Aidez à améliorer cette page
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Pour contribuer à ce guide de l'utilisateur, cliquez sur le GitHub lien Modifier cette page sur qui se trouve dans le volet droit de chaque page.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Concepts Kubernetes
Amazon Elastic Kubernetes Service (Amazon EKS) AWS est un service géré basé sur le projet open source Kubernetes.
Cette page divise les concepts Kubernetes en trois sections : Pourquoi choisir Kubernetes ?, Clusters, et Charges de travail. La première section décrit l’intérêt d’utiliser un service Kubernetes, en particulier sous la forme d’un service géré tel qu’Amazon EKS. La section « Charges de travail » traite de la manière dont les applications Kubernetes sont créées, stockées, exécutées et gérées. La section Clusters présente les différents composants qui constituent les clusters Kubernetes et vos responsabilités en matière de création et de maintenance des clusters Kubernetes.
Au fur et à mesure que vous parcourez ce contenu, des liens vous mèneront vers des descriptions plus détaillées des concepts Kubernetes dans la documentation Amazon EKS et Kubernetes, au cas où vous souhaiteriez approfondir l’un des sujets abordés ici. Pour plus d’informations sur la manière dont Amazon EKS implémente le plan de contrôle et les fonctionnalités de calcul Kubernetes, consultez Architecture Amazon EKS.
Pourquoi choisir Kubernetes ?
Kubernetes a été conçu pour améliorer la disponibilité et la capacité de mise à l’échelle lors de l’exécution d’applications conteneurisées critiques et de qualité production. Plutôt que de simplement exécuter Kubernetes sur une seule machine (bien que cela soit possible), Kubernetes atteint ces objectifs en vous permettant d’exécuter des applications sur des ensembles d’ordinateurs qui peuvent s’étendre ou se réduire pour répondre à la demande. Kubernetes comprend des fonctionnalités qui vous facilitent la tâche pour :
-
Déployer des applications sur plusieurs machines (à l’aide de conteneurs déployés dans des pods)
-
Surveiller l’état des conteneurs et redémarrer ceux qui ont échoué
-
Augmenter ou réduire la taille des conteneurs en fonction de la charge
-
Mettre à jour les conteneurs avec les nouvelles versions
-
Répartir les ressources entre les conteneurs
-
Équilibrer le trafic entre les machines
Le fait que Kubernetes automatise ce type de tâches complexes permet aux développeurs d’applications de se concentrer sur la création et l’amélioration de leurs charges de travail applicatives, plutôt que de se soucier de l’infrastructure. Le développeur crée généralement des fichiers de configuration, au format YAML, qui décrivent l’état souhaité de l’application. Cela peut inclure les conteneurs à exécuter, les limites de ressources, le nombre de répliques de Pod, CPU/memory l'allocation, les règles d'affinité, etc.
Attributs de Kubernetes
Pour atteindre ses objectifs, Kubernetes présente les caractéristiques suivantes :
-
Conteneurisé — Kubernetes est un outil d’orchestration de conteneurs. Pour utiliser Kubernetes, vous devez d’abord conteneuriser vos applications. Selon le type d’application, il peut s’agir d’un ensemble de microservices, de tâches par lots ou d’autres formes. Vos applications peuvent alors tirer parti d’un workflow Kubernetes qui englobe un vaste écosystème d’outils, où les conteneurs peuvent être stockés sous forme d’images dans un registre de conteneurs
, déployés sur un cluster Kubernetes et exécutés sur un nœud disponible. Vous pouvez créer et tester des conteneurs individuels sur votre ordinateur local avec Docker ou une autre exécution de conteneurs , avant de les déployer sur votre cluster Kubernetes. -
Évolutif : si la demande pour vos applications dépasse la capacité des instances en cours d’exécution de ces applications, Kubernetes est en mesure d’augmenter verticalement. Au besoin, Kubernetes peut déterminer si les applications ont besoin de plus de CPU ou de mémoire et réagir en augmentant automatiquement la capacité disponible ou en utilisant davantage la capacité existante. La mise à l’échelle peut être effectuée au niveau du pod, s’il y a suffisamment de puissance de calcul disponible pour exécuter davantage d’instances de l’application (mise à l’échelle automatique horizontale des pods
), ou au niveau du nœud, si davantage de nœuds doivent être activés pour gérer l’augmentation de capacité (Cluster Autoscaler ou Karpenter ). Comme la capacité n’est plus nécessaire, ces services peuvent supprimer les pods inutiles et arrêter les nœuds superflus. -
Disponible : si une application ou un nœud devient défaillant ou indisponible, Kubernetes peut déplacer les charges de travail en cours vers un autre nœud disponible. Vous pouvez forcer la question en supprimant simplement une instance en cours d’exécution d’une charge de travail ou d’un nœud qui exécute vos charges de travail. En résumé, cela signifie que les charges de travail peuvent être transférées vers d’autres emplacements si elles ne peuvent plus être exécutées là où elles se trouvent.
