Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration depuis Couchbase Server
Introduction
Ce guide présente les points clés à prendre en compte lors de la migration de Couchbase Server vers Amazon DocumentDB. Il explique les considérations relatives aux phases de découverte, de planification, d'exécution et de validation de votre migration. Il explique également comment effectuer des migrations hors ligne et en ligne.
Comparaison avec Amazon DocumentDB
| Serveur Couchbase | Amazon DocumentDB | |
|---|---|---|
| Organisation des données | Dans les versions 7.0 et ultérieures, les données sont organisées en compartiments, étendues et collections. Dans les versions antérieures, les données étaient organisées en compartiments. | Les données sont organisées en bases de données et en collections. |
| Compatibilité | Il existe des services distincts APIs (par exemple, données, index, recherche, etc.). Les recherches secondaires utilisent SQL++ (anciennement connu sous le nom de N1QL), un langage de requête basé sur le SQL standard ANSI, qui est donc familier à de nombreux développeurs. | Amazon DocumentDB est compatible avec l'API MongoDB. |
| Architecture | Le stockage est attaché à chaque instance de cluster. Vous ne pouvez pas dimensionner le calcul indépendamment du stockage. | Amazon DocumentDB est conçu pour le cloud et pour éviter les limites des architectures de base de données traditionnelles. Les couches de calcul et de stockage sont séparées dans Amazon DocumentDB et la couche de calcul peut être mise à l'échelle indépendamment du stockage. |
| Ajoutez de la capacité de lecture à la demande | Les clusters peuvent être étendus en ajoutant des instances. Le stockage étant rattaché à l'instance sur laquelle le service est exécuté, le temps nécessaire pour le faire évoluer dépend de la quantité de données à déplacer vers la nouvelle instance ou à rééquilibrer. | Vous pouvez obtenir un dimensionnement de lecture pour votre cluster Amazon DocumentDB en créant jusqu'à 15 répliques Amazon DocumentDB dans le cluster. Il n'y a aucun impact sur la couche de stockage. |
| Restauration rapide en cas de défaillance d'un nœud | Les clusters sont dotés de fonctionnalités de basculement automatique, mais le temps nécessaire pour rétablir leur pleine capacité dépend de la quantité de données à déplacer vers la nouvelle instance. | Amazon DocumentDB peut généralement basculer le cluster principal en 30 secondes et rétablir la pleine puissance du cluster en 8 à 10 minutes, quelle que soit la quantité de données qu'il contient. |
| Faites évoluer le stockage à mesure que les données augmentent | Pour le stockage en clusters autogéré, ne IOs procédez pas à une mise à l'échelle automatique. | Stockage et mise à l' IOs échelle d'Amazon DocumentDB automatiquement. |
| Backup des données sans affecter les performances | Les sauvegardes sont effectuées par le service de sauvegarde et ne sont pas activées par défaut. Comme le stockage et le calcul ne sont pas séparés, cela peut avoir un impact sur les performances. | Les sauvegardes Amazon DocumentDB sont activées par défaut et ne peuvent pas être désactivées. Les sauvegardes sont gérées par la couche de stockage, elles n'ont donc aucun impact sur la couche de calcul. Amazon DocumentDB prend en charge la restauration à partir d'un instantané de cluster et la restauration à un point précis dans le temps. |
| Durabilité des données | Il peut y avoir un maximum de 3 répliques de données dans un cluster, pour un total de 4 copies. Chaque instance sur laquelle le service de données est exécuté comportera des copies actives et une, deux ou trois répliques des données. | Amazon DocumentDB conserve 6 copies de données, quel que soit le nombre d'instances de calcul, avec un quorum d'écriture de 4 et un résultat toujours vrai. Les clients reçoivent un accusé de réception une fois que la couche de stockage a conservé 4 copies des données. |
| Cohérence | La cohérence immédiate des K/V opérations est prise en charge. Le SDK Couchbase achemine les K/V demandes vers l'instance spécifique qui contient la copie active des données. Ainsi, une fois la mise à jour confirmée, le client est assuré de lire cette mise à jour. La réplication des mises à jour vers d'autres services (index, recherche, analyse, événements) est finalement cohérente. | Les répliques Amazon DocumentDB sont finalement cohérentes. Si des lectures cohérentes immédiates sont requises, le client peut lire à partir de l'instance principale. |
| Réplication | La réplication entre centres de données (XDCR) permet une réplication filtrée, active-passive/active-active des données dans de nombreuses topologies. | Les clusters globaux Amazon DocumentDB fournissent une réplication active-passive dans des topologies 1:many (jusqu'à 10). |
Découverte
La migration vers Amazon DocumentDB nécessite une connaissance approfondie de la charge de travail de base de données existante. La découverte de la charge de travail consiste à analyser la configuration et les caractéristiques opérationnelles de votre cluster Couchbase (ensemble de données, index et charge de travail) afin de garantir une transition fluide avec un minimum de perturbations.
