Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Équilibrage de charge
Astuce
Découvrez les
Les équilibreurs de charge reçoivent le trafic entrant et le distribuent entre les cibles de l'application prévue hébergée dans un cluster EKS. Cela améliore la résilience de l'application. Lorsqu'il est déployé dans un cluster EKS, le contrôleur AWS Load Balancer crée et gère les AWS Elastic Load Balancers pour ce cluster. Lorsqu'un service de type Kubernetes LoadBalancer est créé, le contrôleur AWS Load Balancer crée un Network Load Balancer (NLB) qui équilibre la charge du trafic reçu au niveau de la couche 4 du modèle OSI. Lors de la création d'un objet Kubernetes Ingress, le AWS Load Balancer Controller crée un Application Load Balancer (ALB) qui équilibre la charge du trafic au niveau de la couche 7 du modèle OSI.
Choix du type de Load Balancer
Le portefeuille AWS Elastic Load Balancing (ELB) prend en charge les équilibreurs de charge suivants : les équilibreurs de charge d'application (ALB), les équilibreurs de charge réseau (NLB), les équilibreurs de charge de passerelle (GWLB) et les équilibreurs de charge classiques (CLB). Cette section sur les meilleures pratiques se concentrera sur l'ALB et le NLB, qui sont les deux plus pertinents pour les clusters EKS.
La principale considération lors du choix du type d'équilibreur de charge est la charge de travail requise.
Pour des informations plus détaillées et à titre de référence pour tous les équilibreurs de charge AWS, consultez Comparaisons de produits
Choisissez l'Application Load Balancer (ALB) si votre charge de travail est HTTP/HTTPS
Si une charge de travail nécessite un équilibrage de charge au niveau de la couche 7 du modèle OSI, le AWS Load Balancer Controller peut être utilisé pour provisionner un ALB ; nous aborderons le provisionnement dans la section suivante. L'ALB est contrôlé et configuré par la ressource Ingress mentionnée précédemment et achemine le trafic HTTP ou HTTPS vers différents pods au sein du cluster. L'ALB offre aux clients la flexibilité de modifier l'algorithme de routage du trafic de l'application ; l'algorithme de routage par défaut est circulaire, l'algorithme de routage des demandes les moins en suspens constituant également une alternative.
Choisissez le Network Load Balancer (NLB) si votre charge de travail est TCP ou si votre charge de travail nécessite la préservation de l'adresse IP source des clients
Un Network Load Balancer fonctionne au niveau de la quatrième couche (Transport) du modèle d'interconnexion des systèmes ouverts (OSI). Il est adapté aux charges de travail basées sur TCP et UDP. Network Load Balancer préserve également par défaut l'adresse IP source des clients lors de la présentation du trafic au pod.
Choisissez le Network Load Balancer (NLB) si votre charge de travail ne peut pas utiliser le DNS
Une autre raison essentielle d'utiliser le NLB est si vos clients ne peuvent pas utiliser le DNS. Dans ce cas, le NLB est peut-être mieux adapté à votre charge de travail car les adresses IP d'un Network Load Balancer sont statiques. Bien qu'il soit recommandé aux clients d'utiliser le DNS pour résoudre des noms de domaine en adresses IP lorsqu'ils se connectent à des équilibreurs de charge, si l'application d'un client ne prend pas en charge la résolution DNS et n'accepte que des adresses IP codées en dur, un NLB convient mieux car les adresses IP sont statiques et restent les mêmes pendant toute la durée de vie du NLB.
Provisionnement d'équilibreurs de charge
Après avoir déterminé le Load Balancer le mieux adapté à vos charges de travail, les clients disposent de plusieurs options pour le provisionner.
Provisionnez des équilibreurs de charge en déployant le contrôleur AWS Load Balancer
Il existe deux méthodes principales pour provisionner des équilibreurs de charge au sein d'un cluster EKS.
