Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exécution d'applications à haute disponibilité
Vos clients s'attendent à ce que votre application soit toujours disponible, y compris lorsque vous apportez des modifications, en particulier lors de pics de trafic. Une architecture évolutive et résiliente permet à vos applications et services de fonctionner sans interruption, ce qui garantit la satisfaction de vos utilisateurs. Une infrastructure évolutive croît et se réduit en fonction des besoins de l'entreprise. L'élimination des points de défaillance uniques est une étape essentielle pour améliorer la disponibilité d'une application et la rendre résiliente.
Avec Kubernetes, vous pouvez exploiter vos applications et les exécuter de manière hautement disponible et résiliente. Sa gestion déclarative garantit qu'une fois l'application configurée, Kubernetes essaiera en permanence de faire correspondre l'état actuel à l'état souhaité
Recommandations
Configurer les budgets d'interruption de service
Les budgets d'interruption des
Évitez d'utiliser des Singleton Pods
Si l'ensemble de votre application s'exécute dans un seul Pod, votre application ne sera pas disponible en cas de fermeture de ce Pod. Au lieu de déployer des applications à l'aide de pods individuels, créez des déploiements.
Exécutez plusieurs répliques
L'exécution de plusieurs répliques (pods) d'une application à l'aide d'un déploiement permet à celle-ci de fonctionner de manière hautement disponible. Si l'une des répliques tombe en panne, les répliques restantes fonctionneront toujours, mais à capacité réduite, jusqu'à ce que Kubernetes crée un autre pod pour compenser la perte. En outre, vous pouvez utiliser le Horizontal Pod Autoscaler pour dimensionner
Planifier des répliques sur les nœuds
L'exécution de plusieurs répliques ne sera pas très utile si toutes les répliques sont exécutées sur le même nœud et que le nœud devient indisponible. Envisagez d'utiliser des contraintes d'anti-affinité ou de propagation de la topologie des pods pour répartir les répliques d'un déploiement sur plusieurs nœuds de travail.
Vous pouvez encore améliorer la fiabilité d'une application classique en l'exécutant sur plusieurs zones de disponibilité.
Utilisation des règles anti-affinité du Pod
Le manifeste ci-dessous indique au planificateur Kubernetes de préférer placer les pods sur des nœuds et des AZ distincts. Il ne nécessite pas de nœuds ou d'AZ distincts, car si c'était le cas, Kubernetes ne sera pas en mesure de planifier des pods une fois qu'un pod sera exécuté dans chaque AZ. Si votre application ne nécessite que trois répliques, vous pouvez utiliser requiredDuringSchedulingIgnoredDuringExecution fortopologyKey: topology.kubernetes.io/zone, et le planificateur Kubernetes ne planifiera pas deux pods dans la même zone de zones.
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 4 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: topology.kubernetes.io/zone weight: 100 - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: kubernetes.io/hostname weight: 99 containers: - name: web-app image: nginx:1.16-alpine
Utilisation des contraintes de propagation de la topologie Pod
À l'instar des règles anti-affinité des pods, les contraintes de propagation de la topologie des pods vous permettent de rendre votre application disponible sur différents domaines de défaillance (ou topologie) tels que les hôtes ou les AZ. Cette approche fonctionne très bien lorsque vous essayez de garantir la tolérance aux pannes ainsi que la disponibilité en disposant de plusieurs répliques dans chacun des différents domaines topologiques. Les règles d'anti-affinité des pods, en revanche, peuvent facilement produire un résultat lorsque vous n'avez qu'une seule réplique dans un domaine topologique, car les pods présentant une anti-affinité les uns envers les autres ont un effet répulsif. Dans de tels cas, une seule réplique sur un nœud dédié n'est pas idéale en termes de tolérance aux pannes et ne constitue pas une bonne utilisation des ressources. Les contraintes d'étalement de topologie vous permettent de mieux contrôler l'étalement ou la distribution que le planificateur doit essayer d'appliquer dans les domaines topologiques. Voici quelques propriétés importantes à utiliser dans cette approche :
-
Le
maxSkewest utilisé pour contrôler ou déterminer le point maximal auquel les choses peuvent être inégales entre les domaines topologiques. Par exemple, si une application possède 10 répliques et est déployée sur 3 zones de disponibilité, vous ne pouvez pas obtenir une répartition uniforme, mais vous pouvez influencer le degré d'inégalité de la distribution. Dans ce cas, ilmaxSkewpeut être compris entre 1 et 10. Une valeur de 1 signifie que vous pouvez vous retrouver avec un spread similaire4,3,33,3,4à3,4,3ou entre les 3 AZ. En revanche, une valeur de 10 signifie que vous pouvez vous retrouver avec un spread similaire10,0,00,10,0ou0,0,10sur 3 AZ. -
topologyKeyIl s'agit d'une clé pour l'une des étiquettes de nœuds et définit le type de domaine topologique à utiliser pour la distribution des pods. Par exemple, un spread zonal comporterait la paire clé-valeur suivante :topologyKey: "topology.kubernetes.io/zone" -
La
whenUnsatisfiablepropriété est utilisée pour déterminer comment vous souhaitez que le planificateur réagisse si les contraintes souhaitées ne peuvent pas être satisfaites. -
Le
labelSelectorest utilisé pour trouver les pods correspondants afin que le planificateur puisse en prendre connaissance lorsqu'il décide où placer les pods conformément aux contraintes que vous spécifiez.