Configuration du cluster
Couchbase utilise une architecture centrée sur les services où chaque fonctionnalité correspond à un service. Exécutez la commande suivante sur votre cluster Couchbase pour déterminer quels services sont utilisés (voir Obtenir des informations sur les nœuds
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
Exemple de sortie :
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
Les services de Couchbase incluent les suivants :
Service de données (kv)
Le service de données permet read/write d'accéder aux données en mémoire et sur disque.
Amazon DocumentDB prend en charge les K/V opérations sur les données JSON via l'API MongoDB.
Service de requêtes (n1ql)
Le service de requêtes prend en charge l'interrogation de données JSON via SQL++.
Amazon DocumentDB prend en charge l'interrogation de données JSON via l'API MongoDB.
Service d'indexation (index)
Le service d'index crée et gère des index sur les données, ce qui permet d'accélérer les requêtes.
Amazon DocumentDB prend en charge un index principal par défaut et la création d'index secondaires sur les données JSON via l'API MongoDB.
Service de recherche (fts)
Le service de recherche prend en charge la création d'index pour la recherche en texte intégral.
La fonctionnalité native de recherche en texte intégral d'Amazon DocumentDB vous permet d'effectuer une recherche de texte sur de grands ensembles de données textuels à l'aide d'index de texte spécifiques via l'API MongoDB. Pour les cas d'utilisation de la recherche avancée, l'intégration d'Amazon DocumentDB Zero-ETL à Amazon OpenSearch Service
Service d'analyse (cbas)
Le service d'analyse prend en charge l'analyse des données JSON en temps quasi réel.
Amazon DocumentDB prend en charge les requêtes ad hoc sur les données JSON via l'API MongoDB. Vous pouvez également exécuter des requêtes complexes sur vos données JSON dans Amazon DocumentDB à l'aide d'Apache Spark exécuté sur Amazon EMR
Service de concours complet (concours complet)
Le service d'événements exécute une logique métier définie par l'utilisateur en réponse aux modifications des données.
Amazon DocumentDB automatise les charges de travail basées sur les événements en invoquant des AWS Lambda fonctions chaque fois que les données changent avec votre cluster Amazon DocumentDB.
Service de sauvegarde (sauvegarde)
Le service de sauvegarde planifie des sauvegardes de données complètes et incrémentielles et des fusions de sauvegardes de données précédentes.
