suivre les charges de travail responsables de la majeure partie du trafic (mesuré par le volume de données) au sein du cluster, entre les zones de disponibilité, ainsi que le trafic vers des destinations externes au sein AWS (DynamoDB et S3) et au-delà AWS du cloud (Internet ou sur site). En outre, vous pouvez surveiller les performances de chacun de ces flux en fonction des retransmissions, des délais de retransmission et des données transférées.
Caractéristiques
-
Indicateurs de performance - Cette fonctionnalité vous permet de récupérer les indicateurs système liés au réseau pour les pods et les nœuds de travail directement à partir de l'agent Network Flow Monitor (NFM) exécuté dans votre cluster EKS.
-
Carte des services : cette fonctionnalité permet de visualiser de manière dynamique l'intercommunication entre les charges de travail du cluster, ce qui vous permet de divulguer rapidement les indicateurs clés (retransmissions - RT, délais de retransmission - RTO et données transférées - DT) associés aux flux réseau entre les modules communicants.
-
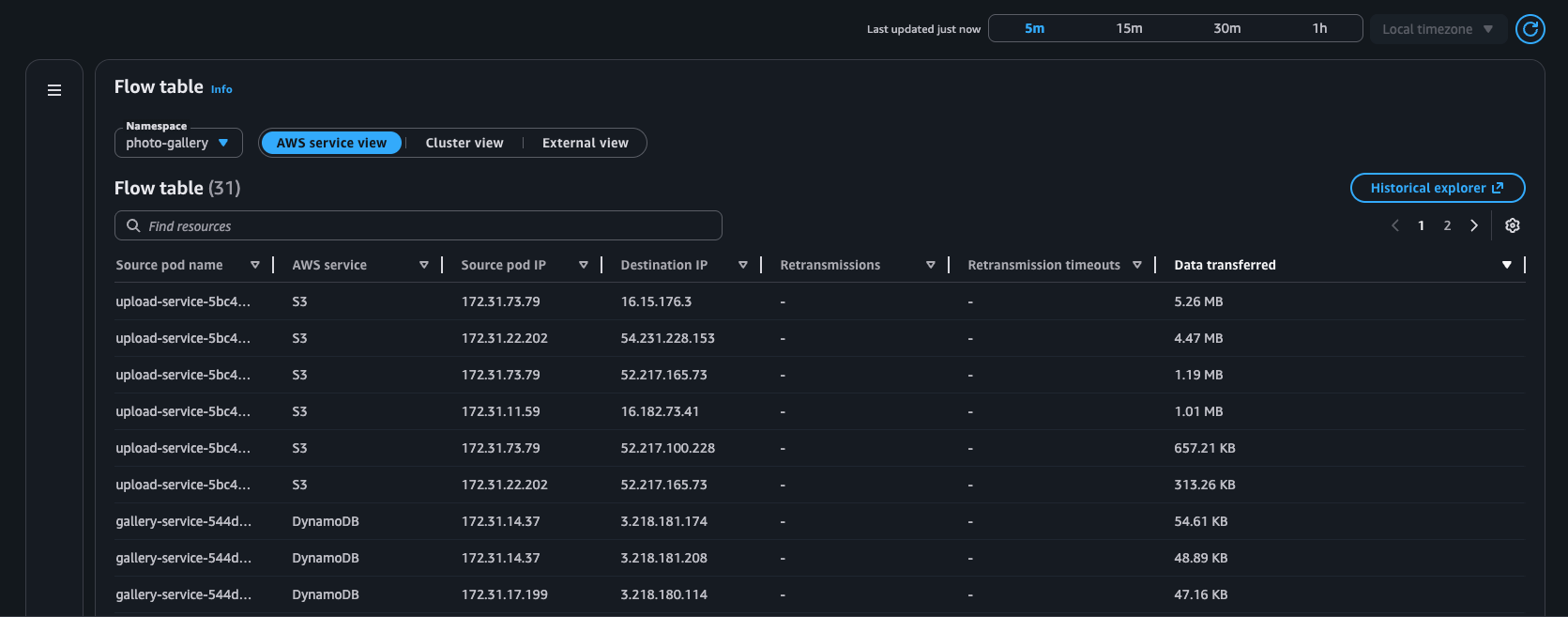
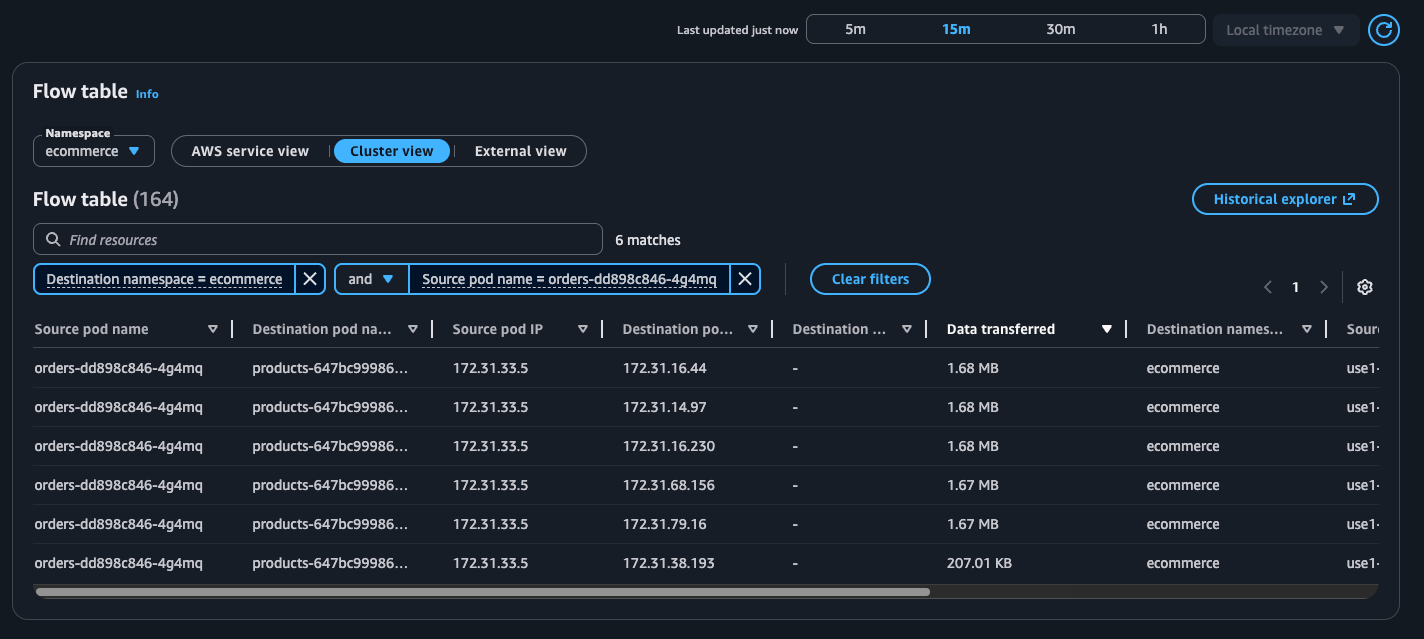
Tableau de flux : avec ce tableau, vous pouvez surveiller les principaux intervenants des charges de travail Kubernetes de votre cluster sous trois angles différents : vue du AWS service, vue du cluster et vue externe. Pour chaque vue, vous pouvez voir les retransmissions, les délais de retransmission et les données transférées entre le module source et sa destination.