-
Tirer parti du contrôleur de service dans le fournisseur de cloud AWS (ancien)
-
Tirer parti du contrôleur AWS Load Balancer (recommandé)
Par défaut, le Kubernetes Service Controller, également connu sous le nom de contrôleur intégré à l'arborescence, réconcilie le type de ressource Kubernetes Service. LoadBalancer Ce contrôleur est intégré au composant AWS Cloud Provider
La configuration de l'Elastic Load Balancer provisionné est contrôlée par des annotations qui doivent être ajoutées au manifeste du service Kubernetes. Les annotations utilisées par le Service Controller
Le Service Controller est obsolète et ne reçoit actuellement que des corrections de bogues critiques. Lorsque vous créez un service Kubernetes de type Kubernetes LoadBalancer, le Service Controller crée un AWS CLB par défaut, mais peut également créer AWS NLB si vous utilisez la bonne annotation. Il convient de noter que Service Controller ne prend pas en charge les ressources Kubernetes Ingress et qu'il ne prend pas non plus en charge IPv6.
Nous vous recommandons d'utiliser le contrôleur AWS Load Balancer dans vos clusters EKS pour réconcilier le service Kubernetes et les ressources d'entrée. Vous devez utiliser les bonnes annotations dans votre service Kubernetes ou dans votre manifeste d'entrée afin qu'AWS Load Balancer Controller soit responsable du processus de réconciliation. (au lieu du contrôleur de service)
Si vous utilisez le mode automatique EKS, le contrôleur AWS Load Balancer vous est fourni automatiquement ; aucune installation n'est nécessaire.
Choisir Load Balancer Target-Type
Enregistrez les pods en tant que cibles à l'aide de l'IP Target-Type
Un AWS Elastic Load Balancer : Network & Application envoie le trafic reçu aux cibles enregistrées dans un groupe cible. Pour un cluster EKS, il existe deux types de cibles que vous pouvez enregistrer dans le groupe cible : Instance et IP. Le type de cible utilisé a une incidence sur les éléments enregistrés et sur la manière dont le trafic est acheminé du Load Balancer vers le pod. Par défaut, le contrôleur AWS Load Balancer enregistre les cibles en utilisant le type « Instance ». Cette cible sera l'adresse IP du nœud de travailNodePort, ce qui implique notamment :
-
Le trafic provenant du Load Balancer sera transféré au Worker Node sur le NodePort, il est traité selon les règles iptables (configurées par kube-proxy exécuté sur le nœud), et est transféré au service sur son ClusterIP (toujours sur le nœud). Enfin, le service sélectionne au hasard un pod enregistré et lui transmet le trafic. Ce flux implique plusieurs sauts et une latence supplémentaire peut être encourue, en particulier parce que le service sélectionne parfois un pod exécuté sur un autre nœud de travail qui peut également se trouver dans une autre zone de disponibilité.
-
Étant donné que le Load Balancer enregistre le nœud de travail comme cible, cela signifie que son bilan de santé envoyé à la cible ne sera pas reçu directement par le pod mais par le nœud de travail sur celui-ci, NodePort et le trafic de contrôle de santé suivra le même chemin que celui décrit ci-dessus.
-
La surveillance et le dépannage sont plus complexes car le trafic transféré par le Load Balancer n'est pas directement envoyé aux pods. Vous devez donc soigneusement corréler le paquet reçu sur le Worker Node avec le Service ClusterIP et, éventuellement, avec le pod pour avoir une visibilité complète de bout en bout sur le trajet du paquet afin de résoudre correctement les problèmes.

En revanche, si vous configurez le type de cible comme « IP » comme nous le recommandons, les implications seront les suivantes :
-
Le trafic provenant du Load Balancer sera transféré directement vers le pod, ce qui simplifie le chemin réseau car il contourne les sauts supplémentaires précédents des nœuds de travail et de l'adresse IP du cluster de services, réduit la latence qui aurait autrement été encourue si le service avait transféré le trafic vers un pod situé dans une autre zone AZ et enfin, cela supprime le traitement de la surcharge de traitement par les règles iptables sur les nœuds de travail.
