Aidez à améliorer cette page
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Pour contribuer à ce guide de l'utilisateur, cliquez sur le GitHub lien Modifier cette page sur qui se trouve dans le volet droit de chaque page.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Charger & des modèles de serveur sur Amazon EKS
Astuce
Inscrivez-vous
Les étapes décrites dans cette section permettent de déployer un modèle de langage étendu (LLM) sur Amazon EKS, de le diffuser avec vLLM et d'interagir avec le point de terminaison d'inférence.
La procédure pas à pas utilise les outils suivants :
-
vLLM
: moteur d'inférence à haut débit optimisé pour le service LLM et la gestion de la mémoire GPU. -
Run:ai Model Streamer
: diffuse les poids des modèles directement depuis Amazon S3 vers la mémoire GPU, réduisant ainsi le temps de chargement de quelques minutes à quelques secondes. -
Open WebUI
: interface de discussion auto-hébergée qui se connecte à l'API de vLLM. OpenAI-compatible
Cette section utilise le Ministral-3-8B-Instruct-2512 modèle
Important
Utilisez le cluster que vous avez créé dans la Configuration du cluster Amazon EKS pour les charges AI/ML de travail section. Les instructions de cette procédure pas à pas fonctionnent à la fois pour le mode automatique EKS et pour Karpenter autogéré.
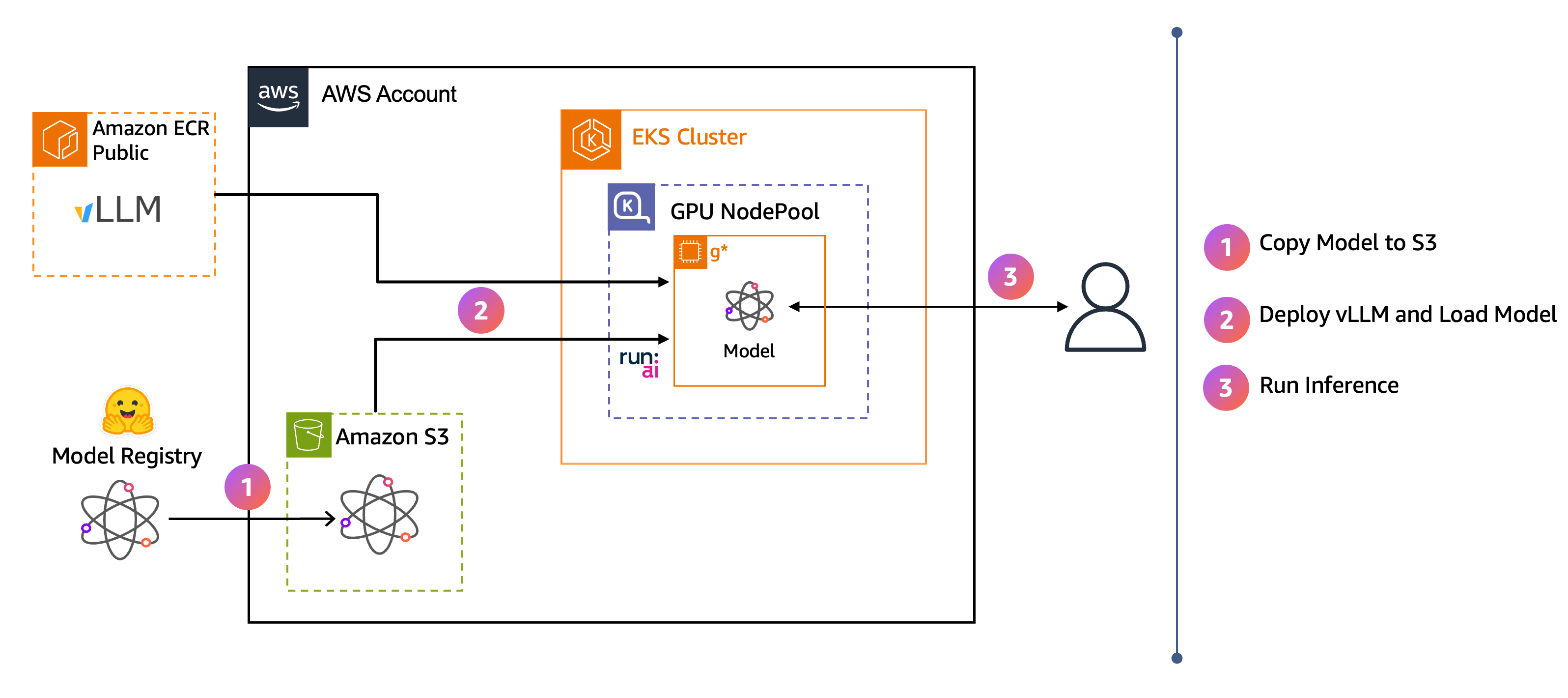
Le schéma d'architecture montre le flux de bout en bout :
-
Les poids des modèles sont téléchargés depuis Hugging Face vers Amazon S3.