-
Déclaratif — Kubernetes utilise la réconciliation active pour vérifier en permanence que l’état que vous déclarez pour votre cluster correspond à l’état réel. En appliquant des objets Kubernetes
à un cluster, généralement par le biais de fichiers de YAML-formatted configuration, vous pouvez, par exemple, demander de démarrer les charges de travail que vous souhaitez exécuter sur votre cluster. Vous pouvez modifier ultérieurement les configurations pour, par exemple, utiliser une version plus récente d’un conteneur ou allouer davantage de mémoire. Kubernetes fera le nécessaire pour établir l’état souhaité. Cela peut inclure la mise en service ou la mise hors service de nœuds, l’arrêt et le redémarrage de charges de travail, ou le retrait de conteneurs mis à jour. -
Composable : Étant donné qu’une application se compose généralement de plusieurs composants, vous souhaitez pouvoir gérer ensemble un ensemble de ces composants (souvent représentés par plusieurs conteneurs). Alors que Docker Compose offre un moyen de le faire directement avec Docker, la commande Kubernetes Kompose
peut vous aider à le faire avec Kubernetes. Consultez Traduire un fichier Docker Compose vers Kubernetes Resources pour obtenir un exemple de la manière de procéder. -
Extensible : Contrairement aux logiciels propriétaires, le projet open source Kubernetes est conçu pour vous permettre d’étendre Kubernetes comme vous le souhaitez afin de répondre à vos besoins. Les API et les fichiers de configuration sont ouverts aux modifications directes. Third-parties sont encouragés à écrire leurs propres contrôleurs
, afin d'étendre à la fois l'infrastructure et les fonctionnalités de Kubernetes pour les utilisateurs finaux. Les webhooks vous permettent de configurer des règles de cluster afin d’appliquer des politiques et de vous adapter à des conditions changeantes. Pour plus d’idées sur la manière d’étendre les clusters Kubernetes, consultez la section Étendre Kubernetes . -
Portable : De nombreuses organisations ont standardisé leurs opérations sur Kubernetes, car cela leur permet de gérer tous leurs besoins applicatifs de la même manière. Les développeurs peuvent utiliser les mêmes pipelines pour créer et stocker des applications conteneurisées. Ces applications peuvent ensuite être déployées sur des clusters Kubernetes exécutés sur site, dans le cloud, sur des terminaux de point de vente dans des restaurants ou sur des appareils IoT dispersés sur les sites distants d'une entreprise. Sa nature open source permet aux utilisateurs de développer ces distributions spéciales de Kubernetes, ainsi que les outils nécessaires pour les gérer.
Gestion Kubernetes
Le code source de Kubernetes est disponible gratuitement. Vous pouvez donc installer et gérer Kubernetes vous-même avec votre propre équipement. Cependant, la gestion autonome de Kubernetes nécessite une expertise opérationnelle approfondie et demande du temps et des efforts pour être maintenue. Pour ces raisons, la plupart des personnes qui déploient des charges de travail de production choisissent un fournisseur de cloud (tel qu’Amazon EKS) ou un fournisseur sur site (tel qu’Amazon EKS Anywhere) disposant de sa propre distribution Kubernetes testée et bénéficiant du soutien d’experts Kubernetes. Cela vous permet de vous décharger d’une grande partie des tâches fastidieuses et répétitives nécessaires à la maintenance de vos clusters, notamment :
-
Matériel : si vous ne disposez pas de matériel pour exécuter Kubernetes selon vos besoins, un fournisseur de cloud tel qu' AWS Amazon EKS peut vous faire économiser sur les coûts initiaux. Avec Amazon EKS, cela signifie que vous pouvez utiliser les meilleures ressources cloud proposées AWS, notamment les instances de calcul (Amazon Elastic Compute Cloud), votre propre environnement privé (Amazon VPC), la gestion centralisée des identités et des autorisations (IAM) et le stockage (Amazon EBS). AWS gère les ordinateurs, les réseaux, les centres de données et tous les autres composants physiques nécessaires au fonctionnement de Kubernetes. De même, vous n’avez pas besoin de planifier votre centre de données pour qu’il puisse gérer la capacité maximale lors des jours où la demande est la plus forte. Pour Amazon EKS Anywhere ou d'autres clusters Kubernetes sur site, vous êtes responsable de la gestion de l'infrastructure utilisée dans vos déploiements Kubernetes, mais vous pouvez toujours compter sur vous pour vous aider AWS à maintenir Kubernetes à jour.
-
Gestion du plan de contrôle : Amazon EKS gère la sécurité et la disponibilité du plan de contrôle Kubernetes AWS hébergé, qui est chargé de planifier les conteneurs, de gérer la disponibilité des applications et d'autres tâches clés, afin que vous puissiez vous concentrer sur les charges de travail de vos applications. Si votre cluster tombe en panne, vous AWS devriez avoir les moyens de rétablir son état de fonctionnement. Pour Amazon EKS Anywhere, vous devez gérer vous-même le plan de contrôle.
-
Mises à niveau testées : Lorsque vous mettez à niveau vos clusters, vous pouvez compter sur Amazon EKS ou Amazon EKS Anywhere pour fournir des versions testées de leurs distributions Kubernetes.
-
Add-ons— Il existe des centaines de projets conçus pour étendre Kubernetes et fonctionner avec Kubernetes. Vous pouvez les ajouter à l'infrastructure de votre cluster ou les utiliser pour faciliter l'exécution de vos charges de travail. Au lieu de créer et de gérer vous-même ces modules complémentaires AWS , Modules complémentaires Amazon EKS fournissez que vous pouvez utiliser avec vos clusters. Amazon EKS Anywhere propose des packages sélectionnés
qui incluent des versions de nombreux projets open source populaires. Vous n’avez donc pas à créer vous-même le logiciel ni à gérer les correctifs de sécurité critiques, les corrections de bogues ou les mises à niveau. De même, si les valeurs par défaut répondent à vos besoins, il est courant que très peu de configuration de ces modules complémentaires soient nécessaires. Consultez Extension des clusters pour plus de détails sur l’extension de votre cluster avec des modules complémentaires.