-
AWS vue des services : affiche les principaux interlocuteurs des AWS services (DynamoDB et S3)
-
Vue du cluster : affiche les principaux orateurs du cluster (est ← vers → ouest)
-
Vue externe : affiche les meilleurs orateurs vers des destinations externes au cluster situées à l'extérieur AWS
-
Mise en route
Pour commencer, activez Container Network Observability dans la console EKS pour un cluster nouveau ou existant. Cela automatisera la création des dépendances du Network Flow Monitor (NFM) (ressources Scope et Monitor). En outre, vous devrez installer le module complémentaire Network Flow Monitor Agent. Vous pouvez également installer ces dépendances à l'aide des API EKS (pour le AWS CLI module complémentaire), des API NFM ou de l'infrastructure en tant que code (comme Terraform
Lorsque vous utilisez Network Flow Monitor dans EKS, vous pouvez conserver votre flux de travail d'observabilité et votre infrastructure technologique existants tout en tirant parti d'un ensemble de fonctionnalités supplémentaires qui vous permettent de mieux comprendre et d'optimiser la couche réseau de votre environnement EKS. Pour en savoir plus sur la tarification du Network Flow Monitor, cliquez ici.
Prérequis et remarques importantes
-
Comme indiqué ci-dessus, si vous activez Container Network Observability depuis la console EKS, les dépendances des ressources NFM sous-jacentes (Scope et Monitor) seront automatiquement créées en votre nom, et vous serez guidé tout au long du processus d'installation du module complémentaire EKS pour NFM.
-
Si vous souhaitez activer cette fonctionnalité à l'aide de l'infrastructure en tant que code (iAc) comme Terraform, vous devrez définir les dépendances suivantes dans votre iAC : NFM Scope, NFM Monitor, module complémentaire EKS pour NFM. En outre, vous devrez accorder les autorisations nécessaires au module complémentaire EKS à l'aide de Pod Identity ou de rôles IAM pour les comptes de service (IRSA).
-
Vous devez exécuter une version minimale de 1.1.0 pour le module complémentaire EKS de l'agent NFM.
-
Vous devez utiliser la version 6.21.0 ou supérieure du AWS fournisseur Terraform
pour prendre en charge les ressources du Network Flow Monitor.
Autorisations IAM requises
Module complémentaire EKS pour agent NFM
Vous pouvez utiliser la politique CloudWatchNetworkFlowMonitorAgentPublishPolicyAWS gérée avec Pod Identity. Cette politique contient des autorisations permettant à l'agent NFM d'envoyer des rapports de télémétrie (métriques) à un point de terminaison Network Flow Monitor.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect" : "Allow", "Action" : [ "networkflowmonitor:Publish" ], "Resource" : "*" } ] }
Observabilité du réseau de conteneurs dans la console EKS
