Aidez à améliorer cette page
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Pour contribuer à ce guide de l'utilisateur, cliquez sur le GitHub lien Modifier cette page sur qui se trouve dans le volet droit de chaque page.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Concepts Kubernetes pour les nœuds hybrides
Cette page détaille les concepts clés de Kubernetes qui sous-tendent l’architecture système des nœuds hybrides EKS.
Plan de contrôle EKS dans le VPC
Les adresses IP des ENI du plan de contrôle EKS sont stockées dans l’objet kubernetes Endpoints dans l’espace de noms default. Lorsque EKS crée de nouveaux ENI ou supprime les anciens, EKS met à jour cet objet afin que la liste des adresses IP soit toujours à jour.
Vous pouvez utiliser ces points de terminaison via le service kubernetes, également dans l’espace de noms default. Ce service, de type ClusterIP, se voit toujours attribuer la première adresse IP du CIDR du service du cluster. Par exemple, pour le service CIDR 172.16.0.0/16, l’adresse IP du service sera 172.16.0.1.
En général, c’est ainsi que les pods (qu’ils fonctionnent dans le cloud ou sur des nœuds hybrides) accèdent au serveur API EKS Kubernetes. Les pods utilisent l’adresse IP du service comme adresse IP de destination, qui est traduite en adresses IP réelles de l’une des ENI du plan de contrôle EKS. La principale exception est kube-proxy, car elle configure la traduction.
point de terminaison de serveur d’API E
L’adresse IP du service kubernetes n’est pas le seul moyen d’accéder au serveur API EKS. EKS crée également un nom DNS Route53 lorsque vous créez votre cluster. Il s’agit du champ endpoint de votre cluster EKS lorsque vous appelez l’action API DescribeCluster EKS.
{ "cluster": { "endpoint": "https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com", "name": "my-cluster", "status": "ACTIVE" } }
Dans un cluster d’accès aux points de terminaison publics ou d’accès aux points de terminaison publics et privés, vos nœuds hybrides résoudront ce nom DNS en une adresse IP publique par défaut, routable via Internet. Dans un cluster d’accès aux points de terminaison privés, le nom DNS est résolu en adresses IP privées des ENI du plan de contrôle EKS.
Voici comment le kubelet et kube-proxy accèdent au serveur API Kubernetes. Si vous souhaitez que tout le trafic de votre cluster Kubernetes passe par le VPC, vous devez soit configurer votre cluster en mode d’accès privé, soit modifier votre serveur DNS sur site afin de résoudre le point de terminaison du cluster EKS vers les adresses IP privées des ENI du plan de contrôle EKS.
Point de terminaison kubelet
Le kubelet expose plusieurs points de terminaison REST, permettant à d’autres parties du système d’interagir avec chaque nœud et d’y recueillir des informations. Dans la plupart des clusters, la majorité du trafic vers le serveur kubelet provient du plan de contrôle, mais certains agents de surveillance peuvent également interagir avec lui.
Grâce à cette interface, le kubelet gère diverses requêtes : récupération des journaux (kubectl logs), exécution de commandes à l’intérieur des conteneurs (kubectl exec) et redirection du trafic (kubectl port-forward). Chacune de ces requêtes interagit avec l’exécution de conteneur sous-jacent via kubelet, ce qui semble transparent pour les administrateurs de cluster et les développeurs.
Le serveur d’API Kubernetes est le serveur d’API Kubernetes. Lorsque vous utilisez l’une des commandes kubectl mentionnées précédemment, kubectl envoie une requête API au serveur API, qui appelle ensuite l’API kubelet du nœud sur lequel le pod est exécuté. C’est la principale raison pour laquelle l’adresse IP du nœud doit être accessible depuis le plan de contrôle EKS et pourquoi, même si vos pods sont en cours d’exécution, vous ne pourrez pas accéder à leurs journaux ou à exec si la route du nœud est mal configurée.
IP des nœuds
Lorsque le plan de contrôle EKS communique avec un nœud, il utilise l’une des adresses indiquées dans l’état de l’objet Node (status.addresses).