Kubernetes en action
Le diagramme suivant présente les principales activités que vous devrez réaliser en tant qu’administrateur Kubernetes ou développeur d’applications pour créer et utiliser un cluster Kubernetes. Ce faisant, il illustre comment les composants Kubernetes interagissent les uns avec les autres, en utilisant le AWS cloud comme exemple du fournisseur de cloud sous-jacent.
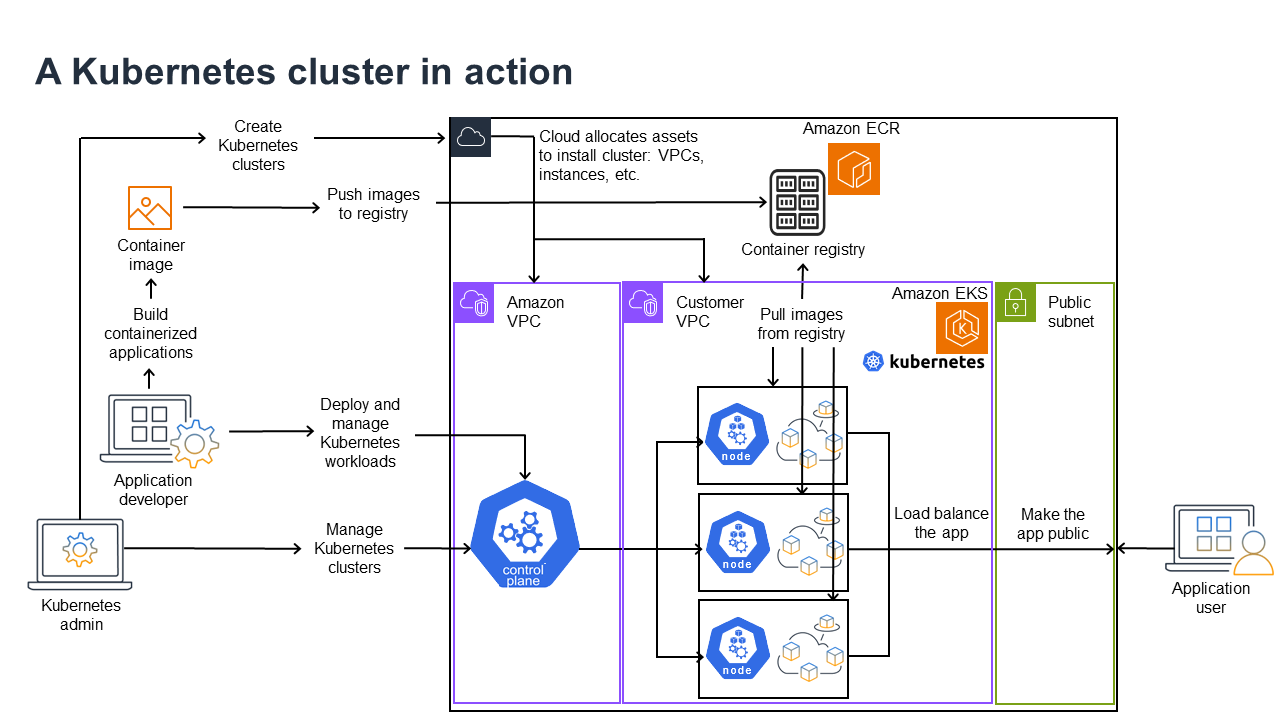
Un administrateur Kubernetes crée le cluster Kubernetes à l’aide d’un outil spécifique au type de fournisseur sur lequel le cluster sera construit. Cet exemple utilise le AWS cloud comme fournisseur, qui propose le service Kubernetes géré appelé Amazon EKS. Le service géré alloue automatiquement les ressources nécessaires à la création du cluster, notamment la création de deux nouveaux clouds privés virtuels (Amazon VPC) pour le cluster, la configuration du réseau et le mappage des autorisations Kubernetes directement dans les nouveaux VPC pour la gestion des actifs cloud. Le service géré veille également à ce que les services du plan de contrôle disposent d'emplacements où s'exécuter et n'alloue aucune instance Amazon EC2 ou plus en tant que nœuds Kubernetes pour exécuter les charges de travail. AWS gère lui-même un Amazon VPC pour le plan de contrôle, tandis que l'autre Amazon VPC contient les nœuds clients qui exécutent les charges de travail.
À l’avenir, la plupart des tâches de l’administrateur Kubernetes seront effectuées à l’aide d’outils Kubernetes tels que kubectl. Cet outil envoie les demandes de services directement au plan de contrôle du cluster. La manière dont les requêtes et les modifications sont apportées au cluster est alors très similaire à celle que vous utiliseriez sur n’importe quel cluster Kubernetes.