En plus de ce qui précède, il existe d'autres champs que vous pouvez consulter plus en détail dans la documentation de Kubernetes
La topologie du pod répartit les contraintes sur 3 AZ
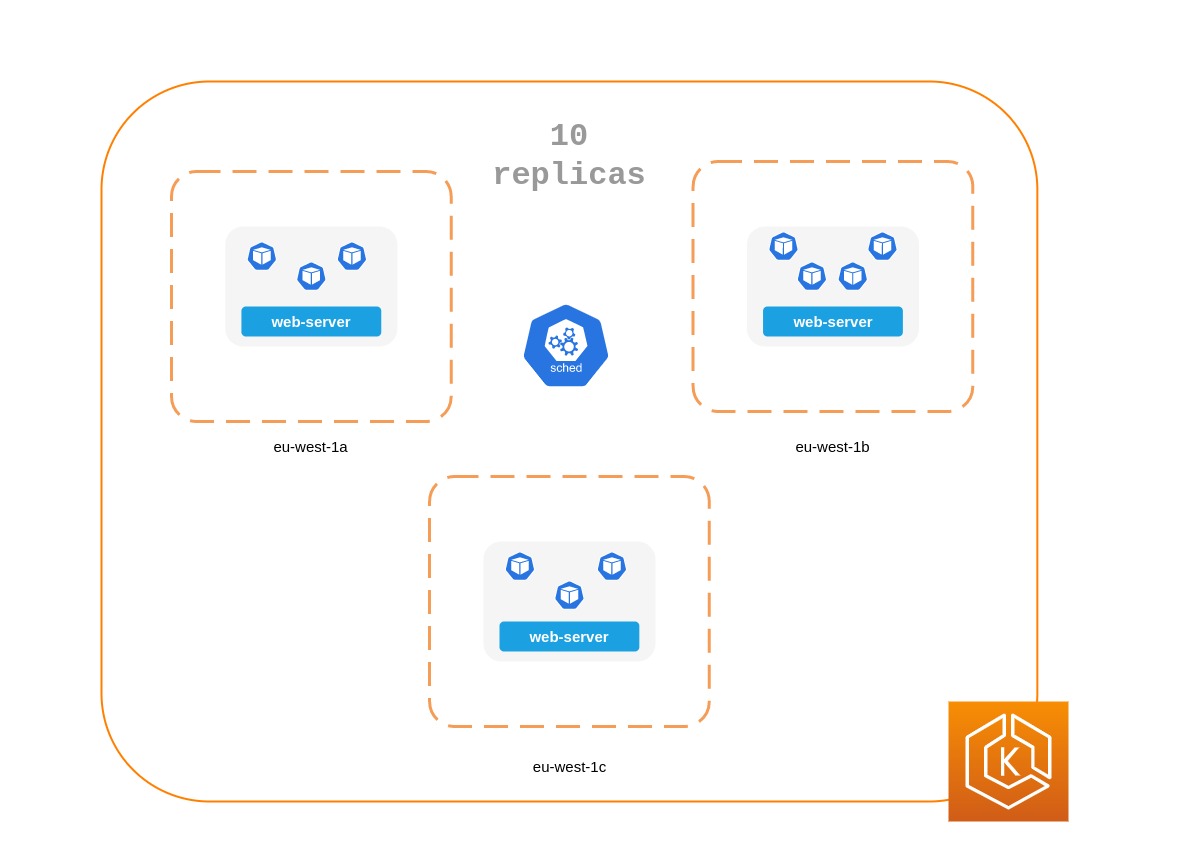
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 10 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test containers: - name: web-app image: nginx:1.16-alpine
Exécuter le serveur Kubernetes Metrics
Installez le serveur de métriques
Le serveur de métriques ne conserve aucune donnée et ne constitue pas une solution de surveillance. Son objectif est d'exposer les métriques d'utilisation du processeur et de la mémoire à d'autres systèmes. Si vous souhaitez suivre l'état de votre application au fil du temps, vous avez besoin d'un outil de surveillance tel que Prometheus ou Amazon. CloudWatch
Suivez la documentation EKS pour installer le serveur de mesures dans votre cluster EKS.
