Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Plan de contrôle Kubernetes
Astuce
Découvrez les
Le plan de contrôle Kubernetes comprend le serveur d'API Kubernetes, le Kubernetes Controller Manager, le planificateur et d'autres composants nécessaires au fonctionnement de Kubernetes. Les limites d'évolutivité de ces composants varient en fonction de ce que vous exécutez dans le cluster, mais les domaines ayant le plus d'impact sur le dimensionnement sont la version de Kubernetes, l'utilisation et le dimensionnement des nœuds individuels.
Vous pouvez exécuter le plan de contrôle de votre cluster dans l'un des deux modes suivants pour répondre aux différentes exigences de charge de travail :
-
Mode standard : par défaut, tous les clusters EKS utilisent le mode standard. Le plan de contrôle s'adapte automatiquement à la hausse ou à la baisse en fonction des exigences de votre charge de travail. Le mode standard alloue dynamiquement une capacité suffisante au plan de contrôle et constitue l'option recommandée dans la plupart des cas d'utilisation.
-
Mode provisionné : si vos charges de travail ne peuvent tolérer la variabilité des performances due à la mise à l'échelle du plan de contrôle, ou si elles nécessitent une capacité de plan de contrôle très élevée, vous pouvez utiliser le mode provisionné. Avec le mode provisionné, vous préallouez la capacité du plan de contrôle qui est toujours prête à répondre aux exigences les plus exigeantes. Vous bénéficiez de performances constantes et prévisibles.
Avec le mode EKS Provisioned, vous pouvez choisir parmi un ensemble de niveaux de dimensionnement (XL, 2XL, 4XL et 8XL). À chaque niveau, vous bénéficiez de performances élevées et prévisibles depuis le plan de contrôle du cluster. Le mode provisionné est particulièrement utile dans les cas d'utilisation suivants :
-
Performance-critical charges de travail
-
Large-scale Opérations d'IA et d'apprentissage automatique
-
Évènements à forte demande prévus
-
Environnements nécessitant une cohérence entre le stade de préparation et la production
Avec le mode provisionné, vous pouvez préallouer la capacité du plan de contrôle à l'avance et bénéficier d'un accord de niveau de service (SLA) amélioré à 99,99 % mesuré à intervalles d'une minute. Pour plus d'informations sur le mode EKS Provisioned, y compris les spécifications des niveaux et la tarification, voir EKS Provisioned Control Plane dans le guide de l'utilisateur EKS.
Limitez la charge de travail et l'éclatement des nœuds
Important
Pour éviter d'atteindre les limites d'API sur le plan de contrôle, vous devez limiter les pics de dimensionnement qui augmentent la taille du cluster de pourcentages à deux chiffres à la fois (par exemple, de 1 000 nœuds à 1 100 nœuds ou de 4 000 à 4 500 pods à la fois).
Le plan de contrôle EKS s'adapte automatiquement à la croissance de votre cluster, mais sa rapidité d'évolution est limitée. Lorsque vous créez un cluster EKS pour la première fois, le plan de contrôle ne pourra pas immédiatement s'adapter à des centaines de nœuds ou à des milliers de pods. Pour en savoir plus sur les améliorations apportées par EKS à la mise à l'échelle, consultez ce billet de blog
La mise à l'échelle d'applications de grande envergure nécessite l'adaptation de l'infrastructure pour être totalement prête (par exemple, des équilibreurs de charge de chauffage). Pour contrôler la vitesse de mise à l'échelle, assurez-vous que vous effectuez la mise à l'échelle en fonction des indicateurs adaptés à votre application. La mise à l'échelle du processeur et de la mémoire peut ne pas prédire avec précision les contraintes de votre application et l'utilisation de métriques personnalisées (par exemple, les demandes par seconde) dans Kubernetes Horizontal Pod Autoscaler (HPA) peut être une meilleure option de dimensionnement.
Pour utiliser une métrique personnalisée, consultez les exemples de la documentation Kubernetes
Diminuez les nœuds et les pods en toute sécurité
Remplacez les instances de longue durée
Le remplacement régulier des nœuds permet de préserver la santé de votre cluster en évitant les dérives de configuration et les problèmes qui ne surviennent qu'après une disponibilité prolongée (par exemple, des fuites de mémoire lentes). Le remplacement automatique vous fournira de bons processus et de bonnes pratiques pour les mises à niveau des nœuds et les correctifs de sécurité. Si chaque nœud de votre cluster est remplacé régulièrement, il est moins difficile de maintenir des processus distincts pour une maintenance continue.