Avec les nœuds cloud EKS, il est courant que le kubelet signale l’adresse IP privée de l’instance EC2 comme une InternalIP lors de l’enregistrement du nœud. Cette adresse IP est ensuite validée par le Cloud Controller Manager (CCM) qui s’assure qu’elle appartient bien à l’instance EC2. De plus, le CCM ajoute généralement les adresses IP publiques (comme ExternalIP) et les noms DNS (InternalDNS et ExternalDNS) de l’instance au statut du nœud.
Cependant, il n’existe pas de CCM pour les nœuds hybrides. Lorsque vous enregistrez un nœud hybride avec la CLI des nœuds hybrides EKS (nodeadm), celle-ci configure le kubelet pour qu’il signale l’adresse IP de votre machine directement dans l’état du nœud, sans passer par le CCM.
apiVersion: v1 kind: Node metadata: name: my-node-1 spec: providerID: eks-hybrid:///us-west-2/my-cluster/my-node-1 status: addresses: - address: 10.1.1.236 type: InternalIP - address: my-node-1 type: Hostname
Si votre machine dispose de plusieurs adresses IP, le kubelet en sélectionnera une selon sa propre logique. Vous pouvez contrôler l’adresse IP sélectionnée à l’aide du drapeau --node-ip, que vous pouvez passer dans la configuration nodeadm dans spec.kubelet.flags. Seule l’adresse IP indiquée dans l’objet Node nécessite une route depuis le VPC. Vos machines peuvent avoir d’autres adresses IP qui ne sont pas accessibles depuis le cloud.
kube-proxy
kube-proxy est responsable de la mise en œuvre de l’abstraction du service au niveau de la couche réseau de chaque nœud. Il agit comme un proxy réseau et un équilibreur de charge pour le trafic destiné aux services Kubernetes. En surveillant en permanence le serveur API Kubernetes pour détecter les changements liés aux services et aux points de terminaison, kube-proxy met à jour de manière dynamique les règles de réseau de l’hôte sous-jacent afin de garantir que le trafic est correctement acheminé.
En mode iptables, kube-proxy programme plusieurs chaînes netfilter pour gérer le trafic de service. Les règles forment la hiérarchie suivante :
-
Chaîne KUBE-SERVICES : point d’entrée pour tout le trafic de services. Il comporte des règles correspondant à chaque
ClusterIPet port du service. -
Chaînes KUBE-SVC-XXX : les chaînes spécifiques à un service disposent de règles d’équilibrage de charge pour chaque service.
-
Chaînes KUBE-SEP-XXX : les chaînes spécifiques aux points de terminaison contiennent les règles
DNATeffectives.
Examinons ce qui se passe pour un service test-server dans l’espace de noms default : * Service ClusterIP : 172.16.31.14 * Port du service : 80 * Pods de sauvegarde : 10.2.0.110, 10.2.1.39, et 10.2.2.254
Lorsque nous inspectons les règles iptables (à l’aide de iptables-save –0— grep -A10 KUBE-SERVICES) :
-
Dans la chaîne KUBE-SERVICES, nous trouvons une règle correspondant au service :
-A KUBE-SERVICES -d 172.16.31.14/32 -p tcp -m comment --comment "default/test-server cluster IP" -m tcp --dport 80 -j KUBE-SVC-XYZABC123456-
Cette règle correspond aux paquets destinés à 172.16.31.14:80
-
Le commentaire indique à quoi sert cette règle :
default/test-server cluster IP -
Les paquets correspondants passent à la chaîne
KUBE-SVC-XYZABC123456
-
-
La chaîne KUBE-SVC-XYZABC123456 dispose de règles d’équilibrage de charge basées sur la probabilité :
-A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-POD1XYZABC -A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-POD2XYZABC -A KUBE-SVC-XYZABC123456 -j KUBE-SEP-POD3XYZABC-
Première règle : 33,3 % de chances de passer à
KUBE-SEP-POD1XYZABC -
Deuxième règle : 50 % de chances que le trafic restant (33,3 % du total) passe à
KUBE-SEP-POD2XYZABC -
Dernière règle : tout le trafic restant (33,3 % du total) passe à
KUBE-SEP-POD3XYZABC
-
-
Les chaînes KUBE-SEP-XXX individuelles exécutent le DNAT (Destination NAT) :
-A KUBE-SEP-POD1XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.0.110:80 -A KUBE-SEP-POD2XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.1.39:80 -A KUBE-SEP-POD3XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.2.254:80-
Ces règles DNAT réécrivent l’adresse IP et le port de destination afin de diriger le trafic vers des pods spécifiques.