-
vLLM diffuse le modèle directement depuis S3 vers la mémoire du GPU à l'aide de Run:ai Model Streamer.
-
Les utilisateurs envoient des demandes d'inférence au point de terminaison vLLM.
Lorsque vous avez effectué ces étapes, vous disposez d'un point de terminaison d'inférence vLLM que vous pouvez utiliser pour interagir avec un modèle ministériel via une application d'interface de chat.
Conditions préalables
Suivez les étapes décrites dans la section Configuration du cluster.
Si vous avez ouvert un nouveau terminal, définissez le nom du cluster et la région que vous avez utilisés dans la section Configuration du cluster via CLI :
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Recherchez le compartiment de poids du modèle que vous avez créé à l'étape du compartiment S3 du poids du modèle :
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
Étape 1 : Téléchargez le modèle depuis Hugging Face
Au cours de cette étape, vous déployez un Kubernetes Job qui télécharge le modèle depuis Hugging Face et le télécharge dans le compartiment S3 que vous avez créé dans la section des prérequis.
Pour télécharger le modèle, appliquez le manifeste de Job suivant :
cat << EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-download namespace: default labels: guide: ai-eks-docs spec: backoffLimit: 10 activeDeadlineSeconds: 3600 ttlSecondsAfterFinished: 86400 template: spec: restartPolicy: Never serviceAccountName: model-storage-sa containers: - name: downloader image: python:3.11-slim command: ["/bin/bash", "-c"] args: - | set -e pip install -q huggingface_hub boto3 echo "Downloading Ministral-3-8B-Instruct-2512 from Hugging Face..." python3 -c "from huggingface_hub import snapshot_download; snapshot_download('mistralai/Ministral-3-8B-Instruct-2512', local_dir='/tmp/mistral', allow_patterns=['*.json', '*.txt', '*.md', 'consolidated.safetensors'], ignore_patterns=['model-*.safetensors', 'model.safetensors.index.json'])" echo "Uploading to S3 bucket: \${MODEL_BUCKET}" python3 << 'PYTHON' import boto3 import os from pathlib import Path s3 = boto3.client('s3') bucket = os.environ.get('MODEL_BUCKET') local_dir = Path("/tmp/mistral") for file_path in local_dir.rglob("*"): if file_path.is_file(): if '.cache' in file_path.parts: continue s3_key = f"Ministral-3-8B-Instruct-2512/{file_path.relative_to(local_dir)}" print(f"Uploading {file_path.name}...") s3.upload_file(str(file_path), bucket, s3_key) print("Upload complete!") PYTHON env: - name: MODEL_BUCKET value: "${MODEL_BUCKET}" - name: HF_HUB_DISABLE_XET value: "1" resources: requests: memory: "2Gi" cpu: "1" limits: memory: "4Gi" cpu: "2" EOF
Attendez que le Job soit terminé. Les poids du modèle (consolidated.safetensors) sont d'environ 10,4 Go, et cette étape prend généralement 3 à 5 minutes.