Utilisez les paramètres TTL (time to live) de Karpenter pour remplacer les instances après leur exécution pendant un certain temps. Les groupes de nœuds autogérés peuvent utiliser ce max-instance-lifetime paramètre pour faire tourner les nœuds automatiquement. Les groupes de nœuds gérés ne disposent pas actuellement de cette fonctionnalité, mais vous pouvez suivre la demande ici GitHub
Supprimer les nœuds sous-utilisés
Vous pouvez supprimer des nœuds lorsqu'aucune charge de travail n'est en cours d'exécution en utilisant le seuil de réduction dans le Kubernetes Cluster Autoscaler avec le paramètre --scale-down-utilization-thresholdttlSecondsAfterEmpty
Utilisez les budgets d'interruption de service et la fermeture sécurisée des nœuds
La suppression des pods et des nœuds d'un cluster Kubernetes nécessite que les contrôleurs mettent à jour plusieurs ressources (par exemple). EndpointSlices Si vous le faites fréquemment ou trop rapidement, vous risquez de ralentir le serveur d'API et d'interrompre les applications lorsque les modifications se propagent aux contrôleurs. Les budgets d'interruption des
Utiliser Client-Side le cache lors de l'exécution de Kubectl
L'utilisation inefficace de la commande kubectl peut ajouter une charge supplémentaire au serveur d'API Kubernetes. Vous devez éviter d'exécuter des scripts ou des automatismes qui utilisent kubectl de manière répétée (par exemple dans une boucle for) ou d'exécuter des commandes sans cache local.
kubectlpossède un cache côté client qui met en cache les informations de découverte provenant du cluster afin de réduire le nombre d'appels d'API requis. Le cache est activé par défaut et est actualisé toutes les 10 minutes.
Si vous exécutez kubectl à partir d'un conteneur ou sans cache côté client, vous risquez de rencontrer des problèmes de limitation de l'API. Il est recommandé de conserver le cache de votre cluster en le montant afin --cache-dir d'éviter d'effectuer des appels d'API inutiles.
Désactiver la compression kubectl
La désactivation de la compression kubectl dans votre fichier kubeconfig peut réduire l'utilisation de l'API et du processeur client. Par défaut, le serveur compresse les données envoyées au client afin d'optimiser la bande passante du réseau. Cela augmente la charge du processeur sur le client et le serveur pour chaque demande et la désactivation de la compression peut réduire le surdébit et la latence si vous disposez d'une bande passante suffisante. Pour désactiver la compression, vous pouvez utiliser le --disable-compression=true drapeau ou le définir disable-compression: true dans votre fichier kubeconfig.