Autoscaler à nacelle horizontale (HPA)
HPA peut adapter automatiquement votre application en fonction de la demande et vous aider à éviter d'avoir un impact sur vos clients pendant les pics de trafic. Il est implémenté sous la forme d'une boucle de contrôle dans Kubernetes qui interroge périodiquement les métriques des API fournissant des métriques de ressources.
HPA peut récupérer des métriques à partir des API suivantes : 1. metrics.k8s.ioégalement connue sous le nom d'API Resource Metrics — Fournit l'utilisation du processeur et de la mémoire pour les pods 2. custom.metrics.k8s.io — Fournit des métriques provenant d'autres collecteurs de métriques tels que Prometheus ; ces métriques sont internes à votre cluster Kubernetes. 3. external.metrics.k8s.io — Fournit des métriques externes à votre cluster Kubernetes (E.g., profondeur de file d'attente SQS, latence ELB).
Vous devez utiliser l'une de ces trois API pour fournir la métrique permettant de dimensionner votre application.
Mise à l'échelle des applications en fonction de métriques personnalisées ou externes
Vous pouvez utiliser des métriques personnalisées ou externes pour adapter votre application à des métriques autres que l'utilisation du processeur ou de la mémoire. Les serveurs d'API Custom Metricscustom-metrics.k8s.ioAPI que HPA peut utiliser pour dimensionner automatiquement les applications.
Vous pouvez utiliser l'adaptateur Prometheus pour les API Kubernetes Metrics pour
Une fois que vous avez déployé l'adaptateur Prometheus, vous pouvez demander des métriques personnalisées à l'aide de kubectl. kubectl get —raw /apis/custom.metrics.k8s.io/v1beta1/
Comme son nom l'indique, les métriques externes permettent à Horizontal Pod Autoscaler de dimensionner les déploiements à l'aide de métriques externes au cluster Kubernetes. Par exemple, dans le cadre du traitement des charges de travail par lots, il est courant d'ajuster le nombre de répliques en fonction du nombre de tâches en cours dans une file d'attente SQS.
Pour dimensionner automatiquement les charges de travail Kubernetes, vous pouvez utiliser KEDA (Kubernetes Event-driven Autoscaling), un projet open source capable de piloter le dimensionnement des conteneurs en fonction d'un certain nombre d'événements personnalisés. Ce blog AWS
Autoscaler à nacelle verticale (VPA)
Le VPA ajuste automatiquement la réserve de processeur et de mémoire pour vos pods afin de vous aider à « dimensionner correctement » vos applications. Pour les applications qui doivent être mises à l'échelle verticalement, ce qui est fait en augmentant l'allocation des ressources, vous pouvez utiliser le VPA
Votre application peut devenir temporairement indisponible si le VPA doit la redimensionner, car l'implémentation actuelle du VPA n'effectue aucun ajustement sur place des pods ; elle recréera plutôt le pod qui doit être redimensionné.
La documentation EKS inclut une procédure pas à pas pour configurer le VPA.
Le projet Fairwinds Goldilocks
Mise à jour des applications
Les applications modernes nécessitent une innovation rapide associée à un haut degré de stabilité et de disponibilité. Kubernetes vous fournit les outils nécessaires pour mettre à jour vos applications en permanence sans perturber vos clients.
Examinons certaines des meilleures pratiques qui permettent de déployer rapidement des modifications sans sacrifier la disponibilité.