kubectl wait --for=condition=complete job/model-download --timeout=600s
Sortie attendue :
job.batch/model-download condition met
Vérifiez que les poids du modèle ont été téléchargés sur S3 :
aws s3 ls s3://$(kubectl get job model-download -o jsonpath='{.spec.template.spec.containers[0].env[?(@.name=="MODEL_BUCKET")].value}')/Ministral-3-8B-Instruct-2512/ --recursive
Sortie attendue :
2026-05-18 10:29:53 20311 Ministral-3-8B-Instruct-2512/README.md 2026-05-18 10:29:53 2361 Ministral-3-8B-Instruct-2512/SYSTEM_PROMPT.txt 2026-05-18 10:29:53 1903 Ministral-3-8B-Instruct-2512/config.json 2026-05-18 10:29:54 10420633176 Ministral-3-8B-Instruct-2512/consolidated.safetensors 2026-05-18 10:29:53 131 Ministral-3-8B-Instruct-2512/generation_config.json 2026-05-18 10:29:53 1185 Ministral-3-8B-Instruct-2512/params.json 2026-05-18 10:29:53 976 Ministral-3-8B-Instruct-2512/processor_config.json 2026-05-18 10:29:53 16753777 Ministral-3-8B-Instruct-2512/tekken.json 2026-05-18 10:29:53 17077402 Ministral-3-8B-Instruct-2512/tokenizer.json 2026-05-18 10:29:53 21168 Ministral-3-8B-Instruct-2512/tokenizer_config.json
Le fichier .safetensors consolidé contient les poids du modèle (environ 10,4 Go). Les autres fichiers sont des fichiers de configuration et de tokenisation dont vLLM a besoin pour servir le modèle.
Étape 2 : Déployer le conteneur d'inférence
Dans cette section, vous déployez vLLM en tant que déploiement Kubernetes pour servir le modèle que vous avez chargé sur Amazon S3.
Cette section utilise les AWS Deep Learning Containers
Ce déploiement utilise le AWS DLC suivant pour vLLM 0.21.0
public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci
La balise image indique vLLM 0.21.0 avec support GPU, Python 3.12, CUDA 13.0, Ubuntu 22.04, optimisé pour les charges de travail et pour EC2-based un démarrage plus rapide des conteneurs. SOCI-enabled
Ce manifeste crée un déploiement qui exécute vLLM sur un nœud GPU et diffuse le modèle directement depuis S3 vers la mémoire GPU à l'aide de Run:ai Model Streamer. Le manifeste crée également un service ClusterIP qui expose le point de terminaison vLLM sur le port 8000 pour un accès intégré au cluster.
Appliquez le manifeste :
cat << EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app labels: guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app guide: ai-eks-docs spec: serviceAccountName: model-storage-sa tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule nodeSelector: karpenter.sh/nodepool: gpu-inf containers: - name: vllm-inference image: public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci ports: - containerPort: 8000 args: - "--model=s3://${MODEL_BUCKET}/Ministral-3-8B-Instruct-2512/" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" - "--load-format=runai_streamer" - "--enforce-eager" - "--tokenizer_mode=mistral" - "--config_format=mistral" - "--enable-auto-tool-choice" - "--tool-call-parser=mistral" resources: limits: nvidia.com/gpu: 1 requests: memory: "40Gi" cpu: "8" --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc namespace: default labels: app: vllm-inference-app spec: selector: app: vllm-inference-app ports: - name: http port: 8000 targetPort: 8000 protocol: TCP EOF
Vérifiez que le pod vLLM est à l'état Prêt :
kubectl get pod -l app=vllm-inference-app -w
Sortie attendue :
NAME READY STATUS RESTARTS AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 Running 0 86s
L'extraction de l'image du conteneur peut prendre environ 2 minutes et le transfert des poids du modèle par vLLM depuis S3 vers la mémoire du GPU peut prendre environ 2 minutes. Attendez que le module 1/1 apparaisse dans la colonne PRÊT avant de continuer.