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
Autoscaler Shard Cluster
Le Kubernetes Cluster Autoscaler a été testé pour atteindre 1
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
Priorité et équité de l'API
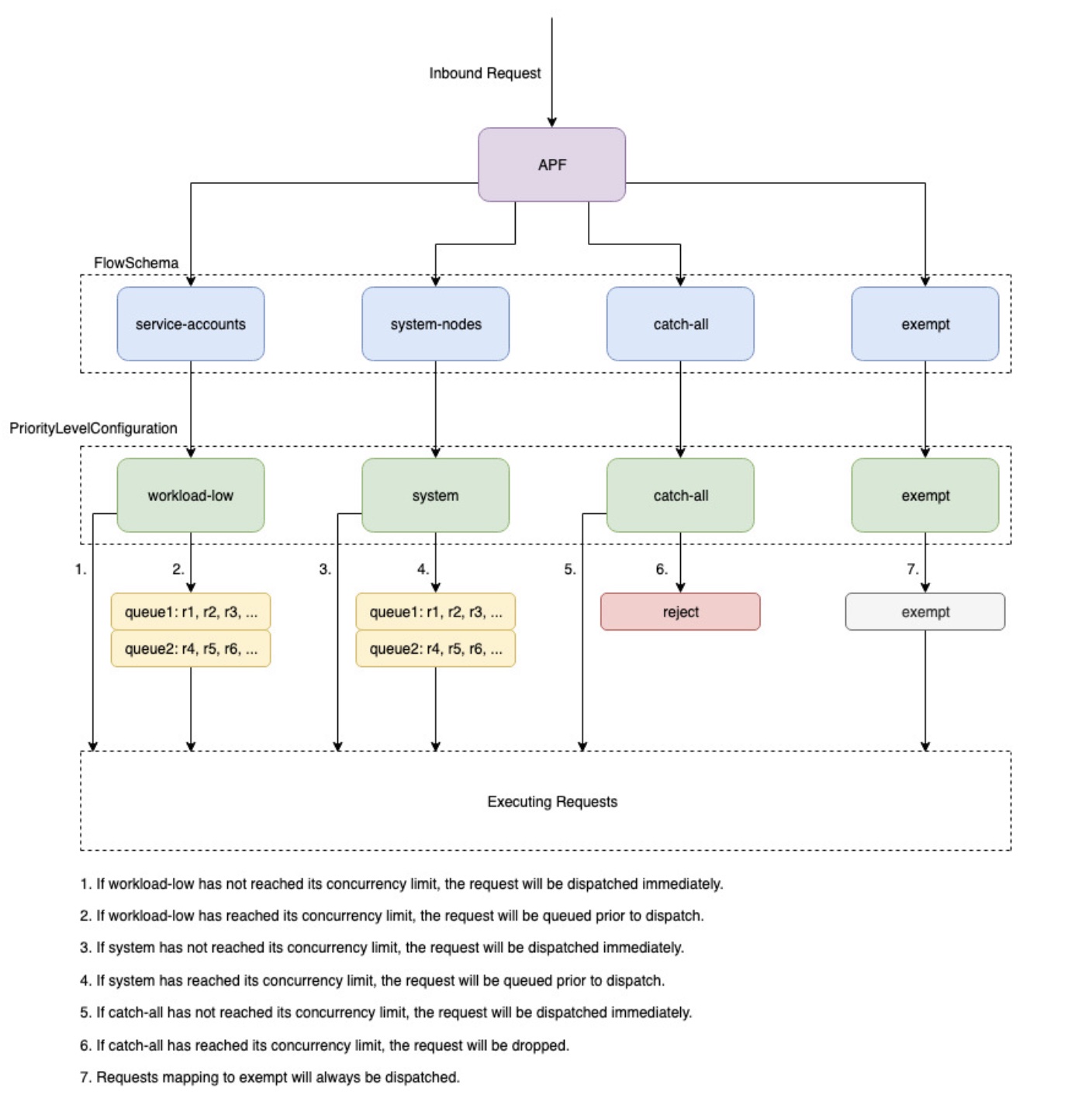
Présentation de
Pour éviter d'être surchargé pendant les périodes d'augmentation des demandes, le serveur API limite le nombre de demandes en cours de vol qu'il peut avoir en suspens à un moment donné. Une fois cette limite dépassée, le serveur API commence à rejeter les demandes et renvoie aux clients un code de réponse HTTP 429 pour « trop de demandes ». Il est préférable que le serveur abandonne les demandes et demande aux clients de réessayer ultérieurement plutôt que de n'imposer aucune limite côté serveur quant au nombre de demandes et de surcharger le plan de contrôle, ce qui pourrait entraîner une dégradation des performances ou une indisponibilité.
Le mécanisme utilisé par Kubernetes pour configurer la façon dont ces demandes en vol sont réparties entre différents types de demandes est appelé API--max-requests-inflight indicateurs et. --max-mutating-requests-inflight EKS utilise les valeurs par défaut de 400 et 200 demandes pour ces indicateurs, ce qui permet d'envoyer un total de 600 demandes à un moment donné. Cependant, à mesure qu'il agrandit le plan de contrôle en fonction de l'augmentation de l'utilisation et de la perte de charge de travail, il augmente en conséquence le quota de demandes en vol jusqu'en 2000 (sous réserve de modifications). L'APF indique comment ces quotas de demandes en vol sont ensuite subdivisés entre les différents types de demandes. Notez que les plans de contrôle EKS sont hautement disponibles avec au moins 2 serveurs API enregistrés pour chaque cluster. Cela signifie que le nombre total de demandes en vol que votre cluster peut traiter est le double (ou supérieur s'il est davantage redimensionné horizontalement) du quota en vol défini par kube-apiserver. Cela représente plusieurs milliers de requests/second clusters EKS parmi les plus importants.