Les autorisations suivantes sont requises pour activer la fonctionnalité et visualiser la carte des services et le tableau des flux dans la console.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect": "Allow", "Action": [ "networkflowmonitor:ListScopes", "networkflowmonitor:ListMonitors", "networkflowmonitor:GetScope", "networkflowmonitor:GetMonitor", "networkflowmonitor:CreateScope", "networkflowmonitor:CreateMonitor", "networkflowmonitor:TagResource", "networkflowmonitor:StartQueryMonitorTopContributors", "networkflowmonitor:StopQueryMonitorTopContributors", "networkflowmonitor:GetQueryStatusMonitorTopContributors", "networkflowmonitor:GetQueryResultsMonitorTopContributors" ], "Resource": "*" } ] }
Utilisation de la AWS CLI, de l'API EKS et de l'API NFM
#!/bin/bash # Script to create required Network Flow Monitor resources set -e CLUSTER_NAME="my-eks-cluster" CLUSTER_ARN="arn:aws:eks:{Region}:{Account}:cluster/{ClusterName}" REGION="us-west-2" AGENT_NAMESPACE="amazon-network-flow-monitor" echo "Creating Network Flow Monitor resources..." # Check if Network Flow Monitor agent is running in the cluster echo "Checking for Network Flow Monitor agent in cluster..." if kubectl get pods -n "$AGENT_NAMESPACE" --no-headers 2>/dev/null | grep -q "Running"; then echo "Network Flow Monitor agent exists and is running in the cluster" else echo "Network Flow Monitor agent not found. Installing as EKS addon..." aws eks create-addon \ --cluster-name "$CLUSTER_NAME" \ --addon-name "$AGENT_NAMESPACE" \ --region "$REGION" echo "Network Flow Monitor addon installation initiated" fi # Get Account ID ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) echo "Cluster ARN: $CLUSTER_ARN" echo "Account ID: $ACCOUNT_ID" # Check for existing scope echo "Checking for existing Network Flow Monitor Scope..." EXISTING_SCOPE=$(aws networkflowmonitor list-scopes --region $REGION --query 'scopes[0].scopeArn' --output text 2>/dev/null || echo "None") if [ "$EXISTING_SCOPE" != "None" ] && [ "$EXISTING_SCOPE" != "null" ]; then echo "Using existing scope: $EXISTING_SCOPE" SCOPE_ARN=$EXISTING_SCOPE else echo "Creating new Network Flow Monitor Scope..." SCOPE_RESPONSE=$(aws networkflowmonitor create-scope \ --targets "[{\"targetIdentifier\":{\"targetId\":{\"accountId\":\"${ACCOUNT_ID}\"},\"targetType\":\"ACCOUNT\"},\"region\":\"${REGION}\"}]" \ --region $REGION \ --output json) SCOPE_ARN=$(echo $SCOPE_RESPONSE | jq -r '.scopeArn') echo "Scope created: $SCOPE_ARN" fi # Create Network Flow Monitor with EKS Cluster as local resource echo "Creating Network Flow Monitor..." MONITOR_RESPONSE=$(aws networkflowmonitor create-monitor \ --monitor-name "${CLUSTER_NAME}-monitor" \ --local-resources "type=AWS::EKS::Cluster,identifier=${CLUSTER_ARN}" \ --scope-arn "$SCOPE_ARN" \ --region $REGION \ --output json) MONITOR_ARN=$(echo $MONITOR_RESPONSE | jq -r '.monitorArn') echo "Monitor created: $MONITOR_ARN" echo "Network Flow Monitor setup complete!" echo "Monitor ARN: $MONITOR_ARN" echo "Scope ARN: $SCOPE_ARN" echo "Local Resource: AWS::EKS::Cluster (${CLUSTER_ARN})"
Utilisation de l'infrastructure en tant que code (IaC)
Terraform
Si vous utilisez Terraform pour gérer votre infrastructure AWS cloud, vous pouvez inclure les configurations de ressources suivantes pour activer l'observabilité du réseau de conteneurs pour votre cluster.