-
Chaque règle gère environ 33,3 % du trafic, assurant ainsi un équilibrage de charge uniforme entre
10.2.0.110,10.2.1.39et10.2.2.254.
-
Cette structure en chaîne à plusieurs niveaux permet à kube-proxy de mettre en œuvre efficacement l’équilibrage de charge et la redirection des services grâce à la manipulation des paquets au niveau du noyau, sans nécessiter de processus proxy dans le chemin de données.
Impact sur les opérations Kubernetes
Une kube-proxy rompu sur un nœud empêche ce dernier d’acheminer correctement le trafic du service, ce qui entraîne des délais d’attente ou des échecs de connexion pour les pods qui dépendent des services du cluster. Cela peut être particulièrement perturbant lors de la première inscription d’un nœud. Le CNI doit communiquer avec le serveur API Kubernetes pour obtenir des informations, telles que le CIDR du pod du nœud, avant de pouvoir configurer le réseau des pods. Pour ce faire, il utilise l’adresse IP du service kubernetes. Cependant, si kube-proxy n’a pas pu démarrer ou n’a pas réussi à définir les règles iptables appropriées, les requêtes envoyées à l’adresse IP du service kubernetes ne sont pas traduites en adresses IP réelles des ENI du plan de contrôle EKS. En conséquence, le CNI entrera dans une boucle de crash et aucun des pods ne pourra fonctionner correctement.
Nous savons que les pods utilisent l’adresse IP kubernetes du service pour communiquer avec le serveur API Kubernetes, mais il faut d’abord que kube-proxy définisse des règles iptables pour que cela fonctionne.
Comment kube-proxy communique-t-il avec le serveur API ?
Le kube-proxy doit être configuré pour utiliser les adresses IP réelles du serveur API Kubernetes ou un nom DNS qui les résout. Dans le cas d’EKS, EKS configure la valeur kube-proxy par défaut pour pointer vers le nom DNS Route53 créé par EKS lors de la création du cluster. Vous pouvez voir cette valeur dans le kube-proxy ConfigMap dans l’espace de noms kube-system. Le contenu de ce ConfigMap est un kubeconfig qui est injecté dans le pod kube-proxy, recherchez donc le champ clusters–0—.cluster.server. Cette valeur correspondra au champ endpoint de votre cluster EKS (lorsque vous appelez l’API DescribeCluster EKS).
apiVersion: v1 data: kubeconfig: |- kind: Config apiVersion: v1 clusters: - cluster: certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt server: https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com name: default contexts: - context: cluster: default namespace: default user: default name: default current-context: default users: - name: default user: tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token kind: ConfigMap metadata: name: kube-proxy namespace: kube-system
CIDR de pods distants routables
Cette page Concepts de mise en réseau pour les nœuds hybrides détaille les conditions requises pour exécuter des webhooks sur des nœuds hybrides ou pour que les pods exécutés sur des nœuds cloud communiquent avec les pods exécutés sur des nœuds hybrides. La condition essentielle est que le routeur sur site doit savoir quel nœud est responsable d’une adresse IP de pod particulière. Il existe plusieurs façons d’y parvenir, notamment le protocole de passerelle frontière (BGP), les routes statiques et le proxy ARP (Address Resolution Protocol). Ces points sont abordés dans les sections suivantes.