Un développeur d’applications souhaitant déployer des charges de travail sur ce cluster peut effectuer plusieurs tâches. Le développeur doit intégrer l'application dans une ou plusieurs images de conteneur, puis transférer ces images vers un registre de conteneurs accessible au cluster Kubernetes. AWS propose l'Amazon Elastic Container Registry (Amazon ECR) à cette fin.
Pour exécuter l'application, le développeur peut créer des fichiers de YAML-formatted configuration qui indiquent au cluster comment exécuter l'application, notamment les conteneurs à extraire du registre et comment les encapsuler dans des pods. Le plan de contrôle (planificateur) planifie les conteneurs sur un ou plusieurs nœuds et le moteur d’exécution des conteneurs sur chaque nœud extrait et exécute les conteneurs nécessaires. Le développeur peut également configurer un Application Load Balancer afin d’équilibrer le trafic vers les conteneurs disponibles s’exécutant sur chaque nœud et d’exposer l’application afin qu’elle soit accessible sur un réseau public depuis l’extérieur. Une fois tout cela fait, une personne souhaitant utiliser l’application peut se connecter au point de terminaison de l’application pour y accéder.
Les sections suivantes présentent en détail chacune de ces fonctionnalités, du point de vue des clusters et des charges de travail Kubernetes.
Clusters
Si votre travail consiste à démarrer et à gérer des clusters Kubernetes, vous devez savoir comment ces clusters sont créés, améliorés, gérés et supprimés. Vous devez également connaître les composants qui constituent un cluster et ce que vous devez faire pour les entretenir.
Les outils de gestion des clusters gèrent le chevauchement entre les services Kubernetes et le fournisseur de matériel sous-jacent. C'est pourquoi l'automatisation de ces tâches est généralement effectuée par le fournisseur Kubernetes (tel qu'Amazon EKS ou Amazon EKS Anywhere) à l'aide d'outils spécifiques au fournisseur. Par exemple, pour démarrer un cluster Amazon EKS, vous pouvez utiliser eksctl create cluster, tandis que pour Amazon EKS Anywhere, vous pouvez utiliser eksctl anywhere create cluster. Notez que, bien que ces commandes créent un cluster Kubernetes, elles sont spécifiques au fournisseur et ne font pas partie du projet Kubernetes lui-même.
Outils de création et de gestion de clusters
Le projet Kubernetes propose des outils permettant de créer manuellement un cluster Kubernetes. Si vous souhaitez installer Kubernetes sur une seule machine ou exécuter le plan de contrôle sur une machine et ajouter des nœuds manuellement, vous pouvez utiliser des outils CLI tels que kind
Dans AWS le cloud, vous pouvez créer des clusters Amazon EKS à l'aide d'outils CLI, tels que eksctl
-
Plan de contrôle géré :AWS garantit que le cluster Amazon EKS est disponible et évolutif, car il gère le plan de contrôle pour vous et le rend disponible dans toutes les zones de AWS disponibilité.
-
Gestion des nœuds : Au lieu d’ajouter manuellement des nœuds, vous pouvez demander à Amazon EKS de créer automatiquement des nœuds selon vos besoins, à l’aide de groupes de nœuds gérés (voir Simplifiez le cycle de vie des nœuds avec des groupes de nœuds gérés) ou de Karpenter
. Les groupes de nœuds gérés sont intégrés à Kubernetes Cluster Autoscaling. Grâce aux outils de gestion des nœuds, vous pouvez réaliser des économies, notamment grâce aux instances Spot et à la consolidation des nœuds, et bénéficier d’une disponibilité optimale, en utilisant les fonctionnalités Planification pour définir le déploiement des charges de travail et la sélection des nœuds. -
Mise en réseau de clusters : à l'aide de CloudFormation modèles,
eksctlconfigure la mise en réseau entre les composants du plan de contrôle et du plan de données (nœud) dans le cluster Kubernetes. Il met également en place des points d’accès permettant les communications internes et externes. Consultez la section Mise en réseau de De-mystifying clusters pour les nœuds de travail Amazon EKSpour plus de détails. Les communications entre les pods dans Amazon EKS sont effectuées à l'aide d'Amazon EKS Pod Identities (voirDécouvrez comment EKS Pod Identity permet aux pods d'accéder à AWS services), qui permet aux Pods de tirer parti des méthodes AWS cloud de gestion des informations d'identification et des autorisations. -
Add-Ons— Amazon EKS vous évite d'avoir à créer et à ajouter des composants logiciels couramment utilisés pour prendre en charge les clusters Kubernetes. Par exemple, lorsque vous créez un cluster Amazon EKS à partir du AWS Management Console, il ajoute automatiquement les modules complémentaires Amazon EKS kube-proxy (Gérer le kube-proxy dans les clusters Amazon EKS), Amazon VPC CNI pour Kubernetes (Attribuer des adresses IP aux pods avec Amazon VPC CNI) et CoreDNS (). Gestion de CoreDNS pour DNS dans les clusters Amazon EKS Consultez Modules complémentaires Amazon EKS pour en savoir plus sur ces modules complémentaires, y compris la liste des modules disponibles.
Pour exécuter vos clusters sur vos propres ordinateurs et réseaux locaux, Amazon propose Amazon EKS Anywhere
Amazon EKS Anywhere est basé sur le même logiciel Amazon EKS Distroetcd plus loin dans ce document).