La combinaison d'EKS, de SOCI et de Run:ai Model Streamer permet un démarrage rapide du pod. Pour vérifier l'heure de démarrage de chaque étape, consultez les événements du pod :
kubectl describe pod -l app=vllm-inference-app | grep -A 20 "Events:"
Sortie attendue :
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 86s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). Normal Nominated 85s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-kqkq6 Normal Scheduled 55s default-scheduler Successfully assigned default/vllm-inference-app-d9d54586d-csmd7 to i-04f8792414384d2d3 Normal Pulling 52s kubelet Pulling image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" Normal Pulled 4s kubelet Successfully pulled image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" in 48.376s (48.376s including waiting). Image size: 8802823997 bytes. Normal Created 4s kubelet Created container vllm-inference Normal Started 4s kubelet Started container vllm-inference
Dans cet exemple, le nœud GPU a été provisionné en 30 secondes et l'image du conteneur de 8,8 Go a été extraite en 48 secondes environ à l'aide du protocole SOCI. Les extractions d'images rapides réduisent les temps de démarrage à froid pour les grands conteneurs d'inférence, ce qui vous permet de dimensionner les modules GPU de manière dynamique au lieu de surprovisionner la capacité du GPU inactif.
Ensuite, consultez les journaux vLLM pour vérifier le temps de chargement du modèle :
kubectl logs $(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') | grep -i 'Model loading took'
Sortie attendue :
INFO 05-18 18:41:49 [gpu_model_runner.py:4959] Model loading took 9.81 GiB memory and 5.023344 seconds
Le journal confirme que Run:ai Model Streamer a chargé les 10,4 Go de poids du modèle directement depuis S3 dans la mémoire du processeur graphique en 5 secondes environ, consommant ainsi 9,8 Go de mémoire du processeur graphique.
Dans cet exemple, le temps de téléchargement de l'image était effectué à l'aide d'une instance g6e.4xlarge, dotée d'une bande passante réseau soutenue de 20 Gbit/s. Les temps d'extraction d'images et de chargement des modèles varient selon le type d'instance en fonction de la bande passante réseau disponible.
Étape 3 : Exécuter l'inférence
Lorsque le déploiement vLLM est en cours d'exécution, validez le point de terminaison d'inférence et déployez une interface de chat pour interagir avec le modèle.
Exécuter un test de validation du modèle
Exposez le point de terminaison d'inférence via le port forward :
kubectl port-forward svc/vllm-inference-svc 8000:8000
Ouvrez une nouvelle fenêtre de terminal, puis vérifiez que le conteneur d'inférence répond :
curl -sI -X GET http://localhost:8000/health
Sortie attendue :
HTTP/1.1 200 OK date: Fri, 18 May 2026 00:39:23 GMT server: uvicorn content-length: 0
Étape 4 : Surveiller vLLM
vLLM expose les indicateurs Prometheus prêts à l'emploi, notamment le taux de demandes, le débit de jetons, la latence de bout en bout et l'utilisation du cache KV du GPU. Dans cette section, vous utilisez ces métriques avec la pile de surveillance que vous avez configurée dans les étapes de configuration du cluster et vous les visualisez sur un tableau de bord Grafana préconfiguré.
Important
Vous devez compléter la sous-section Surveillance de la section Configuration du cluster via CLI avant de continuer. Cette étape dépend du kube-prometheus-stack en cours d'installation et du tableau de bord vLLM Grafana déjà configuré dans le fichier de valeurs.
Appliquer le vLLM ServiceMonitor
A ServiceMonitor indique à Prometheus où extraire les métriques VLLM.
cat << EOF | kubectl apply -f - apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: vllm-inference-app namespace: default labels: release: kube-prometheus-stack spec: selector: matchLabels: app: vllm-inference-app endpoints: - port: http path: /metrics interval: 15s EOF
Vérifiez que le ServiceMonitor a été créé :
kubectl get servicemonitor vllm-inference-app
Sortie attendue :
NAME AGE vllm-inference-app 5s
Pour remplir le tableau de bord avec des métriques, générez du trafic d'inférence par rapport au point de terminaison vLLM que vous avez déjà exposé via le port forward lors de l'étape de validation.