Deux types d'objets Kubernetes, appelés PriorityLevelConfigurations et FlowSchemas, configurent la façon dont le nombre total de demandes est réparti entre les différents types de demandes. Ces objets sont automatiquement gérés par le serveur API et EKS utilise la configuration par défaut de ces objets pour la version mineure de Kubernetes donnée. PriorityLevelConfigurations représentent une fraction du nombre total de demandes autorisées. Par exemple, la charge de travail la plus élevée PriorityLevelConfiguration est allouée à 98 demandes sur un total de 600. La somme des demandes allouées à toutes PriorityLevelConfigurations sera égale à 600 (ou légèrement supérieure à 600 car le serveur d'API arrondira le chiffre si un niveau donné est accordé à une fraction d'une demande). Pour vérifier le PriorityLevelConfigurations contenu de votre cluster et le nombre de requêtes allouées à chacun, vous pouvez exécuter la commande suivante. Voici les valeurs par défaut d'EKS 1.32 :
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_nominal_limit_seats apiserver_flowcontrol_nominal_limit_seats{priority_level="catch-all"} 13 apiserver_flowcontrol_nominal_limit_seats{priority_level="exempt"} 0 apiserver_flowcontrol_nominal_limit_seats{priority_level="global-default"} 49 apiserver_flowcontrol_nominal_limit_seats{priority_level="leader-election"} 25 apiserver_flowcontrol_nominal_limit_seats{priority_level="node-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="system"} 74 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245
Le deuxième type d'objet est FlowSchemas. Les requêtes du serveur d'API avec un ensemble de propriétés donné sont classées dans la même catégorie FlowSchema. Ces propriétés incluent soit l'utilisateur authentifié, soit les attributs de la demande, tels que le groupe d'API, l'espace de noms ou la ressource. A indique FlowSchema également à quel type de demande PriorityLevelConfiguration ce type de demande doit être mappé. Ensemble, les deux objets indiquent : « Je veux que ce type de demande soit pris en compte dans cette part des demandes en vol. » Lorsqu'une requête atteint le serveur API, celui-ci vérifie chacune de ses requêtes FlowSchemas jusqu'à ce qu'il en trouve une qui correspond à toutes les propriétés requises. Si plusieurs FlowSchemas correspondent à une requête, le serveur API choisira celle qui a la plus petite priorité correspondante spécifiée en tant que propriété dans l'objet. FlowSchema
Le mappage de FlowSchemas vers PriorityLevelConfigurations peut être visualisé à l'aide de cette commande :
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations peut avoir un type de file d'attente, de rejet ou d'exemption. Pour les types Queue et Reject, une limite est imposée au nombre maximum de demandes en vol pour ce niveau de priorité, mais le comportement diffère lorsque cette limite est atteinte. Par exemple, le workload-high PriorityLevelConfiguration utilise le type Queue et dispose de 98 requêtes disponibles pour être utilisées par le controller-manager, le endpoint-controller, le planificateur, les contrôleurs associés à eks et depuis des pods exécutés dans l'espace de noms kube-system. Comme le type Queue est utilisé, le serveur API essaiera de conserver les demandes en mémoire en espérant que le nombre de demandes en vol tombe en dessous de 98 avant l'expiration de ces demandes. Si le délai d'attente d'une requête donnée est dépassé ou si trop de demandes sont déjà en attente, le serveur API n'a pas d'autre choix que de supprimer la demande et de renvoyer au client un 429. Notez que la mise en file d'attente peut empêcher une demande de recevoir un 429, mais cela implique un compromis entre une latence accrue de bout en bout sur la demande.
Considérons maintenant le fourre-tout FlowSchema qui correspond au fourre-tout avec le type Reject PriorityLevelConfiguration . Si les clients atteignent la limite de 13 demandes en vol, le serveur API n'effectuera pas de mise en file d'attente et supprimera les demandes instantanément avec un code de réponse 429. Enfin, les demandes correspondant PriorityLevelConfiguration à un type Exempt ne recevront jamais de 429 et seront toujours expédiées immédiatement. Ceci est utilisé pour les demandes hautement prioritaires telles que les requêtes healthz ou les demandes provenant du groupe system:masters.
Surveillance des demandes APF et abandonnées
Pour confirmer si des demandes sont abandonnées à cause de l'APF, les métriques du serveur d'API apiserver_flowcontrol_rejected_requests_total peuvent être surveillées afin de vérifier les informations concernées FlowSchemas et PriorityLevelConfigurations. Par exemple, cet indicateur montre que 100 demandes provenant des comptes de service FlowSchema ont été abandonnées en raison de l'expiration des délais dans les files d'attente où la charge de travail est faible :
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
Pour vérifier dans quelle mesure une donnée PriorityLevelConfiguration est proche de la réception de 429 secondes ou de l'augmentation de la latence due à une file d'attente, vous pouvez comparer la différence entre la limite de simultanéité et la simultanéité utilisée. Dans cet exemple, nous avons une mémoire tampon de 100 demandes.