-
Le bilan de santé du Load Balancer est reçu et traité directement par le pod, ce qui signifie que l'état cible « sain » ou « malsain » est une représentation directe de l'état de santé du pod.
-
La surveillance et le dépannage sont simplifiés et tout outil utilisé pour capturer l'adresse IP du paquet révélera directement le trafic bidirectionnel entre le Load Balancer et le pod dans ses champs source et destination.

Pour créer un AWS Elastic Load Balancing qui utilise des cibles IP, vous devez ajouter :
-
alb.ingress.kubernetes.io/target-type: ipannotation au manifeste de votre entrée lors de la configuration de votre entrée Kubernetes (Application Load Balancer) -
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ipannotation au manifeste de votre service lors de la configuration de votre service Kubernetes de type LoadBalancer (Network Load Balancer).
Configuration des vérifications de l'état de santé du Load Balancer
Bien que Kubernetes fournisse ses propres mécanismes de vérification de l'état (détaillés dans la section suivante), nous recommandons de mettre en œuvre les contrôles de santé ELB en tant que protection complémentaire qui fonctionne en dehors du plan de contrôle de Kubernetes. Cette couche indépendante continue de surveiller votre application même pendant :
-
Interruptions du plan de contrôle Kubernetes
-
Retards d'exécution des sondes
-
Partitions réseau entre kubelet et pod
Pour les charges de travail critiques nécessitant une disponibilité maximale et une reprise accélérée dans les scénarios mentionnés ci-dessus, les bilans de santé ELB fournissent un filet de sécurité essentiel qui fonctionne parallèlement aux mécanismes natifs de Kubernetes, et non à leur place.
Afin de configurer et d'affiner les contrôles de santé de votre ELB, vous devez utiliser des annotations dans votre service Kubernetes ou dans votre manifeste d'entrée qui seront rapprochées par Service Controller ou AWS Load Balancer Controller.
Disponibilité et cycle de vie du pod
Lors de la mise à niveau d'une application, vous devez vous assurer que celle-ci est toujours disponible pour traiter les demandes afin que les utilisateurs ne subissent aucune interruption de service. L'un des défis courants de ce scénario consiste à synchroniser l'état de disponibilité de vos charges de travail entre la couche Kubernetes et l'infrastructure, par exemple les équilibreurs de charge externes. Les sections suivantes mettent en évidence les meilleures pratiques pour faire face à de tels scénarios.
Note
Les explications ci-dessous sont basées sur EndpointSlices
Utiliser des bilans de santé
Kubernetes exécute par défaut le contrôle de l'état du processus
Veuillez consulter la section Création du pod dans l'annexe ci-dessous pour revoir la séquence des événements du processus de création du pod.
Utiliser des sondes de préparation
Par défaut, lorsque tous les conteneurs d'un pod fonctionnentsuccess. D'autre part, si la sonde tombe en panne plus loin sur la ligne, le Pod est retiré de l' EndpointSlice objet. Vous pouvez configurer une sonde de disponibilité dans le manifeste du Pod pour chaque conteneur. kubeletun processus sur chaque nœud exécute la sonde de préparation sur les conteneurs de ce nœud.
Utilisez les barrières de disponibilité des Pod
L'un des aspects de la sonde de préparation est le fait qu'elle ne contient aucun feedback/influence mécanisme externe. Le processus kubelet sur le nœud exécute la sonde et définit l'état de la sonde. Cela n'a aucun impact sur les requêtes entre les microservices eux-mêmes dans la couche Kubernetes (trafic est-ouest) puisque le EndpointSlice Controller tient la liste des points de terminaison (Pods) toujours à jour. Pourquoi et quand auriez-vous besoin d'un mécanisme externe alors ?