Amazon DocumentDB sauvegarde en permanence vos données sur Amazon S3 avec une période de conservation de 1 à 35 jours afin que vous puissiez les restaurer rapidement à tout moment pendant la période de conservation des sauvegardes. Amazon DocumentDB prend également des instantanés automatiques de vos données dans le cadre de ce processus de sauvegarde continue. Vous pouvez également gérer la sauvegarde et la restauration d'Amazon DocumentDB
Caractéristiques opérationnelles
Utilisez l'outil de découverte pour Couchbase
Jeu de données
L'outil récupère les informations suivantes relatives au compartiment, à l'étendue et à la collection :
nom de compartiment
type de compartiment
nom de la portée
nom de collection
taille totale (octets)
nombre total d'articles
taille de l'élément (octets)
Index
L'outil récupère les statistiques d'index suivantes et toutes les définitions d'index pour tous les compartiments. Notez que les index principaux sont exclus car Amazon DocumentDB crée automatiquement un index principal pour chaque collection.
nom de compartiment
nom de la portée
nom de collection
nom de l'index
taille de l'index (octets)
Charge de travail
L'outil récupère les métriques K/V des requêtes N1QL. K/V les valeurs métriques sont collectées au niveau du bucket et les métriques SQL++ sont collectées au niveau du cluster.
Les options de ligne de commande de l'outil sont les suivantes :
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
Voici un exemple de commande :
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
Les valeurs métriques K/V seront basées sur des échantillons prélevés toutes les 10 minutes au cours de la semaine écoulée (voir méthode HTTP et URI
collection-stats.csv : informations sur le bucket, le champ d'application et la collection
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv — noms et tailles d'index
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv — obtenir, définir et supprimer des métriques pour tous les buckets
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv — SQL++ sélectionne, supprime et insère des métriques pour le cluster
selects,deletes,inserts 0,132,87
indexes- .txt <bucket-name>: définitions d'index de tous les index du compartiment. Notez que les index principaux sont exclus car Amazon DocumentDB crée automatiquement un index principal pour chaque collection.
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
Planification
Au cours de la phase de planification, vous déterminerez les exigences du cluster Amazon DocumentDB et le mappage des compartiments, des étendues et des collections Couchbase avec les bases de données et les collections Amazon DocumentDB.
Exigences relatives au cluster Amazon DocumentDB
Utilisez les données collectées lors de la phase de découverte pour dimensionner votre cluster Amazon DocumentDB. Consultez la section Dimensionnement des instances pour plus d'informations sur le dimensionnement de votre cluster Amazon DocumentDB.
Mappage de compartiments, de portées et de collections avec des bases de données et des collections
Déterminez les bases de données et les collections qui existeront dans votre ou vos clusters Amazon DocumentDB. Envisagez les options suivantes en fonction de la façon dont les données sont organisées dans votre cluster Couchbase. Ce ne sont pas les seules options, mais elles constituent des points de départ à considérer.
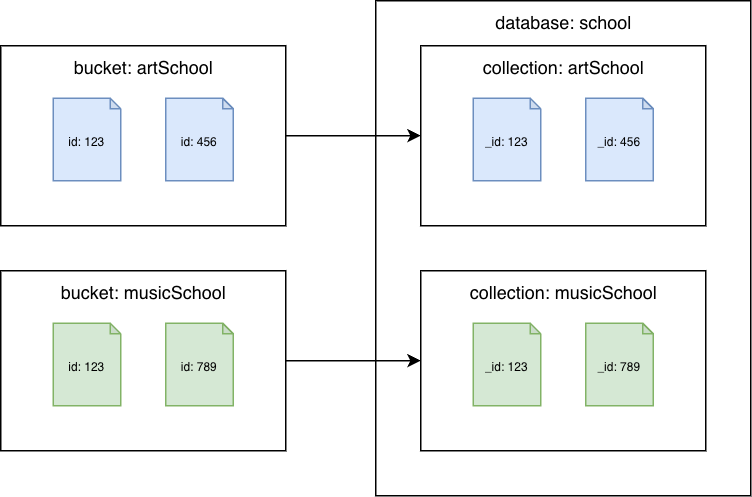
Couchbase Server 6.x ou version antérieure
Buckets Couchbase pour les collections Amazon DocumentDB
Migrez chaque compartiment vers une collection Amazon DocumentDB différente. Dans ce scénario, la valeur du document Couchbase sera utilisée comme id valeur Amazon _id DocumentDB.