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_nominal_limit_seats.*workload-low' apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_executing_seats.*workload-low' apiserver_flowcontrol_current_executing_seats{flow_schema="service-accounts",priority_level="workload-low"} 145
Pour vérifier si une demande PriorityLevelConfiguration est mise en file d'attente mais pas nécessairement abandonnée, la métrique de apiserver_flowcontrol_current_inqueue_requests peut être référencée :
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
Parmi les autres indicateurs utiles de Prometheus, citons :
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
Consultez la documentation en amont pour obtenir la liste complète des métriques APF
Empêcher les demandes abandonnées
Évitez les 429 en modifiant votre charge de travail
Lorsque l'APF abandonne des demandes en raison d'un PriorityLevelConfiguration dépassement du nombre maximum de demandes autorisées en vol, les clients concernés FlowSchemas peuvent réduire le nombre de demandes exécutées à un moment donné. Cela peut être accompli en réduisant le nombre total de demandes effectuées au cours de la période au cours de laquelle 429 demandes se produisent. Notez que les demandes de longue durée, telles que les appels de liste coûteux, sont particulièrement problématiques car elles sont considérées comme des demandes en vol pendant toute la durée de leur exécution. La réduction du nombre de ces demandes coûteuses ou l'optimisation de la latence de ces appels de liste (par exemple, en réduisant le nombre d'objets récupérés par demande ou en passant à une demande de surveillance) peut contribuer à réduire la simultanéité totale requise par la charge de travail donnée.
Évitez les 429 en modifiant vos paramètres APF
Avertissement
Ne modifiez les paramètres APF par défaut que si vous savez ce que vous faites. Des paramètres APF mal configurés peuvent entraîner l'abandon des demandes du serveur d'API et des perturbations importantes de la charge de travail.
Une autre approche pour empêcher les demandes abandonnées consiste à modifier la valeur par défaut FlowSchemas ou à l' PriorityLevelConfigurations installer sur les clusters EKS. EKS installe les paramètres par défaut en amont pour FlowSchemas et PriorityLevelConfigurations pour la version mineure de Kubernetes donnée. Le serveur API rétablit automatiquement ces objets avec leurs valeurs par défaut en cas de modification, sauf si l'annotation suivante sur les objets est définie sur false :
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
À un niveau élevé, les paramètres APF peuvent être modifiés pour :
-
Allouez davantage de capacité en vol aux demandes qui vous intéressent.
-
Isolez les demandes non essentielles ou coûteuses susceptibles de réduire la capacité pour d'autres types de demandes.
Cela peut être accompli soit en modifiant la valeur par défaut FlowSchemas , PriorityLevelConfigurations soit en créant de nouveaux objets de ce type. Les opérateurs peuvent augmenter les valeurs garanties ConcurrencyShares pour les PriorityLevelConfigurations objets concernés afin d'augmenter le pourcentage de demandes en vol qui leur sont allouées. En outre, le nombre de demandes pouvant être mises en file d'attente à un moment donné peut également être augmenté si l'application peut gérer la latence supplémentaire causée par le fait que les demandes sont mises en file d'attente avant leur expédition.
Il est également possible de créer de nouveaux PriorityLevelConfigurations objets FlowSchema et objets spécifiques à la charge de travail du client. Sachez que le fait d'attribuer une plus ConcurrencyShares grande garantie aux demandes existantes PriorityLevelConfigurations ou aux nouvelles PriorityLevelConfigurations entraînera une réduction du nombre de demandes pouvant être traitées par d'autres compartiments, car la limite globale restera à 600 en vol par serveur d'API.
Lorsque vous modifiez les paramètres par défaut de l'APF, ces métriques doivent être surveillées sur un cluster hors production afin de garantir que la modification des paramètres ne provoque pas de 429 indésirables :
-
La métrique de
apiserver_flowcontrol_rejected_requests_totaldoit être surveillée pour tous FlowSchemas afin de s'assurer qu'aucun compartiment ne commence à supprimer des demandes. -
Les valeurs pour
apiserver_flowcontrol_nominal_limit_seatsetapiserver_flowcontrol_current_executing_seatsdoivent être comparées afin de garantir que la simultanéité d'utilisation ne risque pas de dépasser la limite pour ce niveau de priorité.