Champ d'application NFM
data "aws_caller_identity" "current" {} resource "aws_networkflowmonitor_scope" "example" { target { region = "us-east-1" target_identifier { target_type = "ACCOUNT" target_id { account_id = data.aws_caller_identity.current.account_id } } } tags = { Name = "example" } }
Moniteur NFM
resource "aws_networkflowmonitor_monitor" "example" { monitor_name = "eks-cluster-name-monitor" scope_arn = aws_networkflowmonitor_scope.example.scope_arn local_resource { type = "AWS::EKS::Cluster" identifier = aws_eks_cluster.example.arn } remote_resource { type = "AWS::Region" identifier = "us-east-1" # this must be the same region that the cluster is in } tags = { Name = "example" } }
Module complémentaire EKS pour NFM
resource "aws_eks_addon" "example" { cluster_name = aws_eks_cluster.example.name addon_name = "aws-network-flow-monitoring-agent" }
Fonctionnement
Métriques de performances
Métriques du système
Si vous utilisez des outils tiers (3P) pour surveiller votre environnement EKS (tels que Prometheus et Grafana), vous pouvez récupérer les métriques système prises en charge directement à partir de l'agent Network Flow Monitor. Ces mesures peuvent être envoyées à votre système de surveillance pour étendre la mesure des performances réseau de votre système au niveau du module et du nœud de travail. Les métriques disponibles sont répertoriées dans le tableau, sous Métriques système prises en charge.
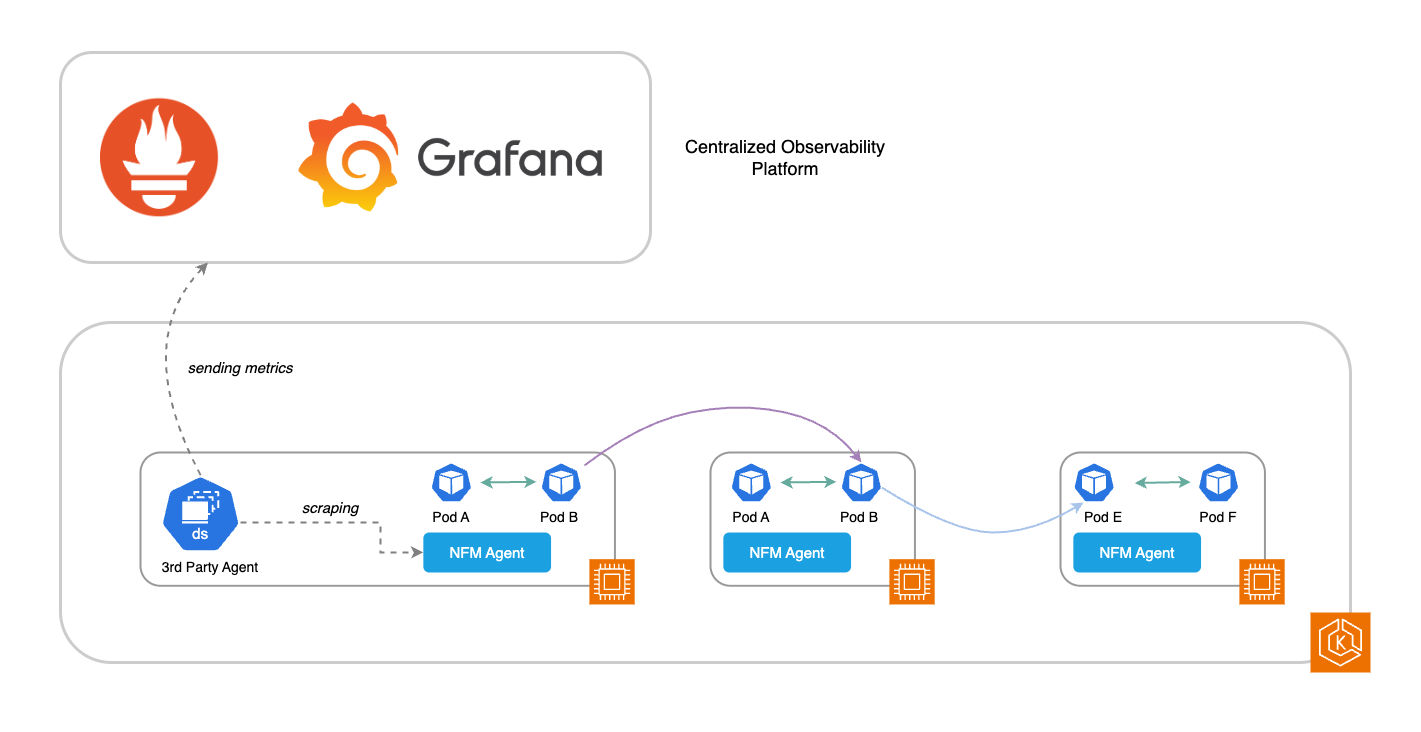
Pour activer ces métriques, remplacez les variables d'environnement suivantes à l'aide des variables de configuration au cours du processus d'installation (voir :https://aws.amazon.com/blogs/containers/amazon-eks-add-ons-advanced-configuration/) :
OPEN_METRICS: Enable or disable open metrics. Disabled if not supplied Type: String Values: [“on”, “off”] OPEN_METRICS_ADDRESS: Listening IP address for open metrics endpoint. Defaults to 127.0.0.1 if not supplied Type: String OPEN_METRICS_PORT: Listening port for open metrics endpoint. Defaults to 80 if not supplied Type: Integer Range: [0..65535]
Mesures du niveau de débit
En outre, Network Flow Monitor capture les données de flux réseau ainsi que les mesures de niveau de débit : retransmissions, délais de retransmission et données transférées. Ces données sont traitées par Network Flow Monitor et visualisées dans la console EKS pour faire apparaître le trafic dans l'environnement de votre cluster et ses performances en fonction de ces mesures de niveau de flux.
Le schéma ci-dessous décrit un flux de travail dans lequel les deux types de métriques (système et niveau de flux) peuvent être exploités pour obtenir une meilleure intelligence opérationnelle.
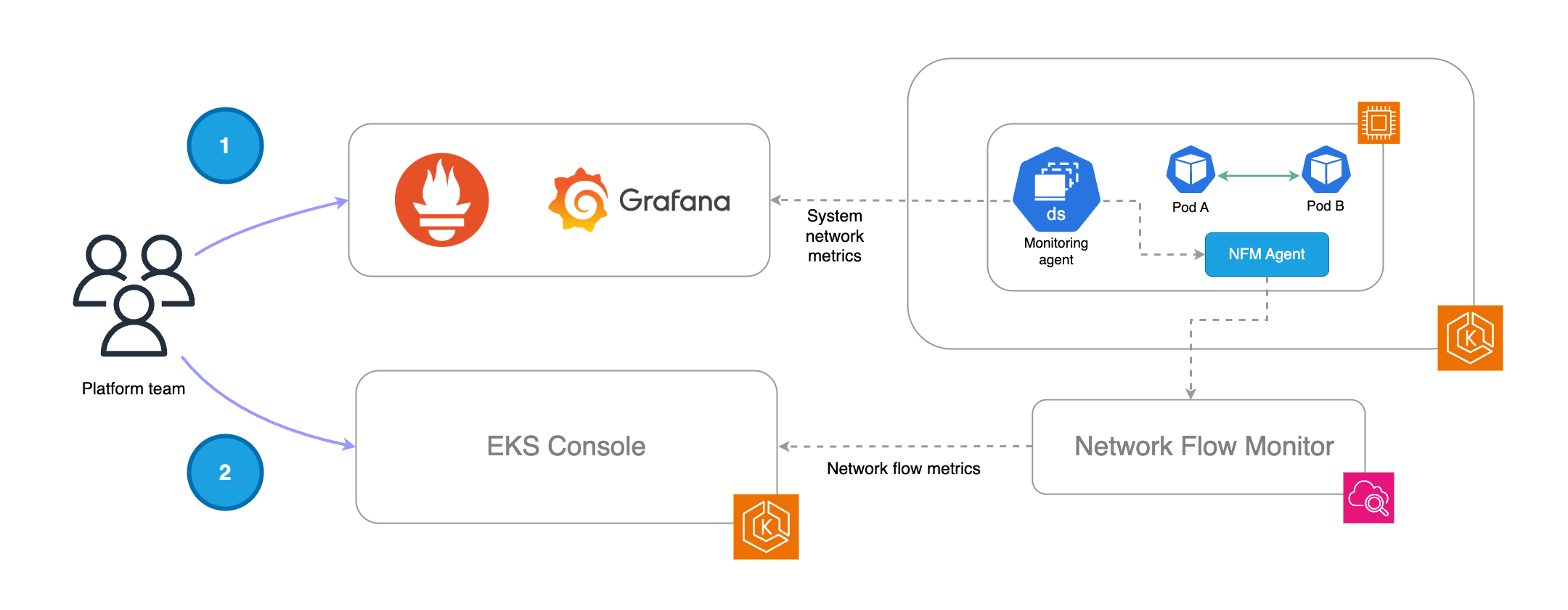
-
L'équipe de la plateforme peut collecter et visualiser les métriques du système dans sa pile de surveillance. Une fois les alertes en place, ils peuvent détecter les anomalies du réseau ou les problèmes affectant les pods ou les nœuds de travail à l'aide des métriques du système fournies par l'agent NFM.