Composants d’un cluster
Les composants du cluster Kubernetes sont divisés en deux grandes catégories : le plan de contrôle et les composants master. Les composants du plan de contrôle
Plan de contrôle
Le plan de contrôle est constitué d’un ensemble de services qui gèrent le cluster. Ces services peuvent tous fonctionner sur un seul ordinateur ou être répartis sur plusieurs ordinateurs. En interne, elles sont appelées instances du plan de contrôle (CPI). Le fonctionnement des CPI dépend de la taille du cluster et des exigences en matière de haute disponibilité. À mesure que la demande augmente dans le cluster, un service de plan de contrôle peut évoluer pour fournir davantage d'instances de ce service, les demandes étant équilibrées entre les instances.
Les tâches effectuées par les composants du plan de contrôle Kubernetes incluent :
-
Communication avec les composants du cluster (serveur API) : Le serveur API (kube-apiserver
) expose l’API Kubernetes afin que les requêtes puissent être envoyées au cluster depuis l’intérieur et l’extérieur de celui-ci. En d’autres termes, les demandes d’ajout ou de modification des objets d’un cluster (Pods, Services, Nœuds, etc.) peuvent provenir de commandes externes, telles que les demandes d’exécution kubectlpour exécuter un Pod. De même, des requêtes peuvent être envoyées depuis le serveur API vers des composants au sein du cluster, comme une requête au servicekubeletpour connaître l’état d’un pod. -
Stocker les données relatives au cluster (stockage de valeurs clés
etcd) : Le serviceetcdjoue un rôle essentiel dans le suivi de l’état actuel du cluster. Si le serviceetcddevenait inaccessible, vous ne pourriez plus mettre à jour ou consulter l’état du cluster, mais les charges de travail continueraient à s’exécuter pendant un certain temps. Pour cette raison, les clusters critiques disposent généralement de plusieurs instances du serviceetcdfonctionnant simultanément avec équilibrage de charge et effectuent des sauvegardes périodiques du magasin de valeurs clésetcden cas de perte ou de corruption des données. N’oubliez pas que, dans Amazon EKS, tout cela est géré automatiquement par défaut. Amazon EKS Anywhere fournit des instructions pour la sauvegarde et la restauration d’etcd. Consultez le modèle de données etcd pour savoir comment etcdgère les données. -
Planifier des pods vers des nœuds (planificateur): Les demandes de démarrage ou d’arrêt d’un pod dans Kubernetes sont dirigées vers le planificateur Kubernetes
(kube-scheduler ). Étant donné qu’un cluster peut comporter plusieurs nœuds capables d’exécuter le pod, c’est au planificateur qu’il revient de choisir le ou les nœuds (dans le cas de réplicas) sur lesquels le pod doit s’exécuter. Si la capacité disponible est insuffisante pour exécuter le pod demandé sur un nœud existant, la demande échouera, sauf si vous avez pris d’autres dispositions. Ces dispositions pourraient inclure des services d’activation tels que Managed Node Groups (Simplifiez le cycle de vie des nœuds avec des groupes de nœuds gérés) ou Karpenter , capables de démarrer automatiquement de nouveaux nœuds pour gérer les charges de travail. -
Maintenir les composants dans l’état souhaité (Controller Manager) : Le Kubernetes Controller Manager s’exécute en tant que processus démon (kube-controller-manager
) afin de surveiller l’état du cluster et d’apporter des modifications au cluster pour rétablir les états attendus. En particulier, plusieurs contrôleurs surveillent différents objets Kubernetes, notamment statefulset-controller,endpoint-controller,cronjob-controller,node-controller, et d’autres. -
Gérer les ressources cloud (Cloud Controller Manager) : Les interactions entre Kubernetes et le fournisseur de cloud qui traite les demandes relatives aux ressources du centre de données sous-jacent sont gérées par le Cloud Controller Manager
(cloud-controller-manager ). Les contrôleurs gérés par Cloud Controller Manager peuvent inclure un contrôleur de routage (pour configurer les routes du réseau cloud), un contrôleur de service (pour utiliser les services d’équilibrage de charge cloud) et un contrôleur de cycle de vie des nœuds (pour synchroniser les nœuds avec Kubernetes tout au long de leur cycle de vie).
Composant master (plan de données)
Pour un cluster Kubernetes à nœud unique, les charges de travail s’exécutent sur la même machine que le plan de contrôle. Cependant, une configuration plus standard consiste à disposer d’un ou plusieurs systèmes informatiques distincts (nœuds
Lorsque vous créez un cluster Kubernetes pour la première fois, certains outils de création de cluster vous permettent de configurer un certain nombre de nœuds à ajouter au cluster (soit en identifiant les systèmes informatiques existants, soit en demandant au fournisseur d’en créer de nouveaux). Avant d’ajouter des charges de travail à ces systèmes, des services sont ajoutés à chaque nœud afin de mettre en œuvre les fonctionnalités suivantes :
-
Gérer chaque nœud (
kubelet) : Le serveur API communique avec le service kubeletexécuté sur chaque nœud afin de s’assurer que le nœud est correctement enregistré et que les pods demandés par le planificateur sont en cours d’exécution. Le kubelet peut lire les manifestes des pods et configurer les volumes de stockage ou d’autres fonctionnalités nécessaires aux pods sur le système local. Il peut également vérifier l’état des conteneurs gérés localement. -
Exécuter des conteneurs sur un nœud (environnement d’exécution de conteneurs) : l’exécution de conteneurs
sur chaque nœud gère les conteneurs demandés pour chaque pod attribué au nœud. Cela signifie qu'il peut extraire les images du conteneur du registre approprié, exécuter le conteneur, l'arrêter et répondre aux requêtes concernant le conteneur. L’exécution de conteneur par défaut est containerd . À partir de Kubernetes 1.24, l’intégration spéciale de Docker ( dockershim) qui pouvait être utilisée comme exécution de conteneur a été supprimée de Kubernetes. Bien que vous puissiez toujours utiliser Docker pour tester et exécuter des conteneurs sur votre système local, pour utiliser Docker avec Kubernetes, vous devez désormais installer Docker Enginesur chaque nœud afin de pouvoir l’utiliser avec Kubernetes. -
Gérer la mise en réseau entre les conteneurs (
kube-proxy) : Afin de prendre en charge la communication entre les pods, Kubernetes utilise une fonctionnalité appelée Servicepour configurer des réseaux de pods qui suivent les adresses IP et les ports associés à ces pods. Le service kube-proxy s’exécute sur chaque nœud pour permettre la communication entre les pods.