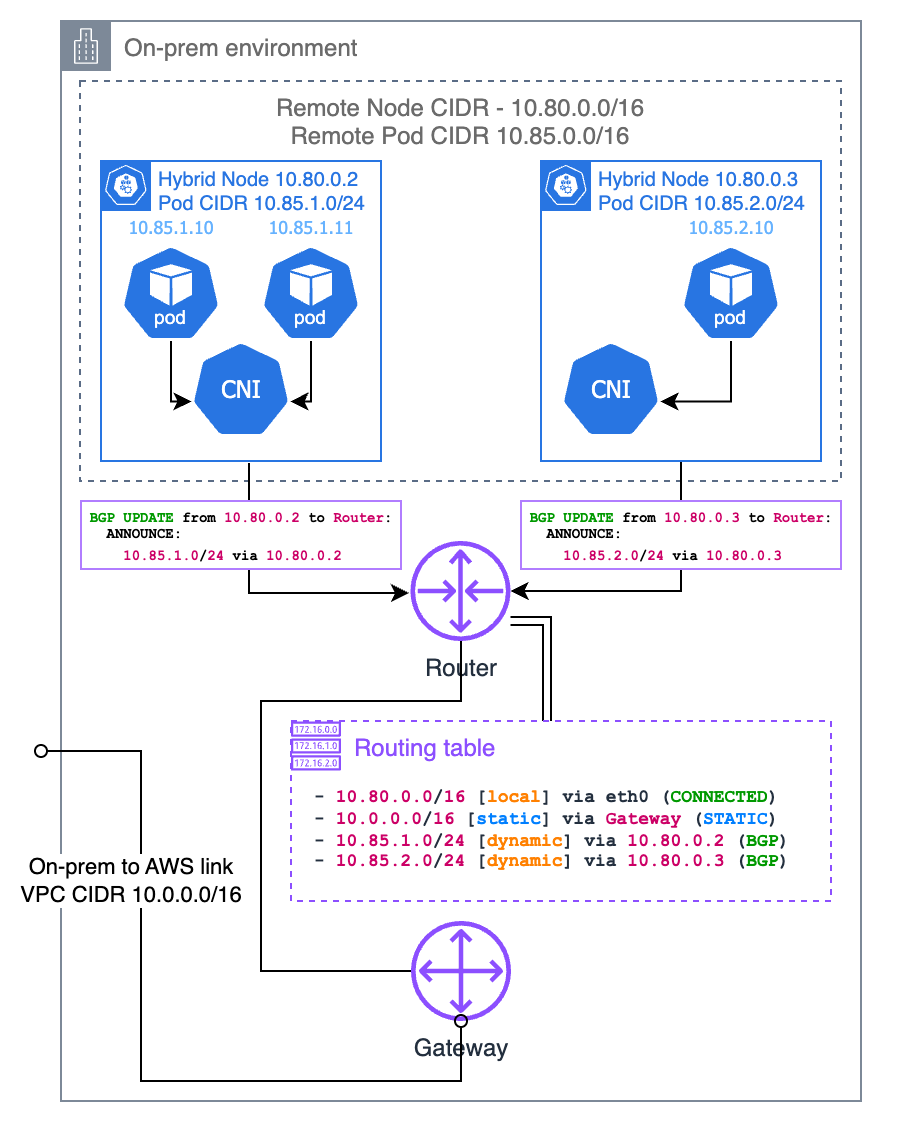
Protocole de passerelle frontière (BGP)
Si votre CNI le prend en charge (comme Cilium et Calico), vous pouvez utiliser le mode BGP de votre CNI pour propager les routes vers vos CIDR de pod par nœud depuis vos nœuds vers votre routeur local. Lorsque vous utilisez le mode BGP du CNI, votre CNI agit comme un routeur virtuel, de sorte que votre routeur local considère que le CIDR du pod appartient à un sous-réseau différent et que votre nœud est la passerelle vers ce sous-réseau.