Lorsque vous exposez vos applications en utilisant le type de service Kubernetes Load Balancer ou Kubernetes Ingress (pour le trafic nord-sud), la liste des adresses IP des pods pour le service Kubernetes correspondant doit être propagée vers l'équilibreur de charge de l'infrastructure externe afin que celui-ci dispose également d'une liste de cibles à jour. AWS Load Balancer Controller comble cette lacune. Lorsque vous utilisez AWS Load Balancer Controller et que vous en tirez partitarget group: IP, tout comme kube-proxy AWS Load Balancer Controller reçoit également une mise à jour (watchvia), puis il communique avec l'API ELB pour configurer et commencer à enregistrer l'adresse IP du pod en tant que cible sur l'ELB.
Lorsque vous effectuez une mise à jour continue d'un déploiement, de nouveaux pods sont créés, et dès que l'état d'un nouveau pod est « prêt », un old/existing pod est résilié. Au cours de ce processus, l' EndpointSliceobjet Kubernetes est mis à jour plus rapidement que le temps nécessaire à l'ELB pour enregistrer les nouveaux pods en tant que cibles, voir enregistrement des cibles. Pendant une courte période, il se peut que l'état de la couche Kubernetes ne corresponde pas à celui de l'infrastructure dans lequel les demandes des clients peuvent être abandonnées. Au cours de cette période, au sein de la couche Kubernetes, les nouveaux pods seraient prêts à traiter les demandes, mais du point de vue de l'ELB, ils ne le sont pas.
Pod Readiness Gates
Arrêtez les applications en toute simplicité
Votre application doit répondre à un signal SIGTERM en démarrant son arrêt progressif afin que les clients ne subissent aucune interruption de service. Cela signifie que votre application doit exécuter des procédures de nettoyage telles que la sauvegarde des données, la fermeture des descripteurs de fichiers, la fermeture des connexions à la base de données, le traitement des demandes en cours de vol avec élégance et la sortie en temps opportun pour répondre à la demande de résiliation du Pod. Vous devez définir le délai de grâce suffisamment long pour que le nettoyage puisse être terminé. Pour savoir comment réagir au signal SIGTERM, vous pouvez consulter les ressources du langage de programmation correspondant que vous utilisez pour votre application.
Si votre application ne parvient pas à s'arrêter correctement à la réception d'un signal SIGTERM ou si elle ignores/does ne reçoit pas le signal
La séquence globale des événements est illustrée dans le schéma ci-dessous. Remarque : quel que soit le résultat de la procédure d'arrêt progressif de l'application ou le résultat du PreStop hook, les conteneurs d'applications sont finalement fermés à la fin de la période de grâce via SIGKILL.
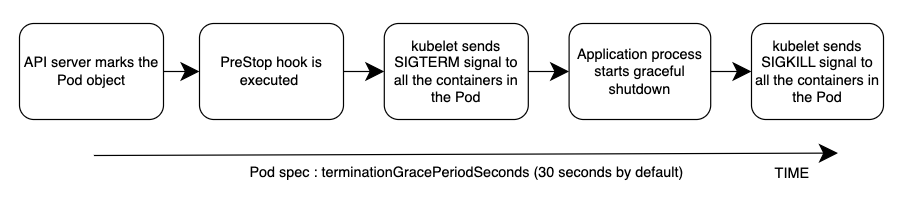
Veuillez consulter la section Suppression du pod dans l'annexe ci-dessous pour revoir la séquence des événements du processus de suppression du pod.
Gérez avec élégance les demandes des clients
La séquence des événements de la suppression du pod est différente de celle de la création du pod. Lorsqu'un pod est créé, l'adresse IP du pod est kubelet mise à jour dans l'API Kubernetes et ce n'est qu'alors que l' EndpointSlice objet est mis à jour. D'autre part, lorsqu'un Pod est arrêté, l'API Kubernetes avertit à la fois le kubelet et EndpointSlice le contrôleur. Inspectez soigneusement le schéma suivant qui montre la séquence des événements.