-
À l'étape suivante, les équipes chargées de la plateforme peuvent tirer parti des visualisations natives de la console EKS pour réduire davantage le champ d'investigation et accélérer le dépannage en fonction des représentations des flux et des indicateurs associés.
Remarque importante : l'extraction des métriques du système depuis l'agent NFM et le processus par lequel l'agent NFM envoie les métriques de niveau de flux vers le backend NFM sont des processus indépendants.
Métriques du système prises en charge
Remarque importante : les métriques du système sont exportées au OpenMetrics
| Nom de la métrique | Type | Dimensions | Description |
|---|---|---|---|
|
flux d'entrée |
Jauge |
instance_id, iface, pod, espace de noms, nœud |
Nombre de flux TCP d'entrée () TcpPassiveOpens |
|
flux de sortie |
Jauge |
instance_id, iface, pod, espace de noms, nœud |
Nombre de flux TCP de sortie () TcpActiveOpens |
|
paquets d'entrée |
Jauge |
instance_id, iface, pod, espace de noms, nœud |
Nombre de paquets entrants (delta) |
|
paquets de sortie |
Jauge |
instance_id, iface, pod, espace de noms, nœud |
Nombre de paquets de sortie (delta) |
|
octets d'entrée |
Jauge |
instance_id, iface, pod, espace de noms, nœud |
Nombre d'octets d'entrée (delta) |
|
octets de sortie |
Jauge |
instance_id, iface, pod, espace de noms, nœud |
Nombre d'octets de sortie (delta) |
|
bw_in_allowance_exceeded |
Jauge |
instance_id, eni, nœud |
Paquets queued/dropped dus à une limite de bande passante entrante |
|
bw_out_allowance_exceeded |
Jauge |
instance_id, eni, nœud |
Paquets queued/dropped dus à une limite de bande passante sortante |
|
pps_allowance_dépassé |
Jauge |
instance_id, eni, nœud |
Paquets queued/dropped dus à une limite PPS bidirectionnelle |
|
conntrack_allowance_exceeded |
Jauge |
instance_id, eni, nœud |
Paquets abandonnés en raison de la limite de suivi des connexions |
|
linklocal_allowance_exceeded |
Jauge |
instance_id, eni, nœud |
Paquets abandonnés en raison de la limite PPS du service proxy local |
Mesures de niveau de débit prises en charge
| Nom de la métrique | Type | Description |
|---|---|---|
|
Retransmissions TCP |
Compteur |
Nombre de fois qu'un expéditeur renvoie un paquet perdu ou endommagé pendant la transmission. |
|
Délais de retransmission TCP |
Compteur |
Nombre de fois qu'un expéditeur a entamé une période d'attente pour déterminer si un paquet avait été perdu en transit. |
|
Données (octets) transférées |
Compteur |
Volume de données transféré entre une source et une destination pour un flux donné. |
Carte des services et tableau des flux
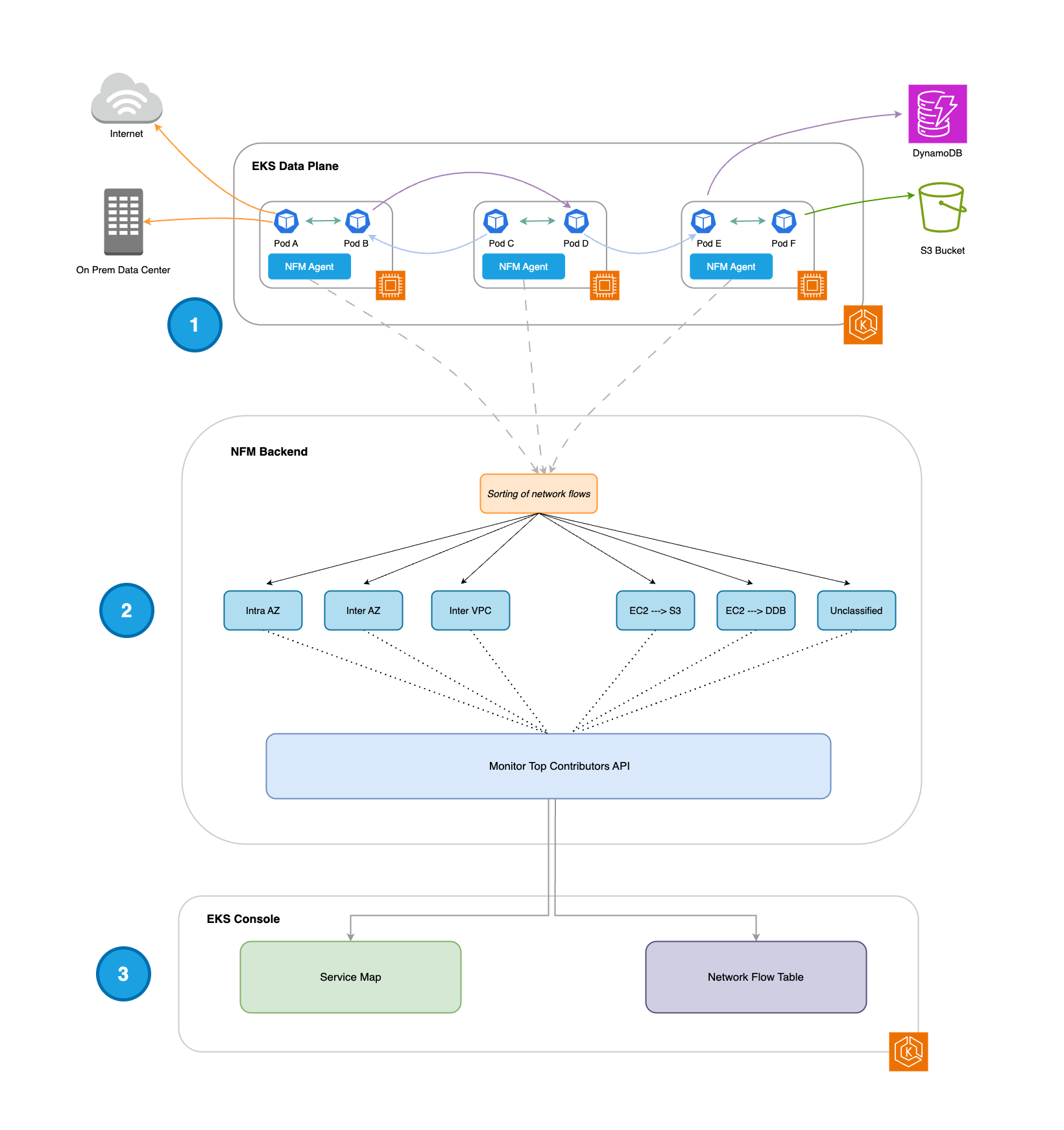
-
Une fois installé, l'agent Network Flow Monitor s'exécute DaemonSet sur chaque nœud de travail et collecte les 500 principaux flux réseau (en fonction du volume de données transférées) toutes les 30 secondes.