Disposer d'un mécanisme pour effectuer des annulations
Le fait d'avoir un bouton d'annulation peut éviter les catastrophes. Il est recommandé de tester les déploiements dans un environnement inférieur distinct (environnement de test ou de développement) avant de mettre à jour le cluster de production. L'utilisation d'un CI/CD pipeline peut vous aider à automatiser et à tester les déploiements. Avec un pipeline de déploiement continu, vous pouvez rapidement revenir à l'ancienne version si la mise à niveau s'avère défectueuse.
Vous pouvez utiliser les déploiements pour mettre à jour une application en cours d'exécution. Cela se fait généralement en mettant à jour l'image du conteneur. Vous pouvez l'utiliser kubectl pour mettre à jour un déploiement comme suit :
kubectl --record deployment.apps/nginx-deployment set image nginx-deployment nginx=nginx:1.16.1
L'--recordargument enregistre les modifications apportées au déploiement et vous aide si vous devez effectuer une restauration. kubectl rollout history deploymentaffiche les modifications enregistrées apportées aux déploiements dans votre cluster. Vous pouvez annuler une modification en utilisantkubectl rollout undo deployment <DEPLOYMENT_NAME>.
Par défaut, lorsque vous mettez à jour un déploiement qui nécessite une recréation des modules, le déploiement effectue une mise à jour continueRollingUpdateStrategy
Lorsque vous effectuez une mise à jour continue d'un déploiement, vous pouvez utiliser la Max UnavailableMax Surge propriété Deployment vous permet de définir le nombre maximum de pods pouvant être créés par rapport au nombre souhaité de pods.
Envisagez max unavailable de procéder à des ajustements pour vous assurer qu'un déploiement ne perturbe pas vos clients. Par exemple, Kubernetes définit 25 % max unavailable par défaut, ce qui signifie que si vous avez 100 pods, il se peut que seuls 75 pods fonctionnent activement pendant un déploiement. Si votre application a besoin d'un minimum de 80 pods, ce déploiement peut être perturbateur. Au lieu de cela, vous pouvez max unavailable régler sur 20 % pour garantir qu'il y ait au moins 80 pods fonctionnels tout au long du déploiement.
Utiliser les blue/green déploiements
Les changements sont intrinsèquement risqués, mais ceux qui ne peuvent pas être annulés peuvent être potentiellement catastrophiques. Les procédures de modification qui vous permettent de remonter le temps de manière efficace par le biais d'un rollback rendent les améliorations et les expérimentations plus sûres. Blue/green les déploiements vous offrent une méthode pour retirer rapidement les modifications en cas de problème. Dans cette stratégie de déploiement, vous créez un environnement pour la nouvelle version. Cet environnement est identique à la version actuelle de l'application en cours de mise à jour. Une fois le nouvel environnement configuré, le trafic est acheminé vers le nouvel environnement. Si la nouvelle version produit les résultats souhaités sans générer d'erreurs, l'ancien environnement est supprimé. Dans le cas contraire, le trafic est rétabli à l'ancienne version.
Vous pouvez effectuer blue/green des déploiements dans Kubernetes en créant un nouveau déploiement identique au déploiement de la version existante. Une fois que vous avez vérifié que les pods du nouveau déploiement fonctionnent sans erreur, vous pouvez commencer à envoyer du trafic vers le nouveau déploiement en modifiant les selector spécifications du service qui achemine le trafic vers les pods de votre application.
De nombreux outils d'intégration continue tels que Flux
Utiliser les déploiements Canary
Les déploiements Canary sont une variante des blue/green déploiements qui peuvent réduire de manière significative les risques liés aux modifications. Dans cette stratégie de déploiement, vous créez un nouveau déploiement avec moins de pods en plus de votre ancien déploiement, et vous redirigez un faible pourcentage du trafic vers le nouveau déploiement. Si les indicateurs indiquent que la nouvelle version fonctionne aussi bien ou mieux que la version existante, vous augmentez progressivement le trafic vers le nouveau déploiement tout en le dimensionnant jusqu'à ce que tout le trafic soit redirigé vers le nouveau déploiement. En cas de problème, vous pouvez acheminer tout le trafic vers l'ancien déploiement et arrêter d'envoyer du trafic vers le nouveau déploiement.
Bien que Kubernetes ne propose aucune méthode native pour effectuer des déploiements Canary, vous pouvez utiliser des outils tels que Flagger avec Istio.