Extension des clusters
Il existe certains services que vous pouvez ajouter à Kubernetes pour prendre en charge le cluster, mais qui ne sont pas exécutés dans le plan de contrôle. Ces services s’exécutent souvent directement sur des nœuds dans l’espace de noms kube-system ou dans leur propre espace de noms (comme c’est souvent le cas avec les fournisseurs de services tiers). Un exemple courant est le service CoreDNS, qui fournit des services DNS au cluster. Reportez-vous à la section Découverte des services intégrés
Il existe différents types de modules complémentaires que vous pouvez envisager d’ajouter à vos clusters. Pour maintenir vos clusters en bon état, vous pouvez ajouter des fonctionnalités d’observabilité (voir Surveillez les performances de votre cluster et consultez les journaux) qui vous permettent d’effectuer des tâches telles que la journalisation, l’audit et la mesure des métriques. Grâce à ces informations, vous pouvez résoudre les problèmes qui surviennent, souvent par le biais des mêmes interfaces d’observabilité. Des exemples de ces types de services incluent Amazon CloudWatch (voirSurveillez les données du cluster avec Amazon CloudWatch) GuardDuty, AWS Distro pour OpenTelemetry, le plugin Amazon VPC CNI pour
Pour une liste plus complète des modules complémentaires Amazon EKS disponibles, consultez Modules complémentaires Amazon EKS.
Charges de travail
Kubernetes définit une charge de travail
Containers
L’élément le plus basique d’une charge de travail d’application que vous déployez et gérez dans Kubernetes est un pod
Le Pod étant la plus petite unité déployable, il contient généralement un seul conteneur. Cependant, plusieurs conteneurs peuvent se trouver dans un pod dans les cas où les conteneurs sont étroitement couplés. Par exemple, un conteneur de serveur Web peut être intégré dans un pod avec un conteneur de type sidecar
Les spécifications du pod (PodSpec
Alors qu’un Pod est la plus petite unité que vous déployez, un conteneur est la plus petite unité que vous construisez et gérez.
Containers de construction
Le Pod n’est en réalité qu’une structure autour d’un ou plusieurs conteneurs, chaque conteneur contenant lui-même le système de fichiers, les exécutables, les fichiers de configuration, les bibliothèques et autres composants nécessaires au fonctionnement de l’application. Comme c’est une société appelée Docker Inc. qui a popularisé les conteneurs, certaines personnes les appellent « conteneurs Docker ». Cependant, la Open Container Initiative
Lorsque vous créez un conteneur, vous commencez généralement par un fichier Dockerfile (qui porte littéralement ce nom). Dans ce Dockerfile, vous identifiez :
-
Une image de base : Une image de conteneur de base est un conteneur généralement construit à partir d’une version minimale du système de fichiers d’un système d’exploitation (tel que Red Hat Enterprise Linux
ou Ubuntu ) ou d’un système minimal amélioré pour fournir des logiciels permettant d’exécuter des types d’applications spécifiques (telles que les applications nodejs ou python ). -
Logiciel d’application : Vous pouvez ajouter votre logiciel d’application à votre conteneur de la même manière que vous l’ajouteriez à un système Linux. Par exemple, dans votre fichier Dockerfile, vous pouvez exécuter
npmetyarnpour installer une application Java ouyumetdnfpour installer des paquets RPM. En d’autres termes, en utilisant une commande RUN dans un fichier Dockerfile, vous pouvez exécuter n’importe quelle commande disponible dans le système de fichiers de votre image de base pour installer ou configurer des logiciels à l’intérieur de l’image de conteneur résultante. -
Instructions : La référence Dockerfile
décrit les instructions que vous pouvez ajouter à un Dockerfile lorsque vous le configurez. Il s’agit notamment des instructions utilisées pour créer le contenu du conteneur lui-même (ou les fichiers ADDouCOPYdu système local), identifier les commandes à exécuter lorsque le conteneur est lancé (CMDouENTRYPOINT), et connecter le conteneur au système sur lequel il s’exécute (en identifiant leUSERsous lequel il doit s’exécuter, un localVOLUMEà monter ou les ports àEXPOSE).