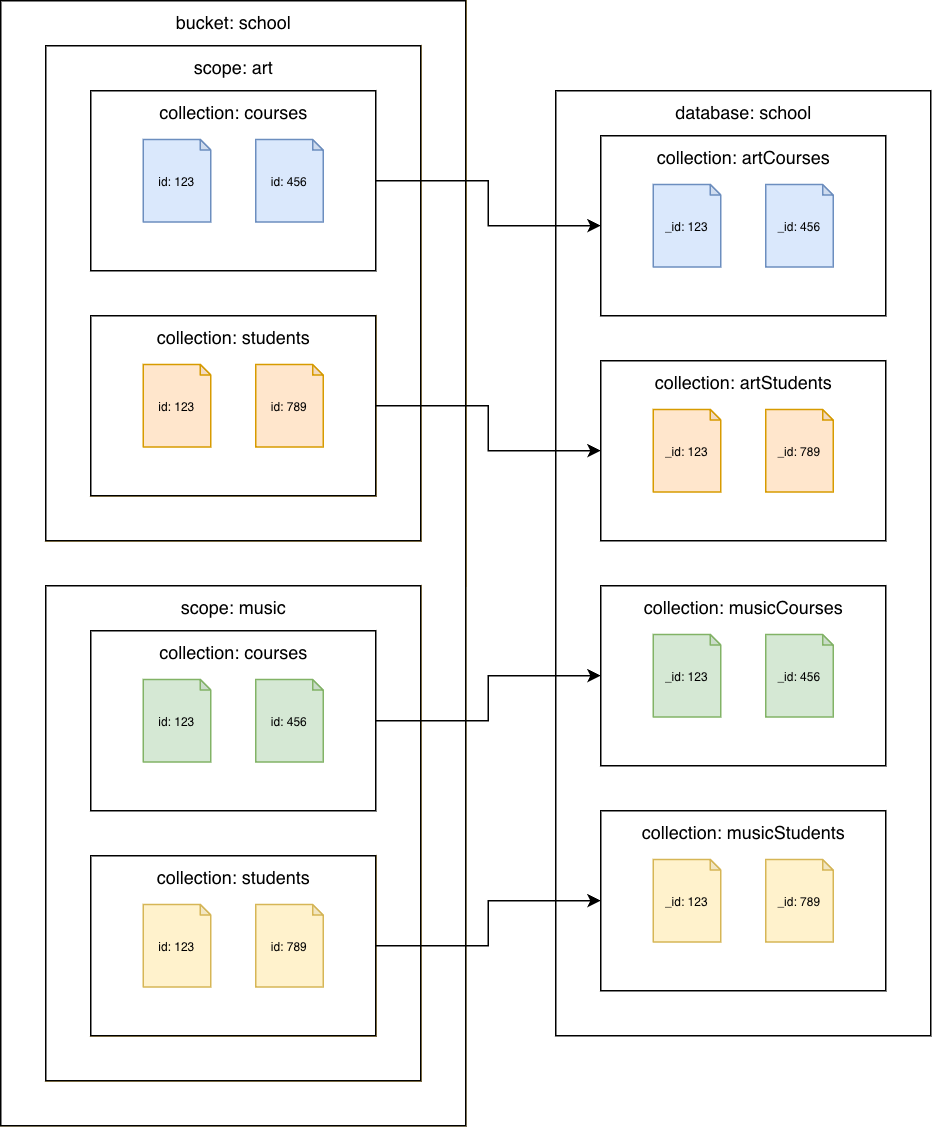
Couchbase Server 7.0 ou version ultérieure
Collections Couchbase vers des collections Amazon DocumentDB
Migrez chaque collection vers une collection Amazon DocumentDB différente. Dans ce scénario, la valeur du document Couchbase sera utilisée comme id valeur Amazon _id DocumentDB.