Un cas d'utilisation courant pour définir une nouvelle FlowSchema et PriorityLevelConfiguration est l'isolation. Supposons que nous voulions isoler les appels d'événements de liste de longue durée provenant des pods pour leur propre part de demandes. Cela évitera que les demandes importantes émanant de pods utilisant les comptes de service existants ne FlowSchema reçoivent 429 demandes et ne soient privées de capacité de demande. Rappelez-vous que le nombre total de demandes en vol est limité. Toutefois, cet exemple montre que les paramètres APF peuvent être modifiés afin de mieux répartir la capacité des demandes pour une charge de travail donnée :
Exemple FlowSchema d'objet pour isoler les demandes d'événements de liste :
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
Cela FlowSchema capture tous les appels d'événements de liste effectués par les comptes de service dans l'espace de noms par défaut.
-
La priorité correspondante de 8000 est inférieure à la valeur de 9000 utilisée par les comptes de service existants, de FlowSchema sorte que ces appels d'événements de liste correspondront à list-events-default-service-accounts plutôt qu'à des comptes de service.
-
Nous utilisons le fourre-tout PriorityLevelConfiguration pour isoler ces demandes. Ce compartiment autorise uniquement l'utilisation de 13 demandes en vol par ces appels d'événements de longue durée. Les pods commenceront à recevoir 429 dès qu'ils essaieront d'émettre plus de 13 de ces demandes simultanément.
Récupération de ressources dans le serveur d'API
L'obtention d'informations depuis le serveur d'API est un comportement attendu pour les clusters de toutes tailles. À mesure que vous augmentez le nombre de ressources dans le cluster, la fréquence des demandes et le volume de données peuvent rapidement devenir un obstacle pour le plan de contrôle et entraîner une latence et un ralentissement des API. En fonction de la gravité de la latence, cela entraîne des temps d'arrêt inattendus si vous ne faites pas attention.
Savoir ce que vous demandez et à quelle fréquence sont les premières étapes pour éviter ce type de problèmes. Voici des conseils pour limiter le volume de requêtes en fonction des meilleures pratiques de dimensionnement. Les suggestions de cette section sont fournies dans l'ordre, en commençant par les options connues pour être les plus évolutives.
Utiliser des informateurs partagés
Lorsque vous créez des contrôleurs et des systèmes d'automatisation qui s'intègrent à l'API Kubernetes, vous devez souvent obtenir des informations à partir des ressources Kubernetes. Si vous interrogez régulièrement ces ressources, cela peut entraîner une charge importante sur le serveur d'API.
L'utilisation d'un informateur
Les contrôleurs doivent éviter d'interroger les ressources à l'échelle du cluster sans étiquettes ni sélecteurs de champs, en particulier dans les grands clusters. Chaque sondage non filtré nécessite l'envoi d'un grand nombre de données inutiles depuis etcd via le serveur API pour être filtrées par le client. En filtrant en fonction des libellés et des espaces de noms, vous pouvez réduire la quantité de travail que le serveur d'API doit effectuer pour répondre aux demandes et aux données envoyées au client.
Optimisation de l'utilisation de l'API Kubernetes
Lorsque vous appelez l'API Kubernetes avec des contrôleurs personnalisés ou une automatisation, il est important de limiter les appels aux seules ressources dont vous avez besoin. Sans limites, vous pouvez entraîner une charge inutile sur le serveur d'API, etc.
Il est recommandé d'utiliser l'argument watch dans la mesure du possible. En l'absence d'arguments, le comportement par défaut consiste à répertorier les objets. Pour utiliser watch au lieu de list, vous pouvez l'ajouter ?watch=true à la fin de votre demande d'API. Par exemple, pour placer tous les pods dans l'espace de noms par défaut avec une montre, utilisez :
/api/v1/namespaces/default/pods?watch=true
Si vous mettez en vente des objets, vous devez limiter la portée de ce que vous mettez en vente et la quantité de données renvoyées. Vous pouvez limiter les données renvoyées en ajoutant des limit=500 arguments aux demandes. L'fieldSelectorargument et le /namespace/ chemin peuvent être utiles pour s'assurer que vos listes ont une portée aussi étroite que nécessaire. Par exemple, pour répertorier uniquement les pods en cours d'exécution dans l'espace de noms par défaut, utilisez le chemin d'API et les arguments suivants.