Alors que la commande docker et le service ont traditionnellement été utilisés pour créer des conteneurs (docker build), d’autres outils sont disponibles pour créer des images de conteneurs, notamment podman
Conteneurs de stockage
Une fois votre image de conteneur créée, vous pouvez la stocker dans un registre de distribution
Pour stocker les images de conteneur de manière plus publique, vous pouvez les envoyer vers un registre de conteneurs public. Les registres publics de conteneurs fournissent un emplacement centralisé pour le stockage et la distribution des images de conteneurs. Parmi les exemples de registres de conteneurs publics, on peut citer le registre Amazon Elastic Container Registry
Lorsque vous exécutez des charges de travail conteneurisées sur Amazon Elastic Kubernetes Service (Amazon EKS), nous vous recommandons de récupérer des copies des images officielles Docker stockées dans Amazon Elastic Container Registry. Amazon ECR stocke ces images depuis 2021. Vous pouvez rechercher des images de conteneurs populaires dans la galerie publique Amazon ECR
Containers de course
Les conteneurs étant construits dans un format standard, ils peuvent fonctionner sur n’importe quelle machine capable d’exécuter une exécution de conteneur (tel que Docker) et dont le contenu correspond à l’architecture de la machine locale (telle que x86_64 ou arm). Pour tester un conteneur ou simplement l’exécuter sur votre bureau local, vous pouvez utiliser les commandes docker run ou podman run pour démarrer un conteneur sur l’hôte local. Pour Kubernetes, cependant, chaque composant master dispose d’une exécution de conteneur déployée et c’est à Kubernetes qu’il appartient de demander à un nœud d’exécuter un conteneur.
Une fois qu’un conteneur a été affecté à un nœud, celui-ci vérifie si la version demandée de l’image du conteneur existe déjà sur le nœud. Si ce n’est pas le cas, Kubernetes demande à l’exécution de conteneur de récupérer ce conteneur à partir du registre de conteneurs approprié, puis d’exécuter ce conteneur localement. Gardez à l’esprit qu’une image de conteneur fait référence au progiciel qui est transféré entre votre ordinateur portable, le registre de conteneurs et les nœuds Kubernetes. Un conteneur désigne une instance en cours d’exécution de cette image.
Capsules
Une fois vos conteneurs prêts, travailler avec les pods implique de les configurer, de les déployer et de les rendre accessibles.
Configuration des pods
Lorsque vous définissez un Pod, vous lui attribuez un ensemble d’attributs. Ces attributs doivent inclure au moins le nom du pod et l’image du conteneur à exécuter. Cependant, vous souhaitez également configurer de nombreux autres éléments avec les définitions de votre pod (consultez la PodSpec
-
Stockage : lorsqu’un conteneur en cours d’exécution est arrêté et supprimé, les stockages de données dans ce conteneur disparaissent, sauf si vous configurez un stockage plus permanent. Kubernetes prend en charge de nombreux types de stockage différents et les regroupe sous l’appellation Volumes
. Les types de stockage incluent CephFS , NFS ,iSCSI et autres. Vous pouvez même utiliser un périphérique de stockage en mode bloc à partir de l’ordinateur local. Avec l’un de ces types de stockage disponibles dans votre cluster, vous pouvez monter le volume de stockage sur un point de montage sélectionné dans le système de fichiers de votre conteneur. Un volume persistant est un volume qui continue d’exister après la suppression du pod, tandis qu’un volume éphémère est supprimé lorsque le pod est supprimé. Si votre administrateur de cluster a créé différentes classes de stockage pour votre cluster, vous pouvez choisir les attributs du stockage que vous utilisez, par exemple si le volume est supprimé ou récupéré après utilisation, s’il s’étend si davantage d’espace est nécessaire, et même s’il répond à certaines exigences de performances. -
Secrets — En mettant les secrets
à la disposition des conteneurs dans les spécifications du Pod, vous pouvez fournir les autorisations dont ces conteneurs ont besoin pour accéder aux systèmes de fichiers, aux bases de données ou à d'autres actifs protégés. Les clés, les mots de passe et les jetons font partie des éléments qui peuvent être stockés en tant que secrets. L’utilisation de secrets vous évite d’avoir à stocker ces informations dans des images de conteneur, mais vous devez simplement mettre les secrets à la disposition des conteneurs en cours d’exécution. Similaire à Secrets are ConfigMaps . Une ConfigMaptendance à contenir moins d’informations critiques, telles que les paires clé-valeur pour la configuration d’un service. -
Ressources de conteneur : Les objets permettant de configurer davantage les conteneurs peuvent prendre la forme d’une configuration de ressources. Pour chaque conteneur, vous pouvez demander la quantité de mémoire et de CPU qu’il peut utiliser, ainsi que fixer des limites quant à la quantité totale de ces ressources que le conteneur peut utiliser. Voir Gestion des ressources pour les pods et les conteneurs
pour des exemples. -
Interruptions : Les pods peuvent être perturbés involontairement (un nœud tombe en panne) ou volontairement (une mise à niveau est souhaitée). En configurant un budget de perturbation des pods
, vous pouvez exercer un certain contrôle sur la disponibilité de votre application en cas de perturbation. Consultez la section Spécification d’un budget de perturbation pour votre application pour obtenir des exemples. -
Espaces de noms : Kubernetes propose différentes méthodes pour isoler les composants et les charges de travail Kubernetes les uns des autres. L’exécution de tous les pods d’une application particulière dans le même espace de noms
est une méthode courante pour sécuriser et gérer ces pods ensemble. Vous pouvez créer vos propres espaces de noms à utiliser ou choisir de ne pas indiquer d’espace de noms (ce qui oblige Kubernetes à utiliser l’espace de noms default). Les composants du plan de contrôle Kubernetes s’exécutent généralement dans l’espace de noms kube-system.