Migration
Migration d'index
La migration vers Amazon DocumentDB implique le transfert non seulement de données, mais également d'index afin de maintenir les performances des requêtes et d'optimiser les opérations de base de données. Cette section décrit le step-by-step processus détaillé de migration des index vers Amazon DocumentDB tout en garantissant la compatibilité et l'efficacité.
Utilisez Amazon Q pour convertir les CREATE INDEX instructions SQL++ en commandes Amazon createIndex() DocumentDB.
Téléchargez le ou les <bucket name>fichiers .txt d'index créés par l'outil de découverte pour Couchbase.
Entrez le message suivant :
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q générera des commandes Amazon DocumentDB createIndex() équivalentes. Notez que vous devrez peut-être mettre à jour les noms des collections en fonction de la façon dont vous avez mappé les compartiments, les étendues et les collections Couchbase aux collections Amazon DocumentDB.
Par exemple :
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Exemple de sortie Amazon Q (extrait) :
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Pour les index qu'Amazon Q n'est pas en mesure de convertir, reportez-vous à la section Gestion des index et des propriétés d'index Amazon DocumentDB pour plus d'informations.
Code de refactorisation pour utiliser le MongoDB APIs
Les clients utilisent Couchbase SDKs pour se connecter au serveur Couchbase. Les clients Amazon DocumentDB utilisent les pilotes MongoDB pour se connecter à Amazon DocumentDB. Toutes les langues prises en charge par Couchbase SDKs sont également prises en charge par les pilotes MongoDB. Consultez la section Pilotes MongoDB
Comme il APIs existe des différences entre Couchbase Server et Amazon DocumentDB, vous devrez refactoriser votre code pour utiliser la MongoDB appropriée. APIs Vous pouvez utiliser Amazon Q pour convertir les appels d' K/V API et les requêtes SQL++ en MongoDB équivalent : APIs
Téléchargez le ou les fichiers de code source.
Entrez le message suivant :
Convert the Couchbase API code to Amazon DocumentDB API code
À l'aide de l'exemple de code Python Hello Couchbase
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Reportez-vous à la section Connexion par programmation à Amazon DocumentDB pour des exemples de connexion à Amazon DocumentDB en Python, Node.js, PHP, Go, Java, C#/.NET, R et Ruby.
Sélectionnez l'approche de migration
Lors de la migration de données vers Amazon DocumentDB, deux options s'offrent à vous :
Migration hors ligne
Envisagez une migration hors ligne lorsque :
Les temps d'arrêt sont acceptables : la migration hors ligne implique l'arrêt des opérations d'écriture dans la base de données source, l'exportation des données, puis leur importation dans Amazon DocumentDB. Ce processus entraîne une interruption de service de votre application. Si votre application ou votre charge de travail peut tolérer cette période d'indisponibilité, la migration hors ligne est une option viable.
Migration de petits ensembles de données ou réalisation de preuves de concept : pour les petits ensembles de données, le temps nécessaire au processus d'exportation et d'importation est relativement court, ce qui fait de la migration hors ligne une méthode simple et rapide. Il est également parfaitement adapté au développement, aux tests et aux proof-of-concept environnements où les temps d'arrêt sont moins critiques.
La simplicité est une priorité : la méthode hors ligne, utilisant cbexport et mongoimport, est généralement l'approche la plus simple pour migrer des données. Il permet d'éviter les complexités liées à la saisie des données de modification (CDC) associées aux méthodes de migration en ligne.
Aucune modification en cours ne doit être répliquée : si la base de données source ne reçoit pas activement les modifications pendant la migration, ou si ces modifications ne sont pas essentielles pour être capturées et appliquées à la cible pendant le processus de migration, une approche hors ligne est appropriée.