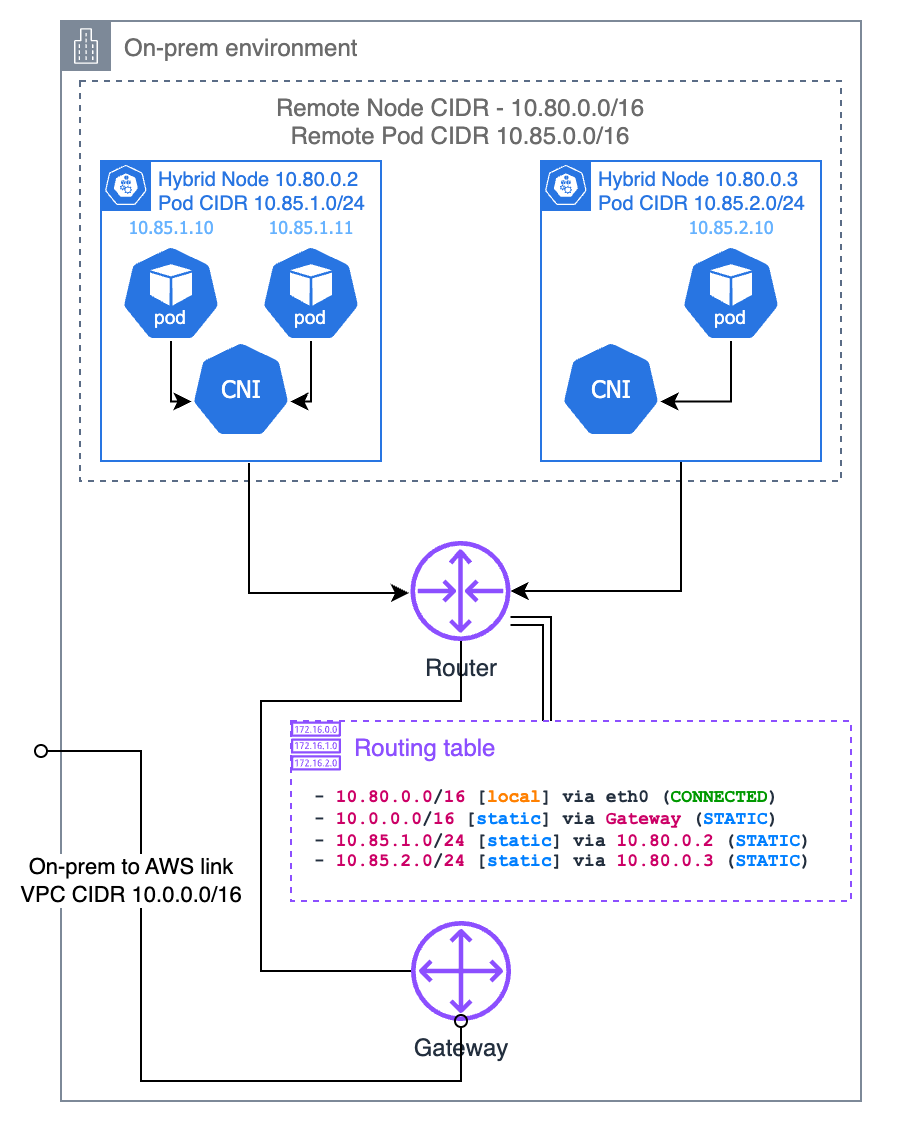
Routes statiques
Vous pouvez également configurer des routes statiques dans votre routeur local. Il s’agit de la méthode la plus simple pour acheminer le CIDR du pod sur site vers votre VPC, mais c’est aussi la plus sujette aux erreurs et la plus difficile à maintenir. Vous devez vous assurer que les routes sont toujours à jour avec les nœuds existants et leurs CIDR de pod attribués. Si votre nombre de nœuds est faible et que votre infrastructure est statique, cette option est viable et élimine le besoin d’une prise en charge BGP dans votre routeur. Si vous optez pour cette solution, nous vous recommandons de configurer votre CNI avec la tranche CIDR du pod que vous souhaitez attribuer à chaque nœud, plutôt que de laisser son IPAM décider.