Bilans de santé et auto-guérison
Aucun logiciel n'est exempt de bogues, mais Kubernetes peut vous aider à minimiser l'impact des défaillances logicielles. Dans le passé, si une application tombait en panne, quelqu'un devait remédier à la situation en redémarrant l'application manuellement. Kubernetes vous permet de détecter les défaillances logicielles de vos pods et de les remplacer automatiquement par de nouvelles répliques. Kubernetes vous permet de surveiller l'état de santé de vos applications et de remplacer automatiquement les instances défectueuses.
Kubernetes prend en charge trois types de tests de santé :
-
Sonde Liveness
-
Sonde de démarrage (prise en charge dans Kubernetes version 1.16+)
-
Sonde de préparation
Kubelet
Si vous choisissez une sonde exec basée, qui exécute un script shell dans un conteneur, assurez-vous que la commande shell se termine avant que la timeoutSeconds valeur n'expire. Dans le cas contraire, votre nœud sera soumis à des <defunct> processus, ce qui entraînera une défaillance du nœud.
Recommandations
Utilisez Liveness Probe pour éliminer les gousses malsaines
La sonde Liveness peut détecter les situations de blocage dans lesquelles le processus continue de s'exécuter, mais où l'application ne répond plus. Par exemple, si vous exécutez un service Web qui écoute sur le port 80, vous pouvez configurer une sonde Liveness pour envoyer une requête HTTP GET sur le port 80 du Pod. Kubelet envoie périodiquement une requête GET au Pod et attend une réponse ; si le Pod répond entre 200 et 399, le kubelet considère que le Pod est en bonne santé ; sinon, le Pod sera marqué comme non sain. Si un Pod échoue continuellement aux contrôles de santé, le kubelet l'arrêtera.
Vous pouvez l'utiliser initialDelaySeconds pour retarder la première sonde.
Lorsque vous utilisez la Liveness Probe, assurez-vous que votre application ne se retrouve pas dans une situation dans laquelle tous les Pods échouent simultanément à la Liveness Probe, car Kubernetes essaiera de remplacer tous vos Pods, ce qui mettra votre application hors ligne. En outre, Kubernetes continuera à créer de nouveaux pods qui échoueront également aux Liveness Probes, ce qui alourdira inutilement le plan de contrôle. Évitez de configurer la Liveness Probe pour qu'elle dépende d'un facteur externe à votre Pod, par exemple une base de données externe. En d'autres termes, une base de données externe à votre POD qui ne répond pas ne devrait pas faire échouer vos pods à leurs sondes de vitalité.
Dans son article LIVENESS PROBES ARE DANGEROUS, Sandor Szücs décrit les problèmes qui peuvent être causés par des sondes
Utilisez Startup Probe pour les applications dont le démarrage prend plus de temps
Lorsque votre application a besoin de plus de temps pour démarrer, vous pouvez utiliser la sonde de démarrage pour retarder la sonde de réactivité et de disponibilité. Par exemple, une application Java qui a besoin d'hydrater le cache d'une base de données peut avoir besoin de deux minutes pour être pleinement fonctionnelle. Toute sonde de vivacité ou de préparation jusqu'à ce qu'elle soit complètement fonctionnelle peut échouer. La configuration d'une sonde de démarrage permettra à l'application Java de retrouver son intégrité avant l'exécution de Liveness ou Readiness Probe.
Jusqu'à ce que la sonde de démarrage réussisse, toutes les autres sondes sont désactivées. Vous pouvez définir la durée maximale pendant laquelle Kubernetes doit attendre le démarrage de l'application. Si, après la durée maximale configurée, le pod échoue toujours aux sondes de démarrage, il sera arrêté et un nouveau pod sera créé.
La Startup Probe est similaire à la Liveness Probe : en cas d'échec, le Pod est recréé. Comme Ricardo A. l'explique dans son article Fantastic Probes And How To Configure Them, lesinitialDelaySeconds place.
Utiliser la sonde Readiness Probe pour détecter une indisponibilité partielle
Alors que la sonde Liveness détecte les défaillances d'une application qui sont résolues en arrêtant le Pod (d'où le redémarrage de l'application), Readiness Probe détecte les situations dans lesquelles l'application peut être temporairement indisponible. Dans ces situations, l'application peut ne plus répondre temporairement ; toutefois, elle devrait être rétablie une fois cette opération terminée.
Par exemple, lors d' I/O opérations intensives sur le disque, les applications peuvent être temporairement indisponibles pour traiter les demandes. Dans ce cas, la résiliation du Pod de l'application n'est pas une solution ; dans le même temps, les demandes supplémentaires envoyées au Pod peuvent échouer.