-
Ces flux réseau sont classés dans les catégories suivantes : Intra AZ, Inter AZ, EC2 → S3, EC2 → DynamoDB (DDB) et Non classifié. Chaque flux est associé à 3 métriques : les retransmissions, les délais de retransmission et les données transférées (en octets).
-
Intra AZ : le réseau circule entre les pods d'une même zone
-
Inter AZ - le réseau circule entre les pods de différentes AZ
-
EC2 → S3 - flux réseau des pods vers S3
-
EC2 → DDB - flux réseau des pods vers DDB
-
Non classé : flux réseau des modules vers Internet ou sur site
-
-
Les flux réseau issus de l'API Top Contributors de Network Flow Monitor sont utilisés pour alimenter les expériences suivantes dans la console EKS :
-
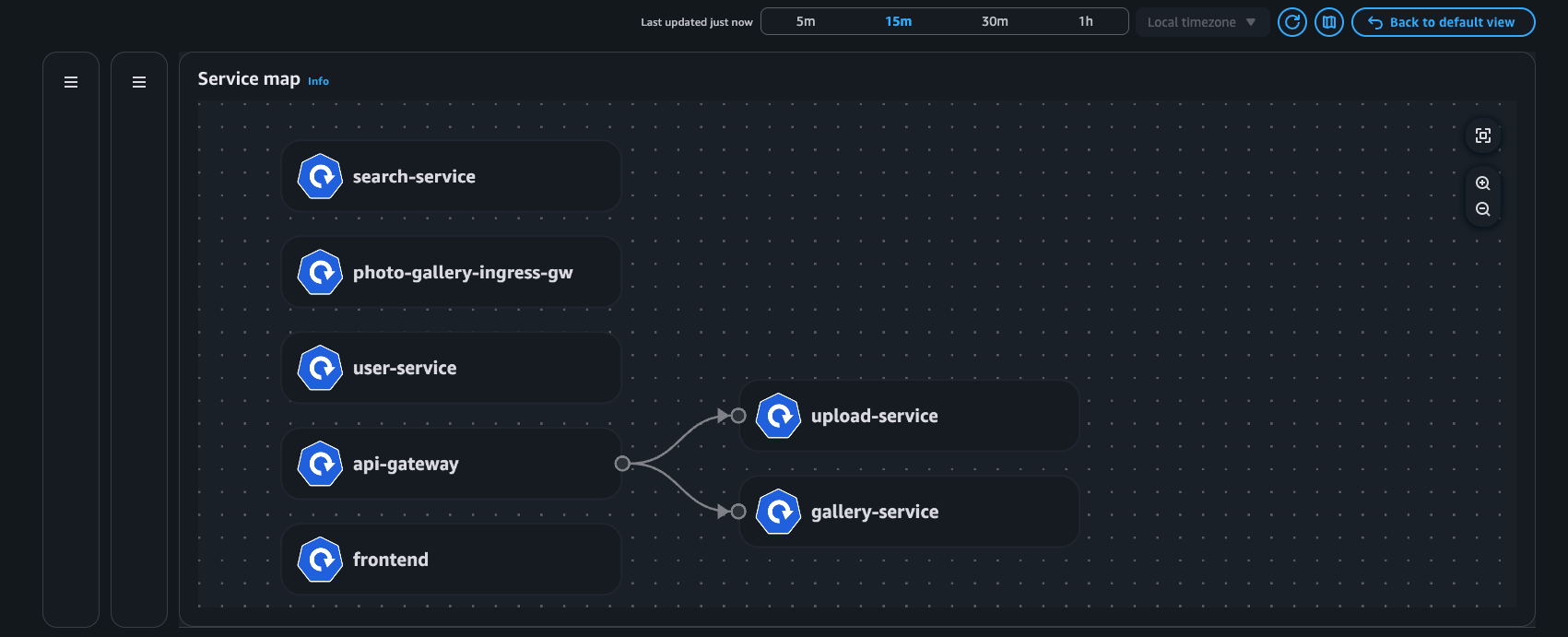
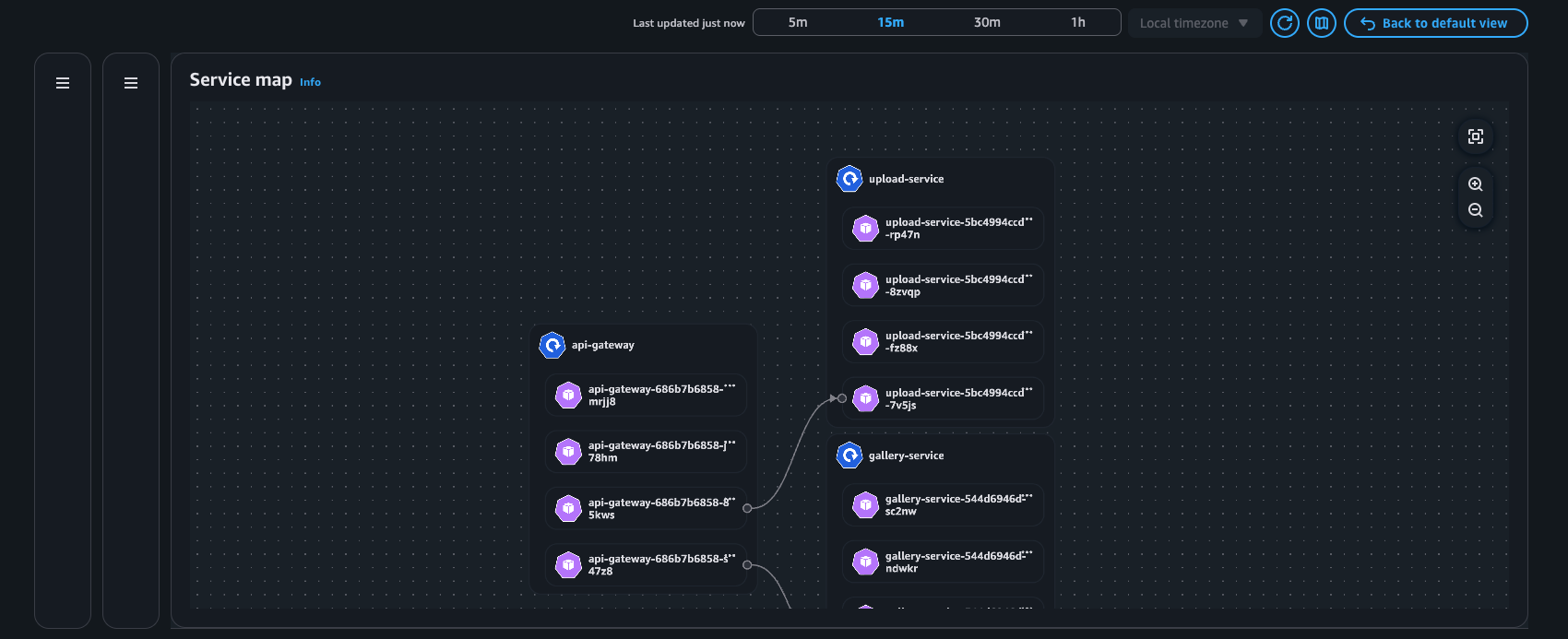
Carte des services : visualisation des flux réseau au sein du cluster (Intra AZ et Inter AZ).
-
Tableau des flux : tableau présentant les flux réseau au sein du cluster (Intra AZ et Inter AZ), des pods aux AWS services (EC2 → S3 et EC2 → DDB), et des pods aux destinations externes (non classés).