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
Ou listez tous les pods qui fonctionnent avec :
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
Une autre option pour limiter les appels de surveillance ou les objets listés consiste à utiliser une option resourceVersionsque vous pouvez consulter dans la documentation de KubernetesresourceVersion argument, vous recevrez la version la plus récente disponible qui nécessite une lecture par quorum etcd, qui est la lecture la plus coûteuse et la plus lente de la base de données. La ResourceVersion dépend des ressources que vous essayez d'interroger et qui se trouvent dans le metadata.resourseVersion champ. Ceci est également recommandé en cas d'utilisation de Watch Calls et pas seulement de listes d'appels
Il existe une resourceVersion=0 option spéciale qui renverra les résultats depuis le cache du serveur API. Cela peut réduire la charge de l'etcd mais ne supporte pas la pagination.
/api/v1/namespaces/default/pods?resourceVersion=0
Il est recommandé d'utiliser watch avec une ResourceVersion définie comme étant la valeur connue la plus récente reçue de la liste ou de la surveillance précédente. Ceci est géré automatiquement dans client-go. Mais il est suggéré de le vérifier si vous utilisez un client k8s dans d'autres langues.
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
Si vous appelez l'API sans aucun argument, cela consommera le plus de ressources pour le serveur d'API et etc. Cet appel permettra d'obtenir tous les pods dans tous les espaces de noms sans pagination ni limitation de portée et nécessitera une lecture du quorum depuis etcd.
/api/v1/pods
Empêchez le DaemonSet tonnerre des troupeaux
A DaemonSet garantit que tous (ou certains) nœuds exécutent une copie d'un pod. Lorsque des nœuds rejoignent le cluster, le daemonset-controller crée des pods pour ces nœuds. Lorsque les nœuds quittent le cluster, ces pods sont collectés à la poubelle. La suppression d'un DaemonSet va nettoyer les pods qu'il a créés.
Voici quelques utilisations typiques de DaemonSet a :
-
Exécution d'un démon de stockage en cluster sur chaque nœud
-
Exécution d'un démon de collecte de logs sur chaque nœud
-
Exécution d'un démon de surveillance des nœuds sur chaque nœud
Sur les clusters comportant des milliers de nœuds, la création d'un nouveau DaemonSet nœud DaemonSet, sa mise à jour ou l'augmentation du nombre de nœuds peuvent entraîner une charge élevée sur le plan de contrôle. Si DaemonSet les pods émettent des requêtes coûteuses au serveur d'API au démarrage du pod, ils peuvent entraîner une utilisation importante des ressources sur le plan de contrôle en raison d'un grand nombre de demandes simultanées.
En fonctionnement normal, vous pouvez utiliser un RollingUpdate pour assurer le déploiement progressif des nouveaux DaemonSet modules. Dans le cadre d'une stratégie de RollingUpdate mise à jour, une fois que vous avez mis à jour un DaemonSet modèle, le contrôleur supprime les anciens DaemonSet DaemonSet modules et en crée de nouveaux automatiquement de manière contrôlée. Au maximum, un pod DaemonSet sera exécuté sur chaque nœud pendant tout le processus de mise à jour. Vous pouvez effectuer un déploiement progressif en maxUnavailable réglant sur 1, maxSurge 0 et minReadySeconds 60. Si vous ne spécifiez pas de stratégie de mise à jour, Kubernetes créera par défaut un RollingUpdate avec maxUnavailable 1, maxSurge 0 et minReadySeconds 0.
minReadySeconds: 60 strategy: type: RollingUpdate rollingUpdate: maxSurge: 0 maxUnavailable: 1
A RollingUpdate garantit le déploiement progressif de nouveaux DaemonSet pods s'ils ont déjà été créés et s'ils contiennent le nombre attendu de Ready pods sur tous les nœuds. DaemonSet Des problèmes graves liés aux troupeaux peuvent survenir dans certaines conditions qui ne sont pas couvertes par les RollingUpdate stratégies.
Empêchez le tonnerre des troupeaux lors de la création DaemonSet
Par défaut, quelle que soit la RollingUpdate configuration, le daemonset-controller du kube-controller-manager créera des pods pour tous les nœuds correspondants simultanément lorsque vous en créerez un nouveau. DaemonSet Pour forcer le déploiement progressif des modules après avoir créé un DaemonSet, vous pouvez utiliser un NodeSelector ouNodeAffinity. Cela créera un DaemonSet nœud correspondant à zéro nœud, puis vous pourrez progressivement mettre à jour les nœuds pour les rendre éligibles à l'exécution d'un pod à partir du DaemonSet à un rythme contrôlé. Vous pouvez suivre cette approche :
-
Ajoutez une étiquette à tous les nœuds pour
run-daemonset=false.
kubectl label nodes --all run-daemonset=false
-
Créez votre DaemonSet avec un
NodeAffinityparamètre correspondant à n'importe quel nœud sansrun-daemonset=falseétiquette. Dans un premier temps, cela se traduira par DaemonSet l'absence de pods correspondants.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
Retirez l'
run-daemonset=falseétiquette de vos nœuds à un rythme contrôlé. Vous pouvez utiliser ce script bash comme exemple :
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
Vous pouvez éventuellement supprimer le
NodeAffinityparamètre de votre DaemonSet objet. Notez que cela déclenchera également unRollingUpdateet remplacera progressivement tous les DaemonSet pods existants car le DaemonSet modèle a changé.