Vous pouvez utiliser la sonde Readiness Probe pour détecter une indisponibilité temporaire de votre application et arrêter d'envoyer des demandes à son Pod jusqu'à ce qu'elle redevienne fonctionnelle. Contrairement à Liveness Probe, où une défaillance entraînerait une recréation de Pod, un échec de Readiness Probe signifierait que Pod ne recevra aucun trafic en provenance du service Kubernetes. Lorsque la sonde de disponibilité aboutit, Pod recommence à recevoir du trafic en provenance du service.
Tout comme pour la Liveness Probe, évitez de configurer des Readiness Probes qui dépendent d'une ressource externe au Pod (telle qu'une base de données). Voici un scénario dans lequel un Readiness mal configuré peut rendre l'application non fonctionnelle : si la sonde de disponibilité d'un pod échoue alors que la base de données de l'application est inaccessible, les autres répliques du pod échoueront également simultanément car elles partagent les mêmes critères de contrôle de santé. En configurant la sonde de cette manière, chaque fois que la base de données n'est pas disponible, les sondes de préparation du pod échoueront et Kubernetes cessera d'envoyer du trafic à tous les pods.
L'un des effets secondaires de l'utilisation des sondes de préparation est qu'elles peuvent augmenter le temps nécessaire à la mise à jour des déploiements. Les nouvelles répliques ne recevront pas de trafic tant que les sondes de préparation ne seront pas concluantes ; d'ici là, les anciennes répliques continueront à recevoir du trafic.
Faire face aux perturbations
Les pods ont une durée de vie limitée. Même si vous avez des pods qui fonctionnent depuis longtemps, il est prudent de vous assurer que les pods se terminent correctement le moment venu. Selon votre stratégie de mise à niveau, les mises à niveau du cluster Kubernetes peuvent nécessiter la création de nouveaux nœuds de travail, ce qui nécessite que tous les pods soient recréés sur des nœuds plus récents. Une gestion appropriée des résiliations et des budgets d'interruption de service peuvent vous aider à éviter les interruptions de service, car les pods sont retirés des anciens nœuds et recréés sur les nouveaux nœuds.
La méthode préférée pour mettre à niveau les nœuds de travail consiste à créer de nouveaux nœuds de travail et à mettre fin aux anciens. Avant de mettre fin aux nœuds de travail, vous devez le drain faire. Lorsqu'un nœud de travail est vidé, tous ses modules sont expulsés en toute sécurité. La sécurité est un mot clé ici ; lorsque les capsules d'un travailleur sont expulsées, il ne s'agit pas simplement d'envoyer un SIGKILL signal. Au lieu de cela, un SIGTERM signal est envoyé au processus principal (PID 1) de chaque conteneur des Pods en cours d'expulsion. Une fois le SIGTERM signal envoyé, Kubernetes accorde au processus un certain temps (période de grâce) avant qu'un SIGKILL signal ne soit envoyé. Ce délai de grâce est de 30 secondes par défaut ; vous pouvez remplacer le délai par défaut en utilisant grace-period flag dans kubectl ou en le déclarant terminationGracePeriodSeconds dans votre Podspec.
kubectl delete pod <pod name> —grace-period=<seconds>
Il est courant d'avoir des conteneurs dans lesquels le processus principal n'a pas de PID 1. Considérez ce contenant Python-based d'échantillons :
$ kubectl exec python-app -it ps PID USER TIME COMMAND 1 root 0:00 {script.sh} /bin/sh ./script.sh 5 root 0:00 python app.py
Dans cet exemple, le script shell reçoitSIGTERM, le processus principal, qui se trouve être une application Python dans cet exemple, ne reçoit aucun SIGTERM signal. Lorsque le Pod sera arrêté, l'application Python sera arrêtée brusquement. Cela peut être résolu en modifiant le ENTRYPOINT
Vous pouvez également utiliser les hooks de conteneurPreStop hook s'exécute avant que le conteneur ne reçoive un SIGTERM signal et doit être terminée avant que ce signal ne soit envoyé. La terminationGracePeriodSeconds valeur s'applique à partir du moment où l'action PreStop hook commence à s'exécuter, et non à partir du moment où le SIGTERM signal est envoyé.