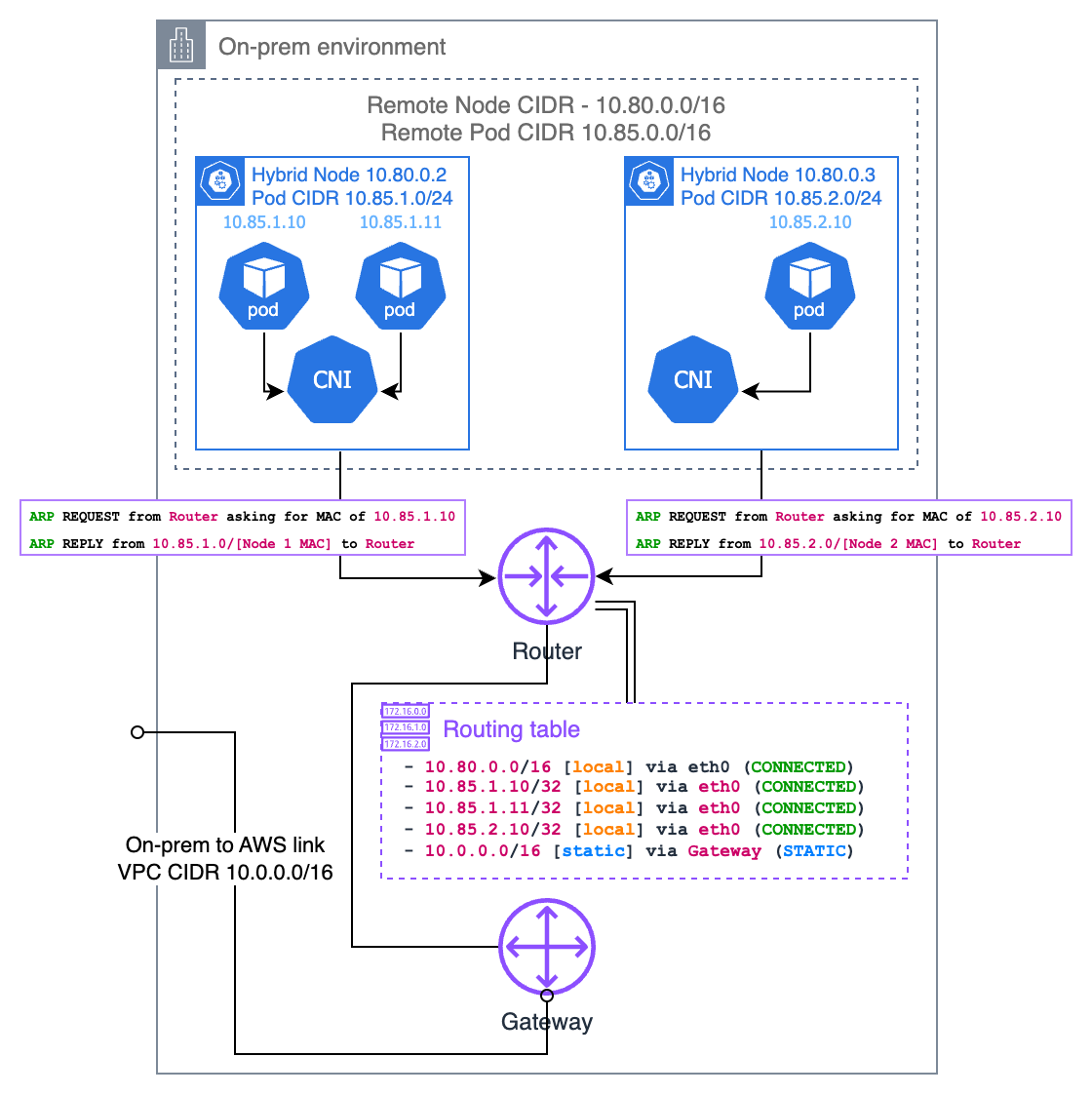
Proxy ARP (Address Resolution Protocol)
Le proxy ARP est une autre approche permettant de rendre routables les adresses IP des pods sur site, particulièrement utile lorsque vos nœuds hybrides se trouvent sur le même réseau de couche 2 que votre routeur local. Lorsque le proxy ARP est activé, un nœud répond aux requêtes ARP pour les adresses IP des pods qu’il héberge, même si ces adresses IP appartiennent à un sous-réseau différent.
Lorsqu’un appareil de votre réseau local tente d’atteindre une adresse IP de pod, il envoie d’abord une requête ARP demandant « Qui possède cette adresse IP ? ». Le nœud hybride hébergeant ce pod répondra avec sa propre adresse MAC, indiquant « Je peux gérer le trafic pour cette adresse IP ». Cela crée un chemin direct entre les appareils de votre réseau local et les pods sans nécessiter de configuration du routeur.