-
Les flux réseau extraits de l'API Top Contributors sont limités à une heure et peuvent inclure jusqu'à 500 flux de chaque catégorie. Pour la carte des services, cela signifie que jusqu'à 1 000 flux peuvent être sélectionnés et présentés à partir des catégories de flux Intra AZ et Inter AZ sur une plage horaire d'une heure. Pour le tableau des flux, cela signifie que jusqu'à 2 500 flux réseau peuvent être obtenus et présentés à partir des 5 catégories de flux réseau sur une période de 2 heures.
Exemple : carte des services
Vue du déploiement
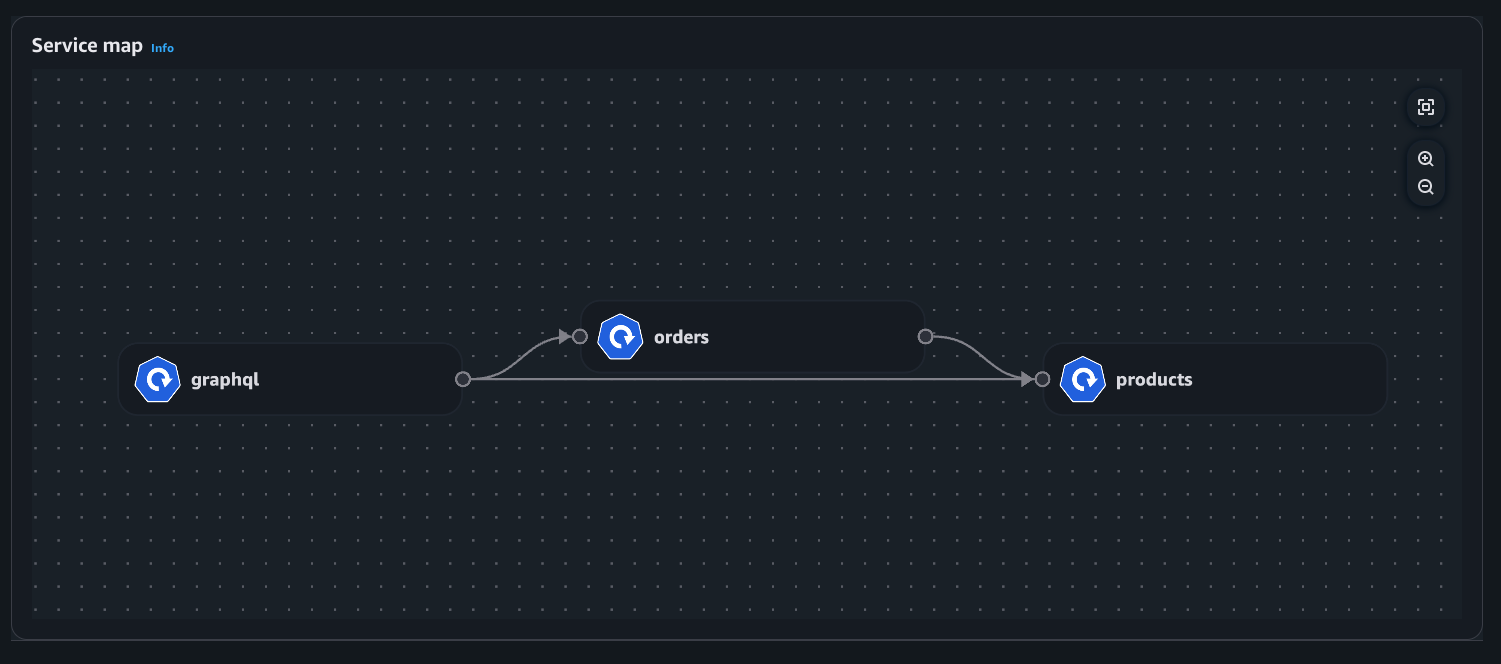
Vue du pod
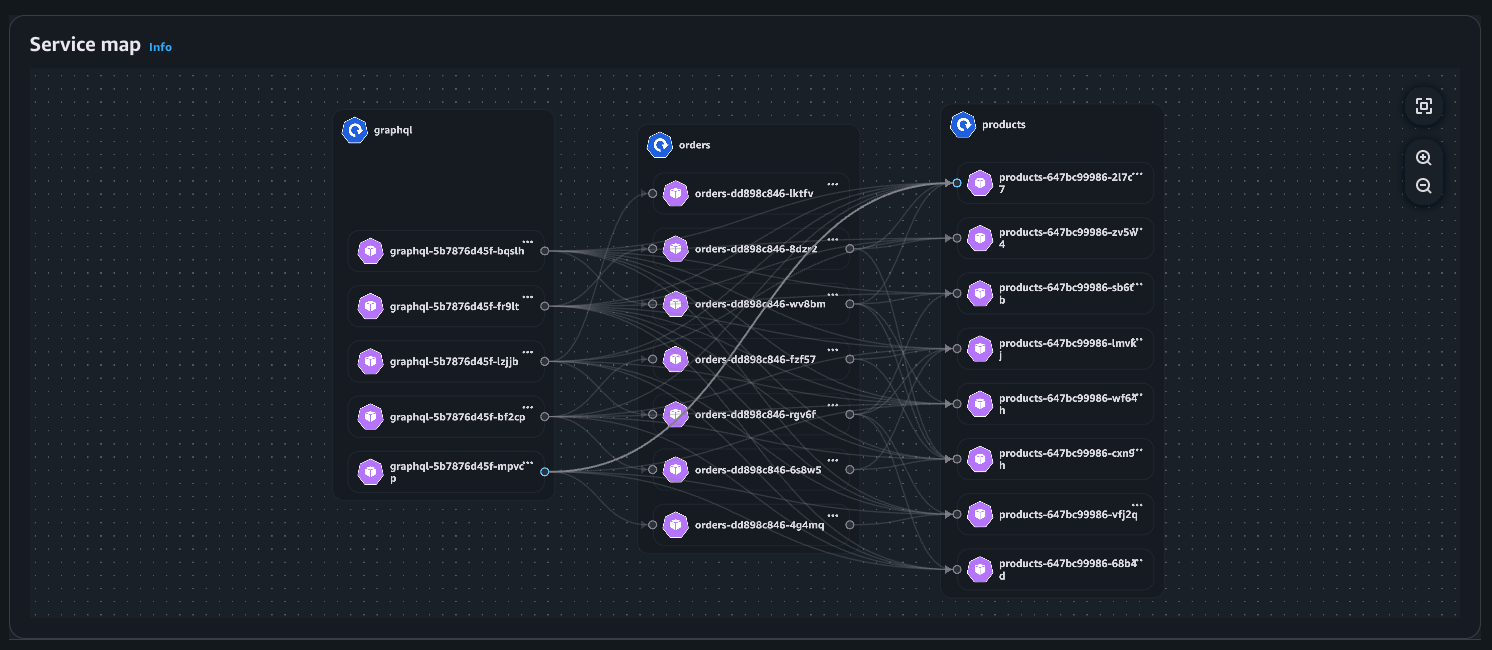
Vue du déploiement
Vue du pod
Exemple : tableau de flux
AWS vue du service
Vue du cluster
Considérations et restrictions
-
L'observabilité du réseau de conteneurs dans EKS n'est disponible que dans les régions où Network Flow Monitor est pris en charge.
-
Les métriques système prises en charge sont OpenMetrics au format et peuvent être directement extraites de l'agent Network Flow Monitor (NFM).
-
Pour activer l'observabilité du réseau de conteneurs dans EKS à l'aide de l'infrastructure en tant que code (iAc) comme Terraform
, vous devez définir et créer les dépendances suivantes dans vos configurations : portée NFM, moniteur NFM et agent NFM. -
Network Flow Monitor prend en charge jusqu'à environ 5 millions de flux par minute. Il s'agit d'environ 5 000 instances EC2 (nœuds de travail EKS) sur lesquelles l'agent Network Flow Monitor est installé. L'installation d'agents sur plus de 5 000 instances peut affecter les performances de surveillance jusqu'à ce que des capacités supplémentaires soient disponibles.
-
Vous devez exécuter une version minimale de 1.1.0 pour le module complémentaire EKS de l'agent NFM.
-
Vous devez utiliser la version 6.21.0 ou supérieure du AWS fournisseur Terraform
pour prendre en charge les ressources du Network Flow Monitor. -
Pour enrichir les flux réseau avec les métadonnées des pods, vos pods doivent s'exécuter dans leur propre espace de noms réseau isolé, et non dans l'espace de noms du réseau hôte.