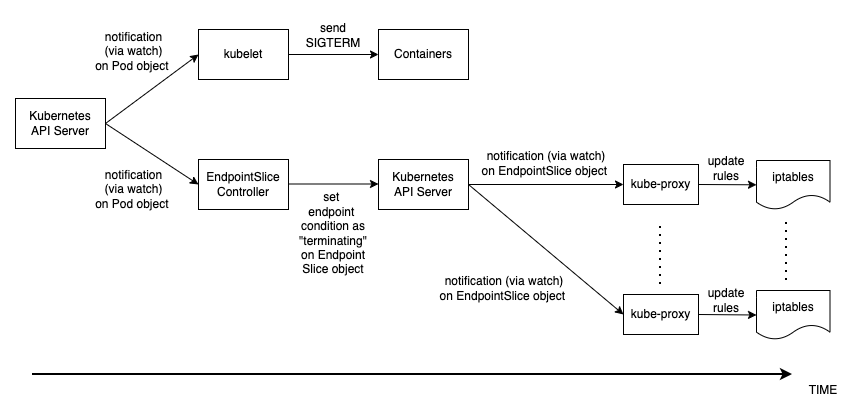
La façon dont l'état se propage depuis le serveur API jusqu'aux règles iptables sur les nœuds expliquées ci-dessus crée une condition de course intéressante. Parce qu'il y a de fortes chances que le conteneur reçoive le signal SIGKILL bien avant que le kube-proxy sur chaque nœud ne mette à jour les règles iptables locales. Dans un tel cas, deux scénarios méritent d'être mentionnés :
-
Si votre application supprime immédiatement et brutalement les demandes et les connexions en cours de vol dès réception de SIGTERM, les clients seront confrontés à 50 fois plus d'erreurs partout.
-
Même si votre application garantit que toutes les demandes et connexions en cours de vol sont traitées dans leur intégralité à la réception de SIGTERM, les nouvelles demandes des clients seront toujours envoyées au conteneur de l'application pendant la période de grâce, car les règles iptables ne sont peut-être pas encore mises à jour. Jusqu'à ce que la procédure de nettoyage ferme le socket du serveur sur le conteneur, ces nouvelles demandes entraîneront de nouvelles connexions. Lorsque le délai de grâce prend fin, les connexions établies après le SIGTERM sont alors abandonnées sans condition puisque SIGKILL est envoyé.
La définition d'une période de grâce suffisamment longue dans la spécification Pod peut résoudre ce problème, mais en fonction du délai de propagation et du nombre réel de demandes clients, il est difficile de prévoir le temps qu'il faudra à l'application pour fermer les connexions correctement. Par conséquent, l'approche la moins parfaite mais la plus réalisable consiste à utiliser un PreStop hook pour retarder le signal SIGTERM jusqu'à ce que les règles iptables soient mises à jour afin de s'assurer qu'aucune nouvelle demande client n'est envoyée à l'application. Seules les connexions existantes sont maintenues. PreStop hook peut être un simple gestionnaire Exec tel que. sleep 10
Le comportement et la recommandation mentionnés ci-dessus s'appliquent également lorsque vous exposez vos applications à l'aide de Load Balancer, de type Kubernetes Service, ou de Kubernetes Ingress (pour le trafic nord-sud) à l'aide d'AWS Load Balancer Controller et de l'effet de levier. target group: IP Parce que tout comme kube-proxy le AWS Load Balancer Controller reçoit également une mise à jour (via watch) sur l' EndpointSlice objet, puis il communique avec l'API ELB pour commencer à désenregistrer l'adresse IP du pod auprès de l'ELB. Cependant, en fonction de la charge de l'API Kubernetes ou de l'API ELB, cela peut également prendre du temps et le SIGTERM a peut-être déjà été envoyé à l'application il y a longtemps. Une fois que l'ELB commence à désenregistrer la cible, il arrête d'envoyer des demandes à cette cible afin que l'application ne reçoive aucune nouvelle demande et l'ELB entame également un délai de désenregistrement de 300 secondes par défaut. Pendant le processus de désinscription, l'ELB draining attend essentiellement que les requests/existing connexions en vol vers cette cible soient épuisées. Une fois le délai de désenregistrement expiré, la cible n'est plus utilisée et toutes les demandes en vol adressées à cette cible sont supprimées de force.