Recommandations
Protégez les charges de travail critiques avec Pod Disruption Budgets
Pod Disruption Budget ou PDB peuvent interrompre temporairement le processus d'expulsion si le nombre de répliques d'une application tombe en dessous du seuil déclaré. Le processus d'expulsion se poursuivra une fois que le nombre de répliques disponibles aura dépassé le seuil. Vous pouvez utiliser PDB pour déclarer le maxUnavailable nombre minAvailable et le nombre de répliques. Par exemple, si vous souhaitez qu'au moins trois copies de votre application soient disponibles, vous pouvez créer un PDB.
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: my-svc-pdb spec: minAvailable: 3 selector: matchLabels: app: my-svc
La politique PDB ci-dessus indique à Kubernetes d'arrêter le processus d'expulsion jusqu'à ce que trois répliques ou plus soient disponibles. Le drainage des nœuds respectePodDisruptionBudgets. Lors d'une mise à niveau d'un groupe de nœuds géré par EKS, les nœuds sont vidangés avec un délai de 15 minutes. Au bout de quinze minutes, si la mise à jour n'est pas forcée (l'option s'appelle Mise à jour continue dans la console EKS), la mise à jour échoue. Si la mise à jour est forcée, les modules sont supprimés.
Pour les nœuds autogérés, vous pouvez également utiliser des outils tels qu'AWS Node Termination Handler
Vous pouvez utiliser l'anti-affinité des pods pour planifier les pods d'un déploiement sur différents nœuds et éviter les retards liés au PDB lors des mises à niveau des nœuds.
Pratiquez l'ingénierie du chaos
L'ingénierie du chaos est la discipline qui consiste à expérimenter sur un système distribué afin de renforcer la confiance dans la capacité du système à résister à des conditions de production turbulentes.
Dans son blog, Dominik Tornow explique que Kubernetes est un système déclaratifreplica panne, le contrôleur de déploiementreplica De cette façon, les contrôleurs Kubernetes corrigent automatiquement les défaillances.
Les outils d'ingénierie du chaos tels que Gremlin
Utiliser un Service Mesh
Vous pouvez utiliser un maillage de services pour améliorer la résilience de votre application. Les maillages de services permettent la communication entre services et augmentent l'observabilité de votre réseau de microservices. La plupart des produits Service Mesh fonctionnent en faisant fonctionner un petit proxy réseau à côté de chaque service qui intercepte et inspecte le trafic réseau de l'application. Vous pouvez placer votre application dans un maillage sans modifier votre application. À l'aide des fonctionnalités intégrées du proxy de service, vous pouvez lui demander de générer des statistiques réseau, de créer des journaux d'accès et d'ajouter des en-têtes HTTP aux demandes sortantes de suivi distribué.
Un maillage de services peut vous aider à rendre vos microservices plus résilients grâce à des fonctionnalités telles que les nouvelles tentatives automatiques de demande, les délais d'expiration, les disjonctions et la limitation de débit.
Si vous exploitez plusieurs clusters, vous pouvez utiliser un maillage de services pour permettre la communication entre services entre clusters.
Maillages de service
Observabilité
L'observabilité est un terme générique qui inclut la surveillance, l'enregistrement et le traçage. Les applications basées sur des microservices sont distribuées par nature. Contrairement aux applications monolithiques où la surveillance d'un seul système est suffisante, dans une architecture d'application distribuée, vous devez surveiller les performances de chaque composant. Vous pouvez utiliser des systèmes de surveillance, de journalisation et de suivi distribué au niveau du cluster pour identifier les problèmes dans votre cluster avant qu'ils ne perturbent vos clients.
Les outils intégrés de Kubernetes pour le dépannage et la surveillance sont limités. Le serveur de mesures collecte les métriques relatives aux ressources et les stocke en mémoire, mais ne les conserve pas. Vous pouvez consulter les journaux d'un Pod à l'aide de kubectl, mais Kubernetes ne conserve pas automatiquement les journaux. Et la mise en œuvre du traçage distribué se fait soit au niveau du code de l'application, soit à l'aide de maillages de services.
L'extensibilité de Kubernetes brille ici. Kubernetes vous permet d'apporter votre solution centralisée préférée de surveillance, de journalisation et de suivi.