Empêchez le tonnerre des troupeaux lors de la mise à l'échelle des nœuds
À l'instar de DaemonSet la création, la création rapide de nouveaux nœuds peut entraîner le démarrage simultané d'un grand nombre de DaemonSet pods. Vous devez créer de nouveaux nœuds à un rythme contrôlé afin que le contrôleur crée DaemonSet des pods au même rythme. Si cela n'est pas possible, vous pouvez rendre les nouveaux nœuds initialement inéligibles à l'existant DaemonSet en utilisantNodeAffinity. Ensuite, vous pouvez ajouter progressivement une étiquette aux nouveaux nœuds afin que le daemonset-controller crée des pods à un rythme contrôlé. Vous pouvez suivre cette approche :
-
Ajoutez une étiquette à tous les nœuds existants pour
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
Mettez à jour votre DaemonSet compte avec un
NodeAffinityparamètre correspondant à n'importe quel nœud doté d'unerun-daemonset=trueétiquette. Notez que cela déclenchera également unRollingUpdateet remplacera progressivement tous les DaemonSet pods existants car le DaemonSet modèle a changé. Vous devez attendre la fin deRollingUpdatel'opération avant de passer à l'étape suivante.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
Créez de nouveaux nœuds dans votre cluster. Notez que ces nœuds n'auront pas d'
run-daemonset=trueétiquette et ne DaemonSet correspondront donc pas à ces nœuds. -
Ajoutez l'
run-daemonset=trueétiquette à vos nouveaux nœuds (qui n'en ont pas actuellement) à un rythme contrôlé.run-daemonsetVous pouvez utiliser ce script bash comme exemple :
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
Vous pouvez éventuellement supprimer le
NodeAffinityparamètre de votre DaemonSet objet et supprimer l'run-daemonsetétiquette de tous les nœuds.
Évitez les foules lors des mises à jour DaemonSet
Une RollingUpdate politique ne respectera le maxUnavailable paramètre que pour les DaemonSet pods qui le sontReady. Si DaemonSet a uniquement NotReady des pods ou un pourcentage élevé de NotReady pods et que vous mettez à jour son modèle, le daemonset-controller créera de nouveaux pods simultanément pour tous les pods. NotReady Cela peut entraîner de graves problèmes de troupeau s'il y a un nombre important de NotReady capsules, par exemple si les capsules tournent continuellement en boucle ou ne parviennent pas à extraire des images.
Pour forcer le déploiement progressif des modules lorsque vous mettez à jour un module DaemonSet et qu'il existe NotReady des modules, vous pouvez modifier temporairement la stratégie de mise à jour DaemonSet du formulaire RollingUpdate auOnDelete. Après avoir mis à jour un DaemonSet modèle, le contrôleur crée de nouveaux modules après avoir supprimé manuellement les anciens afin que vous puissiez contrôler le déploiement des nouveaux modules. OnDelete Vous pouvez suivre cette approche :
-
Vérifiez si vous avez
NotReadydes capsules dans votre DaemonSet. -
Si ce n'est pas le cas, vous pouvez mettre à jour le DaemonSet modèle en toute sécurité et la
RollingUpdatestratégie garantira un déploiement progressif. -
Si c'est le cas, vous devez d'abord mettre à jour votre stratégie DaemonSet pour pouvoir utiliser
OnDeletecette stratégie.
updateStrategy: type: OnDelete
-
Ensuite, mettez à jour votre DaemonSet modèle en y apportant les modifications nécessaires.
-
Après cette mise à jour, vous pouvez supprimer les anciens DaemonSet modules en émettant des demandes de suppression de modules à un rythme contrôlé. Vous pouvez utiliser ce script bash comme exemple où le DaemonSet nom est fluentd-elasticsearch dans l'espace de noms kube-system :
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
Enfin, vous pouvez DaemonSet revenir à la
RollingUpdatestratégie précédente.