Pour que cela fonctionne, votre CNI doit prendre en charge la fonctionnalité ARP proxy. Cilium dispose d’un support intégré pour le proxy ARP que vous pouvez activer via la configuration. Le point essentiel à prendre en compte est que le CIDR du pod ne doit pas chevaucher aucun autre réseau de votre environnement, car cela pourrait entraîner des conflits de routage.
Cette approche présente plusieurs avantages : * Pas besoin de configurer votre routeur avec BGP ou de maintenir des routes statiques * Fonctionne bien dans les environnements où vous n’avez pas le contrôle sur la configuration de votre routeur
Encapsulation de pod à pod
Dans les environnements sur site, les CNI utilisent généralement des protocoles d’encapsulation pour créer des réseaux superposés qui peuvent fonctionner au-dessus du réseau physique sans qu’il soit nécessaire de le reconfigurer. Cette section explique comment fonctionne cette encapsulation. Veuillez noter que certains détails peuvent varier en fonction du CNI que vous utilisez.
L’encapsulation consiste à envelopper les paquets réseau du pod d’origine dans un autre paquet réseau qui peut être acheminé via le réseau physique sous-jacent. Cela permet aux pods de communiquer entre les nœuds exécutant le même CNI sans que le réseau physique ait besoin de savoir comment acheminer ces CIDR de pod.
Le protocole d’encapsulation le plus couramment utilisé avec Kubernetes est le Virtual Extensible LAN (VXLAN), mais d’autres protocoles (tels que Geneve) sont également disponibles en fonction de votre CNI.
Encapsulation VXLAN
VXLAN encapsule les trames Ethernet de couche 2 dans des paquets UDP. Lorsqu’un pod envoie du trafic à un autre pod sur un nœud différent, le CNI effectue les opérations suivantes :
-
Le CNI intercepte les paquets provenant du Pod A.
-
Le CNI encapsule le paquet d’origine dans un en-tête VXLAN.
-
Ce paquet encapsulé est ensuite envoyé via la pile réseau standard du nœud vers le nœud de destination.
-
Le CNI sur le nœud de destination déballe le paquet et le transmet au Pod B
Voici ce qui arrive à la structure du paquet lors de l’encapsulation VXLAN :
Paquet original de pod à pod :
+-----------------+---------------+-------------+-----------------+ | Ethernet Header | IP Header | TCP/UDP | Payload | | Src: Pod A MAC | Src: Pod A IP | Src Port | | | Dst: Pod B MAC | Dst: Pod B IP | Dst Port | | +-----------------+---------------+-------------+-----------------+
Après l’encapsulation VXLAN :
+-----------------+-------------+--------------+------------+---------------------------+ | Outer Ethernet | Outer IP | Outer UDP | VXLAN | Original Pod-to-Pod | | Src: Node A MAC | Src: Node A | Src: Random | VNI: xx | Packet (unchanged | | Dst: Node B MAC | Dst: Node B | Dst: 4789 | | from above) | +-----------------+-------------+--------------+------------+---------------------------+
L’identifiant réseau VXLAN (VNI) permet de distinguer les différents réseaux superposés.
Scénarios de communication de pod
Pods sur le même nœud hybride
Lorsque des pods sur le même nœud hybride communiquent, aucune encapsulation n’est généralement nécessaire. Le CNI configure des routes locales qui dirigent le trafic entre les pods via les interfaces virtuelles internes du nœud :
Pod A -> veth0 -> node's bridge/routing table -> veth1 -> Pod B
Le paquet ne quitte jamais le nœud et ne nécessite pas d’encapsulation.
Pods sur différents nœuds hybrides
La communication entre les pods sur différents nœuds hybrides nécessite une encapsulation :
Pod A -> CNI -> [VXLAN encapsulation] -> Node A network -> router or gateway -> Node B network -> [VXLAN decapsulation] -> CNI -> Pod B
Cela permet au trafic des pods de traverser l’infrastructure réseau physique sans que celle-ci ait besoin de comprendre le routage IP des pods.