Couchbase Server 6.x ou version antérieure
Compartiment Couchbase pour la collection Amazon DocumentDB
Exportez les données à l'aide de cbexport json--formatoption, vous pouvez utiliser lines oulist.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importez les données dans une collection Amazon DocumentDB à l'aide de mongoimport avec l'option appropriée pour importer les lignes ou la liste :
lignes :
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
liste :
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 ou version ultérieure
Pour effectuer une migration hors ligne, utilisez les outils cbexport et mongoimport :
Bucket Couchbase avec étendue et collection par défaut
Exportez les données à l'aide de cbexport json--formatoption, vous pouvez utiliser lines oulist.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importez les données dans une collection Amazon DocumentDB à l'aide de mongoimport avec l'option appropriée pour importer les lignes ou la liste :
lignes :
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
liste :
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Collections Couchbase vers des collections Amazon DocumentDB
Exportez les données à l'aide de cbexport json--include-dataoption pour exporter chaque collection. Pour l'--formatoption, vous pouvez utiliser lines oulist. Utilisez les --collection-field options --scope-field et pour enregistrer le nom de la portée et de la collection dans les champs spécifiés de chaque document JSON.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
Puisque cbexport a ajouté les _collection champs _scope et à chaque document exporté, vous pouvez les supprimer de tous les documents du fichier d'exportation par recherche et remplacementsed, ou par la méthode de votre choix.
Importez les données de chaque collection dans une collection Amazon DocumentDB à l'aide de mongoimport avec l'option appropriée pour importer les lignes ou la liste :
lignes :
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
liste :
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Migration en ligne
Envisagez une migration en ligne lorsque vous devez minimiser les temps d'arrêt et que les modifications en cours doivent être répliquées sur Amazon DocumentDB en temps quasi réel.
Consultez Comment effectuer une migration en direct de Couchbase vers Amazon DocumentDB pour
Couchbase Server 6.x ou version antérieure
Compartiment Couchbase pour la collection Amazon DocumentDB
L'utilitaire de migration pour Couchbasedocument.id.strategy paramètre est configuré pour utiliser la valeur de la clé du message comme valeur de _id champ (voir Propriétés de la stratégie de l'identifiant du connecteur récepteur
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 ou version ultérieure
Bucket Couchbase avec étendue et collection par défaut
L'utilitaire de migration pour Couchbasedocument.id.strategy paramètre est configuré pour utiliser la valeur de la clé du message comme valeur de _id champ (voir Propriétés de la stratégie de l'identifiant du connecteur récepteur
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Collections Couchbase vers des collections Amazon DocumentDB
Configurez le connecteur source
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
Configurez le connecteur récepteur
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
Validation
Cette section fournit un processus de validation détaillé pour vérifier la cohérence et l'intégrité des données après la migration vers Amazon DocumentDB. Les étapes de validation s'appliquent quelle que soit la méthode de migration.
Rubriques
Vérifiez que toutes les collections existent dans la cible
Source de Couchbase
option 1 : banc de requêtes
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
option 2 : outil cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Cible Amazon DocumentDB
mongosh (voir Connect to your Amazon DocumentDB cluster) :
db.getSiblingDB('<database>') db.getCollectionNames()
Vérifiez le nombre de documents entre les clusters source et cible
Source de Couchbase
Couchbase Server 6.x ou version antérieure
option 1 : banc de requêtes
SELECT COUNT(*) FROM `<bucket>`
option 2 : cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 ou version ultérieure
option 1 : banc de requêtes
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
option 2 : cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Cible Amazon DocumentDB
mongosh (voir Connect to your Amazon DocumentDB cluster) :
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
Comparez les documents entre les clusters source et cible
Source de Couchbase
Couchbase Server 6.x ou version antérieure
option 1 : banc de requêtes
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
option 2 : cbq
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 ou version ultérieure
option 1 : banc de requêtes
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
option 2 : cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Cible Amazon DocumentDB
mongosh (voir Connect to your Amazon DocumentDB cluster) :
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