Recommandations
Surveillez vos applications
Le nombre de mesures que vous devez surveiller dans les applications modernes ne cesse de croître. Il est utile de disposer d'un moyen automatisé de suivre vos applications afin de pouvoir vous concentrer sur la résolution des problèmes de vos clients. Cluster-wide des outils de surveillance tels que Prometheus CloudWatch
Les outils de surveillance vous permettent de créer des alertes auxquelles votre équipe des opérations peut s'abonner. Envisagez des règles pour activer les alarmes en cas d'événements susceptibles, lorsqu'ils sont exacerbés, d'entraîner une panne ou d'avoir un impact sur les performances des applications.
Si vous ne savez pas quels indicateurs vous devez surveiller, vous pouvez vous inspirer des méthodes suivantes :
-
Méthode RED
. Représente les demandes, les erreurs et la durée. -
Méthode USE
. Désigne l'utilisation, la saturation et les erreurs.
Le billet de Sysdig Best practices for alerting on Kubernetes
Utiliser la bibliothèque cliente Prometheus pour exposer les métriques de l'application
En plus de surveiller l'état de l'application et d'agréger des métriques standard, vous pouvez également utiliser la bibliothèque cliente Prometheus
Utilisez des outils de journalisation centralisés pour collecter et conserver les journaux
La journalisation dans EKS se divise en deux catégories : les journaux du plan de contrôle et les journaux des applications. La journalisation du plan de contrôle EKS fournit des journaux d'audit et de diagnostic directement depuis le plan de contrôle vers CloudWatch les journaux de votre compte. Les journaux d'application sont des journaux produits par des pods exécutés au sein de votre cluster. Les journaux d'applications incluent les journaux produits par les pods qui exécutent les applications de logique métier et les composants du système Kubernetes tels que CoreDNS, Cluster Autoscaler, Prometheus, etc.
EKS fournit cinq types de journaux du plan de contrôle :
-
Journaux des composants du serveur d'API Kubernetes
-
Audit
-
Authentificateur
-
Responsable du contrôleur
-
Planificateur
Le gestionnaire du contrôleur et les journaux du planificateur peuvent aider à diagnostiquer les problèmes liés au plan de contrôle, tels que les goulots d'étranglement et les erreurs. Par défaut, les journaux du plan de contrôle EKS ne sont pas envoyés à CloudWatch Logs. Vous pouvez activer la journalisation du plan de contrôle et sélectionner les types de journaux du plan de contrôle EKS que vous souhaitez capturer pour chaque cluster de votre compte.
La collecte des journaux d'applications nécessite l'installation d'un outil d'agrégation de journaux tel que Fluent Bit
Les outils d'agrégation de journaux Kubernetes s'exécutent au fur DaemonSets et à mesure que les journaux des conteneurs sont extraits des nœuds. Les journaux des applications sont ensuite envoyés vers une destination centralisée pour y être stockés. Par exemple, CloudWatch Container Insights peut utiliser Fluent Bit ou Fluentd pour collecter des journaux et les envoyer à Logs à CloudWatch des fins de stockage. Fluent Bit et Fluentd prennent en charge de nombreux systèmes d'analyse de journaux populaires tels qu'Elasticsearch et InfluxDB, ce qui vous permet de modifier le backend de stockage de vos journaux en modifiant Fluent bit ou la configuration des journaux de Fluentd.
Utiliser un système de suivi distribué pour identifier les goulots d'étranglement
Une application moderne typique possède des composants répartis sur le réseau, et sa fiabilité dépend du bon fonctionnement de chacun des composants composant l'application. Vous pouvez utiliser une solution de suivi distribué pour comprendre le flux des demandes et la manière dont les systèmes communiquent. Les traces peuvent vous indiquer où se trouvent les goulots d'étranglement dans votre réseau d'applications et prévenir les problèmes susceptibles de provoquer des défaillances en cascade.
Deux options s'offrent à vous pour implémenter le suivi dans vos applications : vous pouvez soit implémenter le suivi distribué au niveau du code à l'aide de bibliothèques partagées, soit utiliser un maillage de services.
La mise en œuvre du traçage au niveau du code peut s'avérer désavantageuse. Dans cette méthode, vous devez apporter des modifications à votre code. Cela est encore plus compliqué si vous avez des applications polyglottes. Vous êtes également responsable de la gestion d'une autre bibliothèque, dans l'ensemble de vos services.
Les maillages de service tels que LinkerD
Les outils de traçage tels qu'AWS X-Ray
Envisagez d'utiliser un outil de suivi tel qu'AWS X-Ray