La configuration qui vient d’être décrite est généralement regroupée dans un fichier YAML à appliquer au cluster Kubernetes. Pour les clusters Kubernetes personnels, vous pouvez simplement stocker ces fichiers YAML sur votre système local. Cependant, avec des clusters et des charges de travail plus critiques, GitOps
Les objets utilisés pour rassembler et déployer les informations Pod sont définis par l’une des méthodes de déploiement suivantes.
Déploiement de pods
La méthode que vous choisirez pour déployer des pods dépend du type d’application que vous prévoyez d’exécuter avec ces pods. Voici certains de vos choix :
-
Applications sans état : Une application sans état n’enregistre pas les données de session d’un client, de sorte qu’une autre session n’a pas besoin de se référer à ce qui s’est passé lors d’une session précédente. Cela permet de remplacer plus facilement les pods par de nouveaux s’ils deviennent insalubres ou de les déplacer sans enregistrer leur état. Si vous exécutez une application sans état (telle qu'un serveur Web), vous pouvez utiliser un déploiement
pour déployer des pods et ReplicaSets . A ReplicaSet définit le nombre d'instances d'un Pod que vous souhaitez exécuter simultanément. Bien que vous puissiez exécuter un pod ReplicaSet directement, il est courant d'exécuter des répliques directement dans un déploiement, afin de définir le nombre de répliques d'un pod à exécuter à la fois. -
Applications dynamiques : Une application avec état est une application dans laquelle l’identité du pod et l’ordre dans lequel les pods sont lancés sont importants. Ces applications ont besoin d’un stockage persistant stable qui doit être déployé et mis à l’échelle de manière cohérente. Pour déployer une application dynamique dans Kubernetes, vous pouvez utiliser. StatefulSets
Une base de données est un exemple d'application généralement exécutée en tant StatefulSet que. Dans un StatefulSet, vous pouvez définir les répliques, le Pod et ses conteneurs, les volumes de stockage à monter et les emplacements dans le conteneur où les données sont stockées. Voir Exécuter une application dynamique répliquée pour un exemple de déploiement d'une base de données en tant que. ReplicaSet -
Per-node applications — Il arrive que vous souhaitiez exécuter une application sur chaque nœud de votre cluster Kubernetes. Par exemple, votre centre de données peut exiger que chaque ordinateur exécute une application de surveillance ou un service d’accès à distance particulier. Pour Kubernetes, vous pouvez utiliser a DaemonSet
pour vous assurer que l'application sélectionnée s'exécute sur tous les nœuds de votre cluster. -
Les applications s’exécutent jusqu’à leur achèvement : Certaines applications doivent être exécutées pour accomplir une tâche particulière. Cela peut inclure un système qui publie des rapports d’état mensuels ou nettoie les anciennes données. Un objet Job
peut être utilisé pour configurer une application afin qu’elle démarre et s’exécute, puis se ferme une fois la tâche terminée. Un CronJob objet vous permet de configurer une application pour qu'elle s'exécute à une heure, une minute, un jour du mois, un mois ou un jour de la semaine spécifiques, en utilisant une structure définie par le format crontab Linux.
Rendre les applications accessibles depuis le réseau
Les applications étant souvent déployées sous la forme d'un ensemble de microservices qui se déplacent vers différents emplacements, Kubernetes avait besoin d'un moyen permettant à ces microservices de se retrouver entre eux. De plus, pour permettre à d’autres personnes d’accéder à une application en dehors du cluster Kubernetes, Kubernetes avait besoin d’un moyen d’exposer cette application sur des adresses et des ports externes. Ces fonctionnalités liées au réseau sont réalisées respectivement à l’aide d’objets Service et Ingress :
-
Services :Étant donné qu’un pod peut se déplacer vers différents nœuds et adresses, un autre pod qui doit communiquer avec le premier pod peut avoir des difficultés à le localiser. Pour résoudre ce problème, Kubernetes vous permet de représenter une application en tant que Service.
Avec un service, vous pouvez identifier un pod ou un ensemble de pods avec un nom particulier, puis indiquer quel port expose le service de cette application à partir du pod et quels ports une autre application pourrait utiliser pour contacter ce service. Un autre pod au sein d’un cluster peut simplement demander un service par son nom, et Kubernetes dirigera cette demande vers le port approprié pour une instance du pod exécutant ce service. -
Ingress : Ingress
permet de mettre les applications représentées par les services Kubernetes à la disposition des clients situés en dehors du cluster. Les fonctionnalités de base d’Ingress comprennent un équilibreur de charge (géré par Ingress), le contrôleur Ingress et des règles pour acheminer les requêtes du contrôleur vers le service. Il existe plusieurs contrôleurs Ingress parmi lesquels vous pouvez choisir avec Kubernetes.
Étapes suivantes
Comprendre les concepts de base de Kubernetes et leur relation avec Amazon EKS vous aidera à naviguer dans la documentation Amazon EKS et Kubernetes