Découvrez le nom du modèle desservi :
MODEL_NAME=$(curl -s http://localhost:8000/v1/models | jq -r '.data[0].id') echo "Using model: $MODEL_NAME"
Envoyez 50 demandes de fin de chat en parallèle :
for i in $(seq 1 50); do curl -s -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d "{\"model\": \"$MODEL_NAME\", \"messages\": [{\"role\": \"user\", \"content\": \"Write a short poem about Kubernetes.\"}], \"max_tokens\": 128}" \ > /dev/null & done wait
Pendant que le trafic circule (ou immédiatement après), vérifiez les métriques de débit de jetons directement depuis le point de terminaison vLLM : /metrics
curl -s http://localhost:8000/metrics | grep -E '^vllm:(prompt_tokens_total|generation_tokens_total|avg_generation_throughput_toks_per_s|avg_prompt_throughput_toks_per_s)' | head
Les vllm:generation_tokens_total métriques vllm:prompt_tokens_total et augmentent de façon monotone les compteurs de jetons d'entrée et de sortie servis. Les vllm:avg_generation_throughput_toks_per_s indicateurs vllm:avg_prompt_throughput_toks_per_s et sont des indicateurs de débit à moyenne mobile. Ces mêmes indicateurs alimentent le tableau de bord Grafana que vous ouvrez dans la sous-section suivante.
Afficher le tableau de bord de vLLM Grafana
Le fichier de valeurs kube-prometheus-stack de la section Monitoring approvisionne déjà le tableau de bord vLLM communautaire (GnetID 25263) dans le dossier GPU Monitoring
Pour accéder à Grafana, lancez une redirection de port vers le service Grafana :
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
Ouvrez http://localhost:3000
Tableau de bord vLLM Grafana

Le tableau de bord affiche le taux de demandes, le débit des jetons d'invite et de génération, les percentiles de latence et l'utilisation du cache KV du GPU pour le point de terminaison d'inférence vLLM.
Étape 5 : Déployer l'application de chat
Au cours de cette étape, vous déployez Open WebUI comme interface de discussion pour interagir avec le modèle. Open WebUI est une interface d'IA open source auto-hébergée qui OpenAI-compatible prend en charge les API et fournit une interface de chat avec historique des conversations et rendu des marquages. Comme vLLM expose une OpenAI-compatible API, Open WebUI s'y connecte directement en tant que backend.
Pour déployer l'application Open WebUI, appliquez le manifeste suivant :