Utiliser le budget d'interruption du Pod
Configurez un budget d'interruption
Références
-
KubeCon Session Europe 2019 - Prêt ? Une étude approfondie de Pod Readiness Gates for Service Health
-
Livre - Kubernetes
en action -
Blog AWS - Comment faire évoluer rapidement votre application avec ALB sur EKS (sans perte de trafic
)
Annexe
Création de pods
Il est impératif de comprendre quelle est la séquence des événements dans un scénario dans lequel un Pod est déployé, puis il doit healthy/ready recevoir et traiter les demandes des clients. Parlons de la séquence des événements.
-
Un pod est créé sur le plan de contrôle Kubernetes (c'est-à-dire par une commande kubectl, une mise à jour de déploiement ou une action de dimensionnement).
-
kube-schedulerassigne le Pod à un nœud du cluster. -
Le processus kubelet exécuté sur le nœud attribué reçoit la mise à jour (via
watch) et communique avec le moteur d'exécution du conteneur pour démarrer les conteneurs définis dans la spécification Pod. -
Lorsque les conteneurs commencent à fonctionner, le kubelet met à jour la condition du Pod
comme Readydans l'objet Pod de l'API Kubernetes. -
Le EndpointSliceController
reçoit la mise à jour de l'état du Pod (via watch) et ajoute le Pod IP/Port en tant que nouveau point de terminaison à l'EndpointSliceobjet (liste des adresses IP du pod) du service Kubernetes correspondant. -
Le processus kube-proxy
sur chaque nœud reçoit la mise à jour (via watch) sur l'EndpointSlice objet, puis met à jour les règles iptablessur chaque nœud, avec le nouveau Pod. IP/port
Suppression du pod
Tout comme lors de la création d'un pod, il est impératif de comprendre quelle est la séquence des événements lors de la suppression du pod. Parlons de la séquence des événements.
-
Une demande de suppression de Pod est envoyée au serveur d'API Kubernetes (c'est-à-dire par une
kubectlcommande, une mise à jour du déploiement ou une action de dimensionnement). -
Le serveur d'API Kubernetes lance une période de grâce
, qui est de 30 secondes par défaut, en définissant le champ DeletionTimestamp dans l'objet Pod. (La période de grâce peut être configurée dans les spécifications du Pod jusqu'à terminationGracePeriodSeconds) -
Le
kubeletprocessus exécuté sur le nœud reçoit la mise à jour (via une montre) sur l'objet Pod et envoie un signal SIGTERMà l'identifiant de processus 1 (PID 1) à l'intérieur de chaque conteneur de ce Pod. Il regarde ensuite le terminationGracePeriodSeconds. -
Le EndpointSliceController
reçoit également la mise à jour (via watch) de l'étape 2 et définit la condition du point de terminaison comme « terminaison » dans l'EndpointSliceobjet (liste des adresses IP des pods) du service Kubernetes correspondant. -
Le processus kube-proxy
sur chaque nœud reçoit la mise à jour (via watch) sur l'EndpointSlice objet, puis les règles iptablessur chaque nœud sont mises à jour par le kube-proxy pour arrêter de transférer les demandes des clients au Pod. -
À l'
terminationGracePeriodSecondsexpiration, le signal SIGKILLest kubeletenvoyé au processus parent de chaque conteneur du Pod et y met fin de force. -
TheEndpointSliceLe contrôleur
supprime le point de terminaison de l'EndpointSlice objet. -
Le serveur API supprime l'objet Pod.