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: open-webui namespace: default labels: app: open-webui guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: open-webui template: metadata: labels: app: open-webui guide: ai-eks-docs spec: containers: - name: open-webui image: ghcr.io/open-webui/open-webui:v0.9.2 ports: - containerPort: 8080 resources: requests: cpu: "500m" memory: "500Mi" limits: cpu: "1000m" memory: "1Gi" env: - name: OPENAI_API_BASE_URLS value: "http://vllm-inference-svc:8000/v1" - name: OPENAI_API_KEY value: "dummy" - name: WEBUI_AUTH value: "False" - name: ENABLE_OLLAMA_API value: "False" - name: ENABLE_EVALUATION_ARENA_MODELS value: "False" volumeMounts: - name: webui-volume mountPath: /app/backend/data volumes: - name: webui-volume emptyDir: {} --- apiVersion: v1 kind: Service metadata: name: open-webui namespace: default labels: app: open-webui spec: type: ClusterIP selector: app: open-webui ports: - protocol: TCP port: 80 targetPort: 8080 EOF
Attendez que le module Open WebUI soit prêt :
kubectl wait --for=condition=ready pod -l app=open-webui --timeout=300s
Sortie attendue :
pod/open-webui-6cbfc9867f-jf9w9 condition met
Pour accéder à l'application, configurez la redirection de port et ouvrez l'application dans votre navigateur :
kubectl port-forward svc/open-webui 8080:80 & sleep 5 echo "Open WebUI: http://localhost:8080"
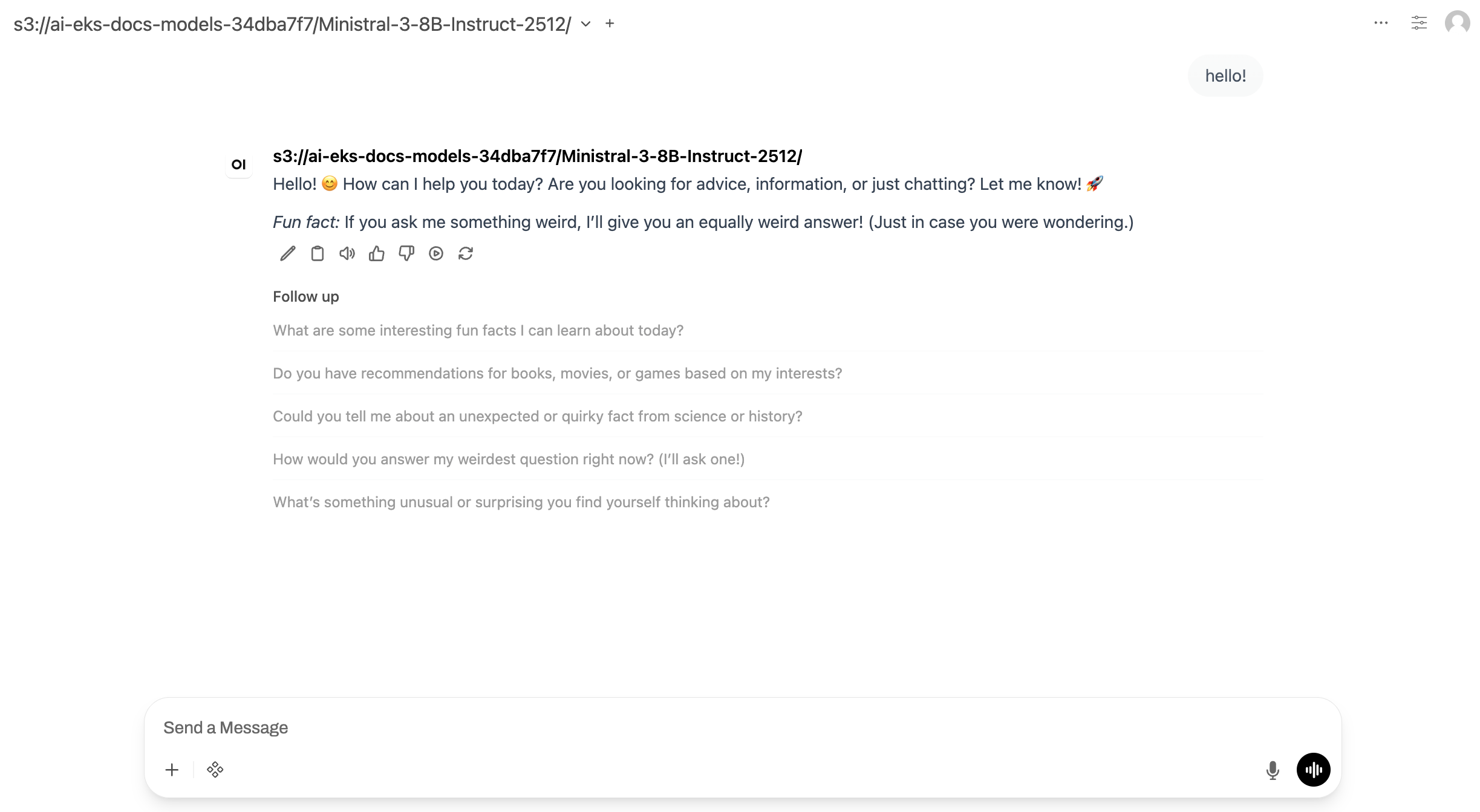
Ouvrez http://localhost:8080
L'interface de chat apparaît où vous pouvez interagir avec le modèle Ministral.
Lorsque vous avez terminé les tests, arrêtez les processus de transfert de port en arrière-plan en les exécutant kill %1 %2 (ou en les exécutant pour les jobs répertorier et kill %<jobspec> pour chacun d'eux).
Nettoyage
Pour supprimer les ressources de charge de travail que vous avez créées dans cette section, supprimez l'application Open WebUI, le serveur d'inférence vLLM et le Job de téléchargement de modèles :
kubectl delete deployment open-webui kubectl delete service open-webui kubectl delete deployment vllm-inference-app kubectl delete service vllm-inference-svc kubectl delete servicemonitor vllm-inference-app kubectl delete job model-download
Pour obtenir des instructions sur la suppression des ressources d'infrastructure telles que le cluster et le compartiment S3 NodePool, consultez la section Nettoyage de la configuration du cluster.
